Elasticsearch 聚合搜索技术深入
Elasticsearch 聚合搜索技术深入
- 一. bucket和metric概念简介
- 二. 聚合统计案例
-
- 2.1 分组统计数量
- 2.2 多层嵌套聚合
- 2.3 统计最大、最小值以及总和
- 2.4 分组后,对组内的数据进行排序,只取前几条数据
- 2.5 histogram 区间统计
- 2.6 date_histogram 区间分组
- 2.7 global bucket
- 2.8 aggs order
- 2.9 search aggs
- 2.10 filter+aggs
- 2.11 在aggs中使用filter
- 2.12 去除重复 cardinality
- 2.13 百分比算法
- 2.14 percentile_ranks - SLA统计
- 2.15 优化percentiles和percentiles_ranks(TDigest算法)
- 2.16 正排索引与聚合分析的内部原理
- 2.17 doc values特征总结
- 2.18 使用fielddata处理text类型字段的聚合分析
-
- 2.18.1 fielddata特征总结
- 2.18.2 内存控制
- 2.18.3 fielddata 内存监控命令
- 2.18.4 circuit breaker 短路器
- 2.18.5 fielddata的filter过滤器
- 2.18.6 fielddata的预加载
- 2.19 海量bucket优化机制
- 三. 聚合算法简介
-
- 3.1 易并行聚合算法
- 3.2 近似聚合算法
- 3.3 三角选择原则
| 序号 | 内容 | 链接地址 |
|---|---|---|
| 1 | SpringBoot整合Elasticsearch7.6.1 | https://blog.csdn.net/miaomiao19971215/article/details/105106783 |
| 2 | Elasticsearch Filter执行原理 | https://blog.csdn.net/miaomiao19971215/article/details/105487446 |
| 3 | Elasticsearch 倒排索引与重建索引 | https://blog.csdn.net/miaomiao19971215/article/details/105487532 |
| 4 | Elasticsearch Document写入原理 | https://blog.csdn.net/miaomiao19971215/article/details/105487574 |
| 5 | Elasticsearch 相关度评分算法 | https://blog.csdn.net/miaomiao19971215/article/details/105487656 |
| 6 | Elasticsearch Doc values | https://blog.csdn.net/miaomiao19971215/article/details/105487676 |
| 7 | Elasticsearch 搜索技术深入 | https://blog.csdn.net/miaomiao19971215/article/details/105487711 |
| 8 | Elasticsearch 聚合搜索技术深入 | https://blog.csdn.net/miaomiao19971215/article/details/105487885 |
| 9 | Elasticsearch 内存使用 | https://blog.csdn.net/miaomiao19971215/article/details/105605379 |
| 10 | Elasticsearch ES-Document数据建模详解 | https://blog.csdn.net/miaomiao19971215/article/details/105720737 |
一. bucket和metric概念简介
bucket: 又被称作桶,满足特定条件的文档集合,可以看作是一个数据分组。聚合开始后,Elasticsearch会根据文档的值计算出文档究竟符合哪个桶,如果匹配,则将文档放入相应的桶。当所有的文档都经过计算后,再分别对每个桶进行聚合操作。
metric: 又被称作指标,对桶内的文档进行进行聚合分析操作,操作有若干种类别,如:求和、最大值、最小值、平均值等,通过对桶内文档进行相应的操作,我们可以得到想要的指标。
二. 聚合统计案例
准备数据:
PUT /cars
{
"mappings": {
"properties": {
"price": {
"type": "long"
},
"color": {
"type": "keyword"
},
"brand": {
"type": "keyword"
},
"model": {
"type": "keyword"
},
"sold_date": {
"type": "date"
},
"remark" : {
"type" : "text",
"analyzer" : "ik_max_word"
}
}
}
}
POST /cars/_bulk
{
"index": {
}}
{
"price" : 258000, "color" : "金色", "brand":"大众", "model" : "大众迈腾", "sold_date" : "2017-10-28","remark" : "大众中档车" }
{
"index": {
}}
{
"price" : 123000, "color" : "金色", "brand":"大众", "model" : "大众速腾", "sold_date" : "2017-11-05","remark" : "大众神车" }
{
"index": {
}}
{
"price" : 239800, "color" : "白色", "brand":"标志", "model" : "标志508", "sold_date" : "2017-05-18","remark" : "标志品牌全球上市车型" }
{
"index": {
}}
{
"price" : 148800, "color" : "白色", "brand":"标志", "model" : "标志408", "sold_date" : "2017-07-02","remark" : "比较大的紧凑型车" }
{
"index": {
}}
{
"price" : 1998000, "color" : "黑色", "brand":"大众", "model" : "大众辉腾", "sold_date" : "2017-08-19","remark" : "大众最让人肝疼的车" }
{
"index": {
}}
{
"price" : 218000, "color" : "红色", "brand":"奥迪", "model" : "奥迪A4", "sold_date" : "2017-11-05","remark" : "小资车型" }
{
"index": {
}}
{
"price" : 489000, "color" : "黑色", "brand":"奥迪", "model" : "奥迪A6", "sold_date" : "2018-01-01","remark" : "政府专用?" }
{
"index": {
}}
{
"price" : 1899000, "color" : "黑色", "brand":"奥迪", "model" : "奥迪A 8", "sold_date" : "2018-02-12","remark" : "很贵的大A6。。。" }
2.1 分组统计数量
只是简单的对数据进行聚合分组,计算每组中元素的个数,不做复杂的聚合统计。在ES中,最基础的聚合就是terms,相当于SQL中的count。ES内默认会参考doc_count值,也就是参考_count元数据,根据每组元素的个数,执行降序排列,我们也可以根据_key元数据进行排序,_key指的是用来分组的字段对应的值(字典顺序)。 terms不支持多字段聚合分组,原因在于多字段聚合分组,其实就是在一个聚合分组的基础上再次执行聚合分组,terms无法统计组内的元素个数。
举例: 在cars索引中根据color统计车辆的销量情况,并按照元素个数进行倒序排序。
GET /cars/_search
{
"size":0,
"aggs": {
"group_by_color_mmr": {
"terms": {
"field": "color",
"order": {
"_count": "desc"
}
}
}
}
}
得到的结果为:
"aggregations" : {
"group_by_color_mmr" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "黑色",
"doc_count" : 3
},
{
"key" : "白色",
