ElasticSearch6.x 之字段类型
本文转载至:https://blog.csdn.net/chengyuqiang/article/details/79048800
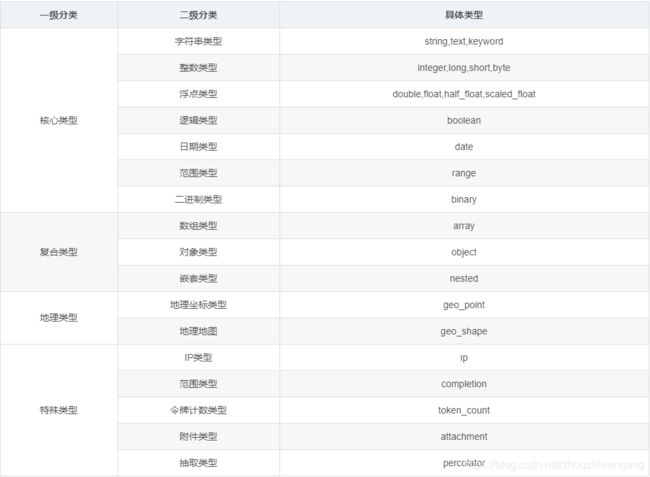
字段类型概述
字符串类型
(1)string
string类型在ElasticSearch 旧版本中使用较多,从ElasticSearch 5.x开始不再支持string,由text和keyword类型替代。
(2)text
当一个字段是要被全文搜索的,比如Email内容、产品描述,应该使用text类型。设置text类型以后,字段内容会被分析,在生成倒排索引以前,字符串会被分析器分成一个一个词项。text类型的字段不用于排序,很少用于聚合。
(3)keyword
keyword类型适用于索引结构化的字段,比如email地址、主机名、状态码和标签。如果字段需要进行过滤(比如查找已发布博客中status属性为published的文章)、排序、聚合。keyword类型的字段只能通过精确值搜索到。
整数类型

浮点类型
| 类型 | 取值范围 |
|---|---|
| doule | 64位双精度IEEE 754浮点类型 |
| float | 32位单精度IEEE 754浮点类型 |
| half_float | 16位半精度IEEE 754浮点类型 |
| scaled_float | 缩放类型的的浮点数 |
对于float、half_float和scaled_float,-0.0和+0.0是不同的值,使用term查询查找-0.0不会匹配+0.0,同样range查询中上边界是-0.0不会匹配+0.0,下边界是+0.0不会匹配-0.0。
其中scaled_float,比如价格只需要精确到分,price为57.34的字段缩放因子为100,存起来就是5734
优先考虑使用带缩放因子的scaled_float浮点类型。
date类型
我们人类使用的计时系统是相当复杂的:秒是基本单位, 60秒为1分钟, 60分钟为1小时, 24小时是一天……如果计算机也使用相同的方式来计时, 那显然就要用多个变量来分别存放年月日时分秒, 不停的进行进位运算, 而且还要处理偶尔的闰年和闰秒以及协调不同的时区. 基于”追求简单”的设计理念, UNIX在内部采用了一种最简单的计时方式:
计算从UNIX诞生的UTC时间1970年1月1日0时0分0秒起, 流逝的秒数.
UTC时间1970年1月1日0时0分0秒就是UNIX时间0, UTC时间1970年1月2日0时0分0秒就是UNIX时间86400.
