Tesseract-OCR安装及Java代码识别文字
点击打开链接
你也可以去其他网站下载3.0以上版本即可
2.下载后就进行安装,这里需要注意的是安装时有个步骤时需要选择语言的,默认的是英文语言包,安装是我们还需要选择一个中文的简体语言包(你也可以勾选多个语言包,我安装时勾选多个出错了,所以只选择了一个中文简体),然后下一步知道安装结束。
3.配置环境变量
4.配置好后检查是否安装成功
进入cmd窗口 —— 执行命令 tessercate -version 或者直接 tessercate 没报错就说明安装成功了

5.安装成功后我们需要去安装目录下查看语言包是否下载成功了(语言包必须要和安装的tesseract ocr 一致否则在识别中文字体时会报错:actual_tessdata_num_entries_ <= TESSDATA_NUM_ENTRIES - Stack Overflow)
 这个就是中文简体语言包
这个就是中文简体语言包
6.现在可以找些简单的英文图片试着识别一下
命令为:tesseract 图片名称 要保存的名称
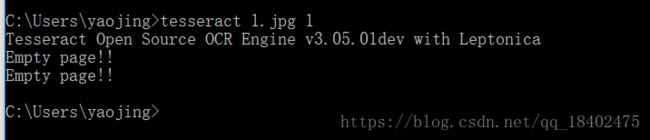
这个其实报错了说是空页,这个说明执行的字体无法识别

这个表示执行成功
执行成功后去放图片的目录下找到一个叫1.txt的文件
 原图片
原图片
 识别后文字
识别后文字
大家可以看到我的是I have 但是识别后却是have 这是大概因为我的I是大写的在字体库里面找不到大写的I所以就只识别了have(这里就需要我们自己训练字体库了)
对于一般的英文而言没什么大问题,但是中文的话就不行了
中文的执行代码是:tesseract 2.jpg 2 -l chi_sim

![]() ——————
——————![]() 看南和封有问题是吧!所以这里就需要我们自己训练字体库了
看南和封有问题是吧!所以这里就需要我们自己训练字体库了
7.下载jTessBoxEditor
点击打开链接
下载后将这个文件解压放在这个目录下面

下载好后就可以通过这个去训练字体了,后面这步我还没完全学会,等我学会了再来更新。
java 代码
package test;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.List;
public class OcrTest {
private final String LANG_OPTION = "-l";
private final String EOL = System.getProperty("line.separator");
/**
* Tesseract-OCR的安装路径
*/
private String tessPath = "Z:\\Software\\Tool\\Tesseract-OCR";
/**
* @param imageFile 传入的图像文件
* @param imageFormat 传入的图像格式
* @return 识别后的字符串
*/
public String recognizeText(File imageFile) throws Exception {
/**
* 设置输出文件的保存的文件目录
*/
File outputFile = new File(imageFile.getParentFile(), "2");
StringBuffer strB = new StringBuffer();
List cmd = new ArrayList();
cmd.add(tessPath + "//tesseract");
cmd.add("");
cmd.add(outputFile.getName());
cmd.add(LANG_OPTION);
cmd.add("chi_sim");
//cmd.add("eng");
ProcessBuilder pb = new ProcessBuilder();
/**
*Sets this process builder's working directory.
*/
pb.directory(imageFile.getParentFile());
cmd.set(1, imageFile.getName());
pb.command(cmd);
pb.redirectErrorStream(true);
long startTime = System.currentTimeMillis();
System.out.println("开始时间:" + startTime);
Process process = pb.start();
// tesseract.exe 1.jpg 1 -l chi_sim
//不习惯使用ProcessBuilder的,也可以使用Runtime,效果一致
// Runtime.getRuntime().exec("tesseract.exe 1.jpg 1 -l chi_sim");
/**
* the exit value of the process. By convention, 0 indicates normal
* termination.
*/
// System.out.println(cmd.toString());
int w = process.waitFor();
if (w == 0)// 0代表正常退出
{
BufferedReader in = new BufferedReader(new InputStreamReader(
new FileInputStream(outputFile.getAbsolutePath() + ".txt"),
"UTF-8"));
String str;
while ((str = in.readLine()) != null) {
strB.append(str).append(EOL);
}
in.close();
long endTime = System.currentTimeMillis();
System.out.println("结束时间:" + endTime);
System.out.println("耗时:" + (endTime - startTime) + "毫秒");
} else {
String msg;
switch (w) {
case 1:
msg = "Errors accessing files. There may be spaces in your image's filename.";
break;
case 29:
msg = "Cannot recognize the image or its selected region.";
break;
case 31:
msg = "Unsupported image format.";
break;
default:
msg = "Errors occurred.";
}
throw new RuntimeException(msg);
}
new File(outputFile.getAbsolutePath() + ".txt").delete();
return strB.toString().replaceAll("\\s*", "");
}
} 测试
package test;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.List;
public class OcrTest {
private final String LANG_OPTION = "-l";
private final String EOL = System.getProperty("line.separator");
/**
* Tesseract-OCR的安装路径
*/
private String tessPath = "Z:\\Software\\Tool\\Tesseract-OCR";
/**
* @param imageFile 传入的图像文件
* @param imageFormat 传入的图像格式
* @return 识别后的字符串
*/
public String recognizeText(File imageFile) throws Exception {
/**
* 设置输出文件的保存的文件目录
*/
File outputFile = new File(imageFile.getParentFile(), "2");
StringBuffer strB = new StringBuffer();
List cmd = new ArrayList();
cmd.add(tessPath + "//tesseract");
cmd.add("");
cmd.add(outputFile.getName());
cmd.add(LANG_OPTION);
cmd.add("chi_sim");
//cmd.add("eng");
ProcessBuilder pb = new ProcessBuilder();
/**
*Sets this process builder's working directory.
*/
pb.directory(imageFile.getParentFile());
cmd.set(1, imageFile.getName());
pb.command(cmd);
pb.redirectErrorStream(true);
long startTime = System.currentTimeMillis();
System.out.println("开始时间:" + startTime);
Process process = pb.start();
// tesseract.exe 1.jpg 1 -l chi_sim
//不习惯使用ProcessBuilder的,也可以使用Runtime,效果一致
// Runtime.getRuntime().exec("tesseract.exe 1.jpg 1 -l chi_sim");
/**
* the exit value of the process. By convention, 0 indicates normal
* termination.
*/
// System.out.println(cmd.toString());
int w = process.waitFor();
if (w == 0)// 0代表正常退出
{
BufferedReader in = new BufferedReader(new InputStreamReader(
new FileInputStream(outputFile.getAbsolutePath() + ".txt"),
"UTF-8"));
String str;
while ((str = in.readLine()) != null) {
strB.append(str).append(EOL);
}
in.close();
long endTime = System.currentTimeMillis();
System.out.println("结束时间:" + endTime);
System.out.println("耗时:" + (endTime - startTime) + "毫秒");
} else {
String msg;
switch (w) {
case 1:
msg = "Errors accessing files. There may be spaces in your image's filename.";
break;
case 29:
msg = "Cannot recognize the image or its selected region.";
break;
case 31:
msg = "Unsupported image format.";
break;
default:
msg = "Errors occurred.";
}
throw new RuntimeException(msg);
}
new File(outputFile.getAbsolutePath() + ".txt").delete();
return strB.toString().replaceAll("\\s*", "");
}
}