Facebook AI开源在线语音识别的推理框架...#20200114
写在前面
本系列文章分享笔者每天学习的一些圈内前沿有趣事件和开源工作,分享转需。
公众号AISphere。
目录简介
- 1.Facebook AI开源在线语音识别的推理框架-wav2letter
- 2.Google AI 机器学习降水预测
- 3.Hugging Face 开源超高性能tokenizers库
- 4.斯坦福Percy Liang教授在Pinterest实验室发表了关于“语言学习”的演讲
- 5.Jeremy Howard: Self-supervised learning and Computer Vision概述
- 6.Jeremy Howard: 用13行代码做深度学习图像分类
- 7.AllenNLP文档有更新
一、Facebook AI开源在线语音识别的推理框架-wav2letter
从输入音频流实时转录语音的过程称为在线语音识别。大多数自动语音识别(ASR)研究都集中在提高准确性上,而没有实时执行任务的限制。但是,对于诸如实时视频字幕或设备上的转录之类的应用,重要的是减少音频和相应转录之间的等待时间。在这些情况下,需要具有有限时间延迟的在线语音识别,以提供良好的用户体验。为了满足这一需求,Facebook开发了wav2letter @ anywhere 并将其开源,该框架可用于执行在线语音识别。Wav2letter @ anywhere建立在Facebook AI的wav2letter先前版本和wav2letter ++。
开源地址:https://ai.facebook.com/blog/online-speech-recognition-with-wav2letteranywhere/
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Cyyp7zh0-1579064364296)(https://aigroupz-1258285787.cos.ap-shanghai.myqcloud.com/2020/01/14/824488285622396243292654861818999576461312n.gif)]
LeCun对此评价:
Wav2Letter@anywhere: speech recognition engine with transformer-based acoustic model.
SOTA on LibriSpeech.
Fast inference.
Now open source.
二、Google AI 机器学习降水预测
Google AI在2020年1月14日的@ametsoc会议上,介绍了降水临近预报的研究,该研究使用“无物理” 模型,以1 km的分辨率和仅5-10分钟的滞后时间集中于0-6小时的预报。
读者可以在https://goo.gle/35SAEdk 了解所有相关信息。
JeffDean对此评价:使用机器学习解决各种天气和气候问题的潜力很大。这是一个示例,它以比传统的基于物理的模型更精细的空间粒度来预测降水。
三、Hugging Face 开源超高性能tokenizers库
Hugging Face新增Tokenizers功能: ultra-fast, extensible tokenization for state-of-the-art NLP
地址:https://github.com/huggingface/tokenizers
Zhao Yikai对此评价:这对我来说是改变游戏规则的人。每位NLP研究人员或从业人员都了解基于不同的现代NLP架构,以不同方式对文本进行分词和处理的痛苦。Huggingface现在提供了简化的过程,以将分词器和处理器与其惊人的模型集成在一起!
Delip Rao对此评价:如果分词和BERT的fine-tuning一样得到标准化(standardized),NLP中令人头疼的90%bugs和可复现问题能得到解决。

主要特点
- 使用当今最常用的分词器训练新词汇并标记化。
- 得益于Rust的实现,速度非常快(训练和令牌化)。只需不到20秒即可在服务器CPU上标记GB的文本。
- 易于使用,但也非常灵活。
- 专为研究和生产而设计。
- 归一化带有对齐跟踪。总是有可能获得与给定标记相对应的原始句子部分。
- 执行所有预处理:截断,填充,添加模型所需的特殊标记。
python快速上手例子
# Tokenizers provides ultra-fast implementations of most current tokenizers:
>>> from tokenizers import (ByteLevelBPETokenizer,
BPETokenizer,
SentencePieceBPETokenizer,
BertWordPieceTokenizer)
# Ultra-fast => they can encode 1GB of text in ~20sec on a standard server's CPU
# Tokenizers can be easily instantiated from standard files
>>> tokenizer = BertWordPieceTokenizer("bert-base-uncased-vocab.txt", lowercase=True)
Tokenizer(vocabulary_size=30522, model=BertWordPiece, add_special_tokens=True, unk_token=[UNK],
sep_token=[SEP], cls_token=[CLS], clean_text=True, handle_chinese_chars=True,
strip_accents=True, lowercase=True, wordpieces_prefix=##)
# Tokenizers provide exhaustive outputs: tokens, mapping to original string, attention/special token masks.
# They also handle model's max input lengths as well as padding (to directly encode in padded batches)
>>> output = tokenizer.encode("Hello, y'all! How are you ?")
