Python高级 -- 03 多任务(线程、进程、协程)
一、线程
1、并发和并行
并发:指的是任务数多余cpu核数,通过操作系统的各种任务调度算法,实现用多个任务“一起”执行(实际上总有一些任务不在执行,因为切换任务的速度相当快,看上去一起执行而已)
并行:指的是任务数小于等于cpu核数,即任务真的是一起执行的
2、线程
python的thread模块是比较底层的模块,python的threading模块是对thread做了一些包装的,可以更加方便的被使用
3、简单的多线程demo
import threading
import time
def test1():
for i in range(5):
print("-------线程1--------")
time.sleep(1)
def test2():
for i in range(5):
print("---------线程2---------")
time.sleep(1)
def main():
# 使用threading模块的Thread方法,在主线程上创建一个子线程,并返回
# target : 子线程要执行的方法名称
t1 = threading.Thread(target = test1)
t1.start()
t2 = threading.Thread(target = test2)
t2.start()
if __name__ == "__main__":
main()4、查看正在运行的线程
import threading
import time
def test1():
for i in range(5):
time.sleep(1)
def test2():
for i in range(10):
time.sleep(1)
def main():
# 创建子线程
"""
使用Thread方法创建子线程对象的时候,并不会创建线程
当子线程对象调用start()方法的时候,才开始创建子线程,并且线程开始运行
"""
t1 = threading.Thread(target = test1)
t1.start()
t2 = threading.Thread(target = test2)
t2.start()
"""
threading.enumerate()方法可以查看当前运行的线程
返回值是一个列表
列表中放的是主线程和每一个子线程的信息
如果主线程挂了,子线程立即结束运行
子线程运行结束,不会影响主线程的运行
"""
print(type(threading.enumerate()))
# 结果:
print(threading.enumerate())
# 结果:[<_MainThread(MainThread, started 140470619174656)>, , ]
if __name__ == "__main__":
main() 5、创建线程的第二种方法:继承Thread类
import time
class MyThread(threading.Thread):
# 重写run方法,run方法中是该线程要执行的动作
def run(self):
for i in range(5):
time.sleep(1)
msg = self.name
print(msg) # 线程名称
def main():
# 创建自定义的线程类对象
t = MyThread()
# 调用自定义线程类中的继承自父类的start方法,执行自定义线程类中的run方法
t.start()
if __name__ == "__main__":
main()6、多线程共享全局变量
import threading
import time
def test1(temp):
temp.append(33)
print("----------test1的全局变量值:%s-------" % str(temp))
def test2(temp):
print("----------test2的全局变量值:%s-------" % str(temp))
list1 = [11, 22]
def main():
# target指定线程要执行的代码的函数
# args 指定调用函数的时候,要传递的参数列表,类型是一个元组
t1 = threading.Thread(target = test1, args = (list1, ))
t2 = threading.Thread(target = test2, args = (list1, ))
t1.start()
# 此处让进程休眠1秒钟是为了让线程1先执行完成,让全局变量修改完毕在进行操作
time.sleep(1)
t2.start()
time.sleep(1)
# 打印最终的全局变量
print("-------------最终的变量为:%s-----------" % str(list1))
if __name__ == "__main__":
main()7、多线程共享全局变量的问题 -- 资源竞争
import threading
import time
# 定义一个全局变量
glo_num = 0
