21.pgsql中的执行计划explain
一、执行计划的解释
1.EXPLAIN命令

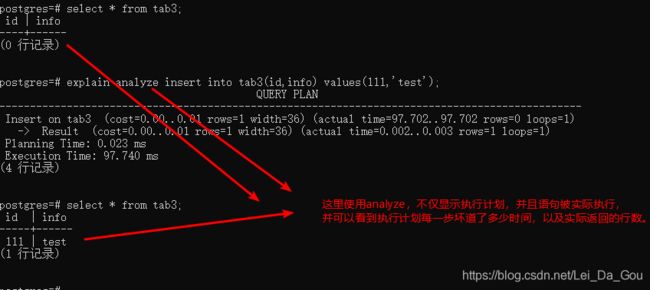
ANALYZE选项通过实际执行的SQL来获得相应的执行计划。因为它真正被执行,所以可以看到执行计划每一步花掉了多少时间,以及它实际返回的行数目。
注意1:加上analyze选项后,会真正执行实际的SQL,如果SQL语句是一个插入、删除、更新或create table as语句,这些语句会修改数据库。为了不影响实际的数据,可以把EXPLAIN ANALYZE放到一个事务中,执行完后回滚事务,如下:
begin;
explain analyze ...;
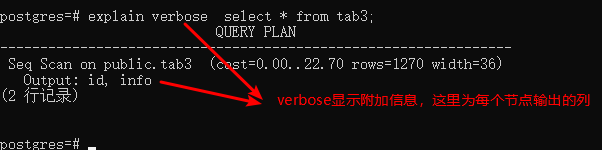
rollback;Verbose(默认false):选项用于显示计划的附加信息。这些附加信息有:计划树中每个节点输出的各个列,如果触发器被触发,还会输出触发器的名称。
Costs(默认true):选项显示每个计划节点的启动成本和总成本,以及估计行数和每行宽度。
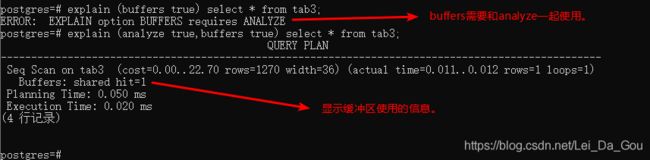
BUFFERS(默认false):选项显示关于缓冲区使用的信息。该参数只能与anlyze参数一起使用。显示的缓冲区信息包括共享块、本地块、和临时块读和写的快数。共享块、本地块、和临时块分别包含表和索引、临时表和临时索引,以及在排序和物化计划中使用的磁盘块。上层节点显示出来的块数包括其所有子节点使用的块数。
FORMAT(默认TEXT):选项指定输出格式,输出格式可以是TEXT、XML、JSON、YAML。
演示如下:
explain(含format和costs):