Encoding(num_tokens=13, attributes=[ids, type_ids, tokens, offsets, attention_mask, special_tokens_mask, overflowing, original_str, normalized_str])
>>> print(output.ids, output.tokens, output.offsets)
[101, 7592, 1010, 1061, 1005, 2035, 999, 2129, 2024, 2017, 100, 1029, 102]
['[CLS]', 'hello', ',', 'y', "'", 'all', '!', 'how', 'are', 'you', '[UNK]', '?', '[SEP]']
[(0, 0), (0, 5), (5, 6), (7, 8), (8, 9), (9, 12), (12, 13), (14, 17), (18, 21), (22, 25), (26, 27),
(28, 29), (0, 0)]
# Here is an example using the offsets mapping to retrieve the string coresponding to the 10th token:
>>> output.original_str[output.offsets[10]]
''
训练一个新的vocabulary也很easy:
# You can also train a BPE/Byte-levelBPE/WordPiece vocabulary on your own files
>>> tokenizer = ByteLevelBPETokenizer()
>>> tokenizer.train(["wiki.test.raw"], vocab_size=20000)
[00:00:00] Tokenize words ████████████████████████████████████████ 20993/20993
[00:00:00] Count pairs ████████████████████████████████████████ 20993/20993
[00:00:03] Compute merges ████████████████████████████████████████ 19375/19375
四、斯坦福Percy Liang教授在Pinterest实验室发表了关于“语言学习”的演讲
talk地址:https://ibm.co/2shu3eG

五、Jeremy Howard: Self-supervised learning and Computer Vision概述
Jeremy Howard在 @AiWamri的医学成像工作,经常需要使用少量数据却对结果大有帮助。一种对此缺乏重视的方法是自监督学习。他觉得简直太神奇了!并且写了一些概述来帮助读者入门。他认为LeCun创造了Self-supervised learning这个词并且很喜欢。
https://www.fast.ai/2020/01/13/self_supervised/
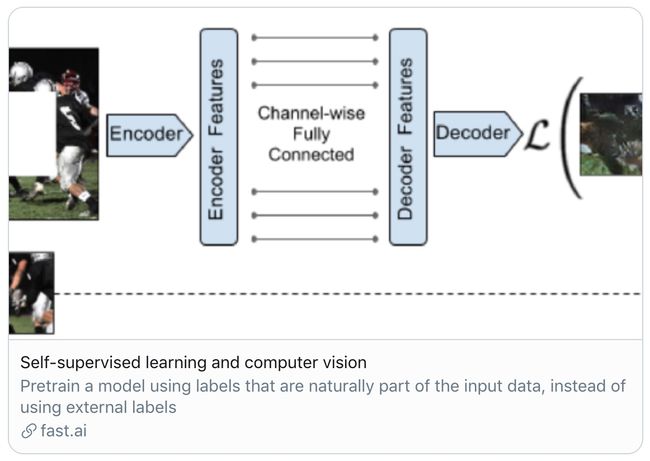
LeCun对此评价:如今学习visual features的最佳SSL方法是使用Siamese networks去学习embeddings,比如最近两篇FAIR的论文:“Pretext-Invariant Representation Learning” (Misra et al.) and “MoCo” (He et al.).
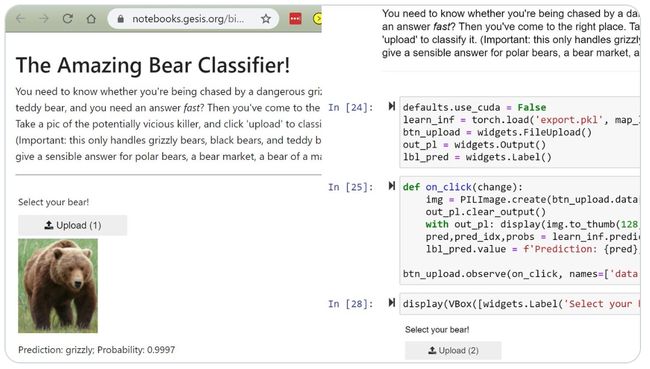
六、Jeremy Howard: 用13行代码做深度学习图像分类
这个真正有效的深度学习图像分类器在mybinder免费运行,完全基于Jupyter编写,并与Voila一起部署。:13行代码:)
读者可以在这里试试吧
https://t.co/kII6K42eZv?amp=1
七、AllenNLP文档有些更新
文档地址:allenai.github.io/allennlp-docs/
Mark Neumann对此评价:这些基于@tiangolo令人难以置信的FastAPI文档,另外还有直接从allennlp的来源自动生成的API部分。内置@squidfunk的很棒的mkdocs-material模板。会推荐!
结语
本系列文章按时更新AI圈一些有趣的事件和开源工作,关注防迷路。
另外我们准备组建NLP沟通交流群,有兴趣的伙伴可以联系echoooo741进群。