- linux制作自定义service服务单元
handsomestWei
后端linux后端
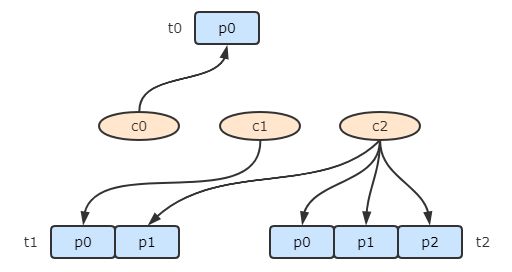
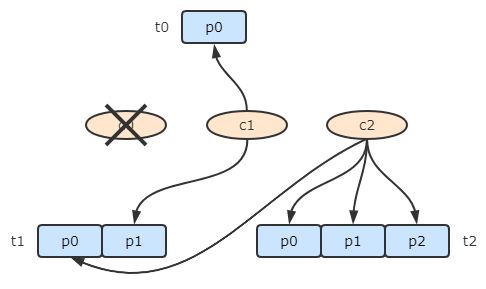
linux制作自定义service服务单元服务单元简介在Linux系统中,服务单元通常以.service后缀结尾,并存储在/etc/systemd/system目录下。服务单元文件定义了服务的启动顺序、依赖关系、执行命令等参数。使得系统管理员能够方便地启动、停止、重启和管理系统中的各种服务。java服务单元示例服务单元myJava.service文件示例。注意关闭标准输出,避免日志文件占用磁盘空间
- flume系列之:flume落cos
快乐骑行^_^
日常分享专栏flume系列
flume系列之:flume落cos一、参考文章二、安装cosjar包三、添加hadoop-cos的相关配置四、flume环境添加hadoop类路径五、使用cos路径六、启动/重启flume一、参考文章Kafka数据通过Flume存储到HDFS或COSflumetocos使用指南二、安装cosjar包将对应hadoop版本的hadoop-cos的jar包(hadoop-cos-{hadoop.ve
- Microi 吾码与 JavaScript:前端低代码平台的强大组合
小周不想卷
javascript
目录一、引言二、Microi吾码概述三、JavaScript在Microi吾码前端开发中的应用(一)前端V8引擎与JavaScript(二)接口引擎与JavaScript四、JavaScript在Microi吾码后端开发中的协同(一)与C#后端框架的交互(二)利用gRPC实现跨语言通信五、Microi吾码中JavaScript与数据库的交互六、Microi吾码中JavaScript在表单与模板引擎
- 线程池的拒绝策略有哪些?
IsToRestart
线程池
在Java中,线程池的拒绝策略决定了在任务队列已满的情况下,如何处理新提交的任务。当线程池达到最大容量并且任务队列也已满时,拒绝策略就会起作用。Java提供了四种内置的拒绝策略,它们分别是:AbortPolicy-这是默认的拒绝策略,当线程池无法接受新任务时,会抛出RejectedExecutionException异常。这意味着新任务会被立即拒绝,不会加入到任务队列中,也不会执行。通常情况下都是
- JavaScript进阶
不断学习的码农
javascriptjavascript前端vue.js
一.同步和异步程序同步程序就是从头到尾一一执行异步是同步程序执行完成之后才来执行异步程序js是单线程的一个任务执行完成之后才会执行另外一个二.js的内存结构栈内存和堆内存js分引用类型和原始类型原始类型存储在栈内存中引用类型存储在堆内存中三.什么是闭包闭包就是函数嵌套函数,内部的函数就是闭包正常情况下函数执行完成之后,内部的变量就会被销毁(释放内存)闭包:内部函数没有执行完成,外部函数变量不会被销
- Android 右键后无Java class创建
不吃凉粉
androidjava开发语言
Androidstudio创建javaclass:最近几个月用Androidstudio开发,因为电脑设置了一个新的用户使用,原来的androidstudio,打开之前的正常的项目总是报一些奇奇怪怪的错误,就重新安装了最新的版本问题描述但是新的androidstudio右键后没有javaclass,本来我就不怎么用java和androidstudio,又赶时间,不想花时间用更不了解的kotlin解
- Android 8 Wifi 初始化过程
weixin_34315665
移动开发java