verbose:
analyze:
buffers:
2.EXPLAIN输出结果解释

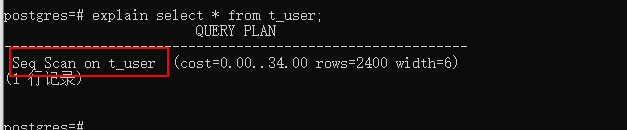
结果中“Seq Scan on t_user”表示顺序扫描表“t_user”,顺序扫描也是全表扫描;
后面的内容“(cost=0.00..34.00 rows=2400 width=6)”可以分为三部分:
1)“cost=0.00..34.00:“cost=”后面两个数字,中间是由“..”分割,第一个数字“0.00”表示启动的成本(注意这里不是时间),也就是说返回第一行pgsql需要消耗多少cost值;第二个数字表示返回所有的数据的成本,成本“cost”是什么后面会解释。
2)rows=2400:表示会返回2400行。
3)width=6:表示每行平均宽度为6byte(int=4byte,smallint=2byte)。
成本“cost”解释:pgsql描述一个SQL执行的代价是多少,默认情况下不同的操作其“cost”的值如下:
1)顺序扫描一个数据块,cost值定为1;
2)随机扫描一个数据块,cost值定为4;
3)处理一个数据行的CPU,cost为0.01;
4)处理一个索引行的CPU,cost为0.005;
5)每个操作符的CPU代价为0.0025;
3.全表扫描
全表扫描叫顺序扫描,就是把标的所有数据块从头到尾读一遍,然后从数据块中找到符合条件的数据块。
4.索引扫描
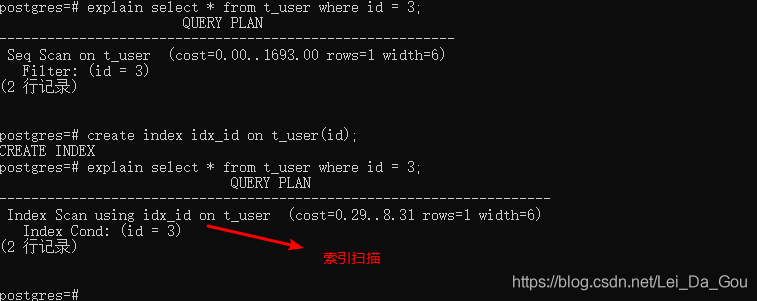
索引扫描通常视为了加快查询数据的速度而增加的。索引扫描,就是在索引中找出需要的数据行的物理位置,然后再到表的数据块中把相应的数据读出来的过程。
5.位图扫描
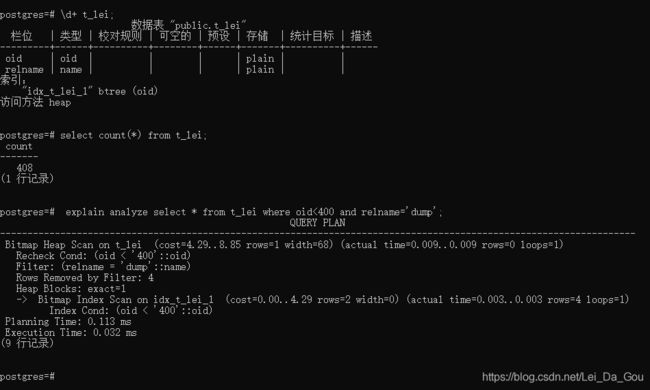
位图扫描也是走索引的一种方式。方法是扫描索引,把满足条件的行或块在内存中建一个位图,扫描完索引后,再根据位图到表的数据文件中把相应的数据读出来。如果走了两个索引,可以吧两个索引形成的位图进行and和or合并成一个位图,再到表的数据文件中把数据读出来。
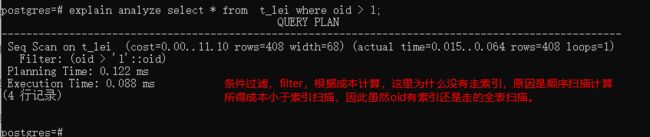
6.条件过滤

7.Nestloop Join
嵌套循环连接(Nestloop Join)是在两个表做连接时最朴素的一种连接方式。在嵌套循环中,内表被外表驱动,外表返回的每一行都要在内表中检索找到与它匹配的行,因此整个查询返回的结果集不能太大(>10000不适合),要把返回子集较小的表作为外表,而且在内表的连接字段上要有索引,否则会很慢。
执行的过程:确定一个驱动表(outer table),另一个表为inner table,驱动表中的每一行与inner表中的相应记录JOIN,类似一个嵌套的循环。适用于驱动表的记录集比较小(<10000)而且inner表有有效的访问方法(index)。需要注意的是,JOIN的顺序很重要,驱动表(outer table)的记录集一定要小,返回的结果集的相应时间是最快的。
8.Hash Join
优化器使用两个表中较小的表,并利用连接键在内存中建立散列表,然后扫描较大的表并探测散列表,找出与散列表匹配的行。
这种方式适用于较小的表可以完全放入内容的情况,这样总成本就是访问两个表的成本之和。但是如果表很大,不能完全放入内存,优化器会将它分割成若干不同的分区,吧不能放入内存的部分写入磁盘的临时段,此时要有较大的临时段以便尽量提高I/O的性能。
9.Merge Join
通常情况下散列表连接的效果比合并连接好,然而如果源数据上有索引,或者结果已经被排过序,在执行排序合并连接时就不需要排序了,这时合并连接的性能会优于是散列连接。
二、与执行计划相关的配置项
1.ENABLE_*参数

