一起学习C语言:函数(三)
上一篇<一起学习C语言:函数(二)> 中,我们了解了内部函数和外部函数,以及变量的声明周期与作用域。本章节,我们分析函数的存储类别与声明方式,以及函数的递归调用原理。
章节预览:
6. 变量的存储类别与声明方式
7. 函数的递归调用
目录预览
章节内容:
6. 变量的存储类别与声明方式
在C语言中,全局变量可以如全局函数那般在别的文件内使用,局部变量也可以具有全局变量相同的生命周期。
在前面的内容中,我们了解到内存分为动态内存和静态内存。其中动态内存属于临时内存,在使用前自动或手动分配,使用完成后进行释放。而静态内存属于常驻内存,由进程启动时分配,进程退出时进行释放。
动态内存一般应用在函数调用过程中,如函数内定义的变量、为指针变量动态分配内存。其中函数内定义的变量在函数执行时自动分配和释放,而动态分配内存则由我们手动编写代码分配和释放。
静态内存则存在进程执行期间,如函数外定义的全局变量、函数外定义的静态变量、函数内定义的静态变量。
接下来,我们通过变量的存储类别来了解不同内存中的变量定义方式。
auto:
在函数中定义变量时,如果在变量类型前指定auto存储类别,则表示这是一个自动变量。如auto int a;
【例8.3】 在函数中定义自动变量:
int main() {
auto int a;
int b;
return 0;
}
示例中,变量a和变量b都属于自动变量。
说明:
在函数内定义一个变量时,如果不指定变量储存类型,则默认这个变量是一个自动变量(auto存储类型)。
自动变量分配的是栈内空间,使用前初始化变量值是个良好的习惯(比如定义为int a = 0;或int a; a = 0;)。在DEBUG模式下,分配的栈内空间每个字节自动填充为0xCC。
register:
在函数中定义变量时,如果在变量类型前指定register存储类别,则表示这个变量优先存储在CPU内部寄存器(auto类型变量存储在栈内存)。如register int a;
【例8.4】 在函数中定义寄存器变量:
int main() {
register int a;
int b;
return 0;
}
变量a存储在CPU内部寄存器,不能获取变量a的地址(不能int *p = &a)。在变量寄存器都被占用的情况下,register变量还是存储在栈内存,但也不能获取变量的地址(编译时不能确定register变量在寄存器内还是在栈内)。
说明:
一般早期的C编译程序不会把变量保存在寄存器中,需要指定register储存 类别,才会考虑把变量保存在寄存器中。
随着编译程序设计的进步,现在的C编译环境可以更好的决定哪些变量应该被存在寄存器内,而不再需要手动指定为register存储类别。
static(静态局部变量):
在函数中定义变量时,如果在变量类型前指定static存储类别,则表示这个变量存储在静态区域。如static int a;
【例8.5】 在函数中定义静态局部变量:
void func() {
static int a;
printf(“a:%d\n”, ++a);
}
int main() {
func();
func();
return 0;
}
执行结果:
a:1
a:2
说明:
静态局部变量在编译时已确定内存区域及数值(在赋值的情况下),并在链接时更新其对应的汇编代码。另外,静态局部变量分配的是干净内存。如static int a;在使用之前已经自动初始化所占用内存区域为空内存(由数字0表示)。
static(静态全局变量):
在函数外定义变量时,如果在变量类型前指定static存储类别,则表示这个变量存储在静态区域。如static int a;
【例8.6】 在函数外定义静态全局变量:
static int a;
void func() {
printf(“a:%d\n”, ++a);
}
int main() {
func();
printf(“a:%d\n”, ++a);
return 0;
}
执行结果:
a:1
a:2
说明:
静态全局变量与静态局部变量在生命周期、初始化、后续赋值方面处理方式相同,但在作用域范围上存在差异。静态全局变量可以被本文件内的所有函数使用,而静态局部变量只能在所在函数内使用。
全局变量:
在函数外定义变量时,如果不指定存储类别,则表示这个变量是一个普通全局变量,与静态变量在生命周期、初始化、后续赋值方面处理方式相同。普通全局变量可以被所有文件内的所有函数使用,但只能存在一个实体(全局变量定义)。
【例8.7】 定义全局变量在多个文件内使用:
math.c代码:
int math_a;
int Add(int a)
{
return a + ++math_a;
}
math.h代码:
extern int math_a;
extern int Add(int a);