def test1(num):
global glo_num
for i in range(num):
glo_num += 1
print("------test1中的num是:%s--------" % str(glo_num))
def test2(num):
global glo_num
for i in range(num):
glo_num += 1
print("------test2中的num是:%d--------" % glo_num)
def main():
t1 = threading.Thread(target = test1, args = (1000000,))
t2 = threading.Thread(target = test2, args = (1000000, ))
t1.start()
t2.start()
time.sleep(10)
print("------两个线程执行完毕之后的全局变量为:%d" % glo_num)
"""
以上程序打印结果是:
------test1中的num是:1358112--------
------test2中的num是:1407249--------
------两个线程执行完毕之后的全局变量为:1407249
发现问题:两个循环各循环1000000次,所以最终结果应该是2000000
但是由于线程之间存在相互抢占资源的问题,则会导致第一个
方法没有执行完毕,已经失去了线程的使用权,第二个方法开始
使用了全局变量,等到第一个方法获取线程cpu使用权的时候,
第二个方法已经对全局变量进行了修改,而此时线程1和线程2
使用的全局变量的值已经不相同了,因此造成数值的错误。
即:多个线程之间会抢占资源⭐⭐⭐
"""
if __name__ == "__main__":
main()8、同步
同步就是协同步调,按预定的先后次序进行运行。如进程、线程同步,可理解为进程或线程A和B一块配合,A执行到一定程度时要依靠B的某个结果,于是停下来,示意B运行;B执行,再将结果给A;A再继续操作。
当多个线程几乎同时修改某一个共享数据的时候,需要进行同步控制。线程同步能够保证多个线程安全访问竞争资源,最简单的同步机制是引入互斥锁。
9、互斥锁
互斥锁为资源引入一个状态:锁定/非锁定。
某个线程要更改共享数据时,先将其锁定,此时资源的状态为“锁定”,其他线程不能更改;直到该线程释放资源,将资源的状态变成“非锁定”,其他的线程才能再次锁定该资源。互斥锁保证了每次只有一个线程进行写入操作,从而保证了多线程情况下数据的正确性。
threading的模块中定义了Lock类,用于处理锁:
# 创建锁,返回的是一个锁的对象
myLock = threading.Lock()
# 锁定当前线程,如果锁定之前,线程没有上锁,acquire()操作不会阻塞
# 如果在acquire()操作之前,它已经被其他线程上了锁,那么此时调用acquire()方法会阻塞,直到其他线程释放锁之后才会执行
myLock.acquire()
# 释放当前线程
myLock.release()使用互斥锁解决7中资源竞争的问题
import threading
import time
# 定义全局变量
glo_num = 0
def test1(num):
global glo_num
for i in range(num):
# 上锁
myLock.acquire()
glo_num += 1
# 解锁
myLock.release()
print("---------test1程序运行结束之后全局变量的结果是:%d---------" % glo_num)
def test2(num):
global glo_num
for i in range(num):
# 上锁
myLock.acquire()
glo_num += 1
# 解锁
myLock.release()
print("---------test2程序运行结束之后全局变量的结果是:%d---------" % glo_num)
# 创建一个互斥锁,默认是没有上锁状态
myLock = threading.Lock()
def main():
t1 = threading.Thread(target = test1, args = (1000000, ))
t2 = threading.Thread(target = test2, args = (1000000, ))
t1.start()
t2.start()
# 让系统休眠5s,等待两个线程执行完毕
time.sleep(5)
print("-----------两个线程执行完毕之后,全局变量的值为:%d-------------" % glo_num)
"""
运行结果:
---------test1程序运行结束之后全局变量的结果是:1988686---------
---------test2程序运行结束之后全局变量的结果是:2000000---------
-----------两个线程执行完毕之后,全局变量的值为:2000000-------------
