九、ElasticSearch——文档管理&路由详解(新建,修改,删除,查询,批量操作,重索引,refresh参数,路由详解)
一、文档管理
1 新建文档

2查询文档
(1)获取单个文档

(2)获取多个文档 _mget
请求参数_source stored_fields 可以用在url上也可用在请求json串中
GET /_mget
{
"docs" : [
{
"_index" : "twitter",
"_type" : "_doc",
"_id" : "1"
},
{
"_index" : "twitter",
"_type" : "_doc",
"_id" : "2"
"stored_fields" : ["field3", "field4"]
}
]
}
GET /twitter/_mget
{
"docs" : [
{
"_type" : "_doc",
"_id" : "1"
},
{
"_type" : "_doc",
"_id" : "2"
}
]
}
GET /twitter/_doc/_mget
{
"docs" : [
{
"_id" : "1"
},
{
"_id" : "2"
}
]
}
GET /twitter/_doc/_mget
{
"ids" : ["1", "2"]
}
3 删除文档
DELETE twitter/_doc/1 指定文档id进行删除
DELETE twitter/_doc/1?version=1 用版本来控制删除
{
“_shards” : {
“total” : 2,
“failed” : 0,
“successful” : 2
},
“_index” : “twitter”,
“_type” : “_doc”,
“_id” : “1”,
“_version” : 2,
“_primary_term”: 1,
“_seq_no”: 5,
“result”: “deleted”
}
查询删除
POST twitter/_delete_by_query
{
“query”: {
“match”: {
“message”: “some message”
}
}
}
POST twitter/_doc/_delete_by_query?conflicts=proceed 当有文档有版本冲突时,不放弃删除操作(记录冲突的文档,继续删除其他复合查询的文档)
{
“query”: {
“match_all”: {}
}
}
通过task api 来查看 查询删除任务
GET _tasks?detailed=true&actions=*/delete/byquery
GET /_tasks/taskId:1 查询具体任务的状态
POST _tasks/task_id:1/_cancel 取消任务
{
“nodes” : {
“r1A2WoRbTwKZ516z6NEs5A” : {
“name” : “r1A2WoR”,
“transport_address” : “127.0.0.1:9300”,
“host” : “127.0.0.1”,
“ip” : “127.0.0.1:9300”,
“attributes” : {
“testattr” : “test”,
“portsfile” : “true”
},
“tasks” : {
“r1A2WoRbTwKZ516z6NEs5A:36619” : {
“node” : “r1A2WoRbTwKZ516z6NEs5A”,
“id” : 36619,
“type” : “transport”,
“action” : “indices:data/write/delete/byquery”,
“status” : {
“total” : 6154,
“updated” : 0,
“created” : 0,
“deleted” : 3500,
“batches” : 36,
“version_conflicts” : 0,
“noops” : 0,
“retries”: 0,
“throttled_millis”: 0
},
“description” : “”
} } } }}
4 更新文档
(1)指定文档id进行修改
PUT twitter/_doc/1
{
“id”: 1,
“user” : “kimchy”,
“post_date” : “2009-11-15T14:12:12”,
“message” : “trying out Elasticsearch”
}
(2)乐观锁并发更新控制(加版本)
PUT twitter/_doc/1?version=1
{
“id”: 1,
“user” : “kimchy”,
“post_date” : “2009-11-15T14:12:12”,
“message” : “trying out Elasticsearch”
}
{
“_index”: “twitter”,
“_type”: “_doc”,
“_id”: “1”,
“_version”: 3,
“result”: “updated”,
“_shards”: {
“total”: 3,
“successful”: 1,
“failed”: 0
},
“_seq_no”: 2,
“_primary_term”: 3
}
(3)Scripted update 通过脚本来更新文档
a)准备一个文档
PUT uptest/_doc/1
{
“counter” : 1,
“tags” : [“red”]
}
b ) 对文档1的counter + 4
POST uptest/_doc/1/_update
{
“script” : {
“source”: “ctx._source.counter += params.count”,
“lang”: “painless”,
“params” : {
“count” : 4
}
}
}
c) 往数组中加入元素
POST uptest/_doc/1/_update
{
“script” : {
“source”: “ctx._source.tags.add(params.tag)”,
“lang”: “painless”,
“params” : {
“tag” : “blue”
}
}
}
脚本说明:painless是es内置的一种脚本语言,ctx执行上下文对象(通过它还可访问_index, _type, _id, _version, _routing and _now (the current timestamp) ),params是参数集合
Scripted update 通过脚本来更新文档
说明:==脚本更新要求索引的_source 字段是启用的。==更新执行流程:
1)获取到原文档
2)通过_source字段的原始数据,执行脚本修改。
3)删除原索引文档
4)索引修改后的文档
它只是降低了一些网络往返,并减少了get和索引之间版本冲突的可能性。
POST uptest/_doc/1/_update 添加一个字段
{
“script” : “ctx._source.new_field = ‘value_of_new_field’”
}
POST uptest/_doc/1/_update 移除一个字段
{
“script” : “ctx._source.remove(‘new_field’)”
}
POST uptest/_doc/1/_update 判断删除或不做什么
{
“script” : {
“source”: “if (ctx._source.tags.contains(params.tag)) { ctx.op = ‘delete’ } else { ctx.op = ‘none’ }”,
“lang”: “painless”,
“params” : {
“tag” : “green”
}
}
}
(4)合并传入的文档字段进行更新
POST uptest/_doc/1/_update
{
“doc” : {
“name” : “new_name”
}
}
{
“_index”: “uptest”, 再次执行,更新内容相同,不需做什么
“_type”: “_doc”,
“_id”: “1”,
“_version”: 4,
“result”: “noop”,
“_shards”: {
“total”: 0,
“successful”: 0,
“failed”: 0
}
}
POST uptest/_doc/1/_update 设置不做noop检测
{
“doc” : {
“name” : “new_name”
},
“detect_noop”: false
}
(5)upsert 操作:如果要更新的文档存在,则执行脚本进行更新,如不存在,则把 upsert中的内容作为一个新文档写入。
POST uptest/_doc/1/_update
{
“script” : {
“source”: “ctx._source.counter += params.count”,
“lang”: “painless”,
“params” : {
“count” : 4
}
},
== “upsert”== : {
"counter" : 1
}
}
(6)查询更新
通过条件查询来更新文档
POST twitter/_update_by_query
{
“script”: {
“source”: “ctx._source.likes++”,
“lang”: “painless”
},
“query”: {
“term”: {
“user”: “kimchy”
}
}
}
5 批量操作
(1)批量操作API /_bulk
让我们可以在一次调用中执行多个索引、删除操作。这可以大大提高索引数据的速度。批量操作内容体需按如下以新行分割的json结构格式给出:

