3种双集群系统方案设计模式详解
当前社会、企业运行当中,大数据分析、数据仓库平台已逐渐成为生产、生活的重要地位,不再是一个附属的可有可无的分析系统,外部监控要求、企业内部服务,涌现大批要求7*24小时在线的应用,逐步出现不同等级要求的双集群系统。
数据仓库主流数据库平台均已存在多重高可靠保障措施设计,如硬盘冗余的raid设计、数据表冗余、节点备用冗余、机柜备用数据交叉等,以及加上服务进程高可用冗余设计,其最大化程度满足数据仓库服务持续在线。
但现实场景,如数据库软件缺陷、定期加固补丁、产品迭代、硬件升级这些产品现实因素,以及来自机房、数据中心、地域、网络的外部灾难故障因素,均在降低数据仓库可用性服务水平。
鉴于数据仓库存在大量数据吞吐,针对不同数据库、不同可用性要求,若需要设计双集群冗余设计,可选技术手段分别有数据同步模式、双ETL模式、双活模式,具体探讨如下:
1. 数据同步模式
a) 架构
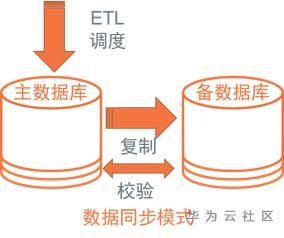
由于数据库IO能力有限、且两个数据库间带宽有限,除了首次全量同步之后,后续通常考虑增量同步技术,即如何准确、高效获取“变化数据”,一般存在日志同步技术、备份增量同步技术、逻辑数据同步;
b) 日志同步技术
日志同步技术,有业内最著名Oracle Golden Gate,大部分厂家也有自己的实现方式,像Teradata近年来推出Unity CDM(变化数据广播)技术,而我司GaussDB for DWS可采用xlog及page进行变化数据同步。
优势:直接同步变化数据增量,数据量少,要求带宽低,但目前市面技术大都只适合数据每日变化量较少的数据仓库环境;
劣势:现实的技术门槛高,应对各类异常场景适应能力差,对主数据库侵入性能要求高,一旦主库繁忙,同步时效低;面对全删全插等变化数据量大场景,同步吃力;
c) 备份增量同步技术
主要利用各数据库平台备份恢复能力,进行数据增、全量备份、恢复;通常源库备份数据压缩之后,经网络传输后,解压恢复到目标库;对应GaussDB for DWS可采用roach备份恢复工具实现;
优势:利用同一技术实现增、全量数据同步,逻辑清晰,各场景容错能力强;
劣势:要求数据库支持增备能力,且往往锁等待严重;
d) 逻辑数据同步
该项主要涉及较高的业务侵入性,即充分获取ETL调度数据流元数据,对应数据库当日数据稳定之后,发起数据表导出-导入操作,针对数据表加工特性,选择增全量同步规则,进行数据准实时同步。
优势:较上述同步技术,可以实现多样选择性同步,同步过程由实施项目本身控制,做到表级数据同步,不需要全系统同步,即可实现部分业务双集群;
劣势:客户化同步逻辑,操作前置依赖多,实施投入人力多,较难推广;
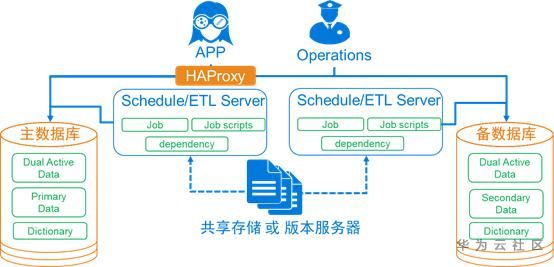
2. 双ETL模式
a) 架构

即采用两套独立调度平台进行数据加工,抽取同一个数据源(往往是落地稳定的数据交换平台),采用同一套ETL代码依赖逻辑调度,各自生成目标数据,往往批量过程中,采取主库对外持续服务,待主备库数据准实时或批后校验一致后,再开放备库对外服务。
若双集群数据发生不一致场景,主要以主库数据为准,覆盖备库。该同步过程,需要使用到“数据同步模式”相关同步技术。
b) 参照落地架构
c) 加载源数据考虑