"doc_count" : 2
},
{
"key" : "金色",
"doc_count" : 2
},
{
"key" : "红色",
"doc_count" : 1
}
]
}
如果使用_key进行排序,实际上就是在对"黑色"、“白色”、“金色”、"红色"这几个单词进行排序。
2.2 多层嵌套聚合
先根据color进行分组,在此基础之上,再对组内的元素针对brand进行分组,最后再通过price进行聚合统计,计算出每组品牌车辆的平均价格。嵌套多层聚合的手法可以实现多字段聚合。但在多层嵌套聚合时,需要注意不得非直系亲属的聚合字段进行排序。多次嵌套聚合的方式又被称作下钻分析,而水平定义就是在同一层指定多个分组方式,具体语法如下:
GET /index_name/type_name/_search
{
"aggs" : {
"定义分组名称(最外层)": {
"分组策略如:terms、avg、sum": {
"field" : "根据哪一个字段分组",
"其他参数" : ""
},
"aggs" : {
"分组名称1" : {
},
"分组名称2" : {
}
}
}
}
}
请看下面这个例子:
GET cars/_search
{
"size": 0,
"aggs": {
"group_by_color": {
"terms": {
"field": "color",
"order": {
"_key": "desc"
}
},
"aggs": {
"avg_by_price_color": {
"avg": {
"field": "price"
}
},
"group_by_brand": {
"terms": {
"field": "brand",
"order": {
"avg_by_price": "desc"
}
},
"aggs": {
"avg_by_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
}
}
可以使用别的聚合字段作为当前分组bucket的排序依据,但是一定不能跨代。比如group_by_color中不能使用avg_by_price进行排序,因为已经隔了1代,不再是"直系亲属"的关系了。如果强行使用,会报错:
“Invalid aggregator order path [avg_by_price]. The provided aggregation [avg_by_price] either does not exist, or is a pipeline aggregation and cannot be used to sort the buckets.”
无效的聚合排序字段[avg_by_price]. 打算用来排序的[avg_by_price]字段要么不存在,要么是管道聚合,不能被当前分组(bucket)用来排序。
2.3 统计最大、最小值以及总和
举例,统计不同color中车辆价格的最大值、最小值以及价格总和。
GET cars/_search
{
"size": 0,
"aggs": {
"group_by_color": {
"terms": {
"field": "color",
"order": {
"_count": "desc"
}
},
"aggs": {
"max_price": {
"max": {
"field": "price"
}
},
"min_price": {
"min": {
"field": "price"
}
},
"sum_price": {
"sum": {
"field": "price"
}
}
}
}
}
}
2.4 分组后,对组内的数据进行排序,只取前几条数据
分组后,可能需要对组内的数据进行排序,并选择其中排名较高的数据,那么可以使用top_hits来实现。top_hits中的属性size代表每组中需要展示多少条数据(默认10条),sort代表组内使用什么字段和规则进行排序(默认使用_doc的asc规则),_source代表结果中包含document中的哪些字段(默认包含全部字段)。
注意: _doc指的是数据真正存储到ES中的顺序,不一定是插入数据的顺序,这个元数据字段由ES来维护。
对车辆品牌分组,为每组中的车辆根据价格倒序排序,只取价格最高的那一台车辆,并展示车辆的型号和价格。
GET cars/_search
{
"size" : 0,
"aggs": {
"group_by_brand": {
"terms": {
"field": "brand"
},
"aggs": {
"top_car": {
"top_hits": {
"size": 1,
"sort": [
{
"price": {
"order": "desc"
}
}
],
"_source": {
"includes": ["model", "price"]
}
}
}
}
}
}
}
2.5 histogram 区间统计
如果说terms是通过某个字段进行分组,那么histogram就是按照给定的区间进行分组。
比如以100万为一个区间间隔,统计不同范围内车辆的销售量和平均价格。那么在使用histogram时,field指定为price,区间范围是100万,此时ES会将price划分成若干区间: [0,10000000),[10000000, 20000000)等等,依此类推,histogram和terms一样,也会统计每个区间内数据的数量,也允许嵌套aggs实现其它聚合统计操作。
GET cars/_search
{
"size" : 0,
"aggs": {
"histogram_by_price": {
"histogram": {
"field": "price",
"interval": 1000000
},
"aggs": {
"avg_by_price": {
"avg": {
"field": "price"
}
},
"max_by_price": {
"max": {
"field": "price"
}
}
}
}
}
}
2.6 date_histogram 区间分组
data_histogram用于对date类型的field进行分组,比如每年的销量、每个月的销量统计。
data_histogram包含以下属性字段:
- field: 指定用于聚合分组的字段 必填。
- interval: 指定区间范围 必填,可选值有: year, quarter, month, week, day, hour, minute, second。
- format: 指定日期的格式化方式 如 yyyy-MM-dd 可选填,默认值为 yyyy-MM-dd HH:mm:ss.fff
- min_doc_count: 指定每个区间至少需要包含document的数量,可选填,默认为0,也即,会显示不包含document的bucket分组。
- extended_bounds: 指定起始时间和结束时间,可选填,默认为所有文档中该字段的最小值所在范围的起始时间到最大值所在范围的结束时间。比如index中date类型字段值最小和最大值分别是: {"_id": “1”, “date_field”: “2019-08-10”}和{"_id": “666”, “2020-04-06”},则extends_bound的默认值为 2019-08-01 ~ 2020-04-30。
GET cars/_search
{
"size": 0,
"aggs": {
"histogram)by_date": {
"date_histogram": {
"field": "sold_date",
"interval": "month",
"min_doc_count": 1,
"format": "yyyy-MM-dd",
"extended_bounds": {
"min": "2017-01-01",
"max": "2020-04-06"
}
},
"aggs": {
"sum_by_price": {
"sum": {
"field": "price"
}
}
}
}
}
}
如果min_doc_count等于0或不设置,将会把不含元素的bucket也展示出来,结果如下:
"aggregations" : {
"histogram)by_date" : {
"buckets" : [
{
"key_as_string" : "2017-01-01",
"key" : 1483228800000,
"doc_count" : 0,
"sum_by_price" : {
"value" : 0.0
}
},
{
"key_as_string" : "2017-02-01",
"key" : 1485907200000,
"doc_count" : 0,
"sum_by_price" : {
"value" : 0.0
}
},
{
"key_as_string" : "2017-03-01",
"key" : 1488326400000,
"doc_count" : 0,
"sum_by_price" : {
"value" : 0.0
}
},
...
