Python编码问题
最近python爬虫遇到的编码问题太多了,发篇博文记录一下

问题
很普通的一个爬虫代码,代码是这样的:
# ecoding=utf-8
import re
import requests
import sys
reload(sys)
sys.setdefaultencoding('utf8')
url = 'http://sz.lianjia.com/ershoufang/rs%E6%8B%9B%E5%95%86%E6%9E%9C%E5%B2%AD/'
res = requests.get(url)
print res.text
目的其实很简单,就是爬一下链家的内容,但是这样执行之后,返回的结果,所有涉及到中文的内容,全部会变成乱码,比如这样

<script type="text/template" id="newAddHouseTpl">
<span class="newHouseRightClose">xspan>
div>
script>
这样的数据拿来可以说毫无作用。
问题分析
这里的问题很明显了,就是文字的编码不正确,导致了乱码。
查看网页的编码
从爬取的目标网页的头来看,网页是用utf-8来编码的。
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
所以,最终的编码,我们肯定也要用utf-8来处理,也就是说,最终的文本处理,要用utf-8来解码,也就是:decode('utf-8’)
文本的编码解码
Python的编码解码的过程是这样的,源文件 ===》 encode(编码方式) ===》decode(解码方式),在很大的程度上,不推荐使用
import sys
reload(sys)
sys.setdefaultencoding('utf8')
这种方式来硬处理文字编码。不过在某些时候不影响的情况下,偷偷懒也不是什么大问题,不过比较建议的就是获取源文件之后,使用encode和decode的方式来处理文本。
回到问题
现在问题最大的是源文件的编码方式,我们正常使用requests的时候,它会自动猜源文件的编码方式,然后转码成Unicode的编码,但是,毕竟是程序,是有可能猜错的,所以如果猜错了,我们就需要手工来指定编码方式。官方文档的描述如下:
When you make a request, Requests makes educated guesses about the encoding of the response based on the HTTP headers. The text encoding guessed by Requests is used when you access r.text. You can find out what encoding Requests is using, and change it, using the r.encoding property.
所以我们需要查看requests返回的编码方式到底是什么?
# ecoding=utf-8
import re
import requests
from bs4 import BeautifulSoup
import sys
reload(sys)
sys.setdefaultencoding('utf8')
url = 'http://sz.lianjia.com/ershoufang/rs%E6%8B%9B%E5%95%86%E6%9E%9C%E5%B2%AD/'
res = requests.get(url)
print res.encoding
打印的结果如下:
ISO-8859-1
也就是说,源文件使用的是ISO-8859-1来编码。百度一下ISO-8859-1,结果如下:
ISO8859-1,通常叫做Latin-1。Latin-1包括了书写所有西方欧洲语言不可缺少的附加字符。
问题解决
发现了这个东东,问题就很好解决了,只要指定一下编码,就能正确的打出中文了。代码如下:
# ecoding=utf-8
import requests
import sys
reload(sys)
sys.setdefaultencoding('utf8')
url = 'http://sz.lianjia.com/ershoufang/rs%E6%8B%9B%E5%95%86%E6%9E%9C%E5%B2%AD/'
res = requests.get(url)
res.encoding = ('utf8')
print res.text
打印的结果就很明显,中文都正确的显示出来了。

另一种方式是在源文件上做解码和编码,代码如下:
# ecoding=utf-8
import requests
import sys
reload(sys)
sys.setdefaultencoding('utf8')
url = 'http://sz.lianjia.com/ershoufang/rs%E6%8B%9B%E5%95%86%E6%9E%9C%E5%B2%AD/'
res = requests.get(url)
# res.encoding = ('utf8')
print res.text.encode('ISO-8859-1').decode('utf-8')
另:ISO-8859-1也叫做latin1,使用latin1做解码结果也是正常的。
Python3编码问题
从网上抓了一些字节流,想打印出来结果发生了一下错误:
UnicodeEncodeError: 'gbk' codec can't encode character '\xbb' in position 8530: illegal multibyte sequence
代码
import urllib.request res=urllib.request.urlopen('http://www.baidu.com') htmlBytes=res.read() print(htmlBytes.decode('utf-8'))
错误信息让人很困惑,为什么用的是'utf-8'解码,错误信息却提示'gbk'错误呢?
