Spark Streaming——DStream Transformation操作
Spark Streaming——DStream Transformation操作
Spark的各个子框架都是基于spark core的,Spark Streaming在内部的处理机制是,接收实时流的数据,并根据一定的时间间隔拆分成一批数据,然后通过Spark Engine处理这些批数据,最终得到处理后的一批结果数据。
对应的批数据,在spark内核对应一个RDD实例,因此,对应流数据的DStream可以看成是一组RDD,即RDD的一个序列。通俗点理解,在流数据分成一批批后,通过一个先入先出的队列,然后Spark Engine从该队列中依次取出一个个批数据,然后把批数据封装成一个RDD,然后进行处理,这是一个典型的生产消费者模型。
1 术语定义
- 离散流(discretized stream或DStream) : 这是Spark STreaming对内部持续的实时数据流的抽象描述,即我们处理的一个实时数据流,在spark Streaming中对应一个DStream实例
- 批数据(batch data) : 这是化整为零的第一步,将实时流数据以时间片为单位进行分批,将流处理转换为时间片数据的批处理。随着持续时间的推移,这些处理结果就形成了对应的结果数据流。
- 时间片或批处理时间间隔(batch interval) : 这是程序员对六数据进行定量的标准,以时间片作为我们拆分流数据的依据。一个时间片的数据对应一个RDD实例。
- 窗口长度(window length) : 一个窗口覆盖的六数据的时间长度。必须是批处理时间间隔的倍数。
- 滑动时间间隔 : 前一个窗口到后一个窗口所经过的时间长度。必须是批处理时间间隔的背书。
- Input DStream : 一个Dstream是一个特殊的DStream,将spark Streaming连接到一个外部数据源来读取数据
2 Dstream Transformation操作
2.1 函数说明
| Transformaiton | Meaning |
|---|---|
| map(func) | 对DStream中的各个元素进行func函数操作,然后返回一个新的DStream. |
| flatMap(func) | 与map方法类似,只不过各个输入项可以被输出为零个或多个输出项 |
| filter(func) | 过滤出所有函数func返回值为true的DStream元素并返回一个新的DStream |
| repartition(numPartitions) | 增加或减少DStream中的分区数,从而改变DStream的并行度 |
| union(otherStream) | 将源DStream和输入参数为otherDStream的元素合并,并返回一个新的DStream. |
| count() | 通过对DStreaim中的各个RDD中的元素进行计数,然后返回只有一个元素的RDD构成的DStream |
| reduce(func) | 对源DStream中的各个RDD中的元素利用func进行聚合操作,然后返回只有一个元素的RDD构成的新的DStream. |
| countByValue() | 对于元素类型为K的DStream,返回一个元素为(K,Long)键值对形式的新的DStream,Long对应的值为源DStream中各个RDD的key出现的次数 |
| reduceByKey(func, [numTasks]) | 利用func函数对源DStream中的key进行聚合操作,然后返回新的(K,V)对构成的DStream |
| join(otherStream, [numTasks]) | 输入为(K,V)、(K,W)类型的DStream,返回一个新的(K,(V,W)类型的DStream |
| cogroup(otherStream, [numTasks]) | 输入为(K,V)、(K,W)类型的DStream,返回一个新的 (K, Seq[V], Seq[W]) 元组类型的DStream |
| transform(func) | 通过RDD-to-RDD函数作用于源码DStream中的各个RDD,可以是任意的RDD操作,从而返回一个新的RDD |
| updateStateByKey(func) | 根据于key的前置状态和key的新值,对key进行更新,返回一个新状态的DStream |
2.2 实例
//读取本地文件~/streaming文件夹
val lines = ssc.textFileStream(args(0))
val words = lines.flatMap(_.split(" "))
val wordMap = words.map(x => (x, 1))
val wordCounts=wordMap.reduceByKey(_ + _)
val filteredWordCounts=wordCounts.filter(_._2>1)
val numOfCount=filteredWordCounts.count()
val countByValue=words.countByValue()
val union=words.union(word1)
val transform=words.transform(x=>x.map(x=>(x,1)))
//显式原文件
lines.print()
//打印flatMap结果
words.print()
//打印map结果
wordMap.print()
//打印reduceByKey结果
wordCounts.print()
//打印filter结果
filteredWordCounts.print()
//打印count结果
numOfCount.print()
//打印countByValue结果
countByValue.print()
//打印union结果
union.print()
//打印transform结果
transform.print()执行结果如下:
-------------------------------------------
lines.print()
-------------------------------------------
A B C D
A B
-------------------------------------------
flatMap结果
-------------------------------------------
A
B
C
D
A
B
-------------------------------------------
map结果
-------------------------------------------
(A,1)
(B,1)
(C,1)
(D,1)
(A,1)
(B,1)
-------------------------------------------
reduceByKey结果
-------------------------------------------
(B,2)
(D,1)
(A,2)
(C,1)
-------------------------------------------
filter结果
-------------------------------------------
(B,2)
(A,2)
-------------------------------------------
count结果
-------------------------------------------
2
-------------------------------------------
countByValue结果
-------------------------------------------
(B,2)
(D,1)
(A,2)
(C,1)
-------------------------------------------
union结果
-------------------------------------------
A
B
C
D
A
B
A
B
C
D
...