2.7 global bucket
在聚合统计时,有时需要需要对比部分数据和总体数据。global用于定义一个全局的bucket,这个bucket分组会忽略query条件,在所有的document中进行聚合统计,写法: “global”: {}
举例,统计大众品牌下的车辆平均价格和所有车辆车辆的平均价格。
GET cars/_search
{
"size": 0,
"query": {
"match": {
"brand": "大众"
}
},
"aggs": {
"dazhong_avg_price": {
"avg": {
"field": "price"
}
},
"all_avg_price": {
"global": {
},
"aggs": {
"all_of_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
得到的结果如下:
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"dazhong_avg_price" : {
"value" : 793000.0
},
"all_avg_price" : {
"doc_count" : 8,
"all_of_price" : {
"value" : 671700.0
}
}
}
2.8 aggs order
对聚合统计的数据进行排序。默认情况下,一般是根据聚合统计的doc_value和key联合实现排序的,其中doc_value降序,而key升序。
如果有多层aggs,那么在执行下钻聚合时,也可以根据子代的聚合数据实现排序,注意,一定不要跨组排序。
GET /cars/_search
{
"aggs": {
"group_by_brand": {
"terms": {
"field": "brand"
},
"aggs": {
"group_by_color": {
"terms": {
"field": "color",
"order": {
"sum_of_price": "desc"
}
},
"aggs": {
"sum_of_price": {
"sum": {
"field": "price"
}
}
}
}
}
}
}
}
2.9 search aggs
search搜索相当于sql中的where条件,aggs相当于group,显然这两个语法使可以结合起来使用的。
比如: 搜索"大众"品牌中,每个季度的销售量和销售总额。
GET cars/_search
{
"query": {
"match": {
"brand": "大众"
}
},
"aggs": {
"date_of_group": {
"date_histogram": {
"field": "sold_date",
"format": "yyyy-MM-dd",
"calendar_interval": "quarter",
"min_doc_count": 1,
"order": {
"_count": "desc"
}
},
"aggs": {
"sum_by_price": {
"sum": {
"field": "price"
}
}
}
}
}
}
2.10 filter+aggs
filter可以和aggs连用,实现相对复杂的过滤聚合分析。
比如,统计售价在10~50万之间的车辆的平均价格。
GET cars/_search
{
"query": {
"constant_score": {
"filter": {
"range": {
"price": {
"gte": 100000,
"lte": 500000
}
}
}
}
},
"aggs": {
"avg_by_price": {
"avg": {
"field": "price"
}
}
}
}
2.11 在aggs中使用filter
filter可以写在aggs中,能够实现在query搜索的范围内进行过滤后,再执行聚合操作。filter的范围决定了聚合的范围。
比如,统计"大众"品牌汽车最近一年的销售总额。 now是ES的内部变量,代表当前时间, y对应年,M对应月,d对应日。(yyyy-MM-dd HH:mm:ss 有需要自己对应着往上套用)
GET cars/_search
{
"query": {
"match": {
"brand": "大众"
}
},
"aggs": {
"filter_sold_date": {
"filter": {
"range": {
"sold_date": {
"gte": "now-3y"
}
}
},
"aggs": {
"sum_price": {
"sum": {
"field": "price"
}
}
}
}
}
}
2.12 去除重复 cardinality
在ES中,如果需要去重重复,可以使用cardinality,类似sql中的distinct。
比如,统计每年销售的汽车的品牌数量。
GET cars/_search
{
"size": 0,
"aggs": {
"group_by_date": {
"date_histogram": {
"field": "sold_date",
"format": "yyyy-MM-dd",
"interval": "year",
"min_doc_count": 1
},
"aggs": {
"count_of_brand": {
"cardinality": {
"field": "brand"
}
}
}
}
}
}
cardinality有一定的错误率,它的执行性能非常高,一般都在100毫秒以内(不用考虑数据量级),其错误率也可以通过参数来进行控制。
cardinality语法中可以增加precision_threshold,这个参数用于定义去除重复字段中unique value的数量,默认值为100。
比如现在有50万台车,希望通过brand(品牌)进行去重。如果把precision_threshold设置成100,则代表最多有100个不同的品牌。若真实情况下不同品牌的数量不超过100,则去重后计算出的结果几乎不会有任何误差。(反之,超过的越多则误差越大)
cardinality算法会占用一定的内存空间,占用空间的大小大致参考以下公式:
占用的内存空间 = precision_threshold * 8(Byte)
根据公式,上述案例中,cardinality算法占用的空间大小为: 100 * 8 = 800个字节。我们可以根据真实服务器的配置来调整precision_threshold,这个数值的取值范围是0~40000,超过40000则按照40000来处理。(因此,不能为了避免误差,盲目的填写precision_threshold)
经官方测试,当precision_threshold=100,对应过滤字段的unique value的数量为百万级别时,最终过滤的错误率为5%以内。
如何优化cardinality算法呢?
