Python 深度学习--学习笔记(十五)
温度预测问题
今天我们将使用一个天气时间序列数据集,它由德国耶拿的马克思 • 普朗克生物地球化学研究所的气象站记录。
目的是给定一些数据,预测24小时之后的气温。
首先,先在https://s3.amazonaws.com/kerasdatasets/jena_climate_2009_2016.csv.zip 下载数据集。
- 查看数据
import os
data_dir = 'C:\\Users\\Administrator\\Desktop\\Keras_learn\\jena_climate'
fname = os.path.join(data_dir,'jena_climate_2009_2016.csv')
f = open(fname,encoding='utf-8')
data = f.read()
f.close()
lines = data.split('\n')
header = lines[0].split(',') #csv文件
lines = lines[1:]
print(header)
print(len(lines))

在这个数据集中,每 10 分钟记录 14 个不同的量(比如气温、气压、湿度、风向等),其中包含多年的记录。
- 解析数据
import numpy as np
float_data = np.zeros((len(lines),len(header)-1))
#第一个元素是记录的时间,不是学习的内容
for i,line in enumerate(lines):
values = [float(x) for x in line.split(',')[1:]]
float_data[i,:] = values
import matplotlib.pyplot as plt
temp = float_data[:,1] #第二个元素为temperature,即原数据的第三个元素
plt.plot(range(len(temp)),temp)

这是2009-2016年的数据。可以看到,这些天气数据很有周期性。
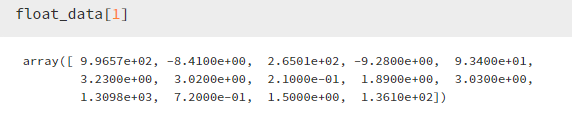
在同一时间内,温、气压、湿度、风向等的单位都不一样,例如:温度通道位于 -20 到 +30之间,但气压大约在 1000 毫巴上下,这造成数据大小不一:
为了让机器更高效地学习,这里需要对它们正则化处理:
mean = float_data[:200000].mean(axis=0)
float_data -= mean
std = float_data[:200000].std(axis=0)
float_data /= std
现在这一步,也是最难地一步,提取样本集:
- lookback表示时间跨度
- delay我们设置为lookback地后delay的时间(预测24小时之后的气温,则delay=24*60/10=144)
- [min_index,max_index]表示取值的区间
- shuffle表示时候需要打乱循序
- step表示每多少10分钟提取一次数据
#生成时间序列样本及其目标的 生成器
#lookback为时间跨度
def generator(data, lookback, delay, min_index, max_index,
shuffle=False, batch_size=128, step=6):
if max_index is None:
max_index = len(data) - delay - 1
#目的是要让24小时后取到值
i = min_index + lookback #可取的跨度终点的起始点
while 1:
if shuffle:
rows = np.random.randint(
min_index + lookback, max_index, size=batch_size)
else:
if i + batch_size >= max_index:
i = min_index + lookback #回到起点
rows = np.arange(i, min(i + batch_size, max_index))
i += len(rows)
samples = np.zeros((len(rows),
lookback // step,
#每一个小时取一个值
data.shape[-1]))
targets = np.zeros((len(rows),))
#24小时后的值,即为标签值
for j, row in enumerate(rows):
indices = range(rows[j] - lookback, rows[j], step)
samples[j] = data[indices]
targets[j] = data[rows[j] + delay][1]
#目标选取隔一天的温度(温度是第二列的数据)
yield samples, targets
#sample为学习数据,targets充当监督学习标签
- 定义数据集
lookback = 1440 #10天
step = 6
delay = 144 #1天
batch_size = 128
train_gen = generator(float_data,
lookback=lookback,
delay=delay,
min_index=0,
max_index=200000,
shuffle=True,
step=step,
batch_size=batch_size)
val_gen = generator(float_data,
lookback=lookback,
delay=delay,
min_index=200001,
max_index=300000,
step=step,
batch_size=batch_size)
test_gen = generator(float_data,
lookback=lookback,
delay=delay,
min_index=300001,
max_index=None,
step=step,
batch_size=batch_size)
val_steps = (300000 - 200001 - lookback) // batch_size
test_steps = (len(float_data) - 300001 - lookback) // batch_size
- 用简单的密集层构建,训练模型
from keras.models import Sequential
from keras import layers
from keras.optimizers import RMSprop
model = Sequential()
model.add(layers.Flatten(input_shape=(lookback//step,float_data.shape[-1],)))
model.add(layers.Dense(32,activation='relu'))
model.add(layers.Dense(1))
model.compile(optimizer=RMSprop(),
loss='mae',)
train_steps = (200000 - lookback) // batch_size
history = model.fit_generator(train_gen,
steps_per_epoch=train_steps,
epochs=20,
validation_data=val_gen,
validation_steps=val_steps
)

差值换算公式:
tmp = loss * std[1]
0.35 x std[1] = 3.098
故,预测值与24小时后的温度相差3.1°C左右。
我们可以知道,天气温度的预测问题是严格按照时间序列的。这让我们想到,可以要循环RNN层来训练模型来提高精度。
- 重新构建模型
这里我们将使用GRU循环层,可以简单理解GRU是LSTM的简化版,这可以缩短运算时间,同时为了抑制过拟合,我们加上循环层特有的外部Dropout和内部循环Dropout,循环的Dropout比较特殊,这里不详细介绍,需要深入了解的可以自行搜索。这里就简要提下:每个循环层都有两个与 dropout 相关的参数,对每个时间步使用相同的 dropout 掩码,而不是让 dropout 掩码随着时间步的增加而随机变化。同时,特别注意,因为使用 dropout正则化的网络总是需要更长的时间才能完全收敛,所以网络训练轮次增加为原来的 2 倍。
from keras.models import Sequential
from keras import layers
from keras.optimizers import RMSprop
model = Sequential()
model.add(layers.GRU(32,
dropout=0.2,
#指定该层输入单元的 dropout 比率
recurrent_dropout=0.2,
#指定循环单元的 dropout 比率
input_shape=(lookback//step,float_data.shape[-1])))
model.add(layers.Dense(1))
model.compile(optimizer=RMSprop(),loss='mae')
history = model.fit_generator(train_gen,
steps_per_epoch=500,
epochs=40,
validation_data=val_gen,
validation_steps=val_steps)
model.save("GRU_With_Dropout.h5")

可以看到loss减小到了0.27,即2.4°C左右。
在真实预测时,2.4度的误差仍然很大,要提高精度,可以尝试循环层堆叠。在GRU层上再添加一层GRU循环层。注意,先循环的层需要设置return_sequences=True(之前讲过)。
这里代码运行相当耗时,故省略了,感兴趣的小伙伴一定要试一试。这里特别提醒,循环层堆叠会提前过拟合,适当提高Dropout值来抑制。
提高精度的方法还有一个,就是使用双向 RNN。这将在下一节讲到。