-------------------------------------------
transform结果
-------------------------------------------
(A,1)
(B,1)
(C,1)
(D,1)
(A,1)
(B,1)3 窗口转换操作
Spark streaming提供窗口操作(window option),如下图所示:
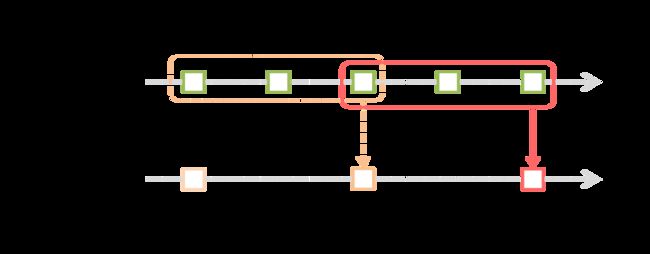
上图中,红色实线表示窗口当前的滑动位置,虚线表示前一次窗口位置,窗口每滑动一次,落在该窗口中的RDD被一起同时处理,生成一个窗口DStream(windowed DStream),窗口操作需要设置两个参数:
- 窗口长度(window length),即窗口的持续时间,上图中的窗口长度为3
- 滑动间隔(sliding interval),窗口操作执行的时间间隔,上图中的滑动间隔为2
这两个参数必须是原始DStream 批处理间隔(batch interval)的整数倍(上图中的原始DStream的batch interval为1)
3.1 函数说明
| Transformation | Meaning |
|---|---|
| window(windowLength, slideInterval) | 返回一个基于源DStream的窗口批次计算后得到新的DStream。 |
| countByWindow(windowLength,slideInterval) | 返回基于滑动窗口的DStream中的元素的数量。 |
| reduceByWindow(func, windowLength,slideInterval) | 基于滑动窗口对源DStream中的元素进行聚合操作,得到一个新的DStream |
| reduceByKeyAndWindow(func,windowLength, slideInterval, [numTasks]) | 基于滑动窗口对(K,V)键值对类型的DStream中的值按K使用聚合函数func进行聚合操作,得到一个新的DStream。 |
| reduceByKeyAndWindow(func, invFunc,windowLength, slideInterval, [numTasks]) | 一个更高效的reduceByKkeyAndWindow()的实现版本,先对滑动窗口中新的时间间隔内数据增量聚合并移去最早的与新增数据量的时间间隔内的数据统计量。例如,计算t+4秒这个时刻过去5秒窗口的WordCount,那么我们可以将t+3时刻过去5秒的统计量加上[t+3,t+4]的统计量,在减去[t-2,t-1]的统计量,这种方法可以复用中间三秒的统计量,提高统计的效率 |
| countByValueAndWindow(windowLength,slideInterval, [numTasks]) | 基于滑动窗口计算源DStream中每个RDD内每个元素出现的频次并返回DStream[(K,Long)],其中K是RDD中元素的类型,Long是元素频次。与countByValue一样,reduce任务的数量可以通过一个可选参数进行配置。 |
对于窗口操作,批处理间隔、窗口间隔和滑动间隔是非常重要的三个时间概念,是理解窗口操作的关键所在。
3.2 代码示例
// WindowWordCount——reduceByKeyAndWindow方法使用
import org.apache.spark.{SparkContext, SparkConf}
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._
object WindowWordCount {
def main(args: Array[String]) {
//传入的参数为localhost 9999 30 10
if (args.length != 4) {
System.err.println("Usage: WindowWorldCount " )
System.exit(1)
}
StreamingExamples.setStreamingLogLevels()
val conf = new SparkConf().setAppName("WindowWordCount").setMaster("local[4]")
val sc = new SparkContext(conf)
// 创建StreamingContext,batch interval为5秒
val ssc = new StreamingContext(sc, Seconds(5))
//Socket为数据源
val lines = ssc.socketTextStream(args(0), args(1).toInt, StorageLevel.MEMORY_ONLY_SER)
val words = lines.flatMap(_.split(" "))
// windows操作,对窗口中的单词进行计数