cardinality底层使用的算法是HyperLogLog++算法,简称HLL算法,它本质上就是对所有的unique value计算hash值,再通过hash值使用类似distinct的手法计算最终去重的结果。由于不能保证hash值绝对不重复,所以cardinality计算的结果可能会有误差。
所谓的对cardinality进行优化,实际上就是想办法优化HLL算法的性能。算法本身虽然没有办法优化,但我们可以调整计算hash值的时机。比如在创建index时,专门创建一个字段,用于存放hash值。新增document时,直接对待过滤的字段计算hash值并保存到hash字段中。这样一来,在使用cardinality进行去重时,就不需要再次计算待去重字段的hash值了,从而提升了cardinality的性能。(虽然这么做会降低数据写入的效率,且并不会对误差有所改善)
所以是否使用cardinality优化,需要我们在数据的写入损耗与过滤时节省的hash计算时长之间做出权衡。
以上优化的方案需要通过安装插件提供支持: mapper-murmur3 plugin。该插件可以从官网获取,注意插件与ES的版本号保持一致。
官方介绍地址: 点我 下载路径: 点我
根据实际的安装路径,在每一个ES节点下,执行以下命令(比如windows):
bin\elasticsearch-plugin install file:///C:/mapper-murmur3-xxx.zip
执行后需要重启ES。
卸载命令:
bin\elasticsearch-plugin remove file:///C:/mapper-murmur3-xxx.zip
使用时,需要在定义index时新增类型为murmur3的子字段。具体写法如下:
PUT /cars
{
"mappings": {
"sales": {
"properties": {
"brand": {
"type": "keyword",
"fields": {
"custom_brand_hash" : {
"type": "murmur3"
}
}
},
... 省略其他字段
}
}
}
}
新增和修改数据的方式照旧,只不过在进行去重聚合时,不再使用"brand"字段,而是使用子字段"custom_brand_hash“。
GET /cars/_search
{
"aggs": {
"group_by_date": {
"date_histogram": {
"field": "sold_date",
"interval": "month",
"min_doc_count": 1
},
"aggs": {
"count_of_brand": {
"cardinality": {
"field": "brand.custom_brand_hash"
}
}
}
}
}
}
2.13 百分比算法
ES有percentile api,用于计算百分比数据,在项目中一般用于统计请求的响应时长。
比如PT99: 指的是99%的请求能达到多少毫秒的响应时长,计算时会抽样99%的数据进行统计。
这里很容易陷入PT99比PT50计算出的响应时长长的陷阱。实际场景中,请求的响应时长不会均匀分布,可能有10%的请求响应平均时长为1000毫秒,50%的请求响应平均时长为300毫秒,40%的请求响应平均时长为50毫秒。统计时会对数据进行抽样对比,现在考虑PT50和PT99,请问是抽样获取50%的数据时包含50毫秒响应时长请求的概率大,还是抽样获取99%的数据时概率大?显然后者概率更大,由于抽样获取响应时长短的数据概率更大,压低了整体数据的响应时长,所以通常而言,PT99比PT50计算出的响应时长更短。(就算有人会反问,如果90%的响应时长是1000毫秒,10%的请求响应时长为50毫秒怎么办?没关系,此时PT99还是比PT50响应时长短,因为PT99抽样获取到50毫秒请求的概率要比PT50大得多,压低了整体数据的响应时长)
举例, 统计出50%,90%以及99%的请求花费的响应时长。
初始化数据:
PUT /test_percentiles
{
"mappings": {
"properties": {
"latency": {
"type": "long"
},
"province": {
"type": "keyword"
},
"timestamp": {
"type": "date"
}
}
}
}
POST /test_percentiles/_bulk
{
"index": {
}}
{
"latency" : 105, "province" : "江苏", "timestamp" : "2016-10-28" }
{
"index": {
}}
{
"latency" : 83, "province" : "江苏", "timestamp" : "2016-10-29" }
{
"index": {
}}
{
"latency" : 92, "province" : "江苏", "timestamp" : "2016-10-29" }
{
"index": {
}}
{
"latency" : 112, "province" : "江苏", "timestamp" : "2016-10-28" }
{
"index": {
}}
{
"latency" : 68, "province" : "江苏", "timestamp" : "2016-10-28" }
{
"index": {
}}
{
"latency" : 76, "province" : "江苏", "timestamp" : "2016-10-29" }
{
"index": {
}}
{
"latency" : 101, "province" : "新疆", "timestamp" : "2016-10-28" }
{
"index": {
}}
{
"latency" : 275, "province" : "新疆", "timestamp" : "2016-10-29" }
{
"index": {
}}
{
"latency" : 166, "province" : "新疆", "timestamp" : "2016-10-29" }
{
"index": {
}}
{
"latency" : 654, "province" : "新疆", "timestamp" : "2016-10-28" }
{
"index": {
}}
{
"latency" : 389, "province" : "新疆", "timestamp" : "2016-10-28" }
{
"index": {
}}
{
"latency" : 302, "province" : "新疆", "timestamp" : "2016-10-29" }
发起请求:
GET /test_percentiles/_search
{
"size": 0,
"aggs": {
"percentiles_latency": {
"percentiles": {
"field": "latency",
"percents": [
50,
90,
99
]
}
}
}
}
聚合结果,50%的请求响应时长为108.5毫秒,90%的请求响应时长约为468毫秒, 而99%的请求响应时长约为654毫秒:
"aggregations" : {
"percentiles_latency" : {
"values" : {
"50.0" : 108.5,
"90.0" : 468.5000000000002,
"99.0" : 654.0
}
}
}
商业项目中,一般要求PT99最好能达到200毫秒以内,PT90要求500毫秒,而PT50要求1秒。
2.14 percentile_ranks - SLA统计
SLA是Service Level Agreement的缩写,意思是提供服务的标准。大家谈论的网站延迟的SLA,指的是这个网站中所有请求的访问延时。一般而言,大型公司要求SLA保持在200毫秒以内。如果延时超过1秒,通常会被标记成A级故障,代表这个网站有严重的性能问题。
percentile_ranks与上一个章节中的percentile的统计方向正好相反,前者指定请求延时时长,希望统计出满足延时标准的请求数量百分比,而后者指定了请求数量百分比,希望统计出给定范围内能够达到的请求延时时长。
keyed参数,默认值为true,用于拼接聚合条件和统计结果,起到简化输出的作用,具体应用方式请看下面的例子。
举例,分别统计访问延时在200毫秒和1000毫秒以内的请求数量占比。
