MFS高可用配置
实验环境:
server6 172.25.0.122 mfsmaster
server7/8 172.25.0.123 / 172.25.0.124 chunkserver
server9 172.25.0.125 mfsmaster
client 172.25.0.16
实验前完善master端的yum源,并做好解析
[LoadBalancer]
name=LoadBalancer
baseurl=http://172.25.0.16/rhel6.5/LoadBalancer
gpgcheck=0
[HighAvailability]
name=HighAvailability
baseurl=http://172.25.0.16/rhel6.5/HighAvailability
gpgcheck=0
[ResilientStorage]
name=ResilientStorage
baseurl=http://172.25.0.16/rhel6.5/ResilientStorage
gpgcheck=0
[root@server6 ~]# vim /etc/hosts
172.25.0.122 server6 mfsmaster
172.25.0.123 server7 chunkserver
172.25.0.124 server8 chunkserver
172.25.0.125 server9 mfsmaster
~
1.master端安装高可用组件
[root@server9 3.0.97]# yum install crmsh-1.2.6-0.rc2.2.1.x86_64.rpm pssh-2.3.1-2.1.x86_64.rpm moosefs-master-
3.0.97-1.rhsysv.x86_64.rpm -y
[root@server9 3.0.97]# cd /etc/corosync/
[root@server9 corosync]# cp corosync.conf.example corosync.conf
[root@server9 corosync]# vim corosync.conf //编辑配置文件
10 bindnetaddr: 172.25.0.0
11 mcastaddr: 226.94.1.1
12 mcastport: 5405
35 service {
36 name: pacemasker
37 ver: 0
38 }
[root@server9 corosync]# /etc/init.d/corosync start
Starting Corosync Cluster Engine (corosync): [ OK ]
[root@server9 corosync]# scp corosync.conf server6:/etc/corosync/
[root@server6 corosync]# /etc/init.d/corosync start
Starting Corosync Cluster Engine (corosync): [ OK ]
2.在server6上查看监控
[root@server6 corosync]# crm_mon

3)server7上添加一块磁盘

[root@server7 ~]# fdisk -l
Disk /dev/vdb: 8589 MB, 8589934592 bytes
16 heads, 63 sectors/track, 16644 cylinders
Units = cylinders of 1008 * 512 = 516096 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0x00000000
[root@server7 ~]# yum install scsi-* -y
[root@server7 ~]# vim /etc/tgt/targets.conf
backing-store /dev/vdb
[root@server7 ~]# /etc/init.d/tgtd start
Starting SCSI target daemon: [ OK ]
4)master端安装iscsi
[root@server6 corosync]# yum install iscsi-* -y
[root@server9 corosync]# yum install iscsi-* -y
[root@server6 ~]# iscsiadm -m discovery -t st -p 172.25.0.123
Starting iscsid: [ OK ]
172.25.0.123:3260,1 iqn.2018-11.com.example:server.target1
[root@server9 corosync]# iscsiadm -m discovery -t st -p 172.25.0.123 //发现
Starting iscsid: [ OK ]
172.25.0.123:3260,1 iqn.2018-11.com.example:server.target1
[root@server6 ~]# iscsiadm -m node -l #登入共享存储组,fdisk -l会发现出现/dev/sda硬盘
Logging in to [iface: default, target: iqn.2018-11.com.example:server.target1, portal: 172.25.0.123,3260] (multiple)
Login to [iface: default, target: iqn.2018-11.com.example:server.target1, portal: 172.25.0.123,3260] successful.
[root@server9 corosync]# iscsiadm -m node -l
Logging in to [iface: default, target: iqn.2018-11.com.example:server.target1, portal: 172.25.0.123,3260] (multiple)
Login to [iface: default, target: iqn.2018-11.com.example:server.target1, portal: 172.25.0.123,3260] successful.
