数据结构与算法系列之一:八大排序之快速排序
- 转载请注明作者和出处:http://blog.csdn.net/u011475210
- 个人博客:https://wordzzzz.github.io/ && https://wordzzzz.gitee.io/
- 代码地址:https://github.com/WordZzzz/Note/tree/master/DS-A
- 博客作者:WordZzzz,一只热爱技术的文艺青年
-
- 快速排序
- 前言
- 简介
- 步骤
- 代码
- 公用接口
- 递归法
- 迭代法
- 算法复杂度
- 分析
- 局限性
- 优化
- 快速排序
快速排序
前言
建议先看排序综述,传送门:数据结构与算法系列之一:八大排序综述。
简介
快速排序(英语:Quicksort),又称划分交换排序(partition-exchange sort),一种排序算法,最早由东尼·霍尔提出。在平均状况下,排序 n 个项目要 O(nlogn) (大O符号)次比较。在最坏状况下则需要 O(n2) 次比较,但这种状况并不常见。事实上,快速排序通常明显比其他 O(nlogn) 算法更快,因为它的内部循环(inner loop)可以在大部分的架构上很有效率地被实现出来。
步骤
快速排序使用分治法(Divide and conquer)策略来把一个序列(list)分为两个子序列(sub-lists)。
步骤为:
- 从数列中挑出一个元素,称为”基准”(pivot).
- 重新排序数列,所有比基准值小的元素摆放在基准前面,所有比基准值大的元素摆在基准后面(相同的数可以到任何一边)。在这个分区结束之后,该基准就处于数列的中间位置。这个称为分区(partition)操作。
- 递归地(recursively)把小于基准值元素的子数列和大于基准值元素的子数列排序。
- 递归到最底部时,数列的大小是零或一,也就是已经排序好了。这个算法一定会结束,因为在每次的迭代(iteration)中,它至少会把一个元素摆到它最后的位置去。
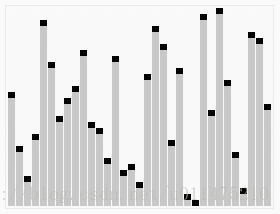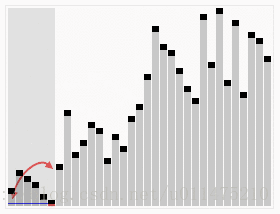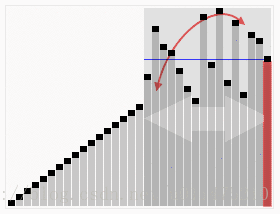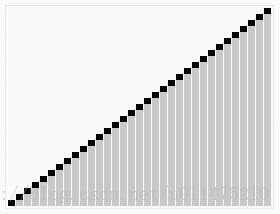
wikipedia的大数据规模演示:
wordzzzz的小数据规模演示:
代码
先给出公用接口,之后的三个递归实现和一个迭代实现在代码中都有详细的说明,我就不再在此赘述。
公用接口
/*
* 快速排序主体函数(递归)
*/
template <typename T>
void QuickSort(T *array, const int length) {
if (array == NULL)
throw invalid_argument("Array must not be empty");
if (length <= 0)
return;
Partion1(array, 0, length - 1);
// Partion2(array, 0, length - 1);
// Partion3(array, 0, length - 1);
// PartionInsert(array, 0, length - 1);
// PartionSecond(array, 0, length - 1);
// PartionThird(array, 0, length - 1);
}递归法
/*
* 快速排序1:
* 将第一个元素array[left]提出来作pivot,i=left(该索引之前的数比pivot小,初始值为left),
* j从left+1开始遍历数组,找到一个比pivot小的数,i+1,如果i和j序列号不等就交换(小值到前)。
* j到最右端之后,for循环结束,再把pivot与i所指数据做交换,当前pivot就到达了它的最终位置。
*/
template <typename T>
void Partion1(T *array, int left, int right){
if (left >= right)
return;
int i = left;
int j = left + 1;
T pivot = array[left]; // 取第一个数为基准
for (; j <= right; ++j){ // 循环直至 j 扫描至 right
if (array[j] < pivot){ // 如果遇到比基准小的数,i右移一位
i++;
if (j != i){ // 如果i与j不重合,则交换他们指向的值
swap(array[j],array[i]);
}
}
}
swap(array[left], array[i]); // 基准值的位置确定
Partion1(array, left, i - 1);
Partion1(array, i + 1, right);
}
/*
* 快速排序2:
* 将第一个元素array[left]提出来作pivot,i = left+1从左向右遍历找到一个比pivot大的数停止,
* 然后等待j从右往左遍历找到一个pivot小的数,两者交换,然后继续寻找直到i=j,for循环结束。
* 之后我们需要做判断,如果pivot比i所指数据大就交换两者,否则i回退一步(因为开始忽略了首元素)。
*/
template <typename T>
void Partion2(T *array, int left, int right) {
if (left >= right)
return;
int i = left + 1;
int j = right;
T pivot = array[left]; // 取第一个数为基准
while (i < j){ // 循环直至 i,j 相遇
while (i < j && array[j] >= pivot) // j向左遍历,直到找到比pivot小的值
--j;
