kubernetes系列之二十:Kubernetes Calico网络插件
一、前言
Calico作为Kubernetes的CNI插件可以支持underlay和overlay模式的网络互联;在BGP信息的交互方式上也同时支持中心服务方式和grid mesh方式;但是Calico的基于underlay路由的网络模式要求网络基础设施对于BGP协议要有支持,所以在私有数据中心进行部署是最佳场景。当然由于在AWS也有Kubernetes的部署,AWS的技术人员也提到过AWS的虚拟路由器对BGP是有支持的,但有待验证。
由于calico是基于三层的解决方案,所以不要求所有节点在同一个大二层之内(当然BGP模式还是要求数据中心内部中间节点的路由器都支持BGP协议),也不存在随着容器增加而带来的大量mac广播风暴,数据中心mac地址广播流量只和k8s节点数目有关,和容器的多少无关。
转载自https://blog.csdn.net/cloudvtech
二、Calico的基本架构

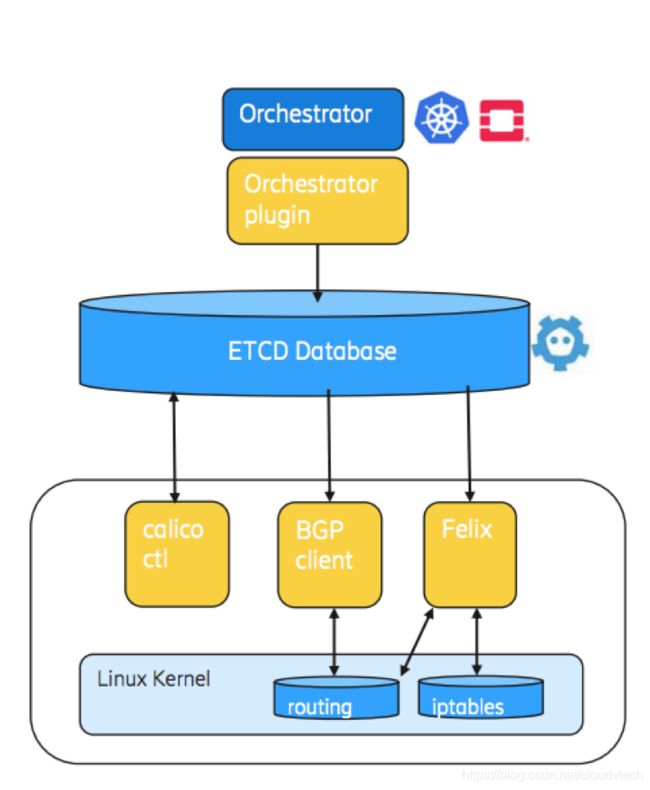
Calico的基本组件:
- Felix:运行在每个Calico节点上,根据容器的网络配置需求,配置Calico节点上的路由信息以及ACL等信息
- etcd:存储Calico控制面网络状态
- BIRD:将Felix维护的本地路由信息发放到Calico控制面网络中,保证跨节点的路由联通
- BGP Router Relfector:中心化的路由控制中心,大规模部署情况下可以由多个RR完成集中式路由管理和分发;跨机房部署也可以借助BGP RR进行集中式路由同步
Calico依赖etcd进行状态存储和管理,所以一个高可用的etcd集群是必须的前提条件。
转载自https://blog.csdn.net/cloudvtech
三、Calico的部署和配置
Calico在部署的时候通过Kubernetes Daemonset的方式在每个Kubernetes node上部署一个Calico POD,在POD内部运行基本组件:
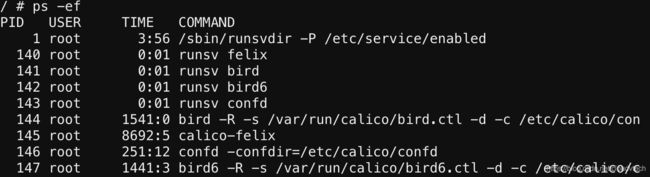
3.1 Calico工作模式及配置
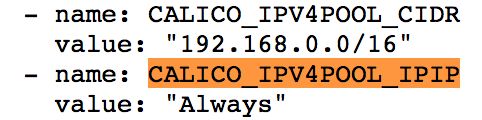
Calico主要有两种互联模式,一种是基于IPIP封装的overlay模式,另外一种是基于BGP路由的underlay模式。
有两种方式可以修改/配置Calico的工作模式,一种是在初始安装的时候在部署Calico Daemonset的时候,设定POD的环境变量如下:
另外一种方式是部署之后通过calicoctl进行更改:
calicoctl get ippool -o json > calico.config
修改里面的配置如下:
"ipipMode": "Always"
calicoctl apply -f calico.config
Calico的配置一部分是在部署Kubernetes Daemonset的yaml里面指定的,另一部分是在ConfigMap里面指定的:
# This ConfigMap is used to configure a self-hosted Calico installation. kind: ConfigMap apiVersion: v1 metadata: name: calico-config namespace: kube-system data: # The location of your etcd cluster. This uses the Service clusterIP # defined below. etcd_endpoints: "http://10.96.232.136:6666" # Configure the Calico backend to use. calico_backend: "bird" # The CNI network configuration to install on each node. cni_network_config: |- { "name": "k8s-pod-network", "cniVersion": "0.3.0", "plugins": [ { "type": "calico", "etcd_endpoints": "__ETCD_ENDPOINTS__", "log_level": "info", "mtu": 1500, "ipam": { "type": "calico-ipam" }, "policy": { "type": "k8s", "k8s_api_root": "https://__KUBERNETES_SERVICE_HOST__:__KUBERNETES_SERVICE_PORT__", "k8s_auth_token": "__SERVICEACCOUNT_TOKEN__" }, "kubernetes": { "kubeconfig": "/etc/cni/net.d/__KUBECONFIG_FILENAME__" } }, { "type": "portmap", "snat": true, "capabilities": {"portMappings": true} } ] }
3.2 IPIP Tunnel模式
IPIP模式在每个node上创建一个tunnel接口,所有目标是集群内部其他节点的流量,都是经由tunnel接口进行封装、转发、解封、送达;而节点自身的正常的流量和容器到外部的流量都经过主机的网卡。

