带你更好的入门 Spring Cloud 常用组件学习
一.微服务
1.什么是微服务?微服务之间如何独立通讯?
什么是微服务?微服务概念起源: Microservices
微服务是用一组小服务的方式来构建一个应用,服务独立运行在不同的进程中,服务之间通过轻量的通讯机制(如RESTful接口)来交互,并且服务可以通过自动化部署方式独立部署。正因为微服务架构中,服务之间是相互独立的,所以不同的服务可以使用不同的语言来开发,或者根据业务的需求使用不同类型的数据库。
- 微服务架构是一个分布式系统, 按照业务进行划分成为不同的服务单元, 解决单体系统性能等不足。
- 微服务是一种架构风格,一个大型软件应用由多个服务单元组成。系统中的服务单元可以单独部署,各个服务单元之间是松耦合的。
微服务之间如何独立通讯?
同步:
REST HTTP协议:REST 请求在微服务中是最为常用的一种通讯方式, 它依赖于 HTTP\HTTPS 协议。RESTFUL 的特点是:
- 每一个 URI 代表 1 种资源
- 客户端使用 GET、POST、PUT、DELETE 4 个表示操作方式的动词对服务端资源进行操作: GET 用来获取资源, POST 用来新建资源(也可以用于更新资源), PUT 用来更新资源, DELETE 用来删除资源
- 通过操作资源的表现形式来操作资源,资源的表现形式是 XML 或者 HTML
- 客户端与服务端之间的交互在请求之间是无状态的,从客户端到服务端的每个请求都必须包含理解请求所必需的信息
RPC TCP协议:RPC(Remote Procedure Call)远程过程调用,简单的理解是一个节点请求另一个节点提供的服务。它的工作流程是这样的:
1.执行客户端调用语句,传送参数 2. 调用本地系统发送网络消息 3. 消息传送到远程主机 4. 服务器得到消息并取得参数 5. 根据调用请求以及参数执行远程过程(服务) 6. 执行过程完毕,将结果返回服务器句柄 7. 服务器句柄返回结果,调用远程主机的系统网络服务发送结果 8. 消息传回本地主机 9. 客户端句柄由本地主机的网络服务接收消息 10. 客户端接收到调用语句返回的结果数据
异步:消息中间件
常见的消息中间件有 Kafka、RabbitMQ、RocketMQ、ActiveMQ , 常见的协议有AMQP、MQTTP、STOMP、XMPP。
2.微服务技术栈有哪些?
- 微服务开发:快速开发服务。Spring、SpringMVC、SpringBoot
- 微服务调用协议:REST、RPC(Remote Procedure Call)、RMI(Remote Method Invocation)
- 微服务注册发现:发现服务,注册服务,集中管理服务。Eureka、Zookeeper、Nacos、consul
- 微服务配置管理:统一管理一个或多个服务的配置信息, 集中管理。Disconf、SpringCloudConfig、Apollo
- 服务负载均衡:Ribbon(客户端)、Nginx(服务端)
- 服务熔断:当请求到达一定阈值时不让请求继续。Hystrix、Sentinel
- 服务接口调用:多个服务之间的通讯。Feign(HTTP)(HTTP)、Dubbo、Apache HttpClient、Spring RestTemplate
- API网关:外部请求通过 API 网关进行拦截处理, 再转发到真正的服务。Spring Cloud GateWay、Zuul
- 服务链路追踪:明确服务之间的调用关系。Zipkin、Brave
- 服务监控:以可视化或非可视化的形式展示出各个服务的运行情况 (CPU、内存、访问量等)。Zabbix、Nagios、Metrics
- 权限认证:根据系统设置的安全规则或者安全策略, 用户可以访问而且只能访问自己被授权的资源。Spring Security、Apache Shiro
- 批处理:批量处理同类型数据或事物。Spring Batch
- 定时任务:定时调度任务。Quartz、Elastic-job
- 消息队列:解耦业务, 异步化处理数据。Kafka、RabbitMQ、RocketMQ、ActiveMQ
- 日志采集(elk):收集各服务日志提供日志分析、用户画像等。Elasticsearch、Logstash、Kibana
- 数据存储:存储数据。关系型:MySql、Oracle、MsSQL、PostgreSql;非关系型:Mongodb、Elasticsearch
- 缓存:存储数据。redis
- 分库分表:数据库分库分表方案。ShardingSphere、Mycat
- 服务部署:将项目快速部署、上线、持续集成。Docker、Jenkins、Kubernetes(K8s)、Mesos
3.微服务的优缺点?
微服务优点:
- 服务简单,只关注一个业务功能
- 每个微服务可由不同团队开发
- 微服务是松散耦合的
- 可用不同的编程语言与工具开发
微服务缺点:
- 运维开销,DevOps要求
- 分布式链路追踪难
- 分布式系统的复杂性,当服务数量增加,管理越加复杂
4.Spring Cloud 和 Dubbo有哪些区别?
Dubbo是阿⾥巴巴公司开源的⼀个⾼性能优秀的服务框架,基于RPC调⽤,对于⽬前使⽤率较⾼的
Spring Cloud Netflix来说,它是基于HTTP的,所以效率上没有Dubbo⾼,但问题在于Dubbo体系的组件不全,不能够提供⼀站式解决⽅案,⽐如服务注册与发现需要借助于Zookeeper等实现,⽽Spring Cloud Netflix则是真正的提供了⼀站式服务化解决⽅案,且有Spring⼤家族背景。
参考:Java微服务框架全方位对比(Dubbo 和 Spring Cloud?)
Dubbo
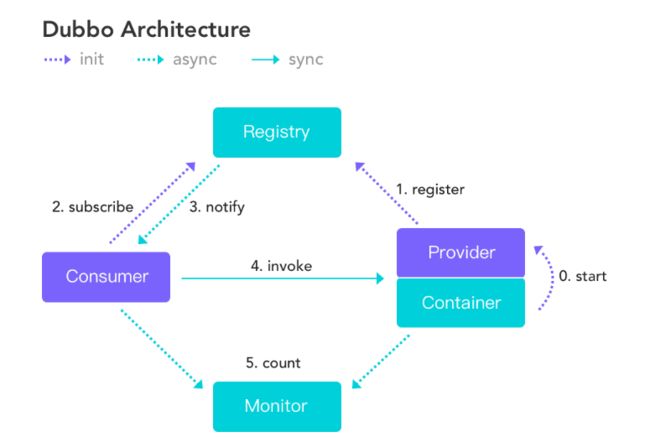
- 优点:
1.支持各种通信协议,而且消费方和服务方使用长链接方式交互,通信速度上略胜 ;
2.采用rpc方式,性能上比Spring Cloud的rpc更好;
3.dubbo的网络消耗小于springcloud
- 缺点:
1.如果我们使用配置中心、分布式跟踪这些内容都需要自己去集成;
2.开发难度较大,原因是dubbo的jar包依赖问题很多大型工程无法解决;
Spring Cloud

- 优点:
1、产出于Spring大家族,Spring在企业级开发框架中来头很大,可以保证后续的更新、完善。
2、spring cloud社区活跃,教程丰富,遇到问题很容易找到解决方案;
3、spring cloud功能比dubbo更加完善;
5、spring cloud采用rest访问方式,rest的技术无关性使用效果更棒;
6、spring cloud轻轻松松几行代码就完成了熔断、均衡负责、服务中心的各种平台功能;
7、从公司招聘工程师方面,spring cloud更有优势,因为其技术更新更炫;
8、提供了微服务的一整套解决方案:服务发现注册、配置中心、消息总线、负载均衡、断路器、数据监控等;作为一个微服务治理的大家伙,考虑的很全面,几乎服务治理的方方面面都考虑到了,方便开发开箱即用;
- 缺点:
1.如果对于系统的响应时间有严格要求,长链接更合适。
2.接口协议约定比较自由且松散,需要有强有力的行政措施来限制接口无序升级
5.Spring Cloud 与 Spring Boot 的关系?