为保证两套ETL调度加载数据源一致及数据复用,往往要求搭建一个数据交换平台。因为至少存在一个文件被两套调度读取,要求数据交换平台两倍过往吞吐能力;且禁止加载的数据文件被二次覆盖,导致两套系统加载不一致;
d) 调度依赖顺序考虑
由于ETL作业调度关系没有配置完备,即存在A作业使用B作业的数据,但不配置依赖关系(绝大部分的情况是A作业可容忍B数据的时效,是否最新数据均可以使用,故为时效,业务上不配置依赖关系;当然也存在物理时间上,通常B远远早于A执行),导致两套系统A作业生成数据不一致。
该场景下,在一套调度平台无法发现此问题,但存在两套系统的校验比对,即发现数据不一致;
该问题建议用户补全依赖关系,确认执行顺序一致性;
当然若希望灵活使用依赖关系,则需二次开发,控制两套调度当日时序一致性;
e) ETL代码服务器考虑
为了避免两套ETL调度代码维护不一致,需考虑统一维护渠道,包含不限于同一个代码存储源、版本服务器,以及代码变更时机
f) 存在不确定值的SQL函数返回
ETL代码中往往存在sample、random、row_number排序这种同一份数据产生不同结果集的函数,造成两套系统数据不一致;
该问题建议用户使用替代函数、明确取值、唯一排序,确保最终数据一致性;
同时,该设计逻辑正确情况下,哪份数据均可被业务采信,若该数据对下游影响少,可每日批后从主库同步备库,拉平数据;
g) 报错修数逻辑考虑
其中一套系统的数据发生报错、修数行为,会涉及到另一套系统的维护行为;
可选作法是保留操作逻辑,待另一套系统发生报错时重复执行一次;
其它交给数据质量校验(DQC)、数据校验去复查;
h) 干预重跑修数逻辑考虑
若批后重跑,两套系统重跑逻辑一致,涉及重复劳动(或支撑平台优化),相对简单;
但涉及批量过程中发现部分数据需要重跑,由于两套调度进度不一致,会导致
i) 数据校验
i. 校验时机
批后校验,逻辑清晰,对调度依赖少,即根据整体调度进度,做到分层、分库或整体数据校验;
准实时校验,即侵入调度环节,在每个作业完成时,均发起日志解析,提取每个SQL影响记录数,若相应作业SQL存在影响记录数不一致场景,即中止较晚完成的调度平台调度后续作业;
ii. 校验手段
增全量校验,即针对不同加工逻辑的数据表,区分增、全量数据值,以最小代价覆盖所有业务表
iii. 校验方法
通常作法有记录数、汇总值、checksum校验;
汇总值校验,通过是数值型字段直接sum、字符型计算字符长度的sum、时间类型则转换成数值相加的比对;
Checksum校验,针对全表或部分字段,进行md5或hash运算,完成两套系统一致性比对;
对于关系型数据库,校验开销代价逐步递增(记录数 < 汇总值 < checksum校验);往往是结合增量校验、结合重要指标,区分维度校验,日常增量逻辑校验,定期全量校验,在校验数据一致性和系统性能之间取得平衡点。
j)优化考量
i. 校验改进
即嵌入调度平台,提取ETL代码运行日志,通过执行SQL影响的记录值,实时进行两套系统完成作业日志比对,发现记录值影响,立即停止备库调度,采用人工或自动方式修复数据,继续后续批量。
该作法最大好处是,即时发现数据异常,避免问题放大,保障备库更高可用性;
ii. 引入统一维护平台
即减少人为双系统维护操作,代码变更平台化,修数逻辑平台化,由平台分别下发两套调度平台、两套数据库。