请求语法,以下语法中会将latency划分成三个区间,[0,200), [200, 1000), [1000,∞)
GET test_percentiles/_search
{
"size": 0,
"aggs": {
"percentile_ranks_latency": {
"percentile_ranks": {
"field": "latency",
"values": [
200,
1000
],
"keyed": true
}
}
}
}
执行结果:
"aggregations" : {
"percentile_ranks_latency" : {
"values" : [
{
"key" : 200.0,
"value" : 64.57055214723927
},
{
"key" : 1000.0,
"value" : 100.0
}
]
}
}
如果将keyed设置成true或不写,则输出以下结果:
"aggregations" : {
"percentile_ranks_latency" : {
"values" : {
"200.0" : 64.57055214723927,
"1000.0" : 100.0
}
}
}
}
percentile_ranks的很常用,经常用于区域占比统计,比如电商中的价格区间统计(某一个品牌中,不同价格区间的手机数量占比)。
2.15 优化percentiles和percentiles_ranks(TDigest算法)
percentiles和percentiles_ranks的底层都是采用TDigest算法,就是用很多的节点来执行百分比计算,计算过程也是一种近似估计,有一定的错误率。节点越多,结果越精确(内存消耗越大)。
ES提供了参数compression用于限制节点的最大数目,限制为: 20 * compression。这个参数的默认值为100,也就是默认提供2000个节点。一个节点大约使用32个字节的内存,所以在最坏的情况下(例如有大量数据有序的存入),默认设置会生成一个大小为64KB的TDigest算法空间。在实际应用中,数据会更随机,也就没有必要用这么多的节点,所以TDigest使用的内存会更少。
GET test_percentiles/_search
{
"size": 0,
"aggs": {
"group_by_province": {
"terms": {
"field": "province"
},
"aggs": {
"percentile_ranks_latency": {
"percentile_ranks": {
"field": "latency",
"values": [
200,
1000
],
"keyed" : false,
"tdigest" : {
"compression" : 200
}
}
},
"percentiles_latency" : {
"percentiles": {
"field": "latency",
"percents": [
50,
90,
99
],
"keyed" : false,
"tdigest" : {
"compression" : 200
}
}
}
}
}
}
}
2.16 正排索引与聚合分析的内部原理
ES内部是如何执行聚合的?是否是通过倒排索引实现的聚合分析?
在ES中,进行聚合统计的时候,是不使用倒排索引的,因为使用倒排索引实现聚合统计的代价太高。
比如针对custom_field字段 有如下倒排索引:
| Term | Doc_1 | Doc_2 | Doc_3 |
|---|---|---|---|
| brown | x | x | |
| dog | x | x | |
| fox | x | x |
如果我们想获得包含brown的文档列表,且对custom_field字段分组统计文档数量,则可以使用如下搜索语句:
GET /my_index/_search
{
"query" : {
"match" : {
"custom_field" : "brown"
}
},
"aggs" : {
"popular_terms": {
"terms" : {
"field" : "custom_field"
}
}
}
}
查询部分简单又高效。我们首先在倒排索引中找到 brown ,然后找到包含 brown 的文档。我们可以快速看到 Doc_1 和 Doc_2 包含 brown 这个 token。对于聚合部分,我们需要找到 Doc_1 和 Doc_2 里所有唯一的词项。 如果用倒排索引来实现这个功能,代价很高,因为需要把所有的Terms全部扫描一遍,挨个检查词条是否在Doc_1或Doc_2的custom_field字段中存在,随着词条数量和文档数量的增加,代价会越来越大,执行的时间也会越来越长。
Doc values 通过转置两者间的关系来解决这个问题。倒排索引将词条映射到包含它们的文档,doc values(正排索引) 将文档映射到它们包含的词条:
| Doc | Values |
|---|---|
| Doc_1 | brown fox |
| Doc_2 | brown dog |
| Doc_3 | dog fox |
当数据被转置之后,想要收集到 Doc_1 和 Doc_2 的唯一 token 会非常容易。获得每个文档行,获取所有的词项,然后求两个集合的并集。
因此,搜索和聚合是相互紧密缠绕的。搜索使用倒排索引查找文档,聚合操作收集和聚合 doc values 里的数据。
2.17 doc values特征总结
如果字段的数据类型是Long,Date或keyword等,那么在数据录入时,ES会为这些字段自动创建正排索引(index-time)。正排索引和倒排索引类似,也有缓存应用(内存级别的缓存、OS Cache),如果内存不足时,doc values会写入磁盘文件。
ES大部分的操作都是基于系统缓存(OS Cache)进行的,而不是JVM。ES官方建议不要给JVM分配太多的内存空间,这样会导致GC的开销过大(需要到达一定的数据量,GC才会进行回收,此外,数据越多,那么新生代老年代的数据也就越多,GC每次需要扫描的数据也会变多。)通常来说,给JVM分配的内存不要超过服务器物理内存的1/4,剩余的内存空间供lucence作为OS Cache使用。毕竟ES中的倒排索引和正排索引都可以使用OS Cache来缓存,OS Cache越大,能够缓存的热数据越多,ES的搜索性能提升的越明显。
ES为了能够在缓存中尽可能的保存多的doc value和倒排索引,会使用压缩技术来实现doc value和倒排索引的数据压缩。技术手段有许多种,如: 合并相同值、table encoding压缩、最大公约数、offset压缩等等。
如果确定索引绝对不需要doc values,可以在创建索引时关闭doc values,但要保证索引绝对不会做聚合、排序、父子关系处理以脚本处理。关闭的方法如下:
PUT test_index
{
"mappings": {
"my_type" : {
"properties": {
"custom_field" : {
"type": "keyword",
"doc_values" : false
}
}
}
}
}
2.18 使用fielddata处理text类型字段的聚合分析
如果document中field的类型是text,那么在默认情况下是不能执行聚合分析的。比如下面的例子中,remark的类型是text:
Tips: 再次说明,size指的是分组后组的数量,也可以说是bucket的数量。
GET /cars/_search
{
"size": 0,
"aggs": {
"group_of_remark": {
"terms": {
"field": "reark",
"size": 2
}
}
}
}
执行后的部分错误信息为:
Text fields are not optimised for operations that require per-document field data like aggregations and sorting, so these operations are disabled by default. Please use a keyword field instead. Alternatively, set fielddata=true on [remark] in order to load field data by uninverting the inverted index. Note that this can use significant memory.