Spring Boot 是 Spring 的一套快速配置脚手架,可以基于Spring Boot 快速开发单个微服务,Spring Cloud是一个基于Spring Boot实现的云应用开发工具;Spring Boot专注于快速、方便集成的单个微服务个体,Spring Cloud关注全局的服务治理框架;Spring Boot使用了默认大于配置的理念,很多集成方案已经帮你选择好了,能不配置就不配置,Spring Cloud很大的一部分是基于Spring Boot来实现,可以不基于Spring Boot吗?不可以。
总结:SpringBoot在Spring Clound中起到了承上启下的作用。Spring Boot可以离开Spring Cloud独立使用开发项目,但是Spring Cloud离不开Spring Boot,属于依赖的关系。
二.Eureka服务注册中心
1.什么是Eureka
注册中心:一个中心化组件来进行服务的登记和管理,管理所有服务信息和状态。注册中心有 Eureka、Nacos、Consul、Zookeeper,之间的对比为下图:

Eureka是Netflix开发的服务发现框架,是一个RESTful风格的服务,是一个用于服务发现和注册的基础组件,是搭建Spring Cloud微服务的前提之一,它屏蔽了Server和client的交互细节,使得开发者将精力放到业务上。
服务注册与发现包括两个部分:服务端(Eureka Server)和客服端(Eureka Client)

- 服务端(Eureka Server):一个公共服务,为Client提供服务注册和发现的功能,维护注册到自身的Client的相关信息,同时提供接口给Client获取注册表中其他服务的信息,使得动态变化的Client能够进行服务间的相互调用。
- 客户端(Eureka Client):Client将自己的服务信息通过一定的方式登记到Server上,并在正常范围内维护自己信息一致性,方便其他服务发现自己,同时可以通过Server获取到自己依赖的其他服务信息,完成服务调用,还内置了负载均衡器,用来进行基本的负载均衡。
2.Eureka的一些基础概念
服务注册 Register:当 Eureka 客户端向 Eureka Server 注册时,它提供自身的元数据,比如IP地址、端口,运行状况指示符URL,主页等。
服务续约 Renew:Eureka 客户会每隔30秒(默认情况下)发送一次心跳来续约。 通过续约来告知 Eureka Server 该 Eureka 客户仍然存在,没有出现问题。 正常情况下,如果 Eureka Server 在90秒没有收到 Eureka 客户的续约,它会将实例从其注册表中删除。
获取注册列表信息 Fetch Registries: Eureka 客户端从服务器获取注册表信息,并将其缓存在本地。客户端会使用该信息查找其他服务,从而进行远程调用。该注册列表信息定期(每30秒钟)更新一次。每次返回注册列表信息可能与 Eureka 客户端的缓存信息不同, Eureka 客户端自动处理。如果由于某种原因导致注册列表信息不能及时匹配,Eureka 客户端则会重新获取整个注册表信息。 Eureka 服务器缓存注册列表信息,整个注册表以及每个应用程序的信息进行了压缩,压缩内容和没有压缩的内容完全相同。Eureka 客户端和 Eureka 服务器可以使用JSON / XML格式进行通讯。在默认的情况下 Eureka 客户端使用压缩 JSON 格式来获取注册列表的信息。
服务下线 Cancel:Eureka客户端在程序关闭时向Eureka服务器发送取消请求。 发送请求后,该客户端实例信息将从服务器的实例注册表中删除。该下线请求不会自动完成,它需要调用以下内容:DiscoveryManager.getInstance().shutdownComponent();
服务剔除 Eviction: 在默认的情况下,当Eureka客户端连续90秒(3个续约周期)没有向Eureka服务器发送服务续约,即心跳,Eureka服务器会将该服务实例从服务注册列表删除,即服务剔除。
3.Eureka基础架构
Eureka通过心跳检测、健康检查和客户端缓存等机制,提高系统的灵活性、伸缩性和可用性。https://github.com/Netflix/eureka/wiki/Eureka-at-a-glance

Eureka包含两个组件:Eureka Server 和 Eureka Client,Eureka Server提供服务发现的能力,各个微服务启动时会通过 Eureka Client 向 Eureka Server 进行注册自己的信息,Eureka Server 会存储该服务的信息。
- 服务提供者向Eureka Server中注册服务,Eureka Server接受到注册事件会在集群和分区中进行数据同步,服务消费者可以从注册中心获取服务注册信息,进行服务调用
- 每个Eureka Server同时也是Eureka Client,多个Eureka Server之间通过复制方式完成服务注册列表的同步
- 微服务启动后会周期性的向Eureka Server发送心跳(默认周期为30秒)以续约自己的信息
- Eureka Server在一定时间内(默认为90秒)没有接受到某个微服务的心跳,将会注销掉该微服务节点
- Eureka Client会缓存Eureka Server中的信息,当所有的Eureka Server节点都宕机,服务消费者依然可以使用缓存中的信息找到服务提供者
4.Eureka元数据
Eureka元数据有两种:标准元数据和自定义元数据。
- 标准元数据:主机名、IP地址、端口号等信息,这些信息都会发布到服务注册列表中,用于服务之间调用
- 自定义元数据:可以在application.yml中配置 eureka.instance.metadata-map配置,符合key/value的存储格式。这些数据可以在远程客服端中访问
如:
eureka:
instance:
metadata-map:
# ⾃定义元数据(key/value⾃定义)
cluster: cl1
region: rn1
在应用程序中可以使用DiscoveryClient获取指定微服务的所有元数据信息:
// 从EurekaServer获取指定微服务实例
List<ServiceInstance> serviceInstanceList =discoveryClient.getInstances("service-user");
通过debug可以看到自定义的元数据:

5.Eureka常用配置
服务端配置:在spring boot启动类中设置 @EnableEurekaServer 注解开启 Eureka 服务
eureka:
instance:
hostname: xxxxx # 主机名称
prefer-ip-address: true/false # 注册时显示ip
server:
enableSelfPreservation: true # 启动自我保护
renewalPercentThreshold: 0.85 # 续约配置百分比
客服端配置:在spring boot启动类中设置 @EnableDiscoveryClient 注解开启 Eureka 服务
eureka:
client:
register-with-eureka: true/false # 是否向注册中心注册自己
fetch-registry: # 指定此客户端是否能获取eureka注册信息
service-url: # 暴露服务中心地址
defaultZone: http://xxxxxx # 默认配置
instance: instance-id: xxxxx # 指定当前客户端在注册中心的名称
6.Eureka Client客户端
服务提供者向Eureka服务端注册服务,并完成服务续约等⼯作,服务消费者获取服务列表。
服务注册(服务提供者):
- 添加eureka-client依赖,配置Eureka服务注册中心地址
- 服务启动时会向注册中心发起注册请求,携带服务元数据信息
- Eureka注册中心会把服务节点的相关信息保存到Map中
服务续约(服务提供者):
服务每隔30秒会向注册中心续约(心跳检测)一次,若没有续约,租约在90秒后到期,然后服务失效。
配置文件中配置:一般不需要调整
# 向Eureka服务中⼼集群注册服务
eureka:
instance:
# 租约续约间隔时间,默认30秒
lease-renewal-interval-in-seconds: 30
# 租约到期,服务时效时间,默认值90秒,服务超过90秒没有发⽣⼼跳,EurekaServer会将服务从列表移除
lease-expiration-duration-in-seconds: 90
获取服务列表(服务消费者):
服务消费者启动后会从Eureka Server服务列表中获取只读备份服务列表清单,缓存到本地。每隔30秒会重新获取并更新数据,时间间隔可以通过配置eureka.client.registry-fetch-interval-seconds修改。
#向Eureka服务中⼼集群注册服务
eureka:
client:
# 每隔多久拉取⼀次服务列表
registry-fetch-interval-seconds: 30
7.Eureka Server服务端
服务下线:当服务正常关闭时会发送服务下线的rest请求给Eureka服务端,注册中心接口请求后将该服务置为下线状态。
失效剔除:Eureka Server会定时(每隔60秒 eureka.server.eviction-interval-timer-in-ms)进行检查,若服务节点在一点个时间(默认90秒 eureka.instance.lease-expiration-duration-in- seconds)内没有收到心跳,会注销该实例。
为什么会有自我保护:默认情况下,如果Eureka Server在⼀定时间内(默认90秒)没有接收到某个微服务实例的⼼跳,Eureka Server将会移除该实例。但是当⽹络分区故障发⽣时,微服务与Eureka Server之间⽆法正常通信,⽽微服务本身是正常运⾏的,此时不应该移除这个微服务,所以引⼊了⾃我保护机制。
自我保护开启:如果在15分钟内超过85%的客户端节点都没有正常的⼼跳,那么Eureka就认为客户端与注册中⼼出现了⽹络故障,Eureka Server⾃动进⼊⾃我保护机制。