"""
if __name__ == "__main__":
main()锁的好处:
确保了某段关键代码只能由一个线程从头到尾完整地执行。
锁的坏处:
阻止了多线程并发执行,包含锁的某段代码实际上只能以单线程模式执行,效率就大大地下降了。
由于可以存在多个锁,不同的线程持有不同的锁,并试图获取对方持有的锁时,可能会造成死锁。
10、死锁
死锁产生的原因:
在线程间共享多个资源的时候,如果两个线程分别占有一部分资源并且同时等待对方的资源,就会造成死锁。
死锁的demo:
import threading
import time
# 自定义的线程类,继承了threading.Thread类
class MyThreadA(threading.Thread):
def run(self):
# 对锁A进行上锁操作
lockA.acquire()
print("-----------A类中对%s进行上锁操作-----------" % self.name)
# 让系统休眠2s
time.sleep(2)
# 对锁B进行上锁
lockB.acquire()
print("-----------A类中对%s进行上锁操作-----------" % self.name)
# 释放B锁
lockB.release()
# 释放A锁
lockA.release()
# 自定义线程类
class MyThreadB(threading.Thread):
def run(self):
# 对锁B进行上锁操作
lockB.acquire()
print("-----------B类中对%s进行上锁操作-----------" % self.name)
# 让系统休眠2s
time.sleep(2)
# 对锁A进行上锁
lockA.acquire()
print("-----------B类中对%s进行上锁操作-----------" % self.name)
# 释放A锁
lockA.release()
# 释放B锁
lockB.release()
# 创建两个自定义锁对象
lockA = threading.Lock()
lockB = threading.Lock()
def main():
t1 = MyThreadA()
t2 = MyThreadB()
t1.start()
t2.start()
"""
程序运行打印两句话之后,变成死锁
"""
if __name__ == "__main__":
main()
11、使用多任务实现udp的聊天器
import threading
import socket
# 发送信息
def send_msg(udp_socket, dest_ip, dest_port):
"""发送数据"""
while True:
content = input("请输入内容:")
udp_socket.sendto(content.encode("utf-8"), (dest_ip, dest_port))
# 接收数据
def recv_msg(udp_socket):
"""接收数据"""
while True:
recv_data = udp_socket.recvfrom(1024)
print(recv_data[0].decode("utf-8"))
def main():
# 1.创建套接字对象
udp_socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
# 2.绑定端口号
udp_socket.bind(("", 8888))
# 3.获取目的方的ip和端口号
ip = input("请输入对方的ip:")
port = int(input("请输入对方的port:"))
# 4.使用多线程同时进行收发操作
sendMsg = threading.Thread(target = send_msg, args = (udp_socket, ip, port))
recvMsg = threading.Thread(target = recv_msg, args = (udp_socket, ))
sendMsg.start()
recvMsg.start()
if __name__ == "__main__":
main()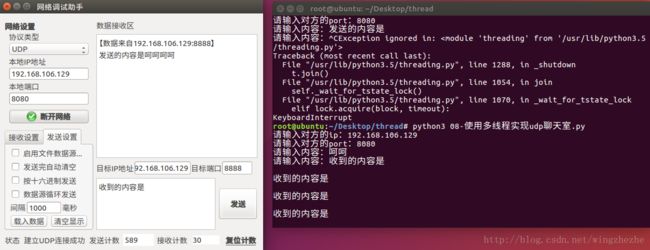
二、进程
1、进程
一个程序运行起来后,代码+用到的资源 称之为进程,它是操作系统分配资源的基本单元。不仅可以通过线程完成多任务,进程也是可以的。
2、进程的状态
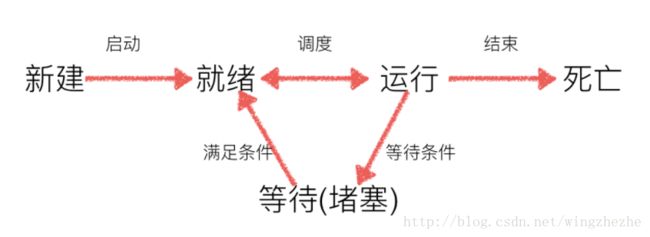
就绪态:运行的条件都已经慢去,正在等在cpu执行
执行态:cpu正在执行其功能
等待态:等待某些条件满足,例如一个程序sleep了,此时就处于等待态
3、创建进程
import multiprocessing
import time
def test1():
while True:
print("-----1----")
time.sleep(1)