记录一下wifi初始化过程。packages/apps/Settings/src/com/android/settings/wifi/WifiSettings.javapublicvoidonStart(){super.onStart();//创建WifiEnabler对象//On/offswitchishiddenforSetupWizard(returnsnull)mWifiEnabler=c
- 深入理解 Java 并发编程中的锁机制
向着开发进攻
java并发编程java开发语言
深入理解Java并发编程中的锁机制在Java并发编程中,锁是一个至关重要的概念,它用于确保多个线程在访问共享资源时能够遵循正确的顺序和互斥规则。锁机制的设计和使用直接影响到程序的效率、正确性和可维护性。本文将从锁的基本概念讲起,深入分析Java中的锁类型、实现方式以及如何避免常见的并发问题。1.什么是锁?锁是一种同步机制,它用于限制对共享资源的访问,确保在同一时刻只有一个线程能够访问资源。锁的目的
- JS宏进阶:Map与Object
jackispy
JS宏进阶javascript开发语言ecmascript
Object是JavaScript中最基本的数据类型之一,用于创建对象实例。newObject()是创建空对象的一种常见方式。而Map只是一种用于存储键值对的数据结构。相对于Object而言,他没有原型(也就是不能通过原型链的方式添加方法),但也存在自身的优势,某些场景,newMap可能比newObject更好用。下面是其内置方法的详细介绍:一、newMap1、创建新的Map对象,只能使用newM
- Java 并发舞台:多线程小精灵的奇幻冒险之旅
guihong004
java面试题java开发语言
1.线程池的拒绝策略有哪些?Java中的线程池提供了几种不同的拒绝策略,当线程池无法处理新的任务时(比如因为线程池已满并且工作队列也满了),这些策略会决定如何处理新提交的任务。ThreadPoolExecutor类中定义了以下四种内置的拒绝策略:AbortPolicy:这是默认的拒绝策略。当有新任务提交且线程池无法处理时,它会抛出一个RejectedExecutionException异常。Cal
- 什么是三高架构?
java1234_小锋
java架构java微服务
大家好,我是锋哥。今天分享关于【什么是三高架构?】面试题。希望对大家有帮助;什么是三高架构?1000道互联网大厂Java工程师精选面试题-Java资源分享网“三高架构”通常是指高可用性(HighAvailability)、高性能(HighPerformance)和高扩展性(HighScalability)架构。这三个特性是现代计算系统、尤其是在分布式系统和云计算架构中,设计和部署的关键目标。以下是
- JavaWeb 开发入门:从基础到应用
大梦百万秋
知识学爆java
JavaWeb是基于Java技术构建的Web应用开发体系。得益于Java的跨平台性和强大的生态系统,JavaWeb长期以来一直是企业级开发的首选方案之一。本篇博客将从JavaWeb的基本概念、核心技术到实际项目开发,带你全面了解如何利用JavaWeb构建一个动态网站。什么是JavaWeb?JavaWeb是使用Java技术开发Web应用程序的总称,通常包括动态网页、交互式功能和后端逻辑。它支持开发以
- 流量分析利器arkime的学习之路(二)---API接口
胖哥王老师
流量分析学习笔记网络协议学习arkimeAPI
前文回忆《流量分析利器arkime的学习之路(一)---安装部署》概述注意点Arkime对所有API调用都使用摘要身份验证,因此请确保在库或curl命令中启用摘要身份验证。学习如何进行API调用的最简单方法是打开浏览器的javascript控制台,观察ArkimeUI正在进行的调用,它使用所有相同的API。注意:许多API端点都需要一个数据库字段名称,这与您在搜索表达式中使用的名称不同。查看数据库
- Android应用开发入门:从Android Studio环境设置到Java编程基础