服务中⼼⻚⾯会显示如下提示信息:

自我保护模式时:
- 不会剔除任何服务实例(可能是服务提供者和EurekaServer之间⽹络问题),保证了⼤多数服务依然可⽤
- Eureka Server仍然能够接受新服务的注册和查询请求,但是不会被同步到其它节点上,保证当前节点依然可⽤,当⽹络稳定时,当前Eureka Server新的注册信息会被同步到其它节点中
在Eureka Server⼯程中通过eureka.server.enable-self-preservation配置可⽤关停⾃我保护,默认值是打开:
eureka:
server:
enable-self-preservation: false # 关闭⾃我保护模式(缺省为打开)
总结和参考
服务提供者启动时会向注册中心发起注册请求,携带服务元数据信息,并每隔30秒会向注册中心发起一次心跳来续约。若没有续约,则租约90秒到期后服务失效。服务消费者从注册中心获取只读备份列表清单并缓存到本地,每隔30秒重新获取并更新数据。
Eureka 客户端正常关闭时,服务端会将服务置为下线状态(不会自动完成);服务端每隔60秒定时检查,若发现实例在90秒内没有收到心跳,会注销该实例;在15分钟内超过85%的客服端节点都没有正常的心跳,服务端会进入自我保护模式,不会剔除任何服务实例,仍然可以接受新的服务注册和查询请求。
Eureka(AP)通过心跳检测、健康检查和客户端缓存等机制,提高系统的灵活性、伸缩性和可用性。
参考链接:
- 深入浅出 Spring Cloud 之 Eureka
- 深入理解Eureka(源码)
- SpringColud Eureka的服务注册与发现
三.Ribbon负载均衡
1.负载均衡概述
负载均衡一般分为服务器端负载均衡和客服端负载均衡:
- 服务端负载均衡,比如Nginx、F5这些,请求到达服务器之后由这些负载均衡器根据一定的算法将请求路由到目标服务器处理
- 客服端负载均衡,比如Ribbon,服务消费者客户端会有一个服务器地址列表,调用方在请求前通过一定的负载均衡算法选择一个服务器进行访问,负载均衡算法的执行是在请求客户端进行
Ribbon是Netflix发布的负载均衡器。Eureka一般配合Ribbon进行使用,Ribbon利用从Eureka中读取到服务信息,在调用服务提供者提供的服务时,会根据一定的算法进行负载。
2.Ribbon核心组件IRule
所谓的负载均衡策略,就是当A服务调用B服务时,此时B服务有多个实例,这时A服务以何种方式来选择调用的B实例,ribbon可以选择以下几种负载均衡策略。
IRule:根据特定算法中从服务列表中选取一个要访问的服务:
- RoundRobinRule: 轮询策略。
- RandomRule: 随机策略。
- AvailabilityFilteringRule: 可用过滤策略。会先过滤掉由于多次访问故障而处于断路跳闸状态的服务,还有并发的连接数量超过阀值的服务,然后对剩余的服务列表按照轮询策略进行访问
- WeightedResponseTimeRule: 权重轮询策略。根据平均响应时间计算所有服务的权重,响应时间越快服务权重越大,被选中的概率越高,刚启动时,如果统计信息不足,则使用RoundRobinRule策略,等统计信息足够,会切换到WeightedResponseTimeRule
- RetryRule: 重试策略。在RoundRobinRule的基础上添加重试机制,即在指定的重试时间内,反复使用线性轮询策略来选择可用实例
- BestAvailableRule: 最小连接数策略。先过滤掉由于多次访问故障而处于断路器跳闸状态的服务,然后选择一个并发量最小的服务
- ZoneAvoidanceRule: 区域权衡策略(默认规则)。采用双重过滤,同时过滤不是同一区域的实例和故障实例,选择并发较小的实例
Ribbon已有策略应用:
全局设置:
@Configuration
public class ConfigBean {
@Bean
@LoadBalanced
public RestTemplate getRestTemplate(){
return new RestTemplate();
}
//用新定义的负载均衡规则覆盖默认的负载均衡规则
@Bean
public IRule myRule(){
//return new RoundRobinRule();// todo 轮询
//return new RandomRule();//todo 随机
return new RetryRule();//todo 先按照轮询的策略获取服务,如果获取服务失败则在指定时间内会进行重试,获取可用的服务
}
}
局部设置:修改配置文件指定服务的负载均衡策略。格式:服务应用名.ribbon.NFLoadBalancerRuleClassName
#针对的被调用方微服务名称,不加就是全局生效
# service-provider 为调用的服务的名称
service-provider:
ribbon:
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule # 负载策略调整
自定义Ribbon的负载均衡策略:
- 启动类添加@RibbonClient:在启动该微服务的时候就能去加载我们的自定义Ribbon配置类,从而使配置生效
- 注意配置细节:官方文档明确给出了警告,自定义配置类不能放在@ComponentScan所描述的当前包下以及其子包下否则这个配置类就会被所有的Ribbon客户端所共享,达不到特殊化定制的目的
需求:依旧轮询策略,但是加上新需求,每台服务器要求被调用5次
-
主启动类添加注解:
@RibbonClient(name = "MICROSERVICECLOUD-DEPT",configuration = MySelfRule.class) -
注入自定义负载均衡算法:
@Configuration public class MySelfRule { @Bean public IRule myRule(){ return new RandomRule_ZY();//todo 自定义负载均衡算法 } } -
自定义算法:
public class RandomRule_ZY extends AbstractLoadBalancerRule { public Server choose(ILoadBalancer lb, Object key) { // ...... } @Override public void initWithNiwsConfig(IClientConfig iClientConfig) { } @Override public Server choose(Object key) { return this.choose(this.getLoadBalancer(), key); } }
3.Ribbon常用配置
全局配置:
ribbon:
ConnectTimeout: 1000 #服务请求连接超时时间(毫秒)
ReadTimeout: 3000 #服务请求处理超时时间(毫秒)
OkToRetryOnAllOperations: true #对超时请求启用重试机制
MaxAutoRetriesNextServer: 1 #切换重试实例的最大个数
MaxAutoRetries: 1 # 切换实例后重试最大次数
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule #修改负载均衡算法
指定服务进行配置:与全局配置的区别就是ribbon节点挂在服务名称下面,如下是对ribbon-service调用user-service时的单独配置
user-service:
ribbon:
ConnectTimeout: 1000 #服务请求连接超时时间(毫秒)
ReadTimeout: 3000 #服务请求处理超时时间(毫秒)
OkToRetryOnAllOperations: true #对超时请求启用重试机制
MaxAutoRetriesNextServer: 1 #切换重试实例的最大个数
MaxAutoRetries: 1 # 切换实例后重试最大次数
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule #修改负载均衡算法
4.Ribbon应用和原理
不需要引用额外的Jar坐标,因为在服务消费者中我们引用过eureka-client,它会引用Ribbon相关Jar包。
使用@LoadBalanced注解赋予RestTemplate负载均衡的能力:可以看出使用Ribbon的负载均衡功能非常简单,和直接使用RestTemplate没什么两样,只需给RestTemplate添加一个@LoadBalanced即可。
@Configuration
public class RibbonConfig {
@Bean
@LoadBalanced // Ribbon负载均衡
public RestTemplate restTemplate(){
return new RestTemplate();
}
}
原理:
LoadBalancerClient 接口中定义了 ServiceInstance choose(String serviceId) 方法,根据服务名获取具体的服务实例;
SpringClientFactory 类中定义了 Map
- IClientConfig:定义了客户端配置,用于初始化客户端以及负载均衡配置;默认值DefaultClientConfigImpl
- IRule:负载均衡的策略,比如轮询等;默认值ZoneAvoidanceRule
- IPing:定义了如何确定服务实例是否正常;默认值DumyPing
- ServerList:定义了获取服务器列表的方法;默认值 Ribbon:
ConfigurationBasedServerList
Spring Cloud Alibaba:NacosServerList - ServerListFilter:根据配置或者过滤规则选择特定的服务器列表;默认值ZonePreferenceServerListFilter
- ServerListUpdater:定义了动态更新服务器列表的策略。默认值PollingServerListUpdater