查看磁盘
[root@server9 corosync]# fdisk -l
Disk /dev/sda: 8589 MB, 8589934592 bytes
64 heads, 32 sectors/track, 8192 cylinders
Units = cylinders of 2048 * 512 = 1048576 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0x00000000
5)server6磁盘分区
[root@server6 ~]# fdisk -cu /dev/sda
Device Boot Start End Blocks Id System
/dev/sda1 2048 16777215 8387584 83 Linux
格式化分区
[root@server6 ~]# mkfs.ext4 /dev/sda1
mke2fs 1.41.12 (17-May-2010)
Filesystem label=
OS type: Linux
Block size=4096 (log=2)
Fragment size=4096 (log=2)
Stride=0 blocks, Stripe width=0 blocks
524288 inodes, 2096896 blocks
104844 blocks (5.00%) reserved for the super user
First data block=0
Maximum filesystem blocks=2147483648
64 block groups
32768 blocks per group, 32768 fragments per group
8192 inodes per group
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632
Writing inode tables: done
Creating journal (32768 blocks): done
Writing superblocks and filesystem accounting information: done
This filesystem will be automatically checked every 33 mounts or
180 days, whichever comes first. Use tune2fs -c or -i to override.
6)在server6上:配置挂载共享目录,在server9查看共享目录
[root@server6 ~]# cd /var/lib/mfs/
[root@server6 mfs]# mount /dev/sda1 /mnt/
[root@server6 mfs]# ls
changelog.3.mfs changelog.5.mfs metadata.mfs.back.1 stats.mfs
changelog.4.mfs metadata.mfs.back metadata.mfs.empty
[root@server6 mfs]# cp -p * /mnt/ //将原来mfs中的changelog全部同步出来。
[root@server6 mfs]# cd /mnt/
[root@server6 mnt]# ls
changelog.3.mfs changelog.5.mfs metadata.mfs.back metadata.mfs.empty
changelog.4.mfs lost+found metadata.mfs.back.1 stats.mfs
[root@server6 /]# umount /mnt/
[root@server6 ~]# chmod mfs.mfs /var/lib/mfs/
[root@server6 /]# ll -d /var/lib/mfs/
drwxr-xr-x 2 mfs mfs 4096 Nov 15 23:00 /var/lib/mfs/
[root@server6 /]# mount /dev/sda1 /var/lib/mfs/
[root@server6 /]# df
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/mapper/VolGroup-lv_root 19134332 1307408 16854944 8% /
tmpfs 510200 37188 473012 8% /dev/shm
/dev/vda1 495844 33475 436769 8% /boot
/dev/sda1 8255928 153104 7683448 2% /var/lib/mfs
server9上查看
[root@server9 corosync]# fdisk -l
Device Boot Start End Blocks Id System
/dev/sda1 2 8192 8387584 83 Linux
自动恢复moosefs-master异常
[root@server9 mfs]# vim /etc/init.d/moosefs-master
31 $prog start >/dev/null 2>&1 && $prog -a >/dev/null 2>&1 && success || failure
7)添加策略
[root@server6 ~]# /etc/init.d/moosefs-master stop
[root@server6 ~]# crm
crm(live)# configure
show crm(live)configure# show
node server6
node server9
property $id="cib-bootstrap-options" \
dc-version="1.1.10-14.el6-368c726" \
cluster-infrastructure="classic openais (with plugin)" \
expected-quorum-votes="2"
crm(live)configure# pr
primitive property
crm(live)configure# property no-quorum-policy=ignore