def test2():
while True:
print("-----2----")
time.sleep(1)
def main():
# 创建进程
"""
Process([group [, target [, name [, args [, kwargs]]]]])
target:如果传递了函数的引用,可以任务这个子进程就执行这里的代码
args:给target指定的函数传递的参数,以元组的方式传递
kwargs:给target指定的函数传递命名参数
name:给进程设定一个名字,可以不设定
group:指定进程组,大多数情况下用不到
Process创建的实例对象的常用方法:
start():启动子进程实例(创建子进程)
is_alive():判断进程子进程是否还在活着
join([timeout]):是否等待子进程执行结束,或等待多少秒
terminate():不管任务是否完成,立即终止子进程
Process创建的实例对象的常用属性:
name:当前进程的别名,默认为Process-N,N为从1开始递增的整数
pid:当前进程的pid(进程号)
"""
p1 = multiprocessing.Process(target = test1)
p2 = multiprocessing.Process(target = test2)
p1.start()
p2.start()
if __name__ == "__main__":
main()4、获取pid、ppid
import multiprocessing
import time
import os
def test1():
while True:
print("--------子进程的pid为:%d, 父进程ppid为:%d-------" % (os.getpid(), os.getppid()))
time.sleep(1)
def main():
print("--------主进程的pid为:%d, 父进程ppid为:%d-------" % (os.getpid(), os.getppid()))
p = multiprocessing.Process(target = test1)
p.start()
if __name__ == "__main__":
main()注意:进程中,如果父进程终止,子进程并不会终止(进程之间时独立的)
5、子进程中传递参数
import multiprocessing
def test1(a, b, *args, **kwargs):
print(a)
print(b)
print(args)
print(kwargs)
"""
打印结果:
11
22
(33, 44, 55)
{'mm': '66'}
"""
def main():
p = multiprocessing.Process(target = test1, args = (11,22,33,44,55), kwargs = {"mm":"66"})
p.start()
if __name__ == "__main__":
main()6、多进程之间共享全局变量
import multiprocessing
import time
# 定义全局变量
glo_list = [11, 22, 33]
def test1():
glo_list.append(44)
print("-------test1中的全局变量为:%s--------" % str(glo_list))
def test2():
time.sleep(1)
print("-------test2中的全局变量为:%s--------" % str(glo_list))
def main():
p1 = multiprocessing.Process(target = test1)
p1.start()
p2 = multiprocessing.Process(target = test2)
p2.start()
"""
打印结果:
-------test1中的全局变量为:[11, 22, 33, 44]--------
-------test2中的全局变量为:[11, 22, 33]--------
"""
if __name__ == "__main__":
main()结论:多个进程之间不共享全局变量,即在一个进程中对全局变量修改过后,不会影响另一个进程中的全局变量,因为:多个进程之间时相互独立的。
7、线程和进程之间的比较
(1)、功能
进程,能够完成多任务,比如 在一台电脑上能够同时运行多个QQ
线程,能够完成多任务,比如 一个QQ中的多个聊天窗口
(2)、定义的不同
进程是系统进行资源分配和调度的一个独立单位.
线程是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位.线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈),但是它可与同属一个进程的其他的线程共享进程所拥有的全部资源。
(3)、区别
一个程序至少有一个进程,一个进程至少有一个线程.