以上默认实现参考 RibbonClientConfiguration. ZoneAwareLoadBalancer,关系图如下:

AnnotationConfigApplicationContext 中确定 ILoadBalancer 的次序是:优先通过外部配置导入,其次是配置类。
Ribbon默认是懒加载的。当服务起动好之后,第一次请求是非常慢的,第二次之后就快很多。开启饥饿加载:
ribbon:
eager-load:
enabled: true #开启饥饿加载
clients: server-1,server-2,server-3 #为哪些服务的名称开启饥饿加载,多个用逗号分隔
参考
- Spring Cloud Ribbon 源码解析
- Spring Cloud Ribbon:负载均衡的服务调用
- Ribbon源码解析
四.Hystrix熔断器
Hystrix 组件是 SpringCloud 提供的服务保护框架。又称断路器,俗称“豪猪”,具有自我保护能力。
1.雪崩效应
连环雪崩效应:微服务中一个请求可能需要多个微服务接口才能实现,会形成复杂的调用链路。当扇出的链路上某个微服务的响应时间过长或不可用,导致所有的请求都处于延迟状态,若延迟到达系统最大值,可能会使系统资源耗尽,导致整个分布式系统都不可用。
- 扇入:代表该微服务被调用的次数,次数越大,该模块的复用性越好
- 扇出:代表该微服务调用其他微服务的个数,个数越多,该模块业务就越复杂
Hystrix保证服务高可用的3个技术:服务熔断、服务降级、线程隔离
- 服务熔断:当一个服务在一定时间内,接口被调用失败次数达到一个阈值或百分比,会开启熔断器,在服务熔断期间,服务会拒绝客户端访问开启熔断的接口。
- 服务降级:如果接口设置了降级方法,当调用接口失败、超时、拒绝访问,则会触发调用降级方法并返回结果给用户
- 线程隔离:对接口另外创建线程池。对调用频率高的接口,防止该接口把 web 容器的线程池消耗光,对该接口进行线程隔离。
通过服务熔断和接口降级,当接口调用失败、超时、被拒,能够及时返回友好提示给客户端,同时也减轻服务压力,保证服务的高可用。服务熔断一般是某个服务故障引起,而服务降级一般是从整体负荷考虑;服务降级一定会出现服务熔断,而服务熔断不一定会出现服务降级。通过线程隔离,解决雪崩效应和连环雪崩效应,保证服务的高可用。
Hystrix 比较消耗服务器资源,所以仅给服务中并发量较高的接口开启 Hystrix 保护即可。Hystrix 通过 @HystrixCommand() 给接口进行增强。@HystrixCommand() 内部可以配置熔断时间等参数,@HystrixCommand() 中配置的参数会覆盖 application.yml 中配置的 Hystrix 参数。
2.Hystrix应用和相关配置
2.1 引入依赖:
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-netflix-hystrixartifactId>
dependency>
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-netflix-eureka-clientartifactId>
dependency>
2.2 全局配置:
hystrix:
command: #用于控制HystrixCommand的行为
default:
execution:
isolation:
strategy: THREAD #控制HystrixCommand的隔离策略,THREAD->线程池隔离策略(默认),SEMAPHORE->信号量隔离策略
thread:
timeoutInMilliseconds: 1000 #配置HystrixCommand执行的超时时间,执行超过该时间会进行服务降级处理,默认1s
interruptOnTimeout: true #配置HystrixCommand执行超时的时候是否要中断
interruptOnCancel: true #配置HystrixCommand执行被取消的时候是否要中断
timeout:
enabled: true #配置HystrixCommand的执行是否启用超时时间
semaphore:
maxConcurrentRequests: 10 #当使用信号量隔离策略时,用来控制并发量的大小,超过该并发量的请求会被拒绝。最大并发请求,默认为:10 条。当该接口已经接收 10 条请求在处理,后续请求触发熔断
fallback:
enabled: true #用于控制是否启用服务降级
circuitBreaker: #用于控制HystrixCircuitBreaker的行为
enabled: true #用于控制断路器是否跟踪健康状况以及熔断请求
requestVolumeThreshold: 20 #窗口时间内允许接口调用报错的请求数,默认20
errorThresholdPercentage: 50 # 窗口时间内允许接口调用报错占总请求数的百分比。默认:50%
sleepWindowInMilliseconds: 5000 # 熔断后休眠时⻓。默认:5000ms
forceOpen: false #强制打开断路器,拒绝所有请求
forceClosed: false #强制关闭断路器,接收所有请求
requestCache:
enabled: true #用于控制是否开启请求缓存
metrics:
rollingStats:
### 默认10秒钟内,请求次数达到20个,并且失败率在50%以上就跳闸,跳闸后活动窗⼝为5s
### 窗口时间,默认:10000ms,即 10s。timeInMilliseconds/numBuckets
### 每隔 1s 就会统计这 1s 内请求:success、failure、timeout、rejection 请求的数量
timeInMilliseconds: 10000
### 桶的数量。默认:10。设置 numBuckets 的值时,保证 timeInMilliseconds % numBuckets == 0 即可
numBuckets: 10
collapser: #用于控制HystrixCollapser的执行行为
default:
maxRequestsInBatch: 100 #控制一次合并请求合并的最大请求数
timerDelayinMilliseconds: 10 #控制多少毫秒内的请求会被合并成一个
requestCache:
enabled: true #控制合并请求是否开启缓存
threadpool: #用于控制HystrixCommand执行所在线程池的行为
default:
coreSize: 10 #线程池的核心线程数,默认10
maximumSize: 10 #线程池的最大线程数,超过该线程数的请求会被拒绝
maxQueueSize: -1 #用于设置线程池的最大队列大小,-1采用SynchronousQueue,其他正数采用LinkedBlockingQueue
queueSizeRejectionThreshold: 5 #用于设置线程池队列的拒绝阀值,由于LinkedBlockingQueue不能动态改版大小,使用时需要用该参数来控制线程数,默认5
# springboot中暴露健康检查等断点接⼝观察跳闸状态
management:
endpoints:
web:
exposure:
include: "*"
# 暴露健康接⼝的细节
endpoint:
health:
show-details: always
### 访问健康检查接⼝:http://localhost:8090/actuator/health
实例配置:实例配置只需要将全局配置中的default换成与之对应的key即可
hystrix:
command:
HystrixComandKey: #将default换成HystrixComrnandKey
execution:
isolation:
strategy: THREAD
collapser:
HystrixCollapserKey: #将default换成HystrixCollapserKey
maxRequestsInBatch: 100
threadpool:
HystrixThreadPoolKey: #将default换成HystrixThreadPoolKey
coreSize: 10
配置文件中相关key的说明:
- HystrixComandKey对应@HystrixCommand中的commandKey属性;
- HystrixCollapserKey对应@HystrixCollapser注解中的collapserKey属性;
- HystrixThreadPoolKey对应@HystrixCommand中的threadPoolKey属性。
2.3 启动类上添加注解 @EnableCircuitBreaker 来开启Hystrix的断路器功能。@EnableCircuitBreaker,@EnableDiscoveryClient,@SpringBootApplication 这三个注解可以使用**@SpringCloudApplication**来替代。
2.4 给接口添加Hystrix修饰,增强接口的高可用性。使用 @HystrixCommand() 注解。注意:失败调用的方法方法参数和返回值必须和原方法相同。服务降级只作用在消费端。
@RestController
public class MemberController {
// 1. 设置回调方法;设置忽略的异常,如果是报这个异常,Hystrix 不会进行捕获并执行降级方法,接口会直接抛出异常
@HystrixCommand(fallbackMethod = "inserMemberFallback", ignoreExceptions =
{
ArithmeticException.class})
@GetMapping("/member/insert")
public String insertMember() {
int i = 10/0;
return "添加会员信息成功!";
}
// 2.设置 commandProperties 参数,设置窗口时间内允许的错误请求阈值,错误请求百分比,熔断器持续时间配置;
// 设置 threadPoolProperties 参数,设置线程隔离的线程池线程数,最大等待请求数