这个计时系统被所有的UNIX和类UNIX系统继承了下来, 而且影响了许多非UNIX系统. 日期类型表示格式可以是以下几种:
(1)日期格式的字符串,比如 “2018-01-13” 或 “2018-01-13 12:10:30”
(2)long类型的毫秒数( milliseconds-since-the-epoch,epoch就是指UNIX诞生的UTC时间1970年1月1日0时0分0秒)
(3)integer的秒数(seconds-since-the-epoch)
示例:
1、日期格式文档数据
第一步:删除test 索引 ,elasticsearch6.x 复合查询执行如下操作。

第二步:创建test索引,指定my类型中的文档属性:postdate为日期类型。
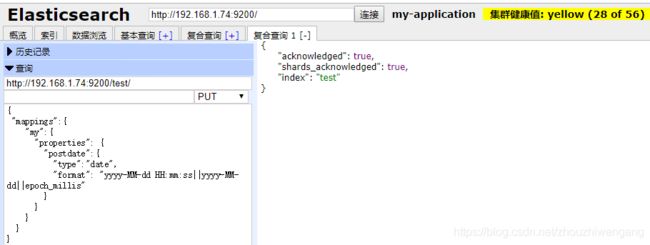 第三步:向test索引中的my类型,插入文档数据。
第三步:向test索引中的my类型,插入文档数据。
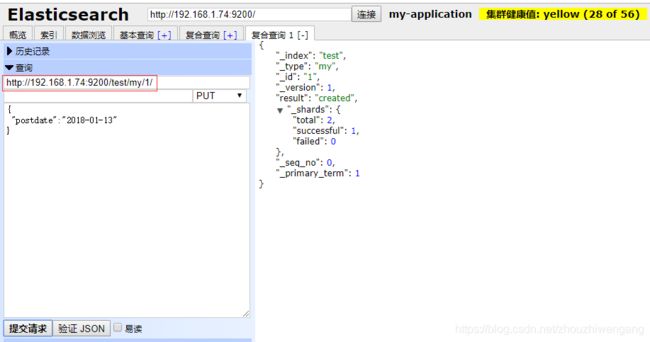
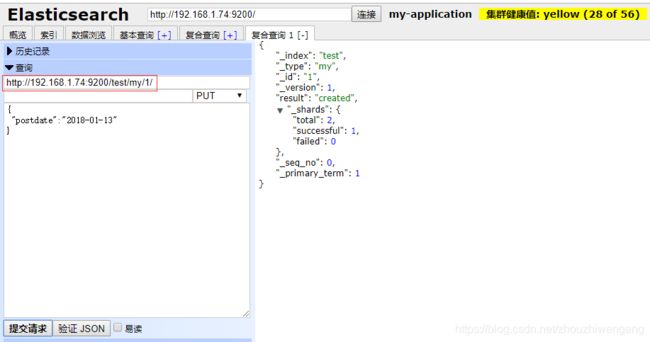
2、boolean 格式文档数据。
第一步:删除test 索引 ,elasticsearch6.x 复合查询执行如下操作。
Delete 请求 http://192.168.1.74:9200/test/