crm(live)configure# commit
crm(live)configure# property stonith-enabled=true
crm(live)configure# commit
crm(live)configure# bye
bye
添加fence机制,server6/9建立目录
[root@server6 ~]# yum install fence-virt -y
[root@server6 ~]# stonith_admin -I
fence_xvm
fence_virt
fence_pcmk
fence_legacy
4 devices found
[root@server6 ~]# mkdir /etc/cluster
[root@foundation78 mfs]# systemctl start fence_virtd.service
[root@foundation78 cluster]# scp fence_xvm.key server6:/etc/cluster/
root@server6's password:
fence_xvm.key 100% 128 0.1KB/s 00:00
[root@foundation78 cluster]# scp fence_xvm.key server9:/etc/cluster/
root@server9's password:
fence_xvm.key 100% 128 0.1KB/s 00:00
继续添加
root@server1 corosync]# crm
crm(live)# configure
crm(live)configure#primitive vmfence stonith:fence_xvm params pcmk_host_map="sever6:server6;server9:server9" op monitor interval=1min
crm(live)configure# primitive vip ocf:heartbeat:IPaddr2 params ip=172.25.0.120 op monitor interval=30s #配置vip信息。
crm(live)configure# commit
crm(live)configure# primitive mfsdata ocf:heartbeat:Filesystem params device=/dev/sda1 directory=/var/lib/mfs fstype=ext4 op monitor interval=1min #配置存储信息
crm(live)configure# primitive mfsmaster lsb:moosefs-master op monitor interval=30s #配置服务信息
crm(live)configure# group mfsgroup vip mfsdata mfsmaster #将其加进一个组内
crm(live)configure# commit
查看监控
Online: [ server6 server9 ]
vmfence (stonith:fence_xvm): Started server6
Resource Group: mfsgroup
vip (ocf::heartbeat:IPaddr2): Started server6
mfsdata (ocf::heartbeat:Filesystem): Started server6
mfsmaster (lsb:moosefs-master): Started server6
添加解析,集群内所有主机,包括客户机,注意去除原先的解析,这个解析文件会从上往下依次读取
[root@foundation78 cluster]# vim /etc/hosts
172.25.0.120 mfsmaster
[root@server6 ~]# vim /etc/hosts
172.25.0.120 mfsmaster
打开chunkserver
[root@server7 ~]# /etc/init.d/moosefs-chunkserver start
[root@server8 ~]# /etc/init.d/moosefs-chunkserver start
此时vip在server6
[root@server6 ~]# ip addr
2: eth0: mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 52:54:00:b3:78:44 brd ff:ff:ff:ff:ff:ff
inet 172.25.0.122/24 brd 172.25.0.255 scope global eth0
inet 172.25.0.120/32 brd 172.25.0.255 scope global eth0
inet6 fe80::5054:ff:feb3:7844/64 scope link
valid_lft forever preferred_lft forever
关闭server6
Online: [ server9 ]
OFFLINE: [ server6 ]
vmfence (stonith:fence_xvm): Started server9
Resource Group: mfsgroup
vip (ocf::heartbeat:IPaddr2): Started server9
mfsdata (ocf::heartbeat:Filesystem): Started server9
mfsmaster (lsb:moosefs-master): Started server9
写入数据时,将master关闭查看数据是否还能正常写入
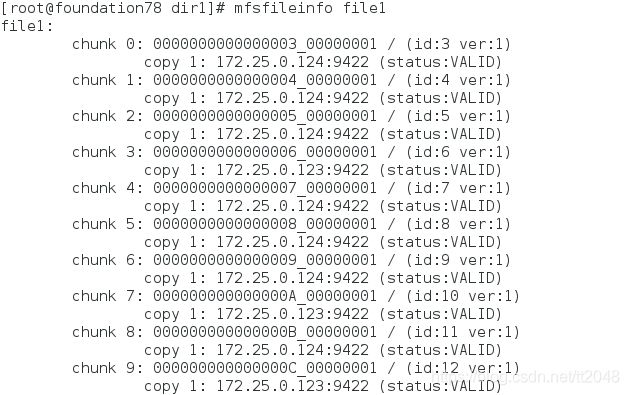
[root@foundation78 ~]# cd /mnt/mfs/dir1
[root@foundation78 dir1]# dd if=/dev/zero of=file1 bs=1M count=2000
Reconnecting...[root@server9 ~]# crm
crm(live)# node standby