@HystrixCommand(
fallbackMethod = "deleteMemberFallback",
commandProperties = {
@HystrixProperty(name = "circuitBreaker.requestVolumeThreshold", value =
"5"),
@HystrixProperty(name = "circuitBreaker.sleepWindowInMilliseconds",value
="30000"),
@HystrixProperty(name = "circuitBreaker.errorThresholdPercentage",value
="60")
}
)
@GetMapping("/member/delete/{id}")
public String deleteMember(@PathVariable("id") String id) {
if("1".equals(id)) {
int i = 10/0;
}
return "删除会员信息成功";
}
@HystrixCommand(
// 线程池标识,要保持唯⼀,不唯⼀的话就共⽤了
threadPoolKey = "findResumeOpenStateTimeoutFallback",
// 线程池细节属性配置
threadPoolProperties = {
@HystrixProperty(name="coreSize",value = "1"), // 线程数
@HystrixProperty(name="maxQueueSize",value="20") // 等待队列⻓度
},
// commandProperties熔断的⼀些细节属性配置
commandProperties = {
// 每⼀个属性都是⼀个HystrixProperty
@HystrixProperty(name="execution.isolation.thread.timeoutInMilliseconds",
value="2000"),
// hystrix⾼级配置,定制⼯作过程细节
// 8秒钟内,请求次数达到2个,并且失败率在50%以上就跳闸,跳闸后活动窗⼝设置为3s
// 统计时间窗⼝定义
@HystrixProperty(name = "metrics.rollingStats.timeInMilliseconds",value =
"8000"),
// 统计时间窗⼝内的最⼩请求数
@HystrixProperty(name = "circuitBreaker.requestVolumeThreshold",value =
"2"),
// 统计时间窗⼝内的错误数量百分⽐阈值
@HystrixProperty(name = "circuitBreaker.errorThresholdPercentage",value =
"50"),
// ⾃我修复时的活动窗⼝⻓度
@HystrixProperty(name = "circuitBreaker.sleepWindowInMilliseconds",value =
"3000")
},
fallbackMethod = "myFallBack" // 回退⽅法
)
@GetMapping("/checkStateTimeoutFallback/{userId}")
public Integer findResumeOpenStateTimeoutFallback(@PathVariable Long userId) {
// 使⽤ribbon不需要我们⾃⼰获取服务实例然后选择⼀个那么去访问了(⾃⼰的负载均衡)
String url = "http://service-resume/resume/openstate/" + userId;
Integer forObject = restTemplate.getForObject(url, Integer.class);
return forObject;
}
// 注意:该⽅法形参和返回值与原始⽅法保持⼀致
public Integer myFallBack(Long userId) {
return -123333; // 兜底数据
}
public String inserMemberFallback() {
return "调用 insertMember() 失败,执行降级方法!";
}
public String deleteMemberFallback(String id) {
return "调用 deleteMember() 失败,执行降级方法!";
}
}
3.HystrixCommand注解详解
@HystrixCommand中的常用参数:
- fallbackMethod:指定服务降级处理方法;
- ignoreExceptions:忽略某些异常,不发生服务降级;
- commandKey:命令名称,用于区分不同的命令;
- groupKey:分组名称,Hystrix会根据不同的分组来统计命令的告警及仪表盘信息;
- threadPoolKey:线程池名称,用于划分线程池。
测试案例:
// 设置命令、分组及线程池名称
@HystrixCommand(fallbackMethod = "getDefaultUser",
commandKey = "getUserCommand",
groupKey = "getUserGroup",
threadPoolKey = "getUserThreadPool")
public CommonResult getUserCommand(@PathVariable Long id) {
return restTemplate.getForObject(userServiceUrl + "/user/{1}", CommonResult.class, id);
}
// 使用ignoreExceptions忽略某些异常降级
@HystrixCommand(fallbackMethod = "getDefaultUser2", ignoreExceptions = {
NullPointerException.class})
public CommonResult getUserException(Long id) {
if (id == 1) {
throw new IndexOutOfBoundsException();
} else if (id == 2) {
throw new NullPointerException();
}
return restTemplate.getForObject(userServiceUrl + "/user/{1}", CommonResult.class, id);
}
public CommonResult getDefaultUser(@PathVariable Long id) {
User defaultUser = new User(-1L, "defaultUser", "123456");
return new CommonResult<>(defaultUser);
}
public CommonResult getDefaultUser2(@PathVariable Long id, Throwable e) {
LOGGER.error("getDefaultUser2 id:{},throwable class:{}", id, e.getClass());
User defaultUser = new User(-2L, "defaultUser2", "123456");
return new CommonResult<>(defaultUser);
}
4.Hystrix的请求缓存
当系统并发量越来越大时,我们需要使用缓存来优化系统,达到减轻并发请求线程数,提供响应速度的效果。
相关注解:
- @CacheResult:开启缓存,默认所有参数作为缓存的key,cacheKeyMethod可以通过返回String类型的方法指定key;
- @CacheKey:指定缓存的key,可以指定参数或指定参数中的属性值为缓存key,cacheKeyMethod还可以通过返回String类型的方法指定;
- @CacheRemove:移除缓存,需要指定commandKey。
测试案例:
@CacheResult(cacheKeyMethod = "getCacheKey")
@HystrixCommand(fallbackMethod = "getDefaultUser", commandKey = "getUserCache")
public CommonResult getUserCache(Long id) {
LOGGER.info("getUserCache id:{}", id);
return restTemplate.getForObject(userServiceUrl + "/user/{1}", CommonResult.class, id);
}
/**
* 为缓存生成key的方法
*/
public String getCacheKey(Long id) {
return String.valueOf(id);
}
// 远程微服务被调用方法
@GetMapping("/testCache/{id}")
public CommonResult testCache(@PathVariable Long id) {
userService.getUserCache(id);
userService.getUserCache(id);
userService.getUserCache(id);
return new CommonResult("操作成功", 200);
}
上面远程调用testCache方法,里面查询了3次id值,但在控制台里只打印了一次日志,即有两次走的是缓存。
在缓存使用过程中,我们需要在每次使用缓存的请求前后对HystrixRequestContext进行初始化和关闭,否则会出现如下异常:
java.lang.IllegalStateException: Request caching is not available. Maybe you need to initialize the HystrixRequestContext?