text类型字段没有对聚合、排序等操作做相应的优化,因此这些操作在默认情况下是不能对text类型的字段使用的。请使用keyword字段来代替text类型字段。还有一种做法,就是将对应字段的fielddata的值设置成true,以便通过倒排索引来加载该字段的数据。请注意,这样做可能会占用大量的内存。
如果必须在text类型的字段上使用聚合操作,则有两种实现方案:
- 为text类型字段增加一个keyword类型的子字段,执行聚合操作时,使用子字段。(利用正派索引实现聚合) 推荐方案
- 为text类型字段设置fielddata=true,通过fielddata,辅助完成聚合分析。(在倒排索引的基础上实现聚合)
第一种方案不过是在创建索引并设置mapping时,增加keyword子字段,这里不再赘述。下面看第二种方案的实现方法(重点看remark字段):
DELETE cars
PUT /cars
{
"mappings": {
"properties": {
"price": {
"type": "long"
},
"color": {
"type": "keyword"
},
"brand": {
"type": "keyword"
},
"model": {
"type": "keyword"
},
"sold_date": {
"type": "date"
},
"remark": {
"type": "text",
"analyzer": "ik_max_word",
"fielddata": true
}
}
}
}
POST /cars/_bulk
{
"index": {
}}
{
"price" : 258000, "color" : "金色", "brand":"大众", "model" : "大众迈腾", "sold_date" : "2017-10-28","remark" : "大众中档车" }
{
"index": {
}}
{
"price" : 123000, "color" : "金色", "brand":"大众", "model" : "大众速腾", "sold_date" : "2017-11-05","remark" : "大众神车" }
{
"index": {
}}
{
"price" : 239800, "color" : "白色", "brand":"标志", "model" : "标志508", "sold_date" : "2017-05-18","remark" : "标志品牌全球上市车型" }
{
"index": {
}}
{
"price" : 148800, "color" : "白色", "brand":"标志", "model" : "标志408", "sold_date" : "2017-07-02","remark" : "比较大的紧凑型车" }
{
"index": {
}}
{
"price" : 1998000, "color" : "黑色", "brand":"大众", "model" : "大众辉腾", "sold_date" : "2017-08-19","remark" : "大众最让人肝疼的车" }
{
"index": {
}}
{
"price" : 218000, "color" : "红色", "brand":"奥迪", "model" : "奥迪A4", "sold_date" : "2017-11-05","remark" : "小资车型" }
{
"index": {
}}
{
"price" : 489000, "color" : "黑色", "brand":"奥迪", "model" : "奥迪A6", "sold_date" : "2018-01-01","remark" : "政府专用?" }
{
"index": {
}}
{
"price" : 1899000, "color" : "黑色", "brand":"奥迪", "model" : "奥迪A 8", "sold_date" : "2018-02-12","remark" : "很贵的大A6。。。" }
此时,再次使用remark字段进行聚合,就不会报错了,执行结果如下:
"aggregations" : {
"group_of_remark" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 18,
"buckets" : [
{
"key" : "车",
"doc_count" : 4
},
{
"key" : "大众",
"doc_count" : 3
},
{
"key" : "的",
"doc_count" : 3
},
{
"key" : "车型",
"doc_count" : 2
},
{
"key" : "6",
"doc_count" : 1
},
{
"key" : "a6",
"doc_count" : 1
},
{
"key" : "上市",
"doc_count" : 1
},
{
"key" : "专用",
"doc_count" : 1
},
{
"key" : "中档",
"doc_count" : 1
},
{
"key" : "中档车",
"doc_count" : 1
}
]
}
}
2.18.1 fielddata特征总结
在默认情况下,不分词的字段类型(data、long、keyword)会自动创建正排索引,所以支持聚合分析、排序、父子数据关系以及脚本操作等。但text类型字段不会创建正排索引,因为分词后再创建正排索引,需要占用的空间太大,由于没有正排索引的支持,text类型字段也就不支持聚合分析了。
如果为text类型的字段开启fielddata,那么在对这个字段进行聚合分析时,ES会一次性将倒排索引逆转并加载到内存中,建立一份类似doc values的fielddata正排索引,最后,基于这个内存中的正排索引来进行聚合分析。
正常情况下,remark(keyword)正排索引,如下图所示:
| Doc | Values |
|---|---|
| 1 | 大众中档车 |
| 2 | 大众神车 |
| 3 | 标志品牌全球上市车型 |
但基于fielddata创建的正排索引,如下图所示(猜测,尚未验证):
| Doc | Values(车) | Values(大众) | Values(车型) |
|---|---|---|---|
| 1 | 车 | 大众 | |
| 2 | 车 | 大众 | |
| 3 | 车型 |
以上Values只写了一部分,随着remark中数据量增多,内容越来越丰富,会导致基于fielddata创建的正排索引的Values越来越多(从表格上来看就是列越来越多)。
fielddata存储在内存中,从结构上来看,就可以很容易的发现,这种数据结构很占用内存。此外,如果fielddata使用磁盘来进行存储,会因为数据量和数据结构的原因,产生非常多的segment file,搜索或聚合使用时,为了打开这些文件,IO的开销也会非常大,因此不推荐使用fielddata实现text类型聚合操作。fielddata是在针对这个字段进行聚合分析时,才会逆转倒排索引并加载到内存中,因此是一个在查询时生成的正排索引(query-time)。