不仅如此,从百度首页的html中发现以下代码:
"content-type" content="text/html;charset=utf-8">
这说明网页的确用的是utf-8,为什么会出现Error呢?
在python3里,有几点关于编码的常识
1.字符就是unicode字符,字符串就是unicode字符数组
如果用以下代码测试,
print('a'=='\u0061')
会发现结果为True,足以说明两者的等价关系。
2.str转bytes叫encode,bytes转str叫decode,如上面的代码就是将抓到的字节流给decode成unicode数组
我根据上面的错误信息分析了字节流中出现\xbb的地方,发现有个\xc2\xbb的特殊字符»,我怀疑是它无法被解码。
用以下代码测试后
print(b'\xc2\xbb'.decode('utf-8'))
它果然报错了:UnicodeEncodeError: 'gbk' codec can't encode character '\xbb' in position 0: illegal multibyte sequence
上网找了下utf-8编码表,发现的确特殊字符»的utf-8形式就是c2bb,unicode是'\u00bb',为什么无法解码呢。。。
仔细看看错误信息,它提示'gbk'无法encode,但是我的代码是utf-8无法decode,压根牛头不对马嘴,终于让我怀疑是print函数出错了。。于是立即有了以下的测试
print('\u00bb')
结果报错了:UnicodeEncodeError: 'gbk' codec can't encode character '\xbb' in position 0: illegal multibyte sequence
原来是print()函数自身有限制,不能完全打印所有的unicode字符。
知道原因后,google了一下解决方法,其实print()函数的局限就是Python默认编码的局限,因为系统是win7的,python的默认编码不是'utf-8',改一下python的默认编码成'utf-8'就行了
import io
import sys
import urllib.request
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf8') #改变标准输出的默认编码
res=urllib.request.urlopen('https://blog.csdn.net/m0_37438418/article/details/80610550')
htmlBytes=res.read()
print(htmlBytes.decode('utf-8'))
运行后不报错了,但是居然有好多乱码(英文显示正常,中文则显示乱码)!!又一阵折腾后发现是控制台的问题,具体来说就是我在cmd下运行该脚本会有乱码,而在IDLE下运行却很正常。
由此我推测是cmd不能很好地兼容utf8,而IDLE就可以,甚至在IDLE下运行,连“改变标准输出的默认编码”都不用,因为它默认就是utf8。如果一定要在cmd下运行,那就改一下编码,比如我换成“gb18030”,就能正常显示了:
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030') #改变标准输出的默认编码
最后,附上一些常用的和中文有关的编码的名称,分别赋值给encoding,就可以看到不同的效果了:
| 编码名称 | 用途 |
| utf8 | 所有语言 |
| gbk | 简体中文 |
| gb2312 | 简体中文 |
| gb18030 | 简体中文 |
| big5 | 繁体中文 |
| big5hkscs | 繁体中文 |
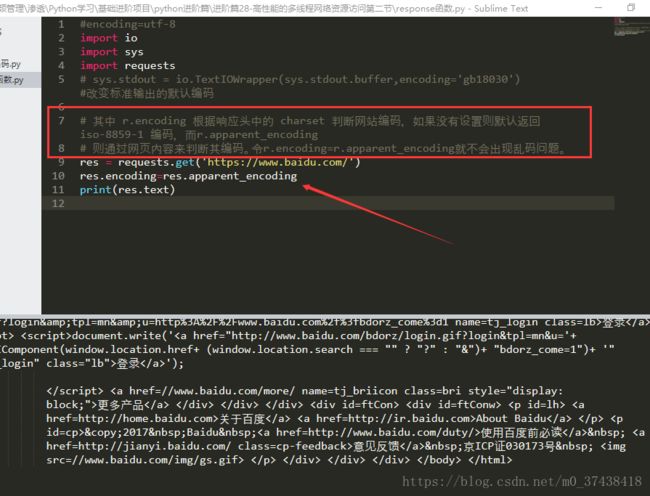
#encoding=utf-8
import io
import sys
import requests
# sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030') #改变标准输出的默认编码
# 其中 r.encoding 根据响应头中的 charset 判断网站编码,如果没有设置则默认返回 iso-8859-1 编码,而r.apparent_encoding
# 则通过网页内容来判断其编码。令r.encoding=r.apparent_encoding就不会出现乱码问题。
res = requests.get('https://www.baidu.com/')
