Elasticsearch:创建一个Elasticsearch Ingest 插件
在前面的一篇文章“Elasticsearch:创建属于自己的Ingest processor”中,我相信地介绍了如何使用一个模板来创建 Ingest 插件。在今天的文章中,我们使用另外一个方法来做同样的事。我们将使用eclipse来生成一个maven的项目。
前言
Elasticsearch是用Java编写的,在Elasticsearch服务器启动期间,所有各种模块都与Google Guice挂钩。 除此之外,还提供了一个插件API,可以进一步扩展Elasticsearch的功能。 在本文中,我们将演示如何为Elasticsearch编写一个 Ingest 插件,该插件可以在文档索引被索引之前过滤掉文档字段中的某个关键字。 该示例插件相当简单,但是它为你提供了足够的知识来编写功能全面的Elasticsearch Ingest插件,该插件能够在实际建立索引之前处理文档。
Elasticsearch plug-in API
Elasticsearch从Elasticsearch的plugins目录加载插件。 每个插件都需要提供一个实现org.elasticsearch.plugins.Plugin接口的类。 此外,该类还可以从同一org.elasticsearch.plugins包中实现一个确定插件类型的特定接口,例如:
除此之外,每个插件都需要在plugin-descriptor.properties文件和可选的plugin-security.policy文件中向Elasticsearch提供插件元数据,该文件具有插件所需的访问控制权限(由JDK指定) 安全沙箱模型)。
动手实践
创建插件
在今天的练习中,我们将创建一个关键字过来的 ingest 插件。我们将使用 eclipse 来进行展示。首先启动供我们eclipse:
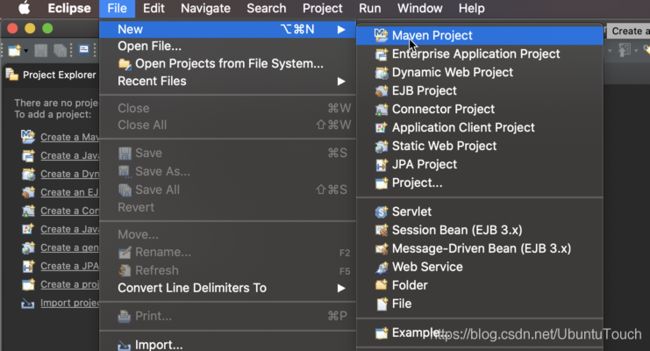
在上面,我们选择Maven Project:
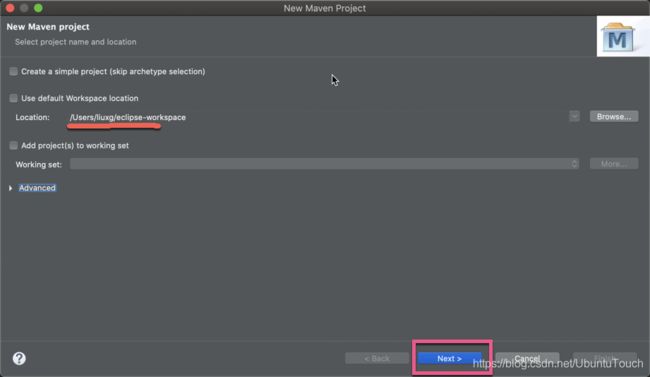
我们接下来选择自己额 workspace 位置,并点击 Next:
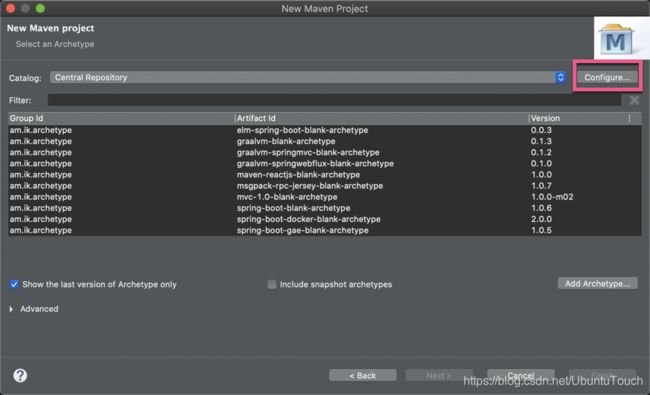
如果你还没配置好你的catalog的话,那么你可以点击上面的Configure:
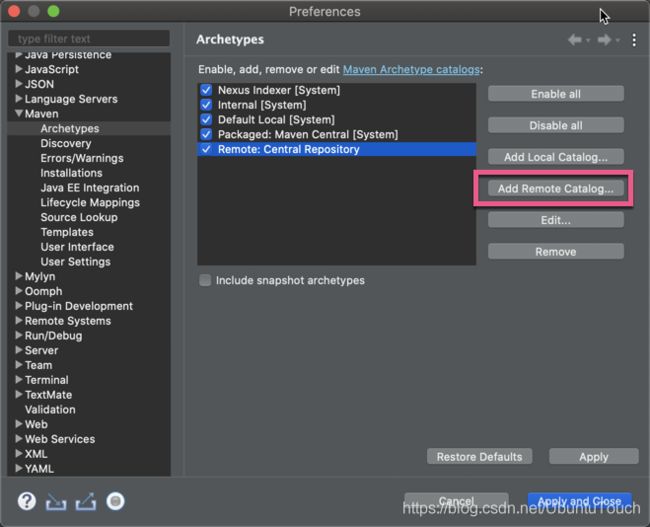
我们点击Add Remote Catalog,并添加如下的一个catalog https://repo1.maven.org/maven2/:

等我们配置好catalog后。我回到先前的页面:
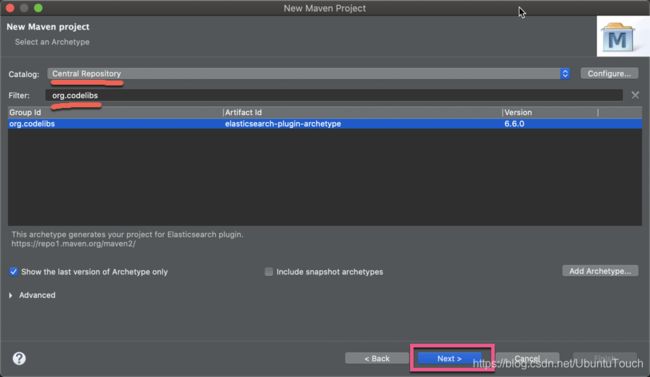
我们点击Next按钮:
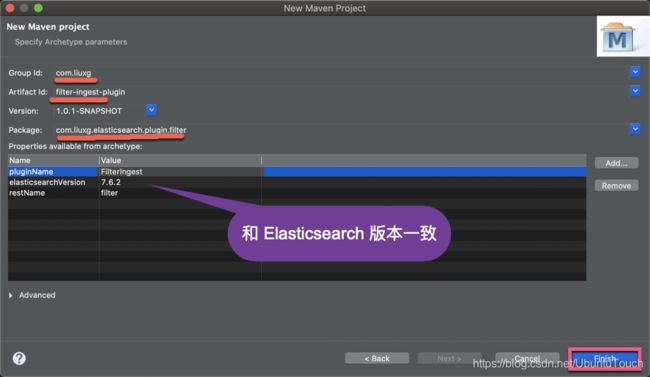
我们填入如上的信息,并点击Finish按钮。这样我们就生产了一个样本的 plugin。但是这个 plugin 并不是我们所希望的 Ingest plugin 框架。我们需要对它做相应的改动:
FilterIngestPlugin.java
package com.liuxg.elasticsearch.plugin.filter;
import java.util.HashMap;
import java.util.Map;
import org.elasticsearch.ingest.Processor;
import org.elasticsearch.plugins.IngestPlugin;
import org.elasticsearch.plugins.Plugin;
public class FilterIngestPlugin extends Plugin implements IngestPlugin {
@Override
public Map getProcessors(Processor.Parameters parameters) {
Map processors = new HashMap<>();
processors.put(FilterWordProcessor.TYPE, new FilterWordProcessor.Factory());
return processors;
}
} 
一旦安装了插件,getProcessors方法将返回一个或多个可由Elasticsearch使用的 ingest 处理器。 在这种情况下,我们将通过以下实现注册FilterWordProcess类提供的一个处理器。我们接着点击上面红色标识的链接,并生产另外一个叫FilterWordProcessor.java的文件:
FilterWordProcessor.java
package com.liuxg.elasticsearch.plugin.filter;
import java.util.Map;
import org.elasticsearch.ingest.AbstractProcessor;
import org.elasticsearch.ingest.ConfigurationUtils;
import org.elasticsearch.ingest.IngestDocument;
import org.elasticsearch.ingest.Processor;
public class FilterWordProcessor extends AbstractProcessor {
public static final String TYPE = "filter_word";
private String filterWord;
private String field;
public FilterWordProcessor(String tag, String filterWord, String field) {
super(tag);
this.filterWord = filterWord;
this.field = field;
}
@Override
public IngestDocument execute(IngestDocument ingestDocument) throws Exception {