解释下这里的tidscan:
PostgreSQL 自带的表是堆表,数据按行存储在HEAP PAGE中,在btree索引中,除了存储字段的value,还会存储对应的ctid(即行号),检索记录也是通过行号进行检索的呢。
因此通过行号是可以快速检索到记录的。
行号的写法是(page_number, item_number),数据块从0开始编号,行号从1开始编号。

2.COST基准值参数
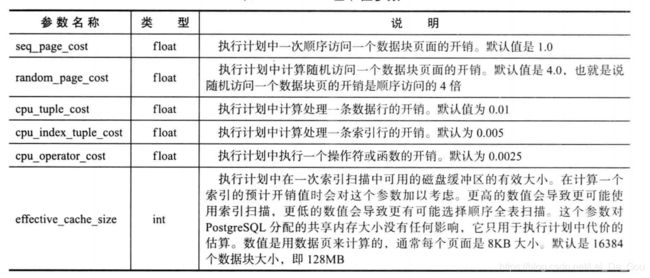
seq_page_cost一般为基准,不用改变。而random_page_cost,如果读取数据都在内存中命中,则随机读和顺序读的消耗差异不大,可能需要把random_page_cost调小一点,如果偏向走索引而不是全表扫描,可以吧random_page_cost值调大一点。
三、统计信息的收集
PgStat子进程是pgsql中专门的统计信息收集器进程。收集的统计信息主要用于查询优化时的成本估算,当然这些统计数据对数据库活动的监控及性能分析也能有很大的帮助。表和索引的行数、块数等统计信息记录在系统表pg_class中,其他的统计信息主要收集在系统表pg_statistic中
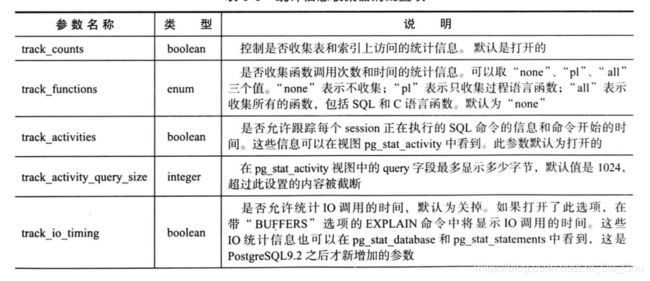
1.统计信息收集器的配项

2.SQL执行的统计信息输出

3.手工收集统计信息(analyze命令)
手工收集统计信息的命令是analyze命令,此命令收集表的统计信息,然后把结果保存在系统表pg_statistic中。优化器可以使用这些统计信息来确定最优的执行计划。
在默认的pgsql配置中,autovacuum守护进程是打开的,它能自动的分析表,并收集表的统计信息。
当autovacuum关闭时,需要周期性地,或者在表的大部分内容变更后运行analyze命令。准确的统计信息将帮助优化器生成最优的执行计划,从而改善查询的性能。一种比较常用的策略是每天在数据库比较空闲的时候运行一次vacuum和analyze。

ANALYZE命令格式:
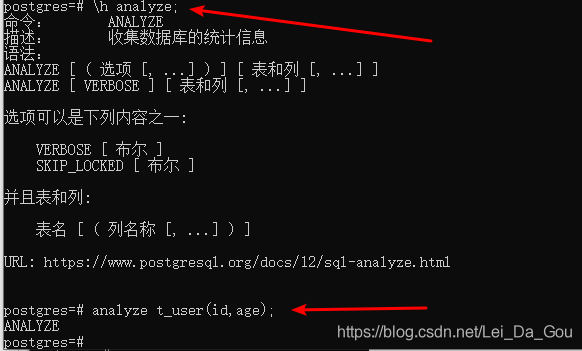
表后不指定列,则默认为分析所有列。