res.encoding=res.apparent_encoding
print(res.text)
sublime的配置问题

介绍
一直不太喜欢使用命令行,所以去年年底的技术创新中,使用TkInter来开发小工具。结果花费了大量的时间来学习TkInter ui的使用。
最近想整理该工具,使用命令行的形式,然后将该工具做成exe的形式进行分发。在工作一开始就遇到了编码的问题。
在脚本中有如下代码,用来接收用户交互式输入的ip。
server = raw_input("请输GIS Server IP:")在脚本文件的第一行,我已经加了如下代码
# -*-coding: utf-8 -*-但是在windows 的控制台执行的时候,出现了乱码。有点不解,因为自己一直以来在python中,处理中文都是在文件头加入该代码。
通过搜索发现,是因为在windows cmd 默认的使用的cp936的编码。既然知道使用这种编码则将编码改为如下:
# -*-coding: cp936-*-但是得到如下的错误:
SyntaxError: encoding problem: cp936 with BOM百思不得其解。作为懒癌患者,就想绕过去。则采用如下方式,对单独字符串进行编码。
userName=raw_input("请输入站点管理员用户名:".decode("utf-8").encode("cp936"))这样重要在cmd中可以正常的输出中文了。但是问题来了,我的脚本中,有上百行代码有中文。每个地方都这么写,感觉偷懒不成,反被*。
这个时候,通过搜索。逐步的发现了问题的原因。这是因为python有几个层次的编码。分别是:
- 字符串变量级别编码
- 脚本级别的编码
- py文件级别的编码
- 显示窗口的编码
字符串变量的编码
对单个字符串转码,可以使用:encode()编码成可以显示的。通常对字符串不能由一个编码直接转换为另一个编码。通常需要解码到Unicode,然后对unicode字符串重新的编码。比如上面的示例。
脚本的编码
上面通过设置 #coding:utf-8设置的就是脚本里面内容的编码。也就是该脚本文件中所有的字符串变量都采用该处设置的编码方式。
py文件的编码
py文件的编码,默认的是ANSI。但是也可以使用utf-8,unicode编码。
显示窗口的编码
上面的几种情况,中文在运行阶段不会出错。但是这些中文还不一定能够正常的显示。能否正常的显示,还有显示窗口支持的编码决定。比如cmd中中文支持GBK和cp936,所以代码中的字符串需要编码到这两种才可以显示。
测试
- 当py文件的编码为utf-8的时候。代码中唔需要添加#coding:utf-8 。脚本中的中文,在运行过程不会报错。
当py文件的编码为ANSI的时候。如代码中没有显示的添加 ** --coding:utf-8 -- **,则当代码中出现中文的时候,运行脚本的时候。会出现如下错误
SyntaxError: Non-ASCII character '\xe4' in file当py文件设置为utf-8,而显示设置代码编码为#coding:936。则会出现ncoding problem: cp936 with BOM的错。这个时候,将py文件的编码改为ANSI即可。
结论
通过上面的测试,有几个结论:
- 编码有层次结构。文件编码影响脚本内容编码,脚本内容编码决定 其中的字符串编码。
- 当字符串显示设置了编码的时候。字符串的编码为显示设置的编码,此时文件和脚本编码不起作用。当字符串没有显示设置编码的时候,则采用上一级编码决定。
- 所以设置这三种编码的时候,需要确保三种编码之间能够转换。否则会出现上面列举的错误。
其他衍生
关于字符的编码,很多东西可以说,想了解的朋友可以参考以下大神的资料。
《The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets (No Excuses!)》
字符编码笔记:ASCII,Unicode和UTF-8
https://www.cnblogs.com/myyouthlife/p/4748096.html
Python3编码问题