2.18.2 内存控制
由于fielddata对内存(堆内存)的开销非常大,因此ES提供了相关参数来设置内存限制,在每一个ES节点的配置文件config/elasticsearch.yml中增加配置:
indices.fielddata.cache.size:30%
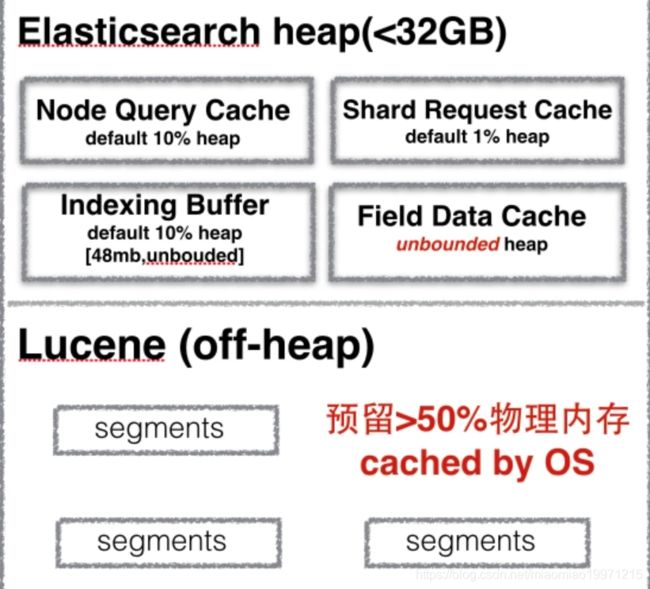
默认情况下,ES对fielddata没有任何限制,如果对fielddata增加了配置信息,代表一旦fieldata在内存中的占比超过了限制,则ES会借助GC清除内存中所有的fielddata数据,也就伴随着频繁的evict和reload(清除内存和重新加载fieldata数据至内存),由于数据本身存储在segment file中,为了取出数据,还需要打开并读取文件,因此IO开销增大,又由于频繁使用GC,内存碎片也会增多,但如果不配置参数,又会严重的消耗堆内存,最终抛出OutOfMemoryError。所以fielddata不推荐使用。
2.18.3 fielddata 内存监控命令
- 查询哪些index中的哪些字段开启了fielddata,分别占用了多大内存空间。由于索引中的数据分布在主分片和副本分片上,除非单节点部署,否则分片会分布在若干节点上。这里统计的内存占用情况是一个总数,无法具体到哪个节点中哪个字段对应的fielddata占用了多少空间。
GET (index)/_stats/fielddata?fields=*
执行结果如下:
"_all" : {
"primaries" : {
"fielddata" : {
"memory_size_in_bytes" : 1760,
"evictions" : 0,
"fields" : {
"remark" : {
"memory_size_in_bytes" : 1760
}
}
}
},
"total" : {
"fielddata" : {
"memory_size_in_bytes" : 3520,
"evictions" : 0,
"fields" : {
"remark" : {
"memory_size_in_bytes" : 3520
}
}
}
}
}
memory_size_in_bytes: 在内存中占用了多大空间,单位: 字节
eviction: 回收了多少个字节
主分片占用了1760个字节,再加上副本分片也占用了1760个字节,因此总计占用了3520个字节。
- 统计每个节点(指定)索引中fielddata占用内存的情况。可以看做是前一条命令的细化。
GET _nodes/stats/indices/fielddata?fields=*
执行结果如下:
{
"_nodes" : {
"total" : 1,
"successful" : 1,
"failed" : 0
},
"cluster_name" : "elasticsearch",
"nodes" : {
"rPIG8hcwT5av908OvQrmPP" : {
"timestamp" : 1587115242615,
# 节点的名称
"name" : "xxxxxMacBook-Pro.local",
"transport_address" : "127.0.0.1:9300",
"host" : "127.0.0.1",
"ip" : "127.0.0.1:9300",
"roles" : [
"ingest",
"master",
"data",
"ml"
],
"attributes" : {
"ml.machine_memory" : "xxxxxxxx",
"xpack.installed" : "true",
"ml.max_open_jobs" : "20"
},
"indices" : {
"fielddata" : {
# 占用内存大小
"memory_size_in_bytes" : 1280,
# 回收的数据大小
"evictions" : 0,
"fields" : {
"remark" : {
"memory_size_in_bytes" : 1280
}
}
}
}
}
}
}
nodes能够会呈现多个节点的信息
2.18.4 circuit breaker 短路器
如果一次聚合操作需要加载的fielddata的数据量超过了给JVM分配的最大堆内存,则会抛出OOM错误,这个时候circuit breaker短路器就派上用场了。ES在加载fielddata之前,短路器会自行估算本次需要加载的fieldata大小,如果加载后超过允许的内存容量上限,则使本次聚合操作请求短路并直接返回错误响应,不会产生OOM导致ES的某个节点宕机。
想要使用circuit breaker短路器,需要在config/elasticsearch.yml中增加配置:
# fielddata的内存限制,默认60%
indices.breaker.fielddata.limit : 60%
# 执行聚合操作时,往往配合搜索一起使用,本参数规定搜索部分涉及到的数据量在堆内存中占比的上限 默认40%
indices.breaker.request.limit: 40%
# 综合上述两个限制,总计内存限制多少。默认无限制。
indices.breaker.total.limit: 70%
2.18.5 fielddata的filter过滤器
我们可以在创建index时,为fielddata增加filter过滤器,实现一个更加细颗粒度的内存控制。
做法如下:在创建index时,定义field字段开启fielddata并指定参数。
min: 只有聚合分析的数据在至少min(比如1%)的document中出现过,才会加载fielddata到内存中。
min_segment_size: 只有segment中保存的document数量大于限制值min_segment_size(比如500)时,才会加载fielddata到内存中,参与聚合计算。如果一个segment中只有少量的文档,那么它的词频会非常粗略且没有任何意义。小的segment很快会被Merge操作合并到大的segment中。
max: 只有聚合分析的数据在少于限制值(比如10%)中的document内出现过,才会加载到fielddata。这样做可以过滤掉一些不必要的词条,比如停用词(“是”、“和”、“的”)
PUT index_name
{
"mappings": {
"properties": {
"test_text_type_field": {
"type": "text",
"fielddata": true,
"fielddata_frequency_filter": {
"min": 0.001,
"max": 0.1,
"min_segment_size": 500
}
}
}
}
}
test_text_type_field是自定义字段的名称,fielddata_frequency_filter中添加fielddata的filter过滤器的相关配置。
2.18.6 fielddata的预加载