at com.netflix.hystrix.HystrixRequestCache.get(HystrixRequestCache.java:104) ~[hystrix-core-1.5.18.jar:1.5.18]
at com.netflix.hystrix.AbstractCommand$7.call(AbstractCommand.java:478) ~[hystrix-core-1.5.18.jar:1.5.18]
at com.netflix.hystrix.AbstractCommand$7.call(AbstractCommand.java:454) ~[hystrix-core-1.5.18.jar:1.5.18]
可以使用过滤器,在每个请求前后初始化和关闭HystrixRequestContext:
@Component
@WebFilter(urlPatterns = "/*",asyncSupported = true)
public class HystrixRequestContextFilter implements Filter {
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
HystrixRequestContext context = HystrixRequestContext.initializeContext();
try {
filterChain.doFilter(servletRequest, servletResponse);
} finally {
context.close();
}
}
}
参考
- Spring Cloud Hystrix:服务容错保护
- Hystrix Dashboard:断路器执行监控
- Hystrix 超时配置的N种玩法
- 带你走进 SpringCloud2.0(五):Hystrix
- Hystrix Dashboard:断路器执行监控
五.Feign远程调用组件
1.Feign概述
Feign是Netflix开发的一个轻量级RESTful的HTTP服务客户端,是以Java接口注解的方式调用Http请求,而不用像Java中通过封装HTTP请求报文的方式直接调用,Feign被广泛应用在Spring Cloud 的解决方案中。
- Feign不需要我们去拼接url然后调用restTemplate的api,在SpringCloud中,创建一个接口(消费者端)并在接口上添加相关注解
- SpringCloud对Feign进行了增强,使Feign支持SpringMVC注解(OpenFeign)
本质:封装了Http调用流程,面向接口化编程,类似Dubbo的服务调用。
2.Feign的应用
Netflix 的 Open Feign 是 Spring 弃用 Ribbion 的 RestTemplate 的替代方案。在消费者端定义与服务端映射的接口,然后你就可以通过调用消费者端的接口方法来调用提供者端的服务了(目标REST服务),除了编写接口的定义,开发人员不需要编写其他调用服务的代码,是现在常用的方案。
引入依赖:
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-openfeignartifactId>
dependency>
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-netflix-eureka-serverartifactId>
dependency>
根据需要选择添加Feign相关配置:
feign:
client:
config:
default:
connectTimeout: 5000 # 指定Feign客户端连接提供者的超时时限,取决于网络环境 ************
readTimeout: 5000 # 指定Feign客户端从请求到获取到提供者给出的响应的超时时限 取决于业务逻辑运算时间 ************
compression:
request:
enabled: true # 开启对请求的压缩
mime-types: text/xml,application/xml,application/json
min-request-size: 2048 # 指定启用压缩的最小文件大小
response:
enabled: true # 开启对响应的压缩
hystrix:
enabled: true # 开启熔断功能
command:
default:
circuitBreaker:
sleepWindowInMilliseconds: 30000
requestVolumeThreshold: 50
execution:
timeout:
enabled: true
isolation:
strategy: SEMAPHORE
semaphore:
maxConcurrentRequests: 50
thread:
timeoutInMilliseconds: 100000 # 全局超时熔断时间 ************
ribbon:
#请求连接超时时间 ************
ConnectTimeout: 2000
#请求处理超时时间 ************
ReadTimeout: 5000
#对所有操作都进⾏重试
OkToRetryOnAllOperations: true
####根据如上配置,当访问到故障请求的时候,它会再尝试访问⼀次当前实例(次数由MaxAutoRetries配置),
####如果不行,就换一个实例进行访问,如果还不行,再换一次实例访问(更换次数由MaxAutoRetriesNextServer配置),
####如果依然不行,返回失败信息。
MaxAutoRetries: 0 #对当前选中实例重试次数,不包括第⼀次调⽤
MaxAutoRetriesNextServer: 0 #切换实例的重试次数
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RoundRobinRule #负载策略调整
启动类上添加 @EnableFeignClients 注解来启用 Feign 客户端
远程调用client service层:
// 使用@FeignClient表示服务 这里的值是提供者的名称
// name属性用于指定调用服务提供者名称,和服务提供者yaml文件中spring.application.name保持一致
@FeignClient(name="provider-application")// 这里的值是提供者相应的路径
@RequestMapping("/provider")
public interface FeginService {
// 这里的路径也要和提供者相同 参数也需要一样
// 参数绑定时可以使用@PathVariable、@RequestParam、@RequestHeader等,value属性必选设置
@GetMapping("/{id}")
Map providerMethod(@PathVariable(value = "id") int id);
}
controller层:
@RestController
public class FeignController {
// 调用服务
@Autowired
private FeginService feginService;
@RequestMapping(value = "/consumer/{id}")
public Map consumerTest(@PathVariable(value = "id")Integer id) {
return feginService.providerMethod(id);
}
}
Feign注解剖析
@FeignClient注解主要被@Target({ElementType.TYPE})修饰,表示该注解主要使用在接口上。它具备了如下的属性:
- name:指定FeignClient的名称,如果使用了Ribbon,name就作为微服务的名称,用于服务发现
- path:定义当前FeignClient的统一前缀
- fallback:定义容错的处理类,当调用远程接口失败或者超时时,会调用对应的接口的容错逻辑,fallback指定的类必须实现@Feign标记的接口
- fallbacjFactory:工厂类,用于生成fallback类实例,通过这个属性可以实现每个接口通用的容错逻辑们介绍重复的代码
- configuration:Feign配置类,可以自定或者配置Feign的Encoder,Decoder,LogLevel,Contract
- url:url一般用于调试,可以指定@FeignClient调用的地址
- decode404:当发生404错误时,如果该字段为true,会调用decoder进行解码,否则抛出FeignException
3.Feign超时设置
Feign的调用分两层,即Ribbon层的调用和Hystrix的调用,高版本的Hystrix默认是关闭的。
对负载均衡ribbon的支持:Feign默认的请求处理超时时长1s,可以调整请求处理超时时长,Feign自己有超时设置,如果配置Ribbon的超时,则会以Ribbon的为准。可以通过 ribbon.xx 来进行全局配置,也可以通过 服务名.ribbon.xx 来对指定服务进行细节配置。

若出现上面错误,需要添加下列配置:Feign的超时时长设置就是下面Ribbon的超时时长设置
ribbon:
#请求连接超时时间 ************
ConnectTimeout: 3000
#请求处理超时时间 ************
ReadTimeout: 6000
对熔断器Hystrix的支持:开启Hystrix后,Feign中的方法都会被进行一个管理,一旦出现问题就进入对应的回退逻辑处理;当前有两个超时时间设置(Feign/hystrix),熔断的时候是根据这两个时间的最小值来进行的,即处理时长超过最短的那个超时时间了就熔断进入回退降级逻辑。
feign:
hystrix:
enabled: true # 开启Feign的熔断功能
如果开启了Hystrix,Hystrix的超时报错信息如下:

此时可以添加如下配置:
feign:
hystrix:
command:
default:
circuitBreaker:
sleepWindowInMilliseconds: 30000
requestVolumeThreshold: 50
execution:
timeout:
enabled: true
isolation:
strategy: SEMAPHORE
semaphore:
maxConcurrentRequests: 50
thread:
timeoutInMilliseconds: 16000 # 全局超时熔断时间 ************
自定义FallBack处理类(需要实现FeignClient接口)
// 降级回退逻辑需要定义一个类,实现FeignClient接口,实现接口中的方法
@Component // 别忘了这个注解,还应该被扫描到
public class UserFallback implements UserServiceFeignClient {
@Override
public Integer findDefaultResumeState(Long userId) {
return 6;
}
}
在@FeignClient注解中添加 fallback 属性和值为 UserFallback.class。注意使用 fallback 属性时,类上的
@RequestMapping 注解的url前缀限定需要改成配置在@FeignClient的 path 属性中。
4.Feign的工作原理

主程序入口添加了@EnableFeignClients注解开启对FeignClient扫描加载处理。根据Feign Client的开发规范,定义接口并加@FeignClientd注解。
当程序启动时,回进行包扫描,扫描所有@FeignClients的注解的类,并且讲这些信息注入Spring IOC容器中,当定义的的Feign接口中的方法呗调用时,通过JDK的代理方式,来生成具体的RequestTemplate.当生成代理时,Feign会为每个接口方法创建一个RequestTemplate。当生成代理时,Feign会为每个接口方法创建一个RequestTemplate对象,改对象封装可HTTP请求需要的全部信息,如请求参数名,请求方法等信息都是在这个过程中确定的。