这种模式的优点在于对下层网络环境无依赖,节点可以跨网络分布,缺点在于存在封包和解包过程,导致性能下降。
3.3 BGP Routing模式
这种模式下,每个节点主机被calico配置为一个虚拟路由器,负责将本主机上面的路由信息汇聚并且以BGP协议的形式向其他节点和网络发送路由信息:

这种模式的优点在于无overlay模式的封包和解包过程,可以接近主机native的性能;缺点在于要求网络联通的路由器支持BGP协议,并且由于这种方式随着节点数目的增加,路由表的数目也会大量增加,更适合中小规模部署。如需大规模部署BGP模式的Calico,则可以通过额外的BGP route reflector来完成。每个BGP RR负责一部分节点的接入,然后多个BGP RR之间再交互信息来达到整个网路路由信息的集中式分发。
美图的容器云就使用这个大规模部署方案:
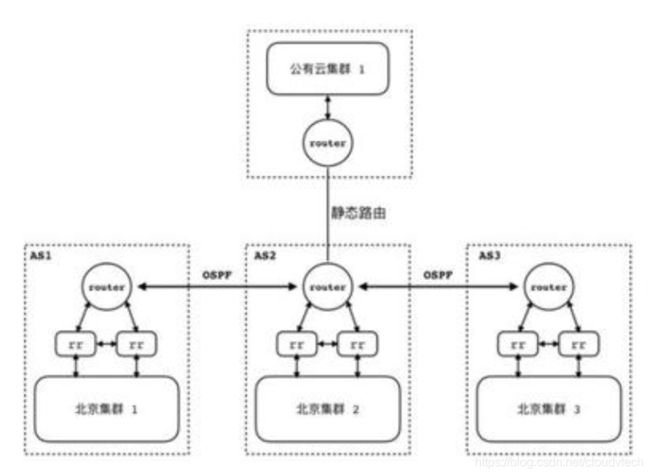
每个机房作为一个 AS 部署一个 Kubernetes 集群,机房内部冗余有多个 BGP RR,各个AS的BPG RR 分别与机房内的网关建立 iBGP 连接,机房间的路由器通过 OSPF 同步彼此之间的路由。而对于混合云的场景,机房网关上配置相应网段的静态路由规则,同时在云端路由上也配置上相应路由规则进行打通。
3.4 BGP协议路由更新
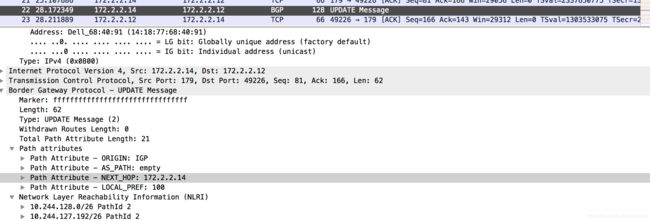
在下面的例子中,一共有172.2.2.11/12/13/14四个node使用BGP模式进行互联,当172.2.2.14上的calico POD重启之后,172.2.2.12和172.2.2.14会通过BGP协议来交换自己所持有的路由信息:
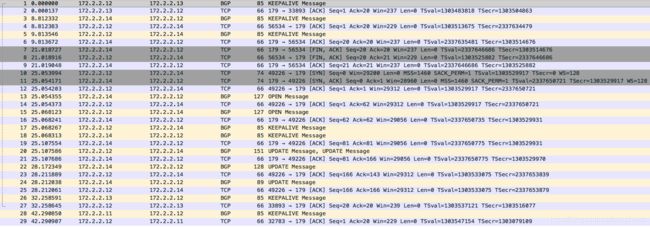
172.2.2.12到172.2.2.14的BGP信息(包含子网10.244.44.192/26和10.244.45.0/26):
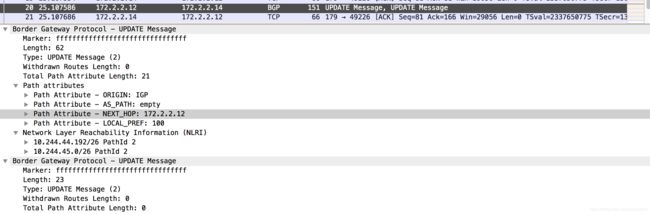
172.2.2.14到172.2.2.12的BGP信息(包含子网10.244.128.0/26和10.244.127.192/26):
转载自https://blog.csdn.net/cloudvtech