Python爬虫项目
移动开发精通教程androidandroidstudiojavagiteeide
目录介绍步骤一:设置AndroidStudio环境步骤二:了解AndroidStudio界面步骤三:学习Java编程基础变量和数据类型数组和集合控制流类和方法结论介绍Android应用开发是一个令人兴奋和有趣的领域。如果你对移动应用程序开发感兴趣,并且想要学习如何开始构建自己的Android应用,那么你来对地方了!本篇博客将带你从头开始,介绍如何设置AndroidStudio环境,学习Java编程
- JVM学习指南(41)-GC日志分析
俞兆鹏
JVM学习指南JVM
文章目录1.GC日志的重要性为什么需要分析GC日志?2.GC日志的基本格式示例GC日志格式3.如何启用和配置GC日志示例代码4.分析GC日志的关键指标5.案例分析案例1:频繁的MinorGC6.GC日志分析工具介绍GCViewerMAT(MemoryAnalyzerTool)7.最佳实践和注意事项常见陷阱8.总结1.GC日志的重要性GC(GarbageCollection)日志是Java虚拟机(J
- 2024最新版JavaScript逆向爬虫教程-------基础篇之JavaScript混淆原理
Amo Xiang
JS逆向爬虫开发语言js逆向
目录一、常量的混淆原理1.1对象属性的两种访问方式1.2十六进制字符串1.3Unicode字符串1.4字符串的ASCII码混淆1.5字符串常量加密1.6数值常量加密二、增加JS逆向者的工作量2.1数组混淆2.2数组乱序2.3花指令2.4jsfuck三、代码执行流程的防护原理3.1流程平坦化3.2逗号表达式混淆四、其他代码防护方案4.1eval加密4.2内存爆破4.3检测代码是否格式化一、常量的混淆
- Chapter Two:无限debugger的原理与绕过与断点调试
Amo Xiang
爬虫实战javascript前端无限debugger
目录1.无限debugger的原理与绕过1.1案例介绍1.2实现原理1.3禁用断点1.4补充:改写JavaScript文件2.断点调试1.无限debugger的原理与绕过1.1案例介绍debugger是JavaScript中定义的一个专门用于断点调试的关键字,只要遇到它,JavaScript的执行便会在此处中断,进入调试模式。有了debugger这个关键字,我们就可以非常方便地对JavaScrip
- 【强化学习】Mava框架
大雨淅淅
人工智能机器学习算法人工智能学习深度学习
目录一、选择框架二、学习框架基础三、深入框架高级特性四、实践项目五、参考文档和社区资源六、编写测试用例七、学习框架的生态系统八、持续学习和适应九、建立个人项目或工作项目十、反思和总结关于Mava框架的学习,首先需要明确的是,您可能是指Java框架的学习,因为“Mava”并非一个广为人知的特定Java框架名称。在Java开发领域,有多个知名的框架,如Spring、SpringBoot、Hiberna
- Python字典实战:打造高效学生成绩管理系统
清水白石008
pythonPython题库python开发语言
Python字典实战:打造高效学生成绩管理系统在日常学习和工作中,我们经常需要管理和查询数据。Python的字典(Dictionary)是一种非常强大的数据结构,它以键值对(key-valuepairs)的形式存储数据,能够实现高效的数据检索。本文将以创建一个学生成绩管理系统为例,深入讲解如何使用Python字典存储学生姓名和成绩信息,并实现根据姓名查找成绩的功能。本文旨在提供实用性强、内容丰富、
- iMac电脑启动ideal跑Java项目报错(Class JavaLaunchHelper is implemented in both...One of the two will be used.)