然后RequestTemplate生成Request,然后把Request交给Client去处理,这里指的时Client可以时JDK原生的URLConnection,Apache的HttpClient,也可以时OKhttp,最后Client被封装到LoadBalanceClient类,这个类结合Ribbon负载均衡发器服务之间的调用。
Feign开启GZIP压缩
Feign 支持对请求和响应进行GZIP压缩,以减少通信过程中的性能损耗。通过下面的参数 即可开启请求
与响应的压缩功能:
feign:
compression:
request:
enabled: true # 开启对请求的压缩
mime-types: text/xml,application/xml,application/json # 设置压缩的数据类型,默认值
min-request-size: 2048 # 指定启用压缩的最小文件大小
response:
enabled: true # 开启对响应的压缩
需要注意的是,在采用了压缩之后,需要使用二级制的方式进行数据传递,所有返回值就需要使用 ResponseEntity
@FeignClient(name = "github-client")
public interface HelloFeignService {
/*
这个返回类型如果采用了压缩,那么就是二进制的方式,就需要使用ResponseEntity作为返回值
*/
@RequestMapping(value = "/search/repositories",method = RequestMethod.GET)
ResponseEntity<byte[]> searchRepositories(@RequestParam("q")String parameter);
}
Feign开启日志
Feign是http请求客户端,类似浏览器,请求和接受响应时可以打印出详细的一些日志信息(响应头、状态码)。默认Feign的日志没有开启,需要在注解类添加配置的类:
@FeignClient(name = "github-client",configuration = FeignConfig.class)
注解类的代码如下:
// Feign的日志级别(Feign请求过程信息)
// NONE:默认的,不显示任何日志----性能最好
// BASIC:仅记录请求方法、URL、响应状态码以及执行时间----生产问题追踪
// HEADERS:在BASIC级别的基础上,记录请求和响应的header
// FULL:记录请求和响应的header、body和元数据----适用于开发及测试环境定位问题
@Configuration
public class FeignConfig {
/**
* Logger.Level 的具体级别如下:
NONE:不记录任何信息
BASIC:仅记录请求方法、URL以及响应状态码和执行时间
HEADERS:除了记录 BASIC级别的信息外,还会记录请求和响应的头信息
FULL:记录所有请求与响应的明细,包括头信息、请求体、元数据
* @return
*/
@Bean
Logger.Level feignLoggerLevel() {
return Logger.Level.FULL;
}
}
配置log日志级别为debug:
logging:
level:
# Feign日志只会对日志级别为debug的做出响应
com.fishleap.client.UserServiceFeignClient: debug
参考
- Spring Cloud OpenFeign 源码解析
- Feign的工作原理
- Feign源码分析:记初次使用Feign踩的一些坑
六.GateWay网关
1.GateWay概述
Gateway是在Spring生态系统之上构建的API网关服务,依赖于Spring Boot 2.0, Spring WebFlux,和Project Reactor,许多熟悉的同步类库(例如Spring-Data和Spring-Security)和同步编程模式在Spring Cloud Gateway中并不适用。Spring Cloud Gateway官方文档地址
Spring Cloud Gateway 具有如下特性:
- 基于Spring Framework 5, Project Reactor 和 Spring Boot 2.0 进行构建;
- 动态路由:能够匹配任何请求属性;
- 可以对路由指定 Predicate(断言)和 Filter(过滤器);
- 集成Hystrix的断路器功能;
- 集成 Spring Cloud 服务发现功能;
- 请求限流功能;
- 支持路径重写。
路由(Route):路由是网关的基本组件。它由ID,目标URI,谓词(Predicate)集合和过滤器集合定义。如果谓词聚合判断为真,则匹配路由。
谓词(Predicate):使用的是Java8中基于函数式编程引入的java.util.Predicate。使用谓词(聚合)判断的时候,输入的参数是ServerWebExchange类型,它允许开发者匹配来自HTTP请求的任意参数,例如HTTP请求头、HTTP请求参数等等。
过滤器(Filter):使用的是指定的GatewayFilter工厂所创建出来的GatewayFilter实例,可以在发送请求到下游之前或者之后修改请求(参数)或者响应(参数)。
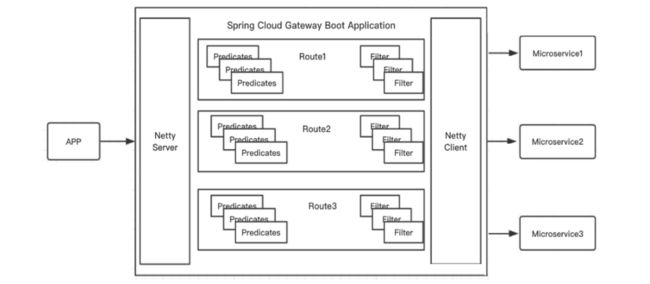
Predicates断言就是匹配条件,而Filter是拦截器,结合URL可以实现一个具体的路由转发。
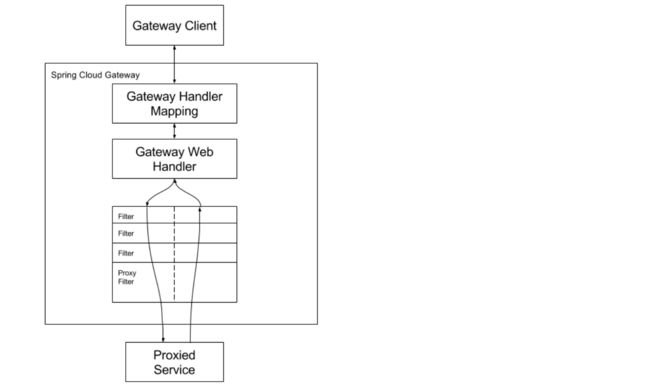
客户端向Spring Cloud GateWay发出请求,然后在GateWay Handler Mapping中找到与请求相匹配的路由,将其发送到GateWay Web Handler;Handler再通过指定的过滤器链来将请求发送到我们实际的服务执行业务逻辑,然后返回。过滤器之间用虚线分开是因为过滤器可能会在发送代理请求之前(pre)或者之后(post)执行业务逻辑。(路由转发+执行过滤器链)
Filter在“pre”类型过滤器中可以做参数校验、权限校验、流量监控、日志输出、协议转换等,在“post”类型的过滤器中可以做响应内容、响应头的修改、日志的输出、流量监控等。
2.GateWay应用
引入依赖:
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-gatewayartifactId>
dependency>
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-netflix-eureka-clientartifactId>
dependency>
路由配置:
Gateway 提供了两种不同的方式用于配置路由,一种是通过yml文件来配置,另一种是通过Java Bean来配置
在application.yml中配置:
server:
port: 9201
spring:
cloud:
gateway:
routes:
- id: path_route #路由的ID
uri: ${
service-url.user-service}/user/{
id} #匹配后路由地址
predicates: # 断言,路径相匹配的进行路由
- Path=/user/{
id}
service-url:
user-service: http://localhost:8201
使用Java Bean配置:添加相关配置类,配置一个RouteLocator对象
@Configuration
public class GatewayConfig {
@Bean
public RouteLocator customRouteLocator(RouteLocatorBuilder builder) {
return builder.routes()
.route("path_route2", r -> r.path("/user/getByUsername")
.uri("http://localhost:8201/user/getByUsername"))
.build();
}
}
3.GateWay路由规则
Spring Cloud Gateway自身包含了很多内建的路由谓词工厂。这些谓词分别匹配一个HTTP请求的不同属性。多个路由谓词工厂可以用and的逻辑组合在一起。
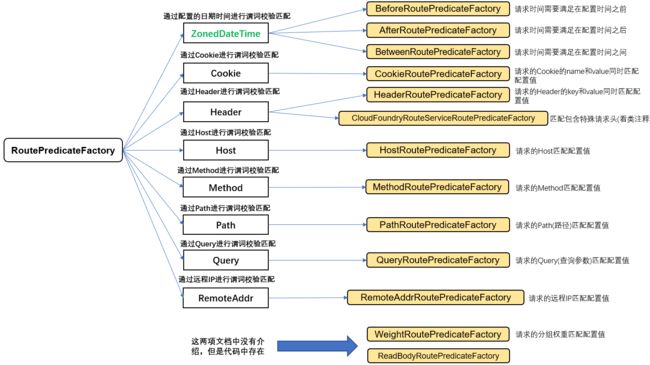
指定日期时间路由谓词
- 匹配请求在指定日期时间之前。
- 匹配请求在指定日期时间之后。
- 匹配请求在指定日期时间之间。
配置的日期时间必须满足ZonedDateTime的格式:年月日和时分秒用’T’分隔,接着-07:00是和UTC相差的时间,最后的[America/Denver]是所在的时间地区 2017-01-20T17:42:47.789-07:00[America/Denver]
server
port: 9090
spring:
cloud:
gateway:
routes:
- id: between_route
uri: https://example.org
predicates:
- Between=2019-05-01T00:00:00+08:00[Asia/Shanghai],2019-05-02T00:00:00+08:00[Asia/Shanghai]
Cookie路由谓词
CookieRoutePredicateFactory需要提供两个参数,分别是Cookie的name和一个正则表达式(value)。只有在请求中的Cookie对应的name和value和Cookie路由谓词中配置的值匹配的时候,才能匹配命中进行路由。
server
port: 9090
spring:
cloud:
gateway:
routes:
- id: cookie_route
uri: https://example.org
predicates:
- Cookie=doge,aaa
请求需要携带一个Cookie,name为doge,value需要匹配正则表达式"aaa"才能路由到https://example.org。
Header路由谓词
HeaderRoutePredicateFactory需要提供两个参数,分别是Header的name和一个正则表达式(value)。只有在请求中的Header对应的name和value和Header路由谓词中配置的值匹配的时候,才能匹配命中进行路由。
Host路由谓词
HostRoutePredicateFactory只需要指定一个主机名列表,列表中的每个元素支持Ant命名样式,使用.作为分隔符,多个元素之间使用,区分。Host路由谓词实际上针对的是HTTP请求头中的Host属性。
spring:
cloud:
gateway:
routes:
- id: host_route
uri: http://localhost:9091
predicates:
- Host=localhost:9090
请求方法路由谓词
MethodRoutePredicateFactory只需要一个参数:要匹配的HTTP请求方法。
spring:
cloud:
gateway:
routes:
- id: method_route
uri: http://localhost:9091
predicates:
- Method=GET
请求路径路由谓词
PathRoutePredicateFactory需要PathMatcher模式路径列表和一个可选的标志位参数matchOptionalTrailingSeparator。这个是最常用的一个路由谓词。
spring:
cloud:
gateway:
routes:
- id: path_route
uri: http://localhost:9091
predicates:
- Path=/order/path
请求查询参数路由谓词
QueryRoutePredicateFactory需要一个必须的请求查询参数(param的name)以及一个可选的正则表达式(regexp)。
spring:
cloud:
gateway:
routes:
- id: query_route
uri: http://localhost:9091
predicates:
- Query=doge,aaa.