IngestDocument document = ingestDocument;
String value = document.getFieldValue(field, String.class);
String clearedValue = value.replace(filterWord, "");
document.setFieldValue(field, clearedValue);
return document;
}
@Override
public String getType() {
return TYPE;
}
public static final class Factory implements Processor.Factory {
@Override
public Processor create(Map registry, String processorTag,
Map config) throws Exception {
String field = ConfigurationUtils.readStringProperty(TYPE, processorTag, config, "field");
String filterWord = ConfigurationUtils.readStringProperty(TYPE, processorTag, config, "filterWord");
return new FilterWordProcessor(processorTag, filterWord, field);
}
}
} 这个 ingest 处理器具有称为filter_word的类型,Elasticsearch使用该类型来对其进行管理。 插件使用在创建处理器时指定的两个属性:表示要过滤的文档字段的字段 field 和表示要在索引文档之前要过滤掉的文档字段中单词的filterWord。 execute方法提供了处理器的逻辑。它的实现是非常简单的。
好了。我们基本完成了我们需要改造的代码。
编译插件
我们接着来编译刚才生成的代码。我们使用如下的命令:
mvn clean install如果不出意外,你将看到和我一样的错误信息:
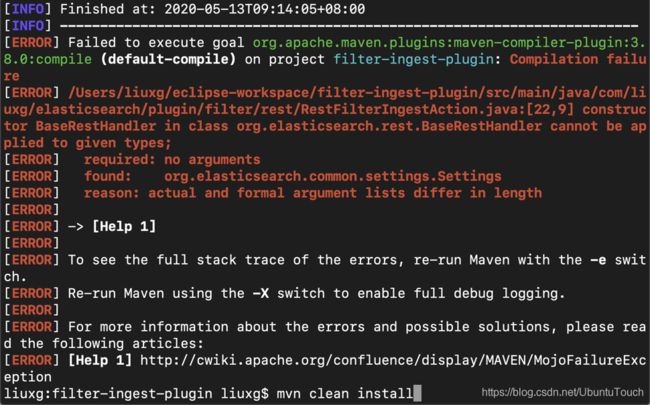
我们回到文件RestFilterIngestAction.java文件,并做相应的修改:
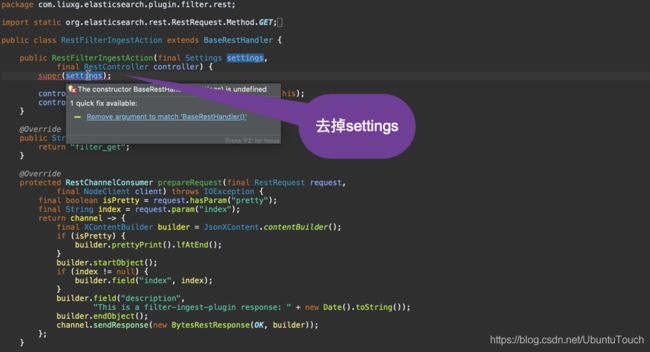
我们做相应的修改后,再重新编译:
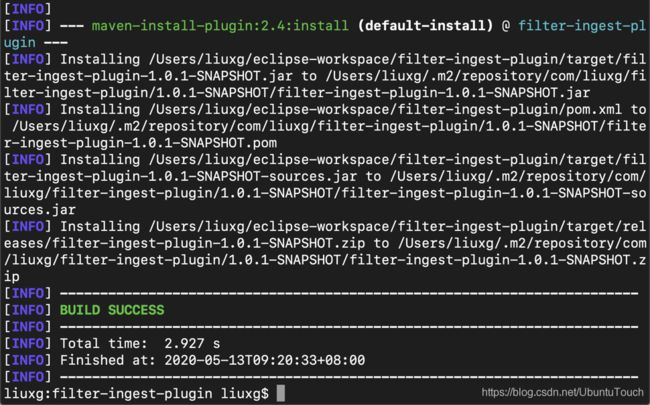
我们把生成的plugin拷入到Elasticsearch的安装根目录中:
cp ./target/releases/filter-ingest-plugin-1.0.0-SNAPSHOT.zip ~/elastic0/elasticsearch-7.6.2依赖于你Elasticsearch安装的位置不同,上面命令的路径需要根据你自己的安装而改变。