3. 双活模式
以下基于Teradata Unity产品理念的延伸构想
a) 架构
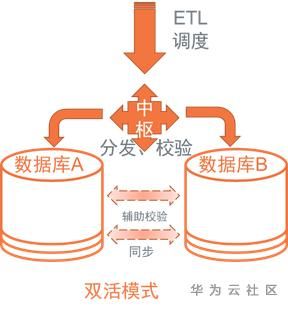
b) 双活功能点
i. 访问路由能力
客户端直接将中间件作为数据库登陆,保持原来登陆逻辑不变;
中间件根据登陆用户及附加参数实现拒绝登陆、双系统登陆、或单系统登陆,实现写登陆、读登陆,实现受控方式登陆、或非受控方式登陆;即实现受控和非受控方式的系统读写;
同时兼顾考虑异常路由选择或同步路由选择,满足最大化异常执行及少部分同步需求场景;
ii. SQL分发能力
经中间件发送的SQL指令,正常发送到相应数据库,并接受数据库响应信息;
iii. 批量导入、导出能力
针对数据大批量的导入,需要考虑采用更加高效的加载协议进行数据加载,并考虑经中间件复制数据块,异步分发两个数据库;
数据导出,需要考虑高效数据导出协议,从其中一套数据库正确导出数据;
iv. 更新类SQL校验能力
Delete、Update、Insert、Merge等更新类DML SQL进行SQL影响记录数校验;
DDL/DCL执行返回码验证一致性能力;
v. 对象注册功能
通过路由及创建对象的DDL语句,实现对象动态注册;
通过命令行指令实现对象注册;
适当增加对象索引、约束索引的注册信息,用于扩展细粒度对象锁能力,提高数据仓库ETL SQL并发能力;
*数据仓库环境下,只需要考虑到表级双活的能力,不建议实施字段级、记录级双活;
vi. 对象锁能力
根据SQL指令给相应对象动态加锁、释放锁;
同时根据数据库自带的锁特征,至少区分读、写锁控制,以及部分数据库的脏读功能锁;
vii. 对象状态控制能力
进行管理的多套数据库在线状态控制;
进行对象状态控制功能,包含不限于在线、离线、只读、只写、主动中断缓存中、被动中断缓存中、不可用等状态;
viii. 缓存能力
进行SQL指令流缓存能力,以及缓存恢复执行的能力;
进行SQL与加载数据结合缓存、以及缓存恢复执行的能力;
ix. SQL异常控制能力
考虑用户体验,始终由返回响应正确的SQL指令返回客户端;
两个数据库返回均成功,但返回的影响记录数不一致,则响应慢的数据库对应SQL及涉及对象被设置成不可用状态;
若两套数据库其中一套执行成功,另一套执行失败,则执行失败的数据库SQL和涉及对象被设置为被动中断缓存中,同时缓存SQL,定时重试SQL;
若两套数据库返回均报错,才通知客户端报错;
若SQL涉及对象已处理非在线状态,则新提交的SQL被缓存,新提交SQL相应对象被设置为被动中断缓存中。
针对中间件和数据库之间,存在数据库已执行完、但中间件未收到信号场景,需考虑闪环该场景(如增加事务锁等);
c) Teradata Unity参照落地架构
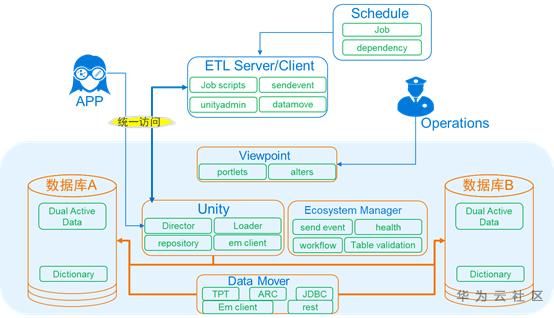
ü 主要通过Unity实现多集群SQL、数据分发与管理;
ü Data Mover实现集群间数据同步;
ü Eocsystem Manager实现数据批后自动校验及不一致重同步事件触发;
ü Viewpoint实现系统平台透视图展现与维护,并对接用户告警平台;
d) 中间件高可用考虑
由于引入了中间件(前置)服务,即该服务的稳定、可靠对双活模式至关重要。