extern int Sub(int a);
math2.c代码:
#include “math.h”
int Sub(int a)
{
return a - --math_a;
}
main.c代码:
#include
#include “math.h”
int main() {
math_a = 4;
printf(“Add:%d\n”, Add(5));
printf(“Sub:%d\n”, Sub(5));
return 0;
}
程序编译:
gcc -o main math.c math2.c main.c
执行结果:
Add:10
Sub:1
说明:
这个程序由math.c、math.h、math2.c、main.c组成,其中math.h作为共有头文件使用。在程序中,math.h负责声明math.c和math2.c中的全局变量和全局函数,而在math2.c和main.c中引用了math.h文件。
这个程序看起来稍微有些复杂,我们来分析一下程序编译过程:
首先我们把math.c、math2.c、main.c分成三个不同模块编译,其中math.c只负责把全局math_a变量和全局Add函数编译成二进制数据;math2.c获取到math.h中的全局math_a变量、全局Add函数及全局Sub函数的形式声明并使用math_a变量,然后把全局Sub函数编译成二进制数据;而main.c函数获取到math.h中的全局math_a变量、全局Add函数及全局Sub函数的形式声明并使用这些变量和函数,然后把main函数编译成二进制数据。
它们直接关系可以看做:
math.c -> math.o // math.c编译成math.o二进制文件
math2.c <- math.h -> math2.o // math2.c获取到math.h中的内容然后编译成math2.o二进制文件
main.c <- math.h -> main.o // main.c获取到math.h中的内容然后编译成main.o二进制文件
main <- math.o <- math2.o <- main.o // 链接器从math.o、math2.o、main.o首先找到main函数定义并写入main文件,然后寻找main函数定义内用到的math_a变量并写入main文件,然后寻找main函数定义内用到的Add函数定义和Sub函数定义并写入main文件,至此main文件获取到了main函数执行所需的所有变量定义和函数定义可以正确执行了
进过上述分析,这个程序编译过程看起来就属于条理有序的执行。当然,实际编译时远比这复杂。比如math.c、math2.c、main.c编译过程中使用的math_a变量是个逻辑地址(0x0(%rip),也称为相对寻址),在链接时计算math_a变量实际信息,然后填充到调用函数内的math_a变量使用处。
C语言中,变量声明也是分为两种形式:一种是形式声明(在变量类型前指定extern关键字,上述所说的变量声明),另一种是实体声明(变量定义)。变量的形式声明不占用内存空间,它只是在程序编译时通知编译器有这么一个变量(比如int类型命名为math_a的变量)。程序链接时,编译器将在已有的二进制文件中寻找这个变量实体。
7. 函数的递归调用
在一个函数的执行过程中,如果又间接或直接的调用自身函数,那么这个调用过程属于函数的递归调用。
首先,分析函数的递归调用过程:
int func(int a);
int init(int a) { //初始化函数,为a值赋值为1
a = 1;
return func(a); //由init函数完成func函数的调用
}
int func(int a) {
if (0 >= a || 11 <= a) //当0大于等于a或11小于等于a时满足判断条件
return init(a); //通过init函数间接调用func函数
printf(“a:%d\n”, a);
if (10 > a) { //当10大于a时满足判断条件
return func(++a); //由func函数直接调用func函数,这里的返回值没有使用
}
printf(“res:%d\n”, a);
return a; //返回执行结果
}
int main() {
int res = func(1); //在main函数内调用func函数
printf(“main res:%d\n”, res);
}
执行结果:
a:1
a:2
a:3
a:4
a:5
a:6
a:7
a:8
a:9
a:10
res:10
main res:10
程序分析:
这个程序属于自增运算程序,展示从1自增到10的过程并返回最终结果10。程序的结构可以看做由四部分组成:调用函数、初始化参数(间接调用过程)、直接调用过程、返回结果。
调用函数:
在main函数内调用func函数,也可以理解为递归函数的起始调用位置。