action_and_meta_data: action可以是 index, create, delete and update ,meta_data 指: _index ,_type,_id
请求端点可以是: /_bulk, /{index}/_bulk, {index}/{type}/_bulk
(2)curl + json 文件 批量索引多个文档
curl -H “Content-Type: application/json” -XPOST “localhost:9200/bank/_doc/_bulk?pretty&refresh” --data-binary “@accounts.json”
curl “localhost:9200/_cat/indices?v”
6 reindex 重索引
Reindex API /_reindex 让我们可以将一个索引中的数据重索引到另一个索引中(拷贝),要求源索引的_source 是开启的。目标索引的setting 、mapping 信息与源索引无关。
POST _reindex
{
“source”: {
“index”: “twitter”
},
“dest”: {
“index”: “new_twitter”
}
}
重索引要考虑的一个问题:目标索引中存在源索引中的数据,这些数据的version如何处理。
(1) 如果没有指定version_type 或指定为 internal,则会是采用目标索引中的版本,重索引过程中,执行的就是新增、更新操作。
POST _reindex
{
“source”: {
“index”: “twitter”
},
“dest”: {
“index”: “new_twitter”,
“version_type”: “internal”
}
}
reindex 重索引
(2) 如果想使用源索引中的版本来进行版本控制更新,则设置 version_type 为extenal。重索引操作将写入不存在的,更新旧版本的数据。
POST _reindex
{
“source”: {
“index”: “twitter”
},
“dest”: {
“index”: “new_twitter”,
“version_type”: “external”
}
}
(3)如果只想从源索引中复制目标索引中不存在的文档数据,可以指定 op_type 为 create 。此时存在的文档将触发 版本冲突(会导致放弃操作),可设置“conflicts”: “proceed“,跳过继续
POST _reindex
{
“conflicts”: “proceed”,
“source”: {
“index”: “twitter”
},
“dest”: {
“index”: “new_twitter”,
“op_type”: “create”
}
}
(4)也可以只索引源索引的一部分数据,通过 type 或 查询来指定你需要的数据
POST _reindex
{
“source”: {
“index”: “twitter”,
“type”: “_doc”,
“query”: {
“term”: {
“user”: “kimchy”
}
}
},
“dest”: {
“index”: “new_twitter”
}
}
(5)可以从多个源获取数据
POST _reindex
{
“source”: {
“index”: [“twitter”, “blog”],
“type”: ["_doc", “post”]
},
“dest”: {
“index”: “all_together”
}
}
reindex 重索引其他操作



