corosync+pacemaker基本配置
Pacemaker是 Linux环境中使用最为广泛的开源集群资源管理器。
1, Pacemaker利用集群基础架构(Corosync或者 Heartbeat)提供的消息和集群成员管理功能,实现节点和资源级别的故障检测和资源恢复,从而最大程度保证集群服务的高可用。
2,从逻辑功能而言,pacemaker在集群管理员所定义的资源规则驱动下,负责集群中软件服务的全生命周期管理,这种管理甚至包括整个软件系统以及软件系统彼此之间的交互。
3,Pacemaker在实际应用中可以管理任何规模的集群,由于其具备强大的资源依赖模型,这使得集群管理员能够精确描述和表达集群资源之间的关系(包括资源的顺序和位置等关系)。同时,对于任何形式的软件资源,通过为其自定义资源启动与管理脚本(资源代理),几乎都能作为资源对象而被 Pacemaker管理。
4,Pacemaker仅是资源管理器,并不提供集群心跳信息,由于任何高可用集群都必须具备心跳监测机制,因而很多初学者总会误以为 Pacemaker本身具有心跳检测功能,而事实上 Pacemaker的心跳机制主要基于 Corosync或 Heartbeat来实现
5,pacemaker只是作为HA的资源管理器,所以不要想当然理解它能够直接管控资源,如果你的资源没有做脚本配置那么对于pacemaker来说它就是不可管理的。
特性
1、监测并恢复节点和服务级别的故障。
2、存储无关,并不需要共享存储。
3、资源无关,任何能用脚本控制的资源都可以作为集群服务。
4、支持节点 STONITH功能以保证集群数据的完整性和防止集群脑裂。
5、支持大型或者小型集群。
6、支持 Quorum机制和资源驱动类型的集群。
7、支持几乎是任何类型的冗余配置。
8、自动同步各个节点的配置文件。
9、可以设定集群范围内的 Ordering、 Colocation and Anti-colocation等约束。
10、高级服务类型支持,例如:
Clone功能:即那些要在多个节点运行的服务可以通过Clone功能实现,Clone功能将会在多个节点上启动相同的服务;
Multi-state功能:
即那些需要运行在多状态下的服务可以通过 Multi–state实现,
在高可用集群的服务中,有很多服务会运行在不同的高可用模式下,如:Active/Active模式或者 Active/passive模式等,
并且这些服务可能会在 Active 与standby(Passive)之间切换。
11、具有统一的、脚本化的集群管理工具。
一:基本配置
Pacemaker集群管理:支持fence;对服务本身也有监控。使用corosync检测结点心跳。
一、集群结点端安装软件----linux1 ,linux2
1,先搭建好yum源
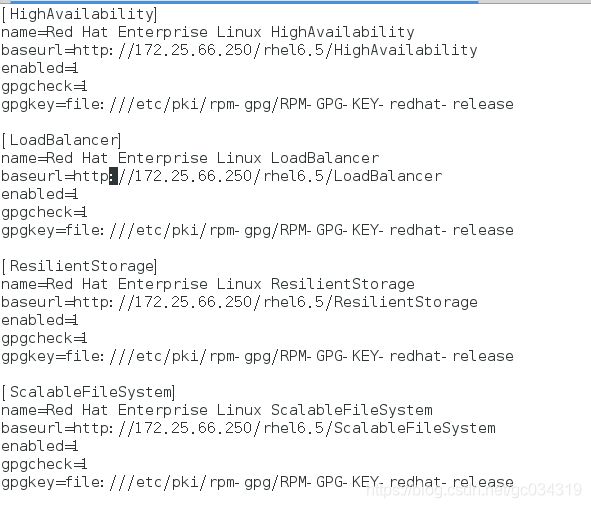
2,yum install pacemaker -y 两台都下载服务


3,下载所需要的依赖包,两个一起下载可解决相互依赖关系


4,拷贝主配置文件

5,配置文件
bindnetaddr: 172.25.66.0 ##集群结点网络
mcastport: 5466 ##多播端口

6,添加此段,启动corosync时,将pacemaker也启动 ver:0 开机自启动
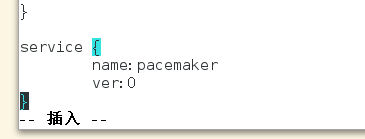
7,因为集群结点配置均相同,因此我们可以将配置文件拷贝至其它结点

