python函数传参
学c的时候是否入门其实就是看函数传参、数组和指针的掌握程度。学python的时候反而忽略了这些基础性的东西,所以涉及列表套列表、字典套字典、列表套字典、字典套列表等复杂数据类型的时候就会发蒙。
文章目录
- 引用传递
- 位置参数和关键字参数
- 接受任意数量的位置参数
- 接受任意数量的关键字参数
- 同时接受任意数量的位置参数和关键字参数
- 指定参数只接受关键字参数
- 将元数据信息附加到函数参数上
- 返回多个值
- 默认参数
- 默认参数使用
- 默认参数赋值只会在函数定义时绑定一次
- 默认参数应该是不可变对象
- 匿名/内联函数
- 匿名函数绑定变量
- 列表推导中创建一列lambda表达式
引用传递
网上大多数的博客把python函数传参分为两种情况:
- 值传递
- 引用传递
对于按值类型传递,代码如下:
num = 10
def double(arg):
arg=arg*2
print(arg)
double(num)
这些博客中这样解释:
调用该函数,传入一个变量,其实传入的是该变量的一个副本,该变量在函数中发生变化,不影响函数外面该变量。
说的对不对呢?我们用id()来看一下:
num = 10
print('num address:', id(num))
def double(arg):
print('arg address:', id(arg))
arg = arg*2
print(arg)
print('arg address:', id(arg))
double(num)
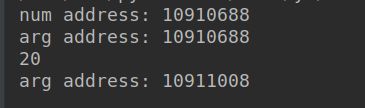
我们发现num和一开始的arg的地址是一样的!这一点同样可以用print(num is arg)证明。arg运算之后值改变了,开辟了一块新的空间,所以运算arg=arg*2之后,arg的id变了。
我们可以提出一个猜想:由于python语言只使用引用语义,所以根本没有什么值传递,也没有什么形参实参之类的概念,所有的函数传参都是引用传递,传的都是地址!
我们知道python的内存回收机制中有一个引用计数,我们从引用计数函数sys.getrefcount()的角度再考察一下:
import sys
print('10 refcount', sys.getrefcount(10))
num = 10
print('num address:', id(num))
print('num refcount', sys.getrefcount(num))
def double(arg):
print('arg address:', id(arg))
print('num refcount', sys.getrefcount(num))
print('arg refcount', sys.getrefcount(arg))
arg = arg*2
print(arg)
print('arg address:', id(arg))
double(num)
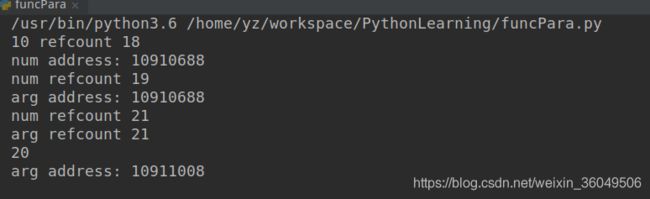
数字10所在的地址在num初始化之前就已经被引用了18次,num初始化之后引用计数变为19,到这里都是符合常识的。传参之后引用计数确实增加了,但是增加的不是1,而是2!这里就不太明白了,大牛们如果看到了,还请讲解一下。
知道了python都是引用传递之后,我们再看看别的。
位置参数和关键字参数
接受任意数量的位置参数
方法:使用*开头的参数。
例子:
def avg(first, *rest):
return (first + sum(rest))/(1+len(rest))
原理:*parameter是用来接受任意多个参数并将其放在一个元组中。
所以rest在这里是一个元组,包含了其他所有传递过来的位置参数。代码在之后的计算中会将其视为一个序列来处理。
接受任意数量的关键字参数
方法:使用**开头的参数。
例子:
import html
def make_element(name, value, **attrs):
keyvals = [' %s="%s"' % item for item in attrs.items()]
attr_str=''.join(keyvals)
element='<{name}{attrs}>{value}'.format(
name=name,
attrs=attr_str,
value=html.escape(value))
return element
# Create '- Albatross
'
make_element('item','Albatross',size='large',quantity=6)
# Create '<spam>
'
make_element('p','' )
原理: **parameter用于接收类似于关键参数一样赋值的形式的多个实参放入字典中(即把该函数的参数转换为字典)。
所以在这里attrs是一个字典,它包含了所有传递过来的关键字参数(如果有的话)。
关于代码中列表生成式的item使用
同时接受任意数量的位置参数和关键字参数
def anyargs(*args, **kwargs):
print(args) # A tuple
print(kwargs) # A dict
注意:以*开头的参数只能是最后一个位置参数,以**开头的参数只能是最后一个参数