初始化参数(间接调用过程):
首次执行func函数时,如果参数a满足初始化条件(参数a小于等于0或参数a大于等于11)将调用init函数(初始化函数),然后由init函数调用func函数并返回执行结果到func函数(main函数内的起始调用位置)。这个过程可以理解为间接调用过程,形式为:func ->(调用) init ->(调用) func ->(返回值) init ->(返回值) func。
当然,如果参数a不满足初始化条件(参数a大于等于1或参数a小于等于10)将不调用init函数(不执行间接调用过程)。
直接调用过程:
当参数 a大于等于1或参数a小于10时,首先自增1然后调用func函数(自身函数),一直到a等于10时返回执行结果10,并且在直接调用过程中产生的返回值没有使用。直接调用形式为:func ->(调用) func -> … ->(返回值) func。
返回结果:
当func函数内的参数a等于10时,已不再满足func函数内的判断条件,将直接返回结果10,然后反顺序退出所有被调用的函数。返回结果形式为:func(a=10) ->(返回) func(a=9) -> … ->(返回)func(a=10,main函数内的起始调用位置)。
关于返回值的问题为什么等于10,大家应该会有这个疑问。当然,这部分应用到了寄存器知识。在C函数中,由eax寄存器暂时保存返回值然后跳转到调用本函数的上一级函数位置,由于调用本身函数的关系,在跳转到上一级本身函数时不再向eax寄存器内写入返回值信息。也就是说,当同一个函数直接调用多次,最后一次执行结果写入eax寄存器后,只进行跳转到上一级本身函数而不再向eax寄存器写入值。
通过上述示例,我们可以了解到间接调用过程与直接调用过程存在着一些差别。
比如间接调用需要通过执行某个函数(比如init函数)然后再进行调用本身函数,而函数返回值首先返回到这个函数(比如init函数,需要获取eax寄存器内的返回值,然后储存init函数的返回值),然后由init函数返回执行结果。
直接调用属于再次或多次调用本身函数,而函数返回值是最后一次执行的返回结果(比如func函数,我们只需要最后一次执行写入eax寄存器的储存结果,而之前调用的返回值我们没有从eax寄存器内获取(没有用到)),返回过程中不再对eax寄存器赋值。
另外,如果一个函数中只存在直接调用方式(调用本身函数),可以称为递归函数。如果一个函数中既存在直接调用方式,也存在间接调用方式(本函数中调用别的函数,然后在这个函数中再次或多次调用本身函数,并以本身函数作为返回值使用)在大部分情况下也可以称为递归函数。
递归函数还有一个较为重要的因素,必须以合理的条件来停止函数无限制执行。如果递归函数设计不合理,可能会造成函数陷入循环执行状态并导致程序崩溃(栈内存分配超出限制,导致栈溢出)。
【例8.8】 递归调用方式实现左上三角形式,输出九九乘法口诀:
void multiplication(int i, int j)
{
if (9 >= i) {
if (9 >= j) {
printf("%d*%d=%2d “, i, j, i * j);
multiplication(i, ++j);
}
else {
++i;
j = i;
printf(”\n");
multiplication(i, j);
}
}
}
示例结果:
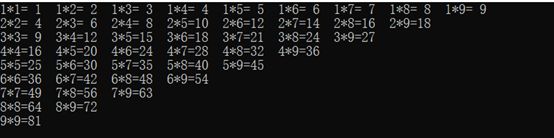
示例分析:
1. 使用递归方式替代循环结构,函数中i和j分别表示乘数(行数)和被乘数(行内输出)。
2. 当j小于等于9时,在当前行输出运算结果。当j大于9时,i自增1,然后j赋值为i,然后换到下一行开始位置输出运算结果。
3. 运算完成后,生成左上三角形。
目录预览
<一起学习C语言:C语言发展历程以及定制学习计划>
<一起学习C语言:初步进入编程世界(一)>
<一起学习C语言:初步进入编程世界(二)>
<一起学习C语言:初步进入编程世界(三)>
<一起学习C语言:C语言数据类型(一)>
<一起学习C语言:C语言数据类型(二)>
<一起学习C语言:C语言数据类型(三)>
<一起学习C语言:C语言基本语法(一)>
<一起学习C语言:C语言基本语法(二)>
<一起学习C语言:C语言基本语法(三)>
<一起学习C语言:C语言基本语法(四)>
<一起学习C语言:C语言基本语法(五)>
<一起学习C语言:C语言循环结构(一)>
<一起学习C语言:C语言循环结构(二)>
<一起学习C语言:C语言循环结构(三)>
<一起学习C语言:数组(一)>
<一起学习C语言:数组(二)>
<一起学习C语言:数组(三)>
<一起学习C语言:初谈指针(一)>
<一起学习C语言:初谈指针(二)>
<一起学习C语言:初谈指针(三)>
<一起学习C语言:函数(一)>
<一起学习C语言:函数(二)>