【API进阶之路】破圈,用一个API代替10人内容团队
自从学习API以后,我用技术手段相继帮助业务部、市场部解决了不少难题,算是从纯研发破圈发展到了业务端。老板召开业务讨论会的时候也会带上我,希望我能从技术角度帮助公司解决业务问题,提升业务的效率和业绩。
前几天的业务讨论会上,业务部门提出:现在官网的整体流量已具规模,接下来要加大资讯内容的运营力度,将原本的资讯内容独立出来成为一个单独的产品,通过优质内容给业务导流,提升现有用户的留存率。说白了就是给公司建立一个私域流量池,将用户聚集沉淀下来。
按照运营部门的规划,需要专门组建一支编辑团队来负责资讯产品的内容生产,主要职责包括:内容转载、改编、摘要编辑、内容推荐等。根据官网的日访问量和内容需求的速度预估,现有的3人远远不够,至少需要再招聘10个编辑。
老板觉得13人的编辑团队成本有点高,且新团队组建的风险也比较大。沉默了一会儿后,他看向我:“听说有一种技术,可以自动筛选和获取优质的文章,你了解吗?”我还没开口,运营老大说:“获取的文章还是需要编辑来写摘要和推荐语,这些也都是工作量。”他说得很有道理,必须同时解决筛选内容、获取内容、摘要生成等多个问题。
在心里默默地过了一遍我了解的API,有一个“文本摘要生成API”正好可以满足我们这个场景,整理了一下思路后,我回答了他们的问题:
“我们可以利用现有技术获取站外优质内容,由编辑同事提供内容获取来源,用关键词分析API和语义分析API判断获取内容的健康度,然后用“文本摘要生成API”对内容进行分析,提取文章的核心内容,自动生成文章摘要,最后由编辑来做优质内容的推荐和push,这样下来最多3个编辑就够了。”
老板听完非常开心,当即敲定就这么办!散会后我马上写了一个文档,让部门的研发同事去执行。
“文本摘要生成API”的调用方式如下。
一、不会写代码?通过postman调用。
1.1 获取Token
发送一条POST请求。
POST:https://iam.cn-north-4.myhuaweicloud.com/v3/auth/tokens
Content-Type:application/json
Body:
{
"auth": {
"identity": {
"methods": [
"password"
],
"password": {
"user": {
"name": "华为云用户名",
"password": "华为云密码",
"domain": {
"name": "华为云用户名"
}
}
}
},
"scope": {
"project": {
"name": "cn-north-4"
}
}
}
}请求结果:点击[Headers],查看x-subject-token对应的值。如图所示。

1.2 请求接口
1.2.1 获取项目ID
登录华为云 →点击控制台 →点击自己用户名[我的凭证] →项目cn-north-4对应的项目ID。
1.2.2 调用postman
发送一条POST请求
POST:https://nlp-ext.cn-north-4.myhuaweicloud.com/v1/{project id}/nlg/summarization/domain
Headers:
Content-Type:application/json
X-Auth-Token:上一步获取的Token值
Body:
{
"length_limit": 50,
"title": "文章标题",
"lang": "zh",
"content": "文章内容"
}参数:length_limit 表示生成摘要的长度限制
如果 length_limit > 1,则表示摘要的具体字数;
如果 0 <= length_limit <=1,则表示生成摘要占原文长度的百分比;
默认数值为0.3

请求结果:
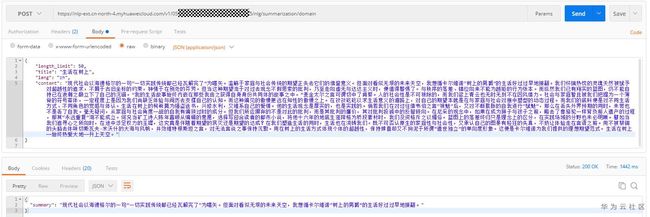
二、会写代码?Python为你一条龙服务
以2020浙江省高考满分作文为例,原文地址:https://zhuanlan.zhihu.com/p/166373560
请求示例:
#-*- version: Python3.0 -*
#-*- coding: UTF-8 -*
import json
import requests
"""
所有全局变量
"""
#
代理
PROXY = {
"http": "http://xxx:[email protected]:8080/",
"https": "https:// xxx:[email protected]:8080/"
}
#
华为云账号、密码、
NAME = "xxx"
PASSWD = "xxx"
ENDPOINT = 'nlp-ext.cn-north-4.myhuaweicloud.com' #
华北-北京四
PROJECT_ID = 'xxxxxxxxxxxxxxxxxxxxxxxxxxx' #
控制台-用户名-我的凭证
# Token
的有效期为24小时,需要使用一个Token鉴权时,可以先缓存起来,避免频繁调用。
def Get_Token(name, passwd, project_name):
URL = 'https://iam.cn-north-4.myhuaweicloud.com/v3/auth/tokens'
headers = {'Content-Type': 'application/json'}
post_data = {
"auth":
{
"identity":
{
"methods": [ "password" ],
"password":
{
"user":
{
"name": name,
"password": passwd,
"domain": {"name": name}
}
}
},
"scope": {"project": {"name": project_name}}
}
}
post_data = json.dumps(post_data, ensure_ascii=False)
content = requests.post(url=URL, data=post_data.encode('utf-8'), headers=headers, proxies=PROXY, verify=False)
token = content.headers["x-subject-token"]
# print(token)
return token
#
读取文章
def Read_News(frname):
with open(frname, 'r', encoding='utf-8') as fr:
return fr.read()
def Use_API_NLG_summarization(token, title, content):
# URL
是URI的一个子集 {URI-scheme} :// {Endpoint} / {resource-path} ? {query-string}
serve_name = 'nlg/summarization/domain' #
服务名和下面请求数据格式对应
URI = "https://{endpoint}/v1/{project_id}/{serve_name}".format(endpoint=ENDPOINT, project_id=PROJECT_ID, serve_name=serve_name)
post_data = {
"length_limit": 50,
"title": title,
"lang": "zh",
"content": content
}
headers = {
'Content-Type': 'application/json',
'X-Auth-Token': token
}
post_data = json.dumps(post_data, ensure_ascii=False)
content = requests.post(url=URI, data=post_data.encode('utf-8'), headers=headers, proxies=PROXY, verify=False)
content = json.loads(content.text)
print(content)
if __name__ == "__main__":
token = Get_Token(NAME, PASSWD, "cn-north-4")
Use_API_NLG_summarization(token, "生活在树上", Read_News("./tmp_news.txt")[:10000])
主函数执行,返回结果。
![]()
从返回结果可以看出此API对作文的中心思想进行了精准地提取。
通过API自动完成文章获取、筛选、摘要提取,一篇文章只需要十几秒,不仅不用新招内容运营,原有3个编辑的工作也轻松了不少。资讯网站上的内容丰富了,用户活跃度也提升了,不少用户留言:“每天来你们这看看新闻,都养成习惯了。”
—— 分割线 ——
了解更多华为云API信息:
“免费下载创新加速利器《华为云API精选手册》
点击这里→了解更多精彩内容