7 ?refresh参数
对于索引、更新、删除操作如果想操作完后立马重刷新可见,可带上refresh参数。
PUT /test/_doc/1?refresh
{“test”: “test”}
PUT /test/_doc/2?refresh=true
{“test”: “test”}
refresh 可选值说明
(1)未给值或=true,则立马会重刷新读索引。
(2)=false ,相当于没带refresh 参数,遵循内部的定时刷新。
(3)=wait_for ,登记等待刷新,当登记的请求数达到index.max_refresh_listeners 参数设定的值时(defaults to 1000),将触发重刷新。
二、路由详解
集群组成
(1)第一个节点启动作为master节点

在master节点存储集群元信息(图中的蓝色部分)
Cluster-name:ess(集群名字)
Nodes:
node1 10.0.1.11 master(集群的节点信息:节点名 节点IP 角色)
(2)Node2启动:给master发消息

集群元信息(发生改变)
Cluster-name:ess
Nodes:
node1 10.0.1.11 master
node2 10.0.1.12
Node2的配置:
Cluster-name:ess
discovery.zen.ping.unicast.hosts: [“10.0.1.11",“10.0.1.12"] 单波方式
networ.host: 10.0.1.12
(3)主节点给节点2发信息,节点2存储元信息
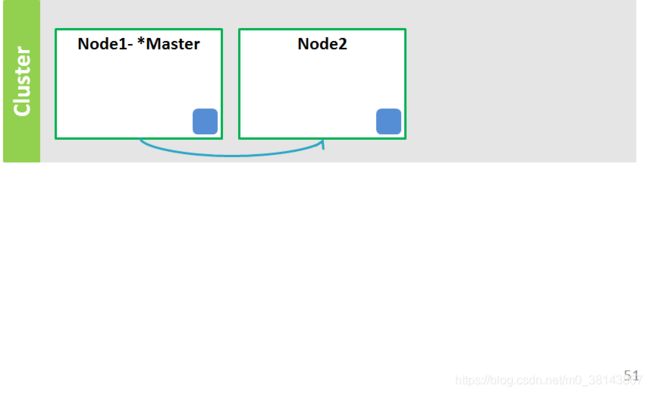
集群元信息
Cluster-name:ess
Nodes:
node1 10.0.1.11 master
node2 10.0.1.12
(4)Node3…NodeN加入:元信息发生改变
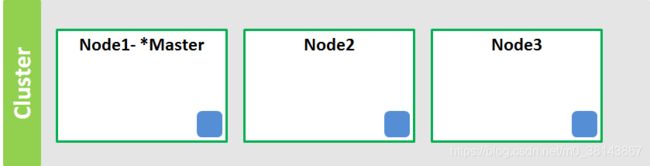
集群元信息
Cluster-name:ess
Nodes:
node1 10.0.1.11 master
node2 10.0.1.12
node3 10.0.1.13
(5)创建索引的流程
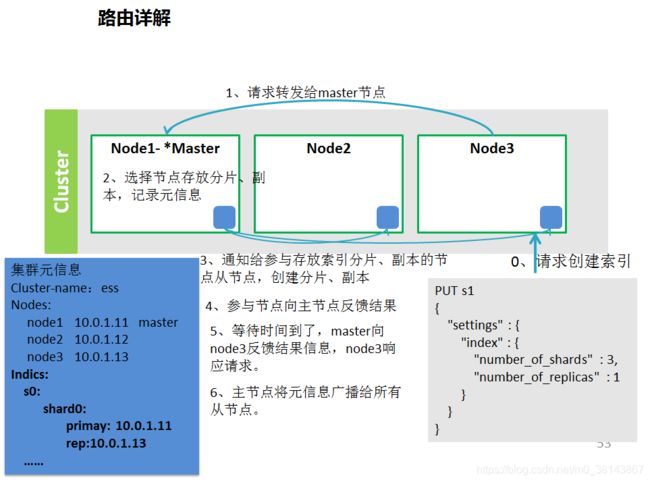
发送创建索引请求—其他节点没有权限,发给主节点—主节点创建存储的元信息(索引名,分片,主分片、备份分片的IP)–主节点根据元信息通知其他节点创建分片、副本—参与的节点反馈结果–等待时间到了,master向接收用户请求的节点反馈结果,用户收到返回结果–master节点广播元信息到所有从节点
有索引的集群