我们进入到Elasticsearch安装的根目录中,并打入如下的命令:
./bin/elasticsearch-plugin install file:Users/liuxg/elastic0/elasticsearch-7.6.2/filter-ingest-plugin-1.0.0-SNAPSHOT.zip你一定要注意上面的 file:///。 否则你的安装将会不成功。后面紧跟的是你的文件的路径。等安装完后,我们可以使用如下的命令来检查安装是否成功:
./bin/elasticsearch-plugin list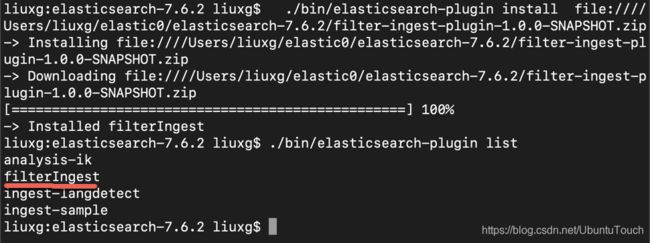
最后一步,也是非常重要的一步。我们需要重新启动我们的Elasticsearch,这样新的plugin才会起作用。
在Kibana中进行测试
打开Kibana,并输入如下的命令:
PUT /_ingest/pipeline/filter_crap
{
"processors": [
{
"filter_word": {
"field": "description",
"filterWord": "crap"
}
}
]
}在上面,我们想对 description 这个字段进行过滤,而且我们过滤的关键词是 crap,也即是没有用的东西 :)。运行上面的命令,显示:
{
"acknowledged" : true
}它表明我们的 filter_word processor已经被安装好了,并且可以找到了。如果没有安装好,或没有被Elasticsearch 装载,那么这个命令就会失败。
我们接着执行如下的命令:
PUT /order_data/_doc/1?pipeline=filter_crap
{
"description": "crap ! Don't buy this."
}{
"_index" : "order_data",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}在上面,在decription中,有一个 crap 的单词。我们希望经过我们的过滤器后,那么最后在 Elasticsearch 存放的文档中,将不会有 crap 这个单词。这个有点像是我们永远看到的东西都是好的。没有坏的语言 :)
我们接着使用如下的命令来进行检查:
GET order_data/_search{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "order_data",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"description" : " ! Don't buy this."
}
}
]
}
}在上面,我们可以看到在description中,没有了crap 这个单词了。它说明了我们的filter processor是正常工作的。
如果你对这个整个代码感兴趣的话,那么请访问我的源码:https://github.com/liu-xiao-guo/filter-ingest-plugin