卷积变分自动编码器
This notebook demonstrates how to generate images of handwritten digits by training a Variational Autoencoder (1, 2).
# to generate gifs
!pip install imageio
- Import TensorFlow and other libraries
from __future__ import absolute_import, division, print_function
!pip install tensorflow-gpu==2.0.0-alpha0
import tensorflow as tf
import os
import time
import numpy as np
import glob
import matplotlib.pyplot as plt
import PIL
import imageio
from IPython import display
- Load the MNIST dataset
每个MNIST图像最初是784个整数的矢量,每个整数在0-255之间并且表示像素的强度。 我们在模型中使用伯努利分布对每个像素进行建模,并对数据集进行静态二值化。
(train_images, _), (test_images, _) = tf.keras.datasets.mnist.load_data()
train_images = train_images.reshape(train_images.shape[0], 28, 28, 1).astype('float32')
test_images = test_images.reshape(test_images.shape[0], 28, 28, 1).astype('float32')
# Normalizing the images to the range of [0., 1.]
train_images /= 255.
test_images /= 255.
# Binarization
train_images[train_images >= .5] = 1.
train_images[train_images < .5] = 0.
test_images[test_images >= .5] = 1.
test_images[test_images < .5] = 0.
TRAIN_BUF = 60000
BATCH_SIZE = 100
TEST_BUF = 10000
- Use tf.data to create batches and shuffle the dataset
train_dataset = tf.data.Dataset.from_tensor_slices(train_images).shuffle(TRAIN_BUF).batch(BATCH_SIZE)
test_dataset = tf.data.Dataset.from_tensor_slices(test_images).shuffle(TEST_BUF).batch(BATCH_SIZE)
- 用tf.keras.Sequential连接生成和推理网络
在我们的VAE示例中,我们使用两个小型ConvNets用于生成和推理网络。 由于这些神经网络很小,我们使用tf.keras.Sequential来简化我们的代码。 在下面的描述中,分别用x和z表示观察和潜在变量。 - Generative Network
这定义了采用潜在编码作为输入的生成模型,并输出观察的条件分布的参数,即p(x | z)。 另外,我们使用单位高斯先验p(z)作为潜在变量。 - Inference Network
这定义了近似后验分布q(z | x),其将观察值作为输入并输出用于潜在表示的条件分布的一组参数。 在这个例子中,我们简单地将这个分布建模为对角高斯分布。 在这种情况下,推理网络输出分解高斯的均值和对数方差参数(对数方差而不是方差直接用于数值稳定性)。 - Reparameterization Trick
在优化过程中,我们可以从q(z | x)中采样,首先从单位高斯采样,然后乘以标准差并加上均值。 这确保了梯度可以通过样本传递到推理网络参数。 - Network architecture
对于推理网络,我们使用两个卷积层,然后是完全连接的层。 在生成网络中,我们通过使用完全连接的层,然后是三个卷积转置层(在某些情况下是反卷积层)来镜像这种架构。 注意,通常的做法是在训练VAE时避免使用批量标准化,因为使用小批量产生的额外随机性可能会加重采样随机性之上的不稳定性。
class CVAE(tf.keras.Model):
def __init__(self, latent_dim):
super(CVAE, self).__init__()
self.latent_dim = latent_dim
self.inference_net = tf.keras.Sequential(
[
tf.keras.layers.InputLayer(input_shape=(28, 28, 1)),
tf.keras.layers.Conv2D(
filters=32, kernel_size=3, strides=(2, 2), activation='relu'),
tf.keras.layers.Conv2D(
filters=64, kernel_size=3, strides=(2, 2), activation='relu'),
tf.keras.layers.Flatten(),
# No activation
tf.keras.layers.Dense(latent_dim + latent_dim),
]
)
self.generative_net = tf.keras.Sequential(
[
tf.keras.layers.InputLayer(input_shape=(latent_dim,)),
tf.keras.layers.Dense(units=7*7*32, activation=tf.nn.relu),
tf.keras.layers.Reshape(target_shape=(7, 7, 32)),
tf.keras.layers.Conv2DTranspose(
filters=64,
kernel_size=3,
strides=(2, 2),
padding="SAME",
activation='relu'),
tf.keras.layers.Conv2DTranspose(
filters=32,
kernel_size=3,
strides=(2, 2),
padding="SAME",
activation='relu'),
# No activation
tf.keras.layers.Conv2DTranspose(
filters=1, kernel_size=3, strides=(1, 1), padding="SAME"),
]
)
def sample(self, eps=None):
if eps is None:
eps = tf.random.normal(shape=(100, self.latent_dim))
return self.decode(eps, apply_sigmoid=True)
def encode(self, x):
mean, logvar = tf.split(self.inference_net(x), num_or_size_splits=2, axis=1)
return mean, logvar
def reparameterize(self, mean, logvar):
eps = tf.random.normal(shape=mean.shape)
return eps * tf.exp(logvar * .5) + mean
def decode(self, z, apply_sigmoid=False):
logits = self.generative_net(z)
if apply_sigmoid:
probs = tf.sigmoid(logits)
return probs
return logits
- Define the loss function and the optimizer
VAE通过最大化边际对数似然下的证据下界(ELBO)进行训练:

在实践中,我们优化了单个样本蒙特卡罗对此期望的估计:
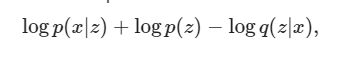
其中z从q(z | x)中采样。
注意:我们也可以分析计算KL项,但为了简单起见,我们在蒙特卡罗估计中将所有三个项合并。
def log_normal_pdf(sample, mean, logvar, raxis=1):
log2pi = tf.math.log(2. * np.pi)
return tf.reduce_sum(
-.5 * ((sample - mean) ** 2. * tf.exp(-logvar) + logvar + log2pi),
axis=raxis)
def compute_loss(model, x):
mean, logvar = model.encode(x)
z = model.reparameterize(mean, logvar)
x_logit = model.decode(z)
cross_ent = tf.nn.sigmoid_cross_entropy_with_logits(logits=x_logit, labels=x)
logpx_z = -tf.reduce_sum(cross_ent, axis=[1, 2, 3])
logpz = log_normal_pdf(z, 0., 0.)