学习时长两年半的小学生
开发的小坑小洼编辑器java
第一次在iMac上面跑ideal,启动一个main方法出现报错(objc[19374]:ClassJavaLaunchHelperisimplementedinboth/Library/Java/JavaVirtualMachines/jdk1.8.0_121.jdk/Contents/Home/bin/java(0x10d1cb4c0)and/Library/Java/JavaVirtualMa
- 关于StringBuilder扩容机制的理解
司空怡瑾
java开发语言
一.为什么要用StringBuilder?在java中由于字符串的不可变性,即一旦创建就不能修改其内容,每次使用String类进行字符串拼接时,都会创建一个新的String对象,原有的String对象会被丢弃,为了解决这一问题,我们引入了StringBuilder类,StringBuilder是一个可变的字符序列,允许在原对象上进行修改,避免了创建大量的中间对象。二.StringBuilder的扩
- Java基础——String
白暮晚
Java八股java
Java基础——StringString是Java基础类型中较为特殊的一个类,我们这里着重探讨一下这个类。StringString底层使用一个char类型的数组来存储字符串,且该数组使用了private和final修饰为什么说String是不可变的final与private修饰该字符数组且未暴露修改方法,杜绝了从外部修改该对象的可能性由于final的使用导致子类无法继承该对象,进而导致子类不可能修
- JSON数据格式转换
百事老饼干
前端积累json
在前端Vue3中,处理JSON数据通常涉及到从API获取JSON、解析JSON数据、或者将JavaScript对象转换为JSON字符串。这里是几种常见的JSON转换操作一、从JSON字符串解析为JavaScript对象如果你从API或其他地方收到一个JSON字符串,可以使用JSON.parse()来将它转换为JavaScript对象。letjsonString='{"name":"John","a
- VUE前端实现防抖节流 Lodash
百事老饼干
前端积累前端
方法一:采用Lodash工具库Lodash是一个一致性、模块化、高性能的JavaScript实用工具库。(1)采用终端导入Lodash库$npmi-gnpm$npmi--savelodash(2)应用示例:搜索框输入防抖在这个示例中,我们希望用户在输入框中停止输入500毫秒后才执行搜索操作,避免频繁请求.//假设这是一个执行搜索操作的函数functionperformSearch(query){c
- minio免费文件管理器(windows版本),若依RuoYi-Vue-Plus框架使用,有需要的可以下载,因为官网下载特别慢
程序员WANG
工具windowsvue.js容器
MinIO是一款开源的对象存储系统,它提供类似AmazonS3的云存储服务,适用于各种规模的企业。MinIO设计为高性能、安全且易于使用,适合存储大量的非结构化数据,如图片、文档、视频以及大数据分析中的日志文件等。在本案例中,我们关注的是Windows版本的MinIO,它被集成到了若依RuoYi-Vue-Plus框架中,以实现文件管理功能。若依RuoYi-Vue-Plus是一个基于Vue.js的现
- 分布式系统理论基础二-CAP
王知无(import_bigdata)
GitHub:https://github.com/wangzhiwubigdata/God-Of-BigData关注公众号,内推,面试,资源下载,关注更多大数据技术~大数据成神之路~预计更新500+篇文章,已经更新50+篇~引言CAP是分布式系统、特别是分布式存储领域中被讨论最多的理论,“什么是CAP定理?”在Quora分布式系统分类下排名FAQ的No.1。CAP在程序员中也有较广的普及,它不仅
- Go 语言 map源码分析及图解(一)(查找、写入、删除K/V值)
Mr.禾
Gogolang数据结构源码分析图解
文章目录map基本结构hash值定位K/V值map创建计算桶的数量申请buckets内存空间tophash标记位介绍查找K/V值(mapaccess1)写入K/V值(mapassign)删除K/V值(mapdelete)map扩容的源码分析见下一节map基本结构hmap是map的核心数据结构:typehmapstruct{countint//当前的元素个数flagsuint8Buint8//桶的数
- 全面解析npm:功能、用途、命令和配置
阿吉的呓语
java开发知识npm
1.npm简介npm(NodePackageManager)是Node.js的官方包管理工具,用于安装、发布、管理JavaScript包和依赖关系。它是世界上最大的软件注册表之一,拥有数百万个包,每天处理数十亿次的下载请求。2.npm的功能和用途包安装和管理:通过npm可以方便地安装、更新、删除JavaScript包。依赖管理:npm能够管理项目的依赖关系,包括安装、更新和移除依赖。包发布和管理:
- Java:读取本地文件
Monly21
Javajava开发语言
/***读取本地JSON文件**@throwsIOException*/publicstaticvoidreadLocalFile()throwsIOException{Filefile=newFile("D:\\repo\\java_base_test\\data.json");FileReaderfileReader=newFileReader(file);BufferedReaderbuff