第二步:创建test索引,指定my类型中的文档属性:empty为boolean类型。
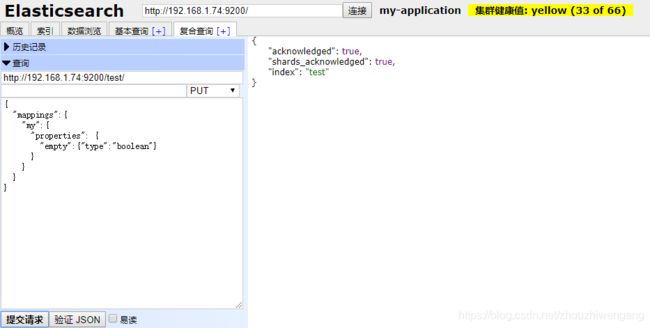
第三步:向test索引中的my类型,插入文档数据。
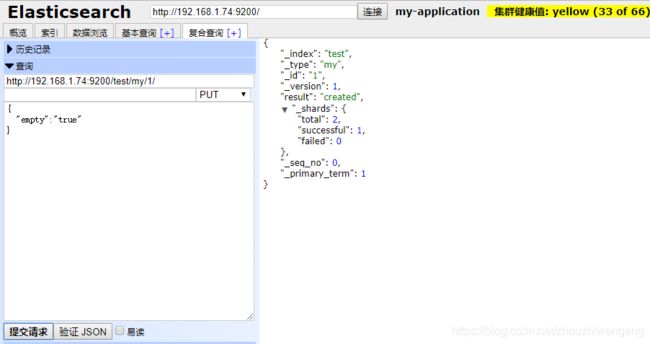
3、object 格式文档数据。
第一步:删除test 索引 ,elasticsearch6.x 复合查询执行如下操作。
Delete 请求 http://192.168.1.74:9200/test/
第二步:创建test索引,指定my类型中的文档属性:employee为object类型。
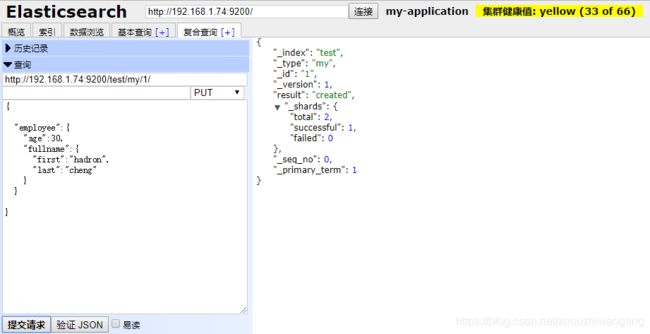
4、IP 格式文档数据
第一步:删除test 索引 ,elasticsearch6.x 复合查询执行如下操作。
Delete 请求 http://192.168.1.74:9200/test/
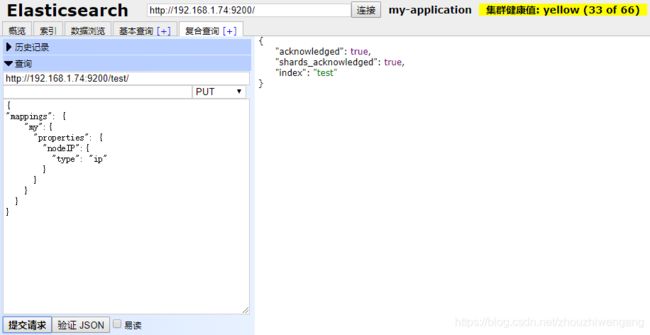
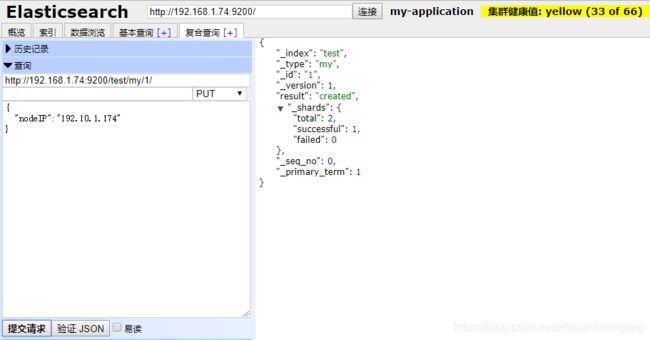
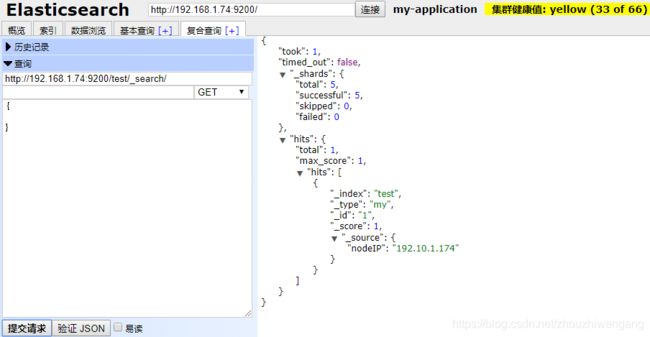
第二步:创建test索引,指定my类型中的文档属性:nodeIP为ip类型。