前文说到,fielddata是一个query-time生成的正排索引,如果某个索引中必须使用fielddata,又希望提升聚合效率,则可以使用fielddata预加载。做法很简单,就是将fielddata的生成时机由query-time提前到index-time,即在写入document的过程中,创建对应字段的fielddata正排索引并存放到内存中(Field Data Cache)
由于预加载是在写入document时所作的操作,势必会降低index写入数据的效率,此外需要额外的存储fielddata对应的正排索引,因此对内存(特别是堆内存)有着不小的压力,从而也就加大了GC的工作量。预加载的fielddata只有在触发GC的时候,才会清除,否则始终在内存中保存。
做法: 使用eager_global_ordinals (默认false)
PUT index_name
{
"mappings": {
"properties": {
"test_text_type_field": {
"type": "text",
"fielddata": true,
"fielddata_frequency_filter": {
"min": 0.001,
"max": 0.1,
"min_segment_size": 500
},
"eager_global_ordinals": true
}
}
}
}
2.19 海量bucket优化机制
在商业项目中做聚合分析时,很有可能出现海量bucket。比如: 统计汽车销量前5的品牌,以及每个品牌中销量前10的车型。
GET /cars/_search
{
"size": 0,
"aggs": {
"group_by_brands": {
"terms": {
"field": "brand",
"order": {
"_count": "desc"
},
"size": 5
},
"aggs": {
"group_by_model": {
"terms": {
"field": "model",
"order": {
"_count": "desc"
},
"size": 10
}
}
}
}
}
}
从实现层面上分析,上述聚合分析操作是按照“深度优先"的方式执行的。何为深度优先?深度优先就是将所有的bucket全部统计(分组)出来后,再执行操作,计算指标。比如这个统计汽车销量的例子中,假如有500个汽车品牌,每个品牌有50个汽车型号,那么相当于有500x50=25000个bucket,而获取指标时,需要对每一个桶进行计算操作,显然bucket的数量越多,聚合整体的执行效率就会越低。所以需要考虑优化。(注意: 在聚合过程中,Elasticsearch会为bucket创建树结构,而树比较占用内存)
优化的方向很明确——不要分出这么多的桶。如果能在500个车型中过滤出销量前5的品牌,再对这5个品牌针对车型进行分桶,就只需要5*50=250个桶,后续计算指标时,只需要在250个桶中执行计算逻辑即可,这种做法被称作"广度优先",所谓广度优先,核心思想是逐层聚合。在当前层的聚合结果的基础上,再执行下一层的聚合操作。 实现广度优先的做法很简单,只需要增加参数"collect_mode",它的默认值是"depth_first",即深度优先,而广度优先对应的参数值为"breadth_first"。
GET /cars/_search
{
"size": 0,
"aggs": {
"group_by_brands": {
"terms": {
"field": "brand",
"order": {
"_count": "desc"
},
"size": 3,
"collect_mode": "breadth_first"
},
"aggs": {
"group_by_model": {
"terms": {
"field": "model",
"order": {
"_count": "desc"
},
"size": 3
}
}
}
}
}
}
depth_first深度优先和breadth_first广度优先模式都有各自的优缺点,深度优先的聚合统计的精确度高,但bucket数量较多,在大数据量的情况下,可能会遇到海量bucket导致内存压力过大和执行效率过低的问题。广度优先通过逐层聚合,使得bucket数量较少,但其聚合的精度比深度优先低。
三. 聚合算法简介
3.1 易并行聚合算法
所谓的易并行聚合算法,就是若干节点中同时计算一个聚合结果,再返回给协调节点进行计算,得到最终的结果。比如聚合计算中的max,min等api。
下面以执行max api为例来描述易并行聚合算法的执行过程。首先,客户端发起包含max api的聚合请求,请求被发送至Elasticsearch集群中的协调节点node2,node2根据请求推导出参与本次聚合统计的数据所在shard的下标(比如此时推导出shard0,shard1,shard2,shard3上都有目标数据)。接着,node2会将请求分别转发至所有推导出的shard,让每个shard计算自身的max最大值,并返回给协调节点node2。至此,node2会收到来自node0~node3上的4个max值,最后再对这4个max值进行比较,取得最大值并返回给客户端。
易并行聚合算法是Elasticsearch中最基本的聚合算法,执行效率较高。
易并行算法属于精确算法(在合适的场景和api下使用)。
3.2 近似聚合算法
有些聚合分析算法很难使用易并行算法解决,比如:count(distinct)排除重复的统计,这时候ES会采用近似聚合算法来进行计算。近似聚合算法不完全准确,但是效率非常高,一般而言,效率是精准算法的数十倍。
比如计算count(distinct),假设总共有4个节点,每个节点上有一个(主)分片,每个shard中都有10万条非重复数据,不能保证不同节点中的数据完全不同,因此在精确计算时,每一个节点都需要把10万条数据发送给协调节点,不仅传输效率慢(I/O压力大),并且4*10=40万条数据存储在协调节点上,给节点对应的堆内存也带来了极大的压力。使用近似聚合算法后,每个分片会自行进行近似聚合计算,并将结果返回给协调节点,最终由协调节点统计数据结果。之前说过,由于不能保证不同节点中的数据完全不同,因此这种预估可能会产生误差。
近似聚合算法一般会有5%左右的错误率,但延迟能控制在100毫秒左右。精确算法虽然不会有任何的误差,但执行时长就不好说了,可能执行几毫秒,也可能需要执行若干小时才能返回结果,具体需要看数据量和算法的复杂度。
3.3 三角选择原则
三角选择原则: 精准度、实时性、大数据。在选择计算原则时,很难保证所有指标都达标,一般都有一个取舍,通常选取三角选择原则中的两项:
- 精准度、实时性
只适用于数据量较小,通常在单机中执行、可以随时调用的场景。比如一个小型的SSM应用。 - 精准度、大数据
数据量级非常大,并且需要保证数据计算的精准度,哪怕一次需要执行若干小时。这种计算一般都采用批处理程序。比如hadoop。 - 大数据、实时性
数据量级非常大,但只需要近似估计即可,不需要过高的精准度。符合这种原则的算法往往会有一定的误差(一般控制在5%以内),比如3.2节中谈到的"近似聚合算法"。