线程的划分尺度小于进程(资源比进程少),使得多线程程序的并发性高。
进程在执行过程中拥有独立的内存单元,而多个线程共享内存,从而极大地提高了程序的运行效率
线线程不能够独立执行,必须依存在进程中
可以将进程理解为工厂中的一条流水线,而其中的线程就是这个流水线上的工人
(4)、优缺点
线程和进程在使用上各有优缺点:线程执行开销小,但不利于资源的管理和保护;而进程正相反。
8、多进程之间通信 -- Queue
可以使用multiprocessing模块的Queue实现多进程之间的数据传递,Queue本身是一个消息列队程序
Queue使用Demo
import multiprocessing
import time
def download(q):
"""模拟下载数据的功能"""
data = [11, 22, 33, 44]
# 向队列中写入数据
for temp in data:
q.put(temp)
print("----下载器已经下载完毕数据,并将数据存入到队列中----")
def analysis(q):
"""数据处理"""
analysis_data = list()
time.sleep(1)
# 从队列中获取数据
while True:
data = q.get()
analysis_data.append(data)
if q.empty():
break
# 对数据进行处理
print(str(analysis_data))
def main():
# 1.创建一个队列
q = multiprocessing.Queue()
# 2.创建多个线程,将队列对象作为参数传递到子线程中
p1 = multiprocessing.Process(target = download, args = (q, ))
p2 = multiprocessing.Process(target = analysis, args = (q, ))
p1.start()
p2.start()
"""
运行结果:
----下载器已经下载完毕数据,并将数据存入到队列中----
[11, 22, 33, 44]
"""
if __name__ == "__main__":
main()队列Queue中API使用说明:
初始化Queue()对象时(例如:q=Queue()),若括号中没有指定最大可接收的消息数量,或数量为负值,那么就代表可接受的消息数量没有上限(直到内存的尽头);
Queue.qsize():返回当前队列包含的消息数量;
Queue.empty():如果队列为空,返回True,反之False ;
Queue.full():如果队列满了,返回True,反之False;
Queue.get([block[, timeout]]):获取队列中的一条消息,然后将其从列队中移除,block默认值为True;
1)如果block使用默认值,且没有设置timeout(单位秒),消息列队如果为空,此时程序将被阻塞(停在读取状态),直到从消息列队读到消息为止,如果设置了timeout,则会等待timeout秒,若还没读取到任何消息,则抛出"Queue.Empty"异常
2)如果block值为False,消息列队如果为空,则会立刻抛出"Queue.Empty"异常;
Queue.get_nowait():相当Queue.get(False);
Queue.put(item,[block[, timeout]]):将item消息写入队列,block默认值为True;
1)如果block使用默认值,且没有设置timeout(单位秒),消息列队如果已经没有空间可写入,此时程序将被阻塞(停在写入状态),直到从消息列队腾出空间为止,如果设置了timeout,则会等待timeout秒,若还没空间,则抛出"Queue.Full"异常;
2)如果block值为False,消息列队如果没有空间可写入,则会立刻抛出"Queue.Full"异常;
Queue.put_nowait(item):相当Queue.put(item, False);
9、进程池Pool
from multiprocessing import Pool
import os, time, random
def worker(msg):
t_start = time.time()
print("%s开始执行,进程号为%d" % (msg,os.getpid()))
# random.random()随机生成0~1之间的浮点数
time.sleep(random.random()*2)
t_stop = time.time()
print(msg,"执行完毕,耗时%0.2f" % (t_stop-t_start))
po = Pool(3) # 定义一个进程池,最大进程数3
for i in range(0,10):
# Pool().apply_async(要调用的目标,(传递给目标的参数元祖,))
# 每次循环将会用空闲出来的子进程去调用目标
po.apply_async(worker,(i,))
print("----start----")
po.close() # 关闭进程池,关闭后po不再接收新的请求
po.join() # 等待po进程池中所有子进程执行完成,必须放在close语句之后
print("-----end-----")
"""
运行结果:
----start----
0开始执行,进程号为21466
1开始执行,进程号为21468
2开始执行,进程号为21467
0 执行完毕,耗时1.01
3开始执行,进程号为21466
2 执行完毕,耗时1.24
4开始执行,进程号为21467
3 执行完毕,耗时0.56
5开始执行,进程号为21466
1 执行完毕,耗时1.68
6开始执行,进程号为21468
4 执行完毕,耗时0.67
7开始执行,进程号为21467
5 执行完毕,耗时0.83
8开始执行,进程号为21466
6 执行完毕,耗时0.75
9开始执行,进程号为21468
7 执行完毕,耗时1.03
8 执行完毕,耗时1.05
9 执行完毕,耗时1.69
-----end-----
"""multiprocessing.Pool常用函数解析:
apply_async(func[, args[, kwds]]):使用非阻塞方式调用func(并行执行,堵塞方式必须等待上一个进程退出才能执行下一个进程),args为传递给func的参数列表,kwds为传递给func的关键字参数列表;
close():关闭Pool,使其不再接受新的任务;
terminate():不管任务是否完成,立即终止;
join():主进程阻塞,等待子进程的退出, 必须在close或terminate之后使用;
进程池中使用Queue:
如果要使用Pool创建进程,就需要使用multiprocessing.Manager()中的Queue(),而不是multiprocessing.Queue(),否则会得到一条如下的错误信息:RuntimeError: Queue objects should only be shared between processes through inheritance.
