【算法竞赛进阶指南】 - 兔子与兔子
题目描述
很久很久以前,森林里住着一群兔子。
有一天,兔子们想要研究自己的 DNA 序列。
我们首先选取一个好长好长的 DNA 序列(小兔子是外星生物,DNA 序列可能包含 26 个小写英文字母)。
然后我们每次选择两个区间,询问如果用两个区间里的 DNA 序列分别生产出来两只兔子,这两个兔子是否一模一样。
注意两个兔子一模一样只可能是他们的 DNA 序列一模一样。
输入格式
第一行输入一个 DNA 字符串 S。
第二行一个数字 m,表示 m 次询问。
接下来 m 行,每行四个数字 l1,r1,l2,r2分别表示此次询问的两个区间,注意字符串的位置从1开始编号。
输出格式
对于每次询问,输出一行表示结果。
如果两只兔子完全相同输出 Yes,否则输出 No(注意大小写)。
数据范围
1≤length(S),m≤1000000
输入样例:
aabbaabb
3
1 3 5 7
1 3 6 8
1 2 1 2
输出样例:
Yes
No
Yes
| 难度:简单 |
| 时/空限制:1s / 64MB |
| 来源:《算法竞赛进阶指南》 |
第一次做字符串hash,学到了好多。
算法说明
本题使用的字符串hash函数BKDRhash是把一个任意长度的字符串映射成一个非负整数,并且其冲突概率几乎为0。是一种非常优秀且常用的算法。
方法是取一固定值p,把字符串看作p进制数,并分配一个大于0的数值,代表每种字符。这有点像数据结构中字符串关键词移位法的散列函数,但与散列函数使用32进制相比,一般来说,我们分配的数值都远小于p。举例来说我们为小写字母a~z分配数值1~26,而我们使用的p要比26大很多。一般来说我们取p = 131,p = 13331,这两个质数冲突很小,不要问为什么,我也不知道,记住就好,当然p = 233也是比较常见的,经过实测,这三个p值都可以AC。
然后取一固定值m,求该p进制数对m的余数,作为该字符串的hash值。书本中是取m = ![]()
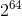 ,使用unsigned long long类型存储这个hash值,在溢出时,会自动对取模,这样可以避免低效的取模运算。当然也可自己找比较大的质数,看别人的博客时发现有人使用m = 19260817*19890604-19491001,经实测,可以AC本题,但一些比较常见的mod,比如1e9 + 7,1e9 + 9,998244353在本题中无法AC,可能是因为这些值太小,使冲突的概率变大。除了一些特殊构造的数据外,上述的p和m很难产生冲突。
,使用unsigned long long类型存储这个hash值,在溢出时,会自动对取模,这样可以避免低效的取模运算。当然也可自己找比较大的质数,看别人的博客时发现有人使用m = 19260817*19890604-19491001,经实测,可以AC本题,但一些比较常见的mod,比如1e9 + 7,1e9 + 9,998244353在本题中无法AC,可能是因为这些值太小,使冲突的概率变大。除了一些特殊构造的数据外,上述的p和m很难产生冲突。
对字符串的各种操作,都可以直接对p进制数进行算术运算反映到hash值上,我们可以通过简单的实例来理解。
例如,S = “abc”,D = “d”,T = “xyz”,
S表示为p进制数为 1 2 3
![]()
S + D表示为p进制数为1 2 3 4
![]()
S + T 表示为p进制数为 1 2 3 24 25 26
![]()
于是我们可以发现 ![]()
根据上面两种操作,我们可以通过O(n)的时间预处理字符串所有前缀的hash值,并在O(1)时间内查询任意字串的hash值,那么这题就可以写了。(参考《算法竞赛进阶指南)
代码:
#include
#include
using namespace std;
typedef unsigned long long ull;
typedef long long ll;
const int N = 1e6 + 5;
char s[N];
const int P = 131;
ll p[N], f[N];
void Hash(int n){
for (int i = 1; i <= n; i ++){
f[i] = (f[i - 1] * P + (s[i] - 'a' + 1));
p[i] = p[i - 1] * P;
}
}
int main()
{
cin >> (s + 1);
int n, m;
n = strlen(s + 1);
p[0] = 1;
Hash(n);
cin >> m;
for (int i = 0; i < m; i ++){
int l1, l2, r1, r2;
cin >> l1 >> r1 >> l2 >> r2;
if (f[r1] - f[l1 - 1] * p[r1 - l1 + 1] == f[r2] - f[l2 - 1] * p[r2 - l2 + 1]){
cout << "Yes" << endl;
}else cout << "No" << endl;
}
return 0;
}
然而,本题使用string类的compare函数也可以AC,但是直接使用cin,cout会TLE,可以用ios :: sync_with_stdio(false),注意,关闭同步流后,不能与scanf,printf 混用,当然,直接使用scanf,printf更快一些,实测大约快了200ms,不过hash是最快的,即使使用不关闭同步流的cin,cout,直接遍历区间内每个元素进行比较会超时。下面附上使用函数的AC代码
#include
#include
using namespace std;
int main()
{
ios :: sync_with_stdio(false);
string s;
cin >> s;
int m;
cin >> m;
for (int i = 0; i < m; i ++){
int l1, r1, l2, r2;
cin >> l1 >> r1 >> l2 >> r2;
if (s.compare(l1 - 1, r1 - l1 + 1, s , l2 - 1, r2 - l2 + 1) == 0)cout << "Yes" << endl;
//int compare(int pos, int n,const string &s,int pos2,int n2)const;//比较当前字符串从pos开始的n个字符组成的字符串与s中pos2开始的n2个字符组成的字符串的大小
else cout << "No" << endl;
}
return 0;
}