集群元信息
Cluster-name:ess
Nodes:
node1 10.0.1.11 master
node2 10.0.1.12
node3 10.0.1.13
Indics:
s0:
shard0:
primay: 10.0.1.11
rep:10.0.1.13
……
脑裂问题解决:设置master存储数据,只负责管理元信息,这样master不会因为过于繁忙而长时间无法响应而导致的重新选举产生脑裂
(6)节点故障

集群元信息
Cluster-name:ess
Nodes:
node1 10.0.1.11 master挂了
node2 10.0.1.12 master
node3 10.0.1.13
Indics:
s0:
shard0:
primay: 10.0.1.12
rep:10.0.1.13
……
1)主节点挂了,会重新选举一个master,主节点数据丢了,从备份的数据中拷贝一份放到新的节点(最终如上图所示)
2)从节点挂了,从备份的数据中拷贝一份放到新的节点
如果故障节点又恢复了(会不会多一份数据):会对比数据的版本信息,会把其他节点的最新版本的数据均衡的移入故障节点
(7)索引文档
请求Node2来索引一个文档

索引文档的步骤:
1)node2计算文档的路由值得到文档存放的分片(假定路由选定的是分片0)。
2)将文档转发给分片0的主分片节点 node1。
3)node1索引文档,同步给副本节点node3索引文档。
4)node1向node2反馈结果
5)node2作出响应
(8)文档是如何路由的
文档该存到哪个分片上?
决定文档存放到哪个分片上就是文档路由。ES中通过下面的计算得到每个文档的存放分片:根据文档id进行hash分片
shard = hash(routing) % number_of_primary_shards
routing 是用来进行hash计算的路由值,默认是使用文档id值。
也可以在索引文档时通过routing参数指定别的路由值
POST twitter/_doc?routing=kimchy
{
“user” : “kimchy”,
“post_date” : “2009-11-15T14:12:12”,
“message” : “trying out Elasticsearch”
}
在索引、删除、更新、查询中都可以使用routing参数(可多值)指定操作的分片。
PUT my_index2
{
“mappings”: {
“_doc”: {
“_routing”: {
“required”: true 强制要求给定路由值
}
}
}
}
思考:关系型数据库中有分区表(根据时间分区,根据部门分区),通过选定分区,可以降低操作的数据量,提高效率。在ES的索引中能不能这样做?
可以:通过指定路由值,让一个分片上存放一个区的数据。如按部门存放数据,则可指定路由值为部门值,不同部门存放到不同分片(存储有规律,可以提高查询效率)。
(9)搜索流程
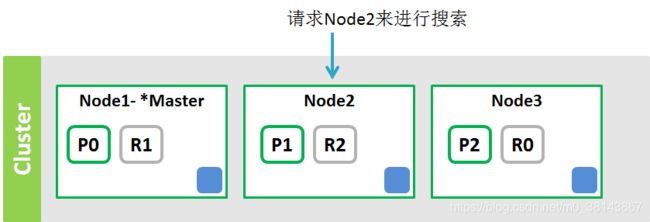
搜索的步骤:如要搜索 索引 s1
1、node2解析查询。
2、node2将查询发给索引s1的分片/副本(R1,R2,R0)节点
3、各节点执行查询,将结果发给Node2
4、Node2合并结果,作出响应。