- 使用npm创建three.js项目
ShawnWeasley
npmjavascriptarcgis前端node.js
1.安装Node.js和npm首先,需要在您的计算机上安装Node.js和npm。Node.js是一个JavaScript运行环境,而npm是一个JavaScript包管理器。npm会随Node.js一起安装,因此只需要安装Node.js即可。从Node.js的官方网站(https://nodejs.org)下载并安装适合您操作系统的版本。2.创建一个新的项目在您希望创建项目的目录下,手动创建一个
- java工厂模式
3213213333332132
java抽象工厂
工厂模式有
1、工厂方法
2、抽象工厂方法。
下面我的实现是抽象工厂方法,
给所有具体的产品类定一个通用的接口。
package 工厂模式;
/**
* 航天飞行接口
*
* @Description
* @author FuJianyong
* 2015-7-14下午02:42:05
*/
public interface SpaceF
- nginx频率限制+python测试
ronin47
nginx 频率 python
部分内容参考:http://www.abc3210.com/2013/web_04/82.shtml
首先说一下遇到这个问题是因为网站被攻击,阿里云报警,想到要限制一下访问频率,而不是限制ip(限制ip的方案稍后给出)。nginx连接资源被吃空返回状态码是502,添加本方案限制后返回599,与正常状态码区别开。步骤如下:
- java线程和线程池的使用
dyy_gusi
ThreadPoolthreadRunnabletimer
java线程和线程池
一、创建多线程的方式
java多线程很常见,如何使用多线程,如何创建线程,java中有两种方式,第一种是让自己的类实现Runnable接口,第二种是让自己的类继承Thread类。其实Thread类自己也是实现了Runnable接口。具体使用实例如下:
1、通过实现Runnable接口方式 1 2
- Linux
171815164
linux
ubuntu kernel
http://kernel.ubuntu.com/~kernel-ppa/mainline/v4.1.2-unstable/
安卓sdk代理
mirrors.neusoft.edu.cn 80
输入法和jdk
sudo apt-get install fcitx
su
- Tomcat JDBC Connection Pool
g21121
Connection
Tomcat7 抛弃了以往的DBCP 采用了新的Tomcat Jdbc Pool 作为数据库连接组件,事实上DBCP已经被Hibernate 所抛弃,因为他存在很多问题,诸如:更新缓慢,bug较多,编译问题,代码复杂等等。
Tomcat Jdbc P
- 敲代码的一点想法
永夜-极光
java随笔感想
入门学习java编程已经半年了,一路敲代码下来,现在也才1w+行代码量,也就菜鸟水准吧,但是在整个学习过程中,我一直在想,为什么很多培训老师,网上的文章都是要我们背一些代码?比如学习Arraylist的时候,教师就让我们先参考源代码写一遍,然
- jvm指令集
程序员是怎么炼成的
jvm 指令集
转自:http://blog.csdn.net/hudashi/article/details/7062675#comments
将值推送至栈顶时 const ldc push load指令
const系列
该系列命令主要负责把简单的数值类型送到栈顶。(从常量池或者局部变量push到栈顶时均使用)
0x02 &nbs
- Oracle字符集的查看查询和Oracle字符集的设置修改
aijuans
oracle
本文主要讨论以下几个部分:如何查看查询oracle字符集、 修改设置字符集以及常见的oracle utf8字符集和oracle exp 字符集问题。
一、什么是Oracle字符集
Oracle字符集是一个字节数据的解释的符号集合,有大小之分,有相互的包容关系。ORACLE 支持国家语言的体系结构允许你使用本地化语言来存储,处理,检索数据。它使数据库工具,错误消息,排序次序,日期,时间,货
- png在Ie6下透明度处理方法
antonyup_2006
css浏览器FirebugIE
由于之前到深圳现场支撑上线,当时为了解决个控件下载,我机器上的IE8老报个错,不得以把ie8卸载掉,换个Ie6,问题解决了,今天出差回来,用ie6登入另一个正在开发的系统,遇到了Png图片的问题,当然升级到ie8(ie8自带的开发人员工具调试前端页面JS之类的还是比较方便的,和FireBug一样,呵呵),这个问题就解决了,但稍微做了下这个问题的处理。
我们知道PNG是图像文件存储格式,查询资
- 表查询常用命令高级查询方法(二)
百合不是茶
oracle分页查询分组查询联合查询
----------------------------------------------------分组查询 group by having --平均工资和最高工资 select avg(sal)平均工资,max(sal) from emp ; --每个部门的平均工资和最高工资
- uploadify3.1版本参数使用详解
bijian1013
JavaScriptuploadify3.1
使用:
绑定的界面元素<input id='gallery'type='file'/>$("#gallery").uploadify({设置参数,参数如下});
设置的属性:
id: jQuery(this).attr('id'),//绑定的input的ID
langFile: 'http://ww
- 精通Oracle10编程SQL(17)使用ORACLE系统包
bijian1013
oracle数据库plsql
/*
*使用ORACLE系统包
*/
--1.DBMS_OUTPUT
--ENABLE:用于激活过程PUT,PUT_LINE,NEW_LINE,GET_LINE和GET_LINES的调用
--语法:DBMS_OUTPUT.enable(buffer_size in integer default 20000);
--DISABLE:用于禁止对过程PUT,PUT_LINE,NEW
- 【JVM一】JVM垃圾回收日志
bit1129
垃圾回收
将JVM垃圾回收的日志记录下来,对于分析垃圾回收的运行状态,进而调整内存分配(年轻代,老年代,永久代的内存分配)等是很有意义的。JVM与垃圾回收日志相关的参数包括:
-XX:+PrintGC
-XX:+PrintGCDetails
-XX:+PrintGCTimeStamps
-XX:+PrintGCDateStamps
-Xloggc
-XX:+PrintGC
通
- Toast使用
白糖_
toast
Android中的Toast是一种简易的消息提示框,toast提示框不能被用户点击,toast会根据用户设置的显示时间后自动消失。
创建Toast
两个方法创建Toast
makeText(Context context, int resId, int duration)
参数:context是toast显示在
- angular.identity
boyitech
AngularJSAngularJS API
angular.identiy 描述: 返回它第一参数的函数. 此函数多用于函数是编程. 使用方法: angular.identity(value); 参数详解: Param Type Details value
*
to be returned. 返回值: 传入的value 实例代码:
<!DOCTYPE HTML>
- java-两整数相除,求循环节
bylijinnan
java
import java.util.ArrayList;
import java.util.List;
public class CircleDigitsInDivision {
/**
* 题目:求循环节,若整除则返回NULL,否则返回char*指向循环节。先写思路。函数原型:char*get_circle_digits(unsigned k,unsigned j)
- Java 日期 周 年
Chen.H
javaC++cC#
/**
* java日期操作(月末、周末等的日期操作)
*
* @author
*
*/
public class DateUtil {
/** */
/**
* 取得某天相加(减)後的那一天
*
* @param date
* @param num
*
- [高考与专业]欢迎广大高中毕业生加入自动控制与计算机应用专业
comsci
计算机
不知道现在的高校还设置这个宽口径专业没有,自动控制与计算机应用专业,我就是这个专业毕业的,这个专业的课程非常多,既要学习自动控制方面的课程,也要学习计算机专业的课程,对数学也要求比较高.....如果有这个专业,欢迎大家报考...毕业出来之后,就业的途径非常广.....
以后
- 分层查询(Hierarchical Queries)
daizj
oracle递归查询层次查询
Hierarchical Queries
If a table contains hierarchical data, then you can select rows in a hierarchical order using the hierarchical query clause:
hierarchical_query_clause::=
start with condi
- 数据迁移
daysinsun
数据迁移
最近公司在重构一个医疗系统,原来的系统是两个.Net系统,现需要重构到java中。数据库分别为SQL Server和Mysql,现需要将数据库统一为Hana数据库,发现了几个问题,但最后通过努力都解决了。
1、原本通过Hana的数据迁移工具把数据是可以迁移过去的,在MySQl里面的字段为TEXT类型的到Hana里面就存储不了了,最后不得不更改为clob。
2、在数据插入的时候有些字段特别长
- C语言学习二进制的表示示例
dcj3sjt126com
cbasic
进制的表示示例
# include <stdio.h>
int main(void)
{
int i = 0x32C;
printf("i = %d\n", i);
/*
printf的用法
%d表示以十进制输出
%x或%X表示以十六进制的输出
%o表示以八进制输出
*/
return 0;
}
- NsTimer 和 UITableViewCell 之间的控制
dcj3sjt126com
ios
情况是这样的:
一个UITableView, 每个Cell的内容是我自定义的 viewA viewA上面有很多的动画, 我需要添加NSTimer来做动画, 由于TableView的复用机制, 我添加的动画会不断开启, 没有停止, 动画会执行越来越多.