我们可以得出一个结论:*开头参数之后的所有参数只能是关键字参数,他们称作keyword-only参数。
例子:
def a(x,*args,y):
pass
defb(x,*args,y,**kwargs):
pass
指定参数只接受关键字参数
我们希望block这个参数只能接收关键字参数,从上面的结论不难实现:
def recv(maxsize, *, block):
pass
recv(1000, block=True)
def mininum(*values, clip=None):
m = min(values)
if clip is not None:
m = clip if clip > m else m
return m
minimum(1,5,2,-5,10)
minimum(1,5,2,-5,10,clip=0)
参考:python中*号的作用:传参和解包
将元数据信息附加到函数参数上
功能:增加代码可读性。不影响python解释器。使用help时可以看到这些注解。
def add(x:int,y:int) -> int:
return x + y
返回多个值
本质上就是返回元组。注意:元组是根据逗号定义的,有没有括号没关系。
def f():
return 1,2,3
a,b,c = f()
默认参数
默认参数使用
def spam(a,b=42):
print(a,b)
spam(1) # a=1,b=42
spam(1,2) # a=1,b=2
对于可变容器,应该把None作为默认值:
def spam(a, b=None):
# 注意,这句话比 if not b更严格,b=[],b=0,b=''等输入也会判为False,但他们不是None
# 所以 if not b会使函数错误的忽略掉一些输入值
if b is None:
b = []
如果不想给默认值,只是想设置一个可选参数:
_no_value = object()
def spam(a,b=_no_value):
if b is _no_value:
print('No b value applied')
...
spam(1) # No b value applied
spam(1,2) # b=2
spam(1,None) #b=None
默认参数赋值只会在函数定义时绑定一次
x = 42
def spam(a, b=x):
print(a,b)
x = 41
spam(1) # 1 42
x = 43
spam(1) # 1 42
x值的改变并不影响spam函数的默认值,这是因为默认值在函数定义时就确定好了。
默认参数应该是不可变对象
默认参数应该是不可变对象,比如None、True、False、数字或者字符串。
反例:
def spam(a,b=[]):
print(b)
return b
x = spam(1)
x.append(99)
x.append('Yow!')
x = spam(1)
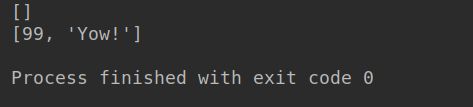
x的地址(id)和b的地址(id)相同,所以结果说明b的默认值被改变!
出现这个结果是因为:
1. 函数返回了默认值的地址,所以我们可以通过x获取到默认值b的地址。
2. 因为默认值是list,所以使用append方法添加元素没有改变x的地址。list成功扩充了,默认值被改变。
匿名/内联函数
有时候需要用户提供一个短小的回调函数给sort()这样的函数。如果不想使用def语句可以采用lambda表达式定义"内联"式的函数。
add = lambda x,y:x+y
add(2,3)
add('Hello','world!')
等价于
def add(x,y):
return x+y
lambda表达式可用在排序或对数据进行整理等上下文环境中:
names = ['David Beazley','Brian Jones','Raymond Hettinger','Ned Batchelder']
names = sorted(names, key=lambda name: name.split()[-1].lower()) # 按姓排序

匿名函数绑定变量
x = 10
a = lambda y:x+y
x = 20
b = lambda y:x+y
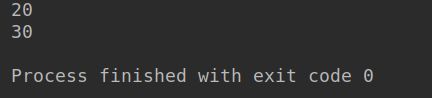
print(a(10))
print(b(10))
结果如下:
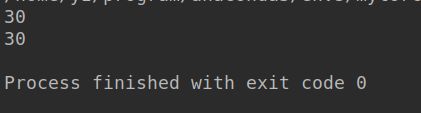
这说明匿名函数绑定变量是在运行时绑定的!执行时x的值是多少就是多少。
如果希望匿名函数可以在定义的时候绑定变量,并保持值不变,那么可以将那个值作为默认函数实现:
x = 10
a = lambda y,x=x:x+y
x =20
b = lambda y,x=x:x+y
print(a(10))
print(b(10))
列表推导中创建一列lambda表达式
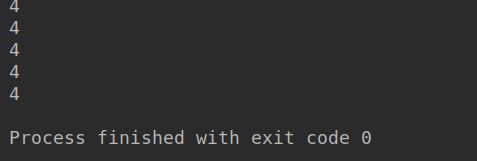
funcs = [lambda x:x+n for n in range(5)]
for f in funcs:
print(f(0))
funcs = [lambda x,n=n:x+n for n in range(5)]
for f in funcs:
print(f(0))

比较两段代码,第一个n是自由变量,运行时n一直是4;第二个n定义时捕获到了不同的n值。