10、案例:文件夹copy器(多进程版)
import os
import multiprocessing
def copy_file(q, file_name, src_folder_name, des_folder_name):
"""完成文件复制的方法"""
print("======== 文件copy方法:从 %s ----> 到 %s , 文件名是:%s " % (src_folder_name, des_folder_name, file_name))
# 打开源文件
src_file = open(src_folder_name + "/" + file_name, "rb")
content = src_file.read()
src_file.close()
des_file = open(des_folder_name + "/" + file_name, "wb")
des_file.write(content)
des_file.close()
# 完成文件拷贝,向队列中写入一个消息,表示已经完成
q.put(file_name)
def main():
# 1.获取用户要拷贝的文件夹
src_folder_name = input("请输入要拷贝的文件夹的名字:")
# 2.创建一个新的文件夹
try:
des_folder_name = "[copy]" + src_folder_name
os.mkdir(des_folder_name)
except:
# 如果创建文件报错,为了保证程序可以正常执行,使用try...except...包裹起来
pass
# 3.获取源文件夹下所有要copy的文件的名字,使用 listdir() 方法,返回一个列表
file_names = os.listdir(src_folder_name)
# print(file_names)
# 4.创建进程池,最大任务数为5
po = multiprocessing.Pool(5)
# 5.创建一个队列
q = multiprocessing.Manager().Queue()
# 6.向进程池中添加copy文件的任务
for file_name in file_names:
po.apply_async(copy_file, args = (q, file_name, src_folder_name, des_folder_name))
# 关闭进程池
po.close()
# po.join 等待进程池中所有任务执行完毕,结束进程
# po.join
"""
此处不实用po.join方法是因为要显示进度条,需要写一个无限循环,自己控制循环结束的时机
"""
# 获取总文件数
all_file_num = len(file_names)
# 定义已经完成copy的文件数
copy_ok_num = 0
while True:
# 从队列中获取完成的文件名
file_name = q.get()
copy_ok_num += 1
# 打印进度
print("\r拷贝的进度为:%.2f %%" % (copy_ok_num * 100/ all_file_num), end = "")
# 设置循环结束的条件
if copy_ok_num >= all_file_num:
break
print()
if __name__ == "__main__":
main()三、协程
1、迭代器
(1)、自定义对象实现迭代器功能
from collections import Iterable
from collections import Iterator
import time
# 自定义类,实现迭代功能
class ClassMate(object):
# 构造方法
def __init__(self):
self.names = list()
self.current_num = 0
# 定义普通方法
def add(self, name):
self.names.append(name)
"""
如果想让一个自定义的对象成为一个可以迭代的对象,
即:可以使用[ for temp in 自定义类对象],
那么必须实现 __iter__ 方法,并且返回一个具有 __iter__ 和 __next__ 方法的引用
"""
def __iter__(self):
# 返回一个迭代器的对象,并将自身的引用当作参数传递
return self
# 遍历的时候调用 next 方法会使用该方法
def __next__(self):
# 判断自定义的索引值是否小于names列表长度
if self.current_num < len(self.names):
value = self.names[self.current_num]
# 每次获取一个元素之后,索引+1
self.current_num += 1
return value
# 如果if条件不成立,即列表中元素都取完,为了不让next方法返回None,在else中抛出一个异常
else:
raise StopIteration # 抛出该异常后,for循环会结束
c = ClassMate()
c.add("zhangsan")