远程IP地址路由谓词
RemoteAddrRoutePredicateFactory匹配规则采用CIDR符号(IPv4或IPv6)字符串的列表(最小值为1),例如192.168.0.1/16(其中192.168.0.1是远程IP地址并且16是子网掩码)。
spring:
cloud:
gateway:
routes:
- id: remoteaddr_route
uri: https://example.org
predicates:
- RemoteAddr=192.168.1.1/24
多个路由谓词组合
因为路由配置中的predicates属性其实是一个列表,可以直接添加多个路由规则:
spring:
cloud:
gateway:
routes:
- id: remoteaddr_route
uri: http://localhost:9091
predicates:
- RemoteAddr=xxxx
- Path=/yyyy
- Query=zzzz,aaaa
GateWay动态路由
GateWay⽀持自动从注册中心获取服务列表并访问,即所谓的动态路由。
动态路由设置时,uri以 lb: //开头(lb代表从注册中心获取服务),后面是需要转发到的服务名称
4.GateWay过滤器
GatewayFilter工厂
路由过滤器GatewayFilter允许修改进来的HTTP请求内容或者返回的HTTP响应内容。路由过滤器的作用域是一个具体的路由配置。Spring Cloud Gateway提供了丰富的内建的GatewayFilter工厂,可以按需选用。
目前GatewayFilter工厂的内建实现如下:
| ID | 类名 | 类型 | 功能 |
|---|---|---|---|
| StripPrefix | StripPrefixGatewayFilterFactory | pre | 移除请求URL路径的第一部分,例如原始请求路径是/order/query,处理后是/query |
| SetStatus | SetStatusGatewayFilterFactory | post | 设置请求响应的状态码,会从org.springframework.http.HttpStatus中解析 |
| SetResponseHeader | SetResponseHeaderGatewayFilterFactory | post | 设置(添加)请求响应的响应头 |
| SetRequestHeader | SetRequestHeaderGatewayFilterFactory | pre | 设置(添加)请求头 |
| SetPath | SetPathGatewayFilterFactory | pre | 设置(覆盖)请求路径 |
| SecureHeader | SecureHeadersGatewayFilterFactory | pre | 设置安全相关的请求头,见SecureHeadersProperties |
| SaveSession | SaveSessionGatewayFilterFactory | pre | 保存WebSession |
| RewriteResponseHeader | RewriteResponseHeaderGatewayFilterFactory | post | 重新响应头 |
| RewritePath | RewritePathGatewayFilterFactory | pre | 重写请求路径 |
| Retry | RetryGatewayFilterFactory | pre | 基于条件对请求进行重试 |
| RequestSize | RequestSizeGatewayFilterFactory | pre | 限制请求的大小,单位是byte,超过设定值返回413 Payload Too Large |
| RequestRateLimiter | RequestRateLimiterGatewayFilterFactory | pre | 限流 |
| RequestHeaderToRequestUri | RequestHeaderToRequestUriGatewayFilterFactory | pre | 通过请求头的值改变请求URL |
| RemoveResponseHeader | RemoveResponseHeaderGatewayFilterFactory | post | 移除配置的响应头 |
| RemoveRequestHeader | RemoveRequestHeaderGatewayFilterFactory | pre | 移除配置的请求头 |
| RedirectTo | RedirectToGatewayFilterFactory | pre | 重定向,需要指定HTTP状态码和重定向URL |
| PreserveHostHeader | PreserveHostHeaderGatewayFilterFactory | pre | 设置请求携带的属性preserveHostHeader为true |
| PrefixPath | PrefixPathGatewayFilterFactory | pre | 请求路径添加前置路径 |
| Hystrix | HystrixGatewayFilterFactory | pre | 整合Hystrix |
| FallbackHeaders | FallbackHeadersGatewayFilterFactory | pre | Hystrix执行如果命中降级逻辑允许通过请求头携带异常明细信息 |
| AddResponseHeader | AddResponseHeaderGatewayFilterFactory | post | 添加响应头 |
| AddRequestParameter | AddRequestParameterGatewayFilterFactory | pre | 添加请求参数,仅仅限于URL的Query参数 |
| AddRequestHeader | AddRequestHeaderGatewayFilterFactory | pre | 添加请求头 |
GatewayFilter工厂使用的时候需要知道其ID以及配置方式,配置方式可以看对应工厂类的公有静态内部类XXXXConfig。
GlobalFilter工厂
GlobalFilter的功能其实和GatewayFilter是相同的,只是GlobalFilter的作用域是所有的路由配置,而不是绑定在指定的路由配置上。多个GlobalFilter可以通过@Order或者getOrder()方法指定每个GlobalFilter的执行顺序,order值越小,GlobalFilter执行的优先级越高。
目前Spring Cloud Gateway提供的内建的GlobalFilter如下:
| 类名 | 功能 |
|---|---|
| ForwardRoutingFilter | 重定向 |
| LoadBalancerClientFilter | 负载均衡 |
| NettyRoutingFilter | Netty的HTTP客户端的路由 |
| NettyWriteResponseFilter | Netty响应进行写操作 |
| RouteToRequestUrlFilter | 基于路由配置更新URL |
| WebsocketRoutingFilter | Websocket请求转发到下游 |
内建的GlobalFilter大多数和ServerWebExchangeUtils的属性相关。
5.跨域配置和Actuator端点
跨域配置:
网关可以通过配置来控制全局的CORS行为。全局的CORS配置对应的类是CorsConfiguration,这个配置是一个URL模式的映射。例如application.yaml文件如下:
spring:
cloud:
gateway:
globalcors:
corsConfigurations:
'[/**]':
allowedOrigins: "https://docs.spring.io"
allowedMethods:
- GET
对于所有请求的路径,将允许来自docs.spring.io并且是GET方法的CORS请求。
Actuator端点相关:
引入spring-boot-starter-actuator,需要做以下配置开启gateway监控端点:
management.endpoint.gateway.enabled=true
management.endpoints.web.exposure.include=gateway
目前支持的端点列表:
| ID | 请求路径 | HTTP方法 | 描述 |
|---|---|---|---|
| globalfilters | /actuator/gateway/globalfilters | GET | 展示路由配置中的GlobalFilter列表 |
| routefilters | /actuator/gateway/routefilters | GET | 展示绑定到对应路由配置的GatewayFilter列表 |
| refresh | /actuator/gateway/refresh | POST | 清空路由配置缓存 |
| routes | /actuator/gateway/routes | GET | 展示已经定义的路由配置列表 |
| routes/{id} | /actuator/gateway/routes/{id} | GET | 展示对应ID已经定义的路由配置 |
| routes/{id} | /actuator/gateway/routes/{id} | POST | 添加一个新的路由配置 |
| routes/{id} | /actuator/gateway/routes/{id} | DELETE | 删除指定ID的路由配置 |
其中/actuator/gateway/routes/{id}添加一个新的路由配置请求参数的格式如下:
{
"id": "first_route",
"predicates": [{
"name": "Path",
"args": {
"doge":"/example"}
}],
"filters": [],
"uri": "https://example.org",
"order": 0
}
参考
- Spring Cloud Gateway:新一代API网关服务
- Spring Cloud Gateway入坑记
- Spring Cloud Gateway 入门
参考链接
- Spring Cloud官网
- Spring Cloud中文社区
- Spring Cloud中国社区
- 冒着挂科的风险也要给你们看的Spring Cloud入门总结
- Spring Cloud学习
- Spring Cloud Config:外部集中化配置管理
- Spring Cloud Bus:消息总线