数据库单套系统本身已经具备极高的可用性,引入中间件后,由于所有数据库访问行为均通过该中间件,中间件任何异常均同时影响两套数据库访问能力。
除了中间件本身所有相关服务需要满足高可用之外,还需考虑极端场景下bypass能力,此项能力在于极端异常条件下,可以保障系统持续服务的能力。
高可用场景中,存在控制节点脑裂与自动升主场景,需借鉴仲裁机制减少脑残裂发生;
e) 数据重同步考虑
即利用“数据同步模式”相关同步技术,实现两套数据库数据重同步能力;
f) 不确定值的SQL函数考虑
最佳方案,是采用“数据同步模式”的数据日志重同步技术,直接将第一套数据库SQL执行结果的日志信息同步到第二套数据库中,消除返回结果不一致;
部分简单的系统时间函数,直接通过中间件改写,保障SQL执行结果一致性;
另外,则通过SQL改写,保证row_number函数进行主键或全字段排序,保证SQL执行结果一致性;
g) 异常会话重放能力
针对异常会话过程的SQL,可能需要从会话建立后,可视化选择,倒回前几个SQL重新执行,并指定过程SQL是否参与结果集校验,以及SQL回放结束的确认动作,让异常场景处理手段更加丰富。
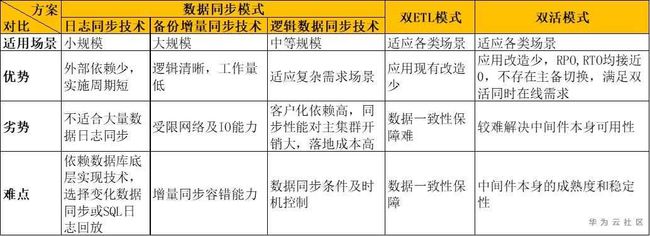
4. 适用场景
a) “数据同步模式” – 日志同步技术
适用数据变化量小、数据传输压力小的数据场景,通常只适用于小型数据仓库平台;
对于规模小的平台,RPO、RTO可以接近0;
b) “数据同步模式” – 备份增量同步技术
适合大数据量同步场景,实现方式容易被用户理解;
往往需要数据库备份工具具备增量备份恢复能力;同时考验备份工具消除相关硬件限制条件,让该技术方案更加灵活;
双集群的初始化同步往往采用全备全恢的逻辑实现,可以最大化、最快拉平存量数据;
对于规模大的平台,RPO往往需要小时级别,RTO最好水准也在分钟、10分钟以上;同时主集群需要保障一定资源量供数据同步使用,对主集群开销大;
c) “数据同步模式” – 逻辑数据同步技术
适用灵活同步场景,往往数据同步量不会太大,或同步时间可容忍场景;
此场景往往适合于用户对其数据仓库ETL过程元数据信息清晰、完整,依赖客户开发能力,相关同步数据存在清晰ETL算法,结合调度作业运行进度,动态发起相关数据表增、全量同步;
对于中等规模的平台,RPO可以做到分钟、半小时,RTO可以维持在分钟级;
d) “双ETL模式”
需要两套ETL调度环境,整体成本翻倍,但调度逻辑清晰、易于理解和维护;
较容易匹配不同规模的数据仓库平台采纳;
较难实现数据实时比对,以及数据发生不一致之后的控制逻辑(若需要实现,对于调度逻辑侵入性大);
ETL调度批量中途,较难实现两套调度链路协调重跑;
同时数据不一致,依赖于”数据同步模式”技术辅助实施;
由于主备调度进行不一致,无法做到主备统一视图展现;
若双集群硬件相当,RPO、RTO均可以维持在分钟级别;
e) “双活模式”
需要独立中间件、且严重依赖数据库自身厂商,中间件实现难度大;
中间件的高可用(稳定性)成为它落地的最大障碍;
“双ETL模式”的升级版,能适应各类数据仓库双集群场景;
绝大部分场景下,RPO、RTO均可以接近0,特别是双活同时在线能力,不存在双集群的主备切换,RTO可以做到0;同时存在统一视图,不会因为其中一个集群故障,造成前后同一个查询返回结果不一致场景;
5. 总结比对
点击这里→了解更多精彩内容