c.add("lisi")
c.add("wangwu")
"""
自定义的类中如果有 __iter__ 方法,则,实例化之后的类对象就会变成一个可以迭代的对象
print("判断c是否是可以迭代的对象:", isinstance(c, Iterable)) # True
使用 iter() 方法将自定义类对象当作参数传递,就相当于调用自定义类中的 __iter__ 方法
返回的是一个迭代器对象,即:我们上面定义的 ClassIterator 类对象
classmate_iterator = iter(c)
然后调用 next() 方法,将迭代器对象当作参数传递,就可以获取迭代器中的 __next__ 方法的返回值
print("判断classmate_iterator是否是迭代器对象:", isinstance(classmate_iterator, Iterator)) # True
"""
for name in c:
print(name)(2)、使用迭代器实现斐波那契数列的算法
# 定义斐波那契类
class Fibonacci(object):
# max_num 生成的斐波那契数的个数
def __init__(self, max_num):
self.current_num = 0
self.max_num = max_num
self.a = 0
self.b = 1
def __iter__(self):
return self
def __next__(self):
if self.current_num < self.max_num:
result = self.a
self.a, self.b = self.b, self.a + self.b
self.current_num += 1
return result
else:
raise StopIteration
f = Fibonacci(15)
for i in f:
print(i)2、生成器
(1)、什么是生成器
利用迭代器,我们可以在每次迭代获取数据(通过next()方法)时按照特定的规律进行生成。但是我们在实现一个迭代器时,关于当前迭代到的状态需要我们自己记录,进而才能根据当前状态生成下一个数据。为了达到记录当前状态,并配合next()函数进行迭代使用,我们可以采用更简便的语法,即生成器(generator)。生成器是一类特殊的迭代器。
(2)、创建生成器的方法
1)、把列表生成式的 [ ] 改为 ( ) 即可
"""
列表生成式
"""
list1 = [i * 2 for i in range(20) if i % 2 == 0]
print(list1) # [0, 4, 8, 12, 16, 20, 24, 28, 32, 36]
"""
列表生成式转换为列表生成器
"""
list2 = (i * 2 for i in range(15) if i % 2 == 1)
print(list2) # at 0x7f0103a54eb8>
# 生成器只是一个生成的方式,不是具体的列表,所以直接打印没有任何的数据
for i in list2:
print(i, end="\t") # 2 6 10 14 18 22 26 2)、创建生成器的方法二
def gen_num(num_nums):
a, b = 0, 1
current_num = 0
while current_num < num_nums:
"""
如果一个函数中出现了 yield 关键字,
那么这个函数就不会被当作函数进行调用,
而是变成了一个生成器的模版
"""
yield a
a, b = b, a+b
current_num += 1
"""
如果在调用函数的时候,发现函数中有yield关键字,则语句就不是调用函数,
而是创建一个生成器对象
"""
obj = gen_num(20)
print(obj) #
for i in obj:
print(i, end=" ") # 0 1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987 1597 2584 4181 (3)、生成器的next用法
def gen_num(num_nums):
current_num = 0
a, b = 0, 1
while current_num < num_nums:
yield a
a, b = b, a+b
current_num += 1
return "end..."
"""
使用 next(生成器对象) 方法的时候,每一次的返回值都是 yield 关键字返回的数据
如果生成器中有 return 关键字,通过生成器对象接收不到
如果想要获取return的值,需要在异常中获取
"""
g = gen_num(10)
while True:
try:
rest = next(g)
print(rest, end = " ") # 0 1 1 2 3 5 8 13 21 34
except Exception as e:
retu = e.value # 生成器的next方法产生异常的时候,异常对象的 value 属性就是生成器中的return的值
print(retu) # end...