while (i < j && array[i] < pivot) // i向右遍历,直到找到比pivot大的值
++i;
if (i < j) // 如果i < j,就交换刚才找到的那两个值
swap(array[j], array[i]);
}
if (array[i] <= array[left]) // 这里一定要做判断再决定是否交换
swap(array[i], array[left]);
else // 如果不交换,说明left是最小,但i是不是第二小不确定,所以需要下次判断
--i;
Partion2(array, left, i - 1);
Partion2(array, i + 1, right);
}
/*
* 快速排序3:
* 将第一个元素array[left]提出来作pivot,然后从j = right向前搜索第一个比pivot小的元素假设为array[k],
* 该元素放在array[left]的位置。因为array[left]已经保存pivot覆盖也没关系,于是array[k]又可以被覆盖了,
* 从前往后搜索比pivot大的元素放到array[k]。一直进行下去直到i=j。
*/
template <typename T>
void Partion3(T *array, int left, int right) {
if (left >= right)
return;
int i = left;
int j = right;
T pivot = array[left]; // 取第一个数为基准
while (i < j){ // 循环直至 i,j 相遇
while (i < j && array[j] >= pivot)
--j;
if (i < j)
array[i++] = array[j]; // 从右向左扫描,将比基准小的数填到左边
while (i < j && array[i] < pivot)
++i;
if (i < j)
array[j--] = array[i]; // 从左向右扫描,将比基准大的数填到右边
}
array[i] = pivot; // 将基准数填回
Partion3(array, left, i - 1);
Partion3(array, i + 1, right);
}迭代法
/*
* 快速排序迭代实现
*/
template<typename T>
void QuickSortIteration(T *array, const int length) {
stackint , int>> trace;
trace.push(make_pair(0, length - 1)); // 将数组首尾压栈
while (!trace.empty()) {
auto top = trace.top(); // 将栈顶元素保存下来
trace.pop(); // 弹出栈顶
int i = top.first; // 取出首尾地址
int j = top.second;
T pivot = array[i]; // 取第一个数为基准
while (i < j) { // 循环直至 i,j 相遇
while (i < j && array[j] >= pivot)
--j;
if (i < j)
array[i++] = array[j]; // 从右向左扫描,将比基准小的数填到左边
while (i < j && array[i] < pivot)
++i;
if (i < j)
array[j--] = array[i]; // 从左向右扫描,将比基准大的数填到右边
}
array[i] = pivot; // 将基准数填回
if (i > top.first) trace.push(make_pair(top.first, i - 1));
if (j < top.second) trace.push(make_pair(j + 1, top.second));
}
}算法复杂度
- 数据结构 不定
- 最坏时间复杂度 O(n2)
- 最优时间复杂度 O(nlogn)
- 平均时间复杂度 O(nlogn)
- 空间复杂度 根据实现的方式不同而不同
分析
快速排序是二叉查找树(二叉查找树)的一个空间最优化版本。不是循序地把数据项插入到一个明确的树中,而是由快速排序组织这些数据项到一个由递归调用所隐含的树中。这两个算法完全地产生相同的比较次数,但是顺序不同。对于排序算法的稳定性指标,原地分区版本的快速排序算法是不稳定的。其他变种是可以通过牺牲性能和空间来维护稳定性的。
快速排序的最直接竞争者是堆排序(Heapsort)。堆排序通常比快速排序稍微慢,但是最坏情况的运行时间总是 O(nlogn) 。快速排序是经常比较快,除了introsort变化版本外,仍然有最坏情况性能的机会。如果事先知道堆排序将会是需要使用的,那么直接地使用堆排序比等待introsort再切换到它还要快。堆排序也拥有重要的特点,仅使用固定额外的空间(堆排序是原地排序),而即使是最佳的快速排序变化版本也需要 O(logn) 的空间。然而,堆排序需要有效率的随机存取才能变成可行。
快速排序也与归并排序(Mergesort)竞争,这是另外一种递归排序算法,但有坏情况 O(nlogn) 运行时间的优势。不像快速排序或堆排序,归并排序是一个稳定排序,且可以轻易地被采用在链表(linked list)和存储在慢速访问媒体上像是磁盘存储或网络连接存储的非常巨大数列。尽管快速排序可以被重新改写使用在链串列上,但是它通常会因为无法随机存取而导致差的基准选择。归并排序的主要缺点,是在最佳情况下需要 Ω(n) 额外的空间。
局限性
快排的优化、归并排序的优化一向是面试的考察重点,至于算法的优化,重点还是要知道现有算法的不足之处。
- 当序列长度很小时,快排效率低,研究表明长度在5~25的数组,快排表现不如插入排序。
- 当pivot选择不当是,会导致树的不平衡,这样导致快排的时间复杂度为 O(n2) 。
- 当数组中有大量重复的元素,快排效率将非常之低。
优化
针对上面提出的快排的局限性,我们依次做出优化策略:
- 当当前序列长度小于特定值时,直接采用插入排序,或者不做处理,等到快排都执行完毕后(大致有序)在执行一次插入排序。