启动服务


8, crm_mon 查看结点连接状态
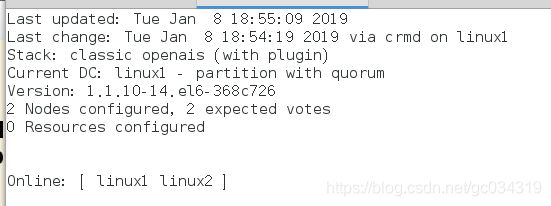
9,关闭fence模块
表示资源不会迁移
verify 检测
commit 保存

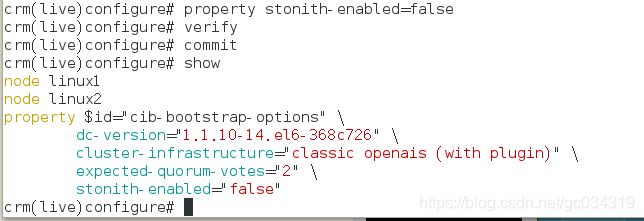
查看是否同步

10,交互式命令
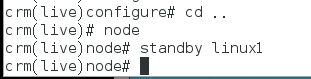
crm(live)# node ##进入对结点操作模式
crm(live)node# standby ##使其为standbt状态 linux1下线


1)online上线,(后面加上那台主机的名字可使那台主机下线或上线)

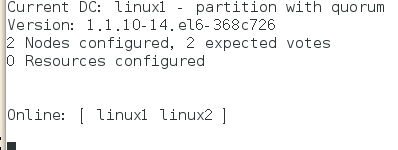
2)创建资源vip,监控以上资源在哪个结点上运行;
添加vip资源,params 指定参数 op monitor 监控配置,interval指定执行操作的频率,单位:秒

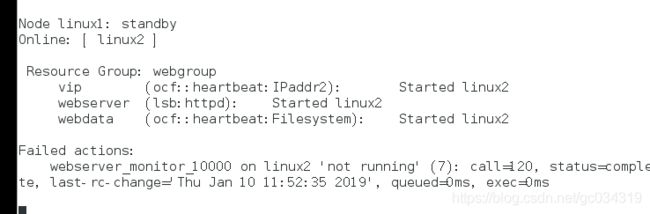
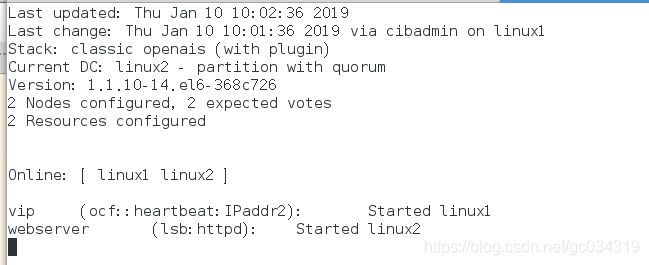
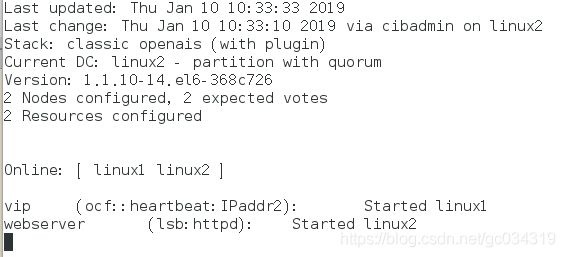
3)online:表示服务正常且可以接管资源的结点;标记部分为添加的资源;started:表示该资源正运行在server1结点上
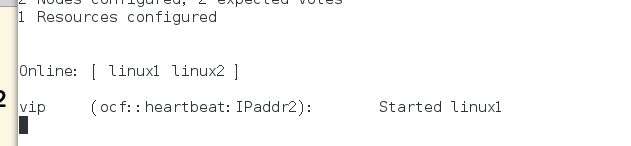
4)测试 使其为standbt状态 linux2接管,
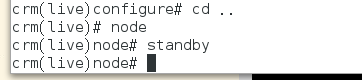

5)pacemaker默认无回切机制,关机linux2结点,让linux1结点上线
若关闭服务,则为OFFline;若是一个双结点集群,当有一端宕掉服务时,另一结点则会自动丢弃资源,也不再接管,因为一个结点不能构成集群。


linux2上线资源并不会回切,在这之前我已将linux1上线


安装apache
在两个节点上都安装
![]()
![]()
建立发布文件


在集群上加入apache
只在一端加入即可,加入httpd服务

建立集群服务组
目的是为了让服务都运行在一台服务器上


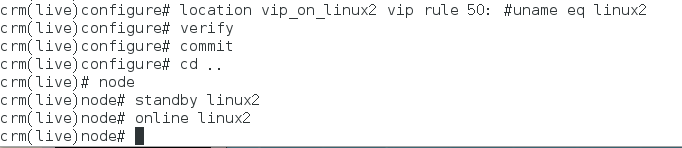
linux1下线 linux2接管,linux1再次上线 ,pacemaker默认无回切机制