break(4)、生成器对象使用send方法
def gen_num(num_nums):
current_num = 0
a, b = 0, 1
while current_num < num_nums:
arg = yield a
print("----> 此处是生成器对象调用send方法的时候,传递的参数,被arg接收:", arg)
a, b = b, a+b
current_num += 1
# 创建生成器对象
g = gen_num(10)
# 调用 next 方法
rest1 = next(g) # 调用next方法,返回值是生成器中 yield 后面的变量
print(rest1) # 0
"""
调用生成器的 send 方法
返回值也是生成器中的 yield 后面的变量
但是 send 方法可以传递参数,参数会传递给生成器中 yield 前面的变量
注意:一般如果传递一个具体的值的时候,send方法不能用在第一次调用生成器的时候
一般会配合这next方法使用
"""
rest2 = g.send("aaa")
print(rest2) # 1
"""
程序最终运行结果:
0
----> 此处是生成器对象调用send方法的时候,传递的参数,被arg接收: aaa
1
3、使用yield完成多任务
import time
def test1():
while True:
print("-------1-------")
yield
time.sleep(0.1)
def test2():
while True:
print("-------2-------")
yield
time.sleep(0.1)
def main():
while True:
t1 = test1()
t2 = test2()
next(t1)
next(t2)
if __name__ == "__main__":
main()
""""
运行结果:
-------1-------
-------2-------
-------1-------
-------2-------
-------1-------
-------2-------
-------1-------
-------2-------
-------1-------
""""4、使用greenlet实现多线程
python中的greenlet模块对多任务进行封装,其实是对yield进行简单的处理,从而使得切换任务变的更加简单。使用greenlet首先要安装greenlet的插件:
sudo pip3 install greenlet使用greenlet的demo
import time
from greenlet import greenlet
def test1():
while True:
print("------A------")
# 切换到test2中运行
t2.switch()
time.sleep(0.5)
def test2():
while True:
print("------B------")
# 切换到test1中运行
t1.switch()
time.sleep(0.5)
t1 = greenlet(test1)
t2 = greenlet(test2)5、使用gevent实现多线程
导入gevent模块
sudo pip3 install gevent使用gevent实现多线程的Demo
# 将程序中用到的耗时操作的代码,换为gevent中自己实现的模块
monkey.patch_all()
def f1(n):
for i in range(n):
print(gevent.getcurrent(), i)
time.sleep(0.5)
def f2(n):
for i in range(n):
print(gevent.getcurrent(), i)
time.sleep(0.5)
def f3(n):
for i in range(n):
print(gevent.getcurrent(), i)
time.sleep(0.5)
print("------1-----")
g1 = gevent.spawn(f1, 5)
print("------2-----")
g2 = gevent.spawn(f2, 5)
print("------3-----")
g3 = gevent.spawn(f3, 5)
g1.join()
g2.join()
g3.join()
"""
运行结果:
------1-----
------2-----
------3-----
0
0
0
1
1
1
2
2
2
3
3
3
4
4
4
"""
"""
如果join操作比较多,可以用一下写法:
"""
gevent.joinall([
gevent.spawn(f1, 5)
gevent.spawn(f2, 5)
gevent.spawn(f3, 5) 6、案例:使用gevent实现图片下载
import gevent
from gevent import monkey
import urllib.request
# 打延时补丁
monkey.patch_all()
# 定义下载的方法
def download(img_url, img_name):
req = urllib.request.urlopen(img_url)
img_content = req.read()
with open(img_name, "wb") as f:
f.write(img_content)
def main():
gevent.joinall([
gevent.spawn(download, "https://rpic.douyucdn.cn/live-cover/appCovers/2018/01/30/4230431_20180130233438_big.jpg", "girl1.jpg"),
gevent.spawn(download, "https://rpic.douyucdn.cn/live-cover/appCovers/2018/02/01/3774794_20180201155048_big.jpg", "girl2.jpg")
])
if __name__ == "__main__":
main()7、线程、进程、协程总结
进程是资源分配的单位
线程是操作系统调度的单位
进程切换需要的资源很最大,效率很低
线程切换需要的资源一般,效率一般(当然了在不考虑GIL的情况下)
协程切换任务资源很小,效率高
多进程、多线程根据cpu核数不一样可能是并行的,但是协程是在一个线程中 所以是并发