- 针对pivot的选择,不再选取固定值,而是采用其他选取策略,如随机、三值取中等。
- 如果数组中重复元素多,就采用三路划分算法:以某个数为基准将一个数组分成三部分:第一部分表示小于该pivot,第二部分等于pivot,第三部分大于pivot,要得到三部分得区间范围。
下面的代码是对上述改进算法的实现:
/*
* 快速排序3优化1:
* 当排序的子序列小于预定的值M时,采用插入排序
*/
template <typename T>
void PartionInsert(T *array, int left, int right) {
if (left >= right)
return;
if (right - left <= M)
InsertSort(array, left, right);
else{
int i = left;
int j = right;
T pivot = array[left]; // 取第一个数为基准
while (i < j){ // 循环直至 i,j 相遇
while (i < j && array[j] >= pivot)
--j;
if (i < j)
array[i++] = array[j]; // 从右向左扫描,将比基准小的数填到左边
while (i < j && array[i] < pivot)
++i;
if (i < j)
array[j--] = array[i]; // 从左向右扫描,将比基准大的数填到右边
}
array[i] = pivot; // 将基准数填回
PartionInsert(array, left, i - 1);
PartionInsert(array, i + 1, right);
}
}
//产生随机数
template <typename T>
void Random(T *array, int left, int right)
{
int size = right - left + 1;
int i = left + rand() % size;
swap(array[i], array[left]);
}
//取中位数移至left
template <typename T>
void Median(T *array, int left, int right)
{
int mid = left + ((right - left )>> 1);
int minIndex = right;
if (array[minIndex] > array[mid])
minIndex = mid;
if (array[minIndex] > array[left])
minIndex = left;
if (minIndex != right) //三个判断,把最小值移到最右侧
swap(array[minIndex], array[right]);
if (array[mid] < array[left]) //那么剩下的两个数,最小的那个就是中位数了
swap(array[left], array[mid]);
}
/*
* 快速排序3优化2:
* 取随机数或者三值取中作为基准值
*/
template <typename T>
void PartionSecond(T *array, int left, int right) {
if (left >= right)
return;
// Random(array, left, right); // 优化2-1:取随机数至最左端(基准值)
Median(array, left, right); // 优化2-2:取中位数至最左端(基准值)
int i = left;
int j = right;
T pivot = array[left]; // 取第一个数为基准
while (i < j){ // 循环直至 i,j 相遇
while (i < j && array[j] >= pivot)
--j;
if (i < j)
array[i++] = array[j]; // 从右向左扫描,将比基准小的数填到左边
while (i < j && array[i] < pivot)
++i;
if (i < j)
array[j--] = array[i]; // 从左向右扫描,将比基准大的数填到右边
}
array[i] = pivot; // 将基准数填回
PartionSecond(array, left, i - 1);
PartionSecond(array, i + 1, right);
}
/*
* 快速排序3优化3:
* 重复数据比较多的话,可以分为小于等于大于三段
*/
template <typename T>
void PartionThird(T *array, int left, int right) {
if (left >= right)
return;
int less = left;
int greater = right;
int it = left;
T pivot = array[left]; // 取第一个数为基准
while (it <= greater){ // 循环直至it和greater相遇
if (array[it] == pivot) // 如果等于pivot,it右移
++it;
else if (array[it] < pivot){ // 如果小于pivot,扔左边,it和less右移
swap(array[less], array[it]);
++it;
++less;
}
else{ // 如果大于pivot,扔右边,greater左移
swap(array[greater], array[it]);
--greater;
}
}
PartionThird(array, left, less - 1);
PartionThird(array, greater + 1, right);
}系列教程持续发布中,欢迎订阅、关注、收藏、评论、点赞哦~~( ̄▽ ̄~)~
完的汪(∪。∪)。。。zzz