解决办法:
在配置cell的时候开始动画, 然后在cell结束显示的时候停止动画
查找cell结束显示的代理
- MySql中case when then 的使用
fanxiaolong
casewhenthenend
select "主键", "项目编号", "项目名称","项目创建时间", "项目状态","部门名称","创建人"
union
(select
pp.id as "主键",
pp.project_number as &
- Ehcache(01)——简介、基本操作
234390216
cacheehcache简介CacheManagercrud
Ehcache简介
目录
1 CacheManager
1.1 构造方法构建
1.2 静态方法构建
2 Cache
2.1&
- 最容易懂的javascript闭包学习入门
jackyrong
JavaScript
http://www.ruanyifeng.com/blog/2009/08/learning_javascript_closures.html
闭包(closure)是Javascript语言的一个难点,也是它的特色,很多高级应用都要依靠闭包实现。
下面就是我的学习笔记,对于Javascript初学者应该是很有用的。
一、变量的作用域
要理解闭包,首先必须理解Javascript特殊
- 提升网站转化率的四步优化方案
php教程分享
数据结构PHP数据挖掘Google活动
网站开发完成后,我们在进行网站优化最关键的问题就是如何提高整体的转化率,这也是营销策略里最最重要的方面之一,并且也是网站综合运营实例的结果。文中分享了四大优化策略:调查、研究、优化、评估,这四大策略可以很好地帮助用户设计出高效的优化方案。
PHP开发的网站优化一个网站最关键和棘手的是,如何提高整体的转化率,这是任何营销策略里最重要的方面之一,而提升网站转化率是网站综合运营实力的结果。今天,我就分
- web开发里什么是HTML5的WebSocket?
naruto1990
Webhtml5浏览器socket
当前火起来的HTML5语言里面,很多学者们都还没有完全了解这语言的效果情况,我最喜欢的Web开发技术就是正迅速变得流行的 WebSocket API。WebSocket 提供了一个受欢迎的技术,以替代我们过去几年一直在用的Ajax技术。这个新的API提供了一个方法,从客户端使用简单的语法有效地推动消息到服务器。让我们看一看6个HTML5教程介绍里 的 WebSocket API:它可用于客户端、服
- Socket初步编程——简单实现群聊
Everyday都不同
socket网络编程初步认识
初次接触到socket网络编程,也参考了网络上众前辈的文章。尝试自己也写了一下,记录下过程吧:
服务端:(接收客户端消息并把它们打印出来)
public class SocketServer {
private List<Socket> socketList = new ArrayList<Socket>();
public s
- 面试:Hashtable与HashMap的区别(结合线程)
toknowme
昨天去了某钱公司面试,面试过程中被问道
Hashtable与HashMap的区别?当时就是回答了一点,Hashtable是线程安全的,HashMap是线程不安全的,说白了,就是Hashtable是的同步的,HashMap不是同步的,需要额外的处理一下。
今天就动手写了一个例子,直接看代码吧
package com.learn.lesson001;
import java
- MVC设计模式的总结
xp9802
设计模式mvc框架IOC
随着Web应用的商业逻辑包含逐渐复杂的公式分析计算、决策支持等,使客户机越
来越不堪重负,因此将系统的商业分离出来。单独形成一部分,这样三层结构产生了。
其中‘层’是逻辑上的划分。
三层体系结构是将整个系统划分为如图2.1所示的结构[3]
(1)表现层(Presentation layer):包含表示代码、用户交互GUI、数据验证。
该层用于向客户端用户提供GUI交互,它允许用户