logqz_x = log_normal_pdf(z, mean, logvar)
return -tf.reduce_mean(logpx_z + logpz - logqz_x)
def compute_gradients(model, x):
with tf.GradientTape() as tape:
loss = compute_loss(model, x)
return tape.gradient(loss, model.trainable_variables), loss
def apply_gradients(optimizer, gradients, variables):
optimizer.apply_gradients(zip(gradients, variables))
optimizer = tf.keras.optimizers.Adam(1e-4)
- Training
我们首先迭代数据集
在每次迭代期间,我们将图像传递给编码器以获得近似后验q(z | x)的一组均值和对数方差参数。
然后我们将重新参数化技巧应用于q(z | x)的样本
最后,我们将重新参数化的样本传递给解码器,以获得生成分布p(x | z)的logits
注意:由于我们使用训练集中60k数据点和测试集中10k数据点的keras加载的数据集,因此我们在测试集上得到的ELBO略高于使用Larochelle的MNIST动态二值化的文献中的报告结果。 - Generate Images
训练结束后,是时候生成一些图像了
我们首先从单位高斯先验分布p(z)中采样一组潜在向量
然后,生成器将潜在样本z转换为观察的logits,给出分布p(x | z)
在这里我们绘制伯努利分布的概率
epochs = 100
latent_dim = 50
num_examples_to_generate = 16
# keeping the random vector constant for generation (prediction) so
# it will be easier to see the improvement.
random_vector_for_generation = tf.random.normal(
shape=[num_examples_to_generate, latent_dim])
model = CVAE(latent_dim)
def generate_and_save_images(model, epoch, test_input):
predictions = model.sample(test_input)
fig = plt.figure(figsize=(4,4))
for i in range(predictions.shape[0]):
plt.subplot(4, 4, i+1)
plt.imshow(predictions[i, :, :, 0], cmap='gray')
plt.axis('off')
# tight_layout minimizes the overlap between 2 sub-plots
plt.savefig('image_at_epoch_{:04d}.png'.format(epoch))
plt.show()
generate_and_save_images(model, 0, random_vector_for_generation)
for epoch in range(1, epochs + 1):
start_time = time.time()
for train_x in train_dataset:
gradients, loss = compute_gradients(model, train_x)
apply_gradients(optimizer, gradients, model.trainable_variables)
end_time = time.time()
if epoch % 1 == 0:
loss = tf.keras.metrics.Mean()
for test_x in test_dataset:
loss(compute_loss(model, test_x))
elbo = -loss.result()
display.clear_output(wait=False)
print('Epoch: {}, Test set ELBO: {}, '
'time elapse for current epoch {}'.format(epoch,
elbo,
end_time - start_time))
generate_and_save_images(
model, epoch, random_vector_for_generation)
- Display an image using the epoch number
def display_image(epoch_no):
return PIL.Image.open('image_at_epoch_{:04d}.png'.format(epoch_no))
plt.imshow(display_image(epochs))
plt.axis('off')# Display images
- Generate a GIF of all the saved images.
with imageio.get_writer('cvae.gif', mode='I') as writer:
filenames = glob.glob('image*.png')
filenames = sorted(filenames)
last = -1
for i,filename in enumerate(filenames):
frame = 2*(i**0.5)
if round(frame) > round(last):
last = frame
else:
continue
image = imageio.imread(filename)
writer.append_data(image)
image = imageio.imread(filename)
writer.append_data(image)
# this is a hack to display the gif inside the notebook
os.system('cp cvae.gif cvae.gif.png')
display.Image(filename="cvae.gif.png")