val wordCounts = words.map(x => (x , 1)).reduceByKeyAndWindow((a:Int,b:Int) => (a + b), Seconds(args(2).toInt), Seconds(args(3).toInt))
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}通过下列代码启动netcat server
root@sparkmaster:~# nc -lk 9999
Spark is a fast and general cluster computing system for Big Data. It provides执行结果如下:
-------------------------------------------
Time: 1448778805000 ms(10秒,第一个滑动窗口时间)
-------------------------------------------
(provides,1)
(is,1)
(general,1)
(Big,1)
(fast,1)
(cluster,1)
(Data.,1)
(computing,1)
(Spark,1)
(a,1)
...
-------------------------------------------
Time: 1448778815000 ms(10秒后,第二个滑动窗口时间)
-------------------------------------------
(provides,1)
(is,1)
(general,1)
(Big,1)
(fast,1)
(cluster,1)
(Data.,1)
(computing,1)
(Spark,1)
(a,1)
...
-------------------------------------------
Time: 1448778825000 ms(10秒后,第三个滑动窗口时间)
-------------------------------------------
(provides,1)
(is,1)
(general,1)
(Big,1)
(fast,1)
(cluster,1)
(Data.,1)
(computing,1)
(Spark,1)
(a,1)
...
-------------------------------------------
Time: 1448778835000 ms(再经10秒后,超出window length窗口长度,不在计数范围内)
-------------------------------------------
-------------------------------------------
Time: 1448778845000 ms
-------------------------------------------4 输出操作
Spark Streaming允许DStream的数据被输出到外部系统,如数据库或文件系统。由于输出操作实际上使transformation操作后的数据可以通过外部系统被使用,同时输出操作触发所有DStream的transformation操作的实际执行(类似于RDD操作)。以下表列出了目前主要的输出操作:
| 函数 | 解释 |
|---|---|
| print() | 在Driver中打印出DStream中数据的前10个元素。 |
| saveAsTextFiles(prefix, [suffix]) | 将DStream中的内容以文本的形式保存为文本文件,其中每次批处理间隔内产生的文件以prefix-TIME_IN_MS[.suffix]的方式命名 |
| saveAsObjectFiles(prefix, [suffix]) | 将DStream中的内容按对象序列化并且以SequenceFile的格式保存。其中每次批处理间隔内产生的文件以prefix-TIME_IN_MS[.suffix]的方式命名。 |
| saveAsHadoopFiles(prefix, [suffix]) | 将DStream中的内容以文本的形式保存为Hadoop文件,其中每次批处理间隔内产生的文件以prefix-TIME_IN_MS[.suffix]的方式命名。 |
| foreachRDD(func) | 最基本的输出操作,将func函数应用于DStream中的RDD上,这个操作会输出数据到外部系统,比如保存RDD到文件或者网络数据库等。需要注意的是func函数是在运行该streaming应用的Driver进程里执行的。 |
参考博文
http://www.cnblogs.com/shishanyuan/p/4747735.html
https://yq.aliyun.com/articles/60316?spm=5176.8251999.569296.76.20f9f017kExcvc#
https://yq.aliyun.com/articles/60315?spm=5176.8251999.569296.77.20f9f017XgNbIM