不仅仅只有服务组这一种方法,下面我们试第二种
先删除集群服务组,删除方法如下


排列约束 (colocation):资源间的依赖/互斥性,定义资源是否运行在同一节点上


位置约束(location):每个节点都有一个score值,正值则倾向于本节点,负值倾向于其他节点,所有节点score比较,倾向于最大值的节点。

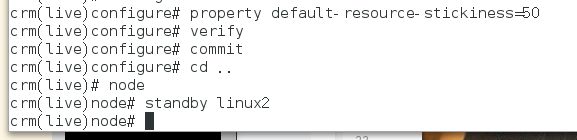
设置默认的粘滞性

定义资源监控配置如下:当httpd服务停止时,将自动重启httpd,如重启失败则将资源转移至可用的节点

这里简单介绍在添加资源时命令写错的解决方法
添加vip资源,params 指定参数 op monitor 监控配置,interval指定执行操作的频率,单位:秒

添加服务

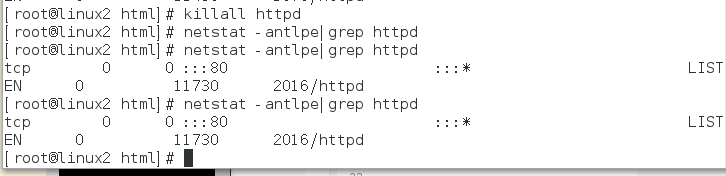
测试:当杀死httpd服务时,根据规则会对httpd进行监控,然后再次让httpd服务启动
可用下面方法删除图中的缓存

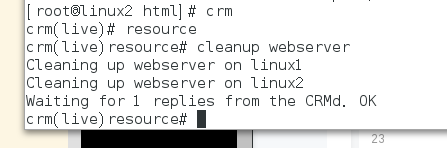
三、corosync+pacemaker+nfs实现高可用案例
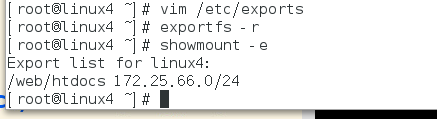
此实验需将另一台服务器启动nfs服务并挂载至两节点上配置同样的页面文件


建立一个递归目录,并且给所有人执行权限
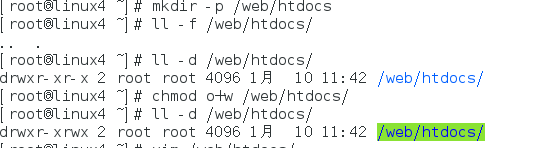
建立共享的发布目录,可读可写

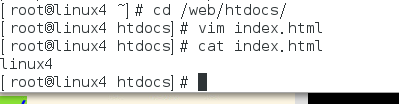
尝试是否成功挂载
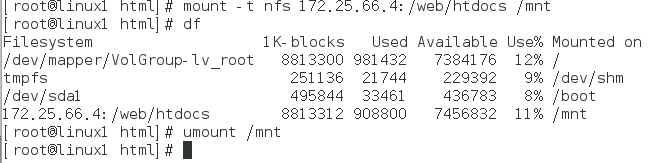
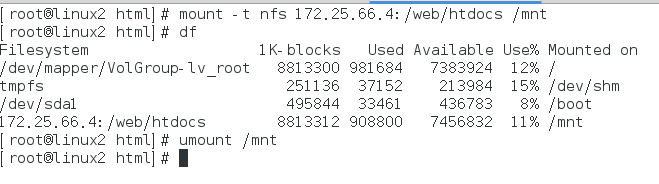
定义webdata

将vip、webserver、webdata加入到webgroup组

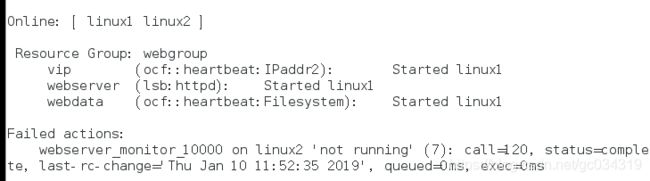
测试 此时服务在linux1上,可以看到linux4共享过来的文件内容
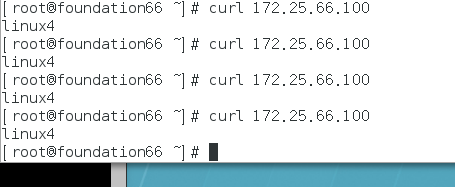
自动挂载

使linux1处于standby状态,linux2接管并且自动挂载,测试也是可以看到linux4共享过来文件的内容