Hadoop3.2.1 【 HDFS 】源码分析 : INode相关类/接口 解析
Table of Contents
一.前言
二.INode相关类/接口
2.1.字段属性:
2.2.构造方法
2.3.1. INode元信息方法
2.4.INode类实现了INodeAttributes接口,清单如下:
2.5.抽象类INodeWithAdditionalFields
2.6.INodeDirectory类
2.7.INodeFile类
2.6.INodeReference类
一.前言
Namenode最重要的两个功能之一就是维护文件系统的命名空间(namesystem) 。
HDFS文件系统的命名空间在Namenode的内存中是以一颗树的结构来存储的。 HDFS文件系统的命名空间(namespace) 是以“/”为根的整个目录树, 是通过FSDirectory类来管理的.在HDFS中, 不管是目录还是文件, 在文件系统目录树中都被看作是一个INode节点。 如果是目录, 则其对应的类为INodeDirectory;如果是文件,则其对应的类为INodeFile。INodeDirectory以及INodeFile类都是INode的派生类。 INodeDirectory中包含一个成员集合变量children , 如果该目录下有子目录或者文件, 其子目录或文件的INode引用就会被保存在children集合中。 HDFS就是通过这种方式来维护整个文件系统的目录结构的.
HDFS会将命名空间保存到Namenode的本地文件系统上一个叫fsimage(命名空间镜像) 的文件中。 利用这个文件, Namenode每次重启时都能将整个HDFS的命名空间重构,fsimage文件的操作由FSImage类负责。 另外, 对HDFS的各种操作, Namenode都会在操作日志(editlog) 中进行记录, 以便周期性地将该日志与fsimage进行合并生成新的fsimage。 该日志文件也在Namenode的本地文件系统中保存, 叫editlog文件, editlog的相关操作由FSEditLog类管理.
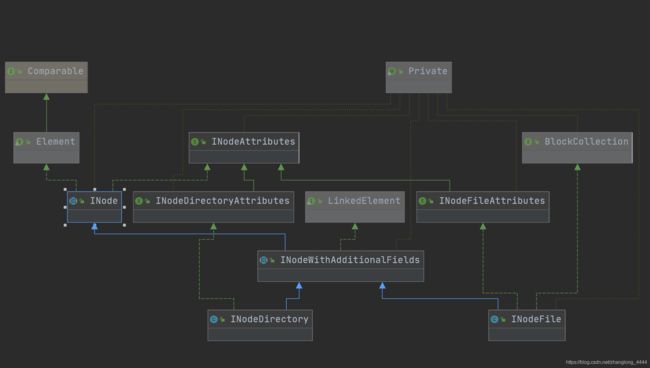
根据上图,我们可以看到INodeDirectory和INodeFiled都是抽象类INodeWithAdditionalFields的实现类.而 INodeWithAdditionalFields的父类为 INode, 所以接下来,我们就从INode抽象类开始说起.
二.INode相关类/接口
INode类是整个INode体系的根接口, 它是一个抽象类, 保存了HDFS目录和文件的所有共同属性, 包括当前节点的父节点的INode对象的引用(只能是INodeDirectory类或者INodeReference类) 、 文件/ 目录名、 用户组、 访问权限、 最后修改时间、 上次访问时间、 完整路径名、 文件扩展属性等

2.1.字段属性:
INode类中只有一个字段, 就是parent, 表明当前INode的父目录。 HDFS中除了根目录外, 其他所有的文件与目录都存在一个父目录。 注意, 父目录的类型只能是INodeDirectory类或者INodeReference类之一。
private INode parent = null;2.2.构造方法
INode构造方法只有一个参数就是传入INode类型的对象, 类型只能是INodeDirectory类或者INodeReference类之一。
INode(INode parent) {
this.parent = parent;
}2.3.1. INode元信息方法
■ id: INode的id。
■ fullPathName: 文件/ 目录的完整路径。
■ parent: 文件/ 目录的父节点。INode还提供了如下几个基本的判断方法。
■ isFile(): 判断是否为文件。
■ isDirectory(): 判断是否为目录。
■ isSymlink(): 判断是否为符号链接。
■ isRoot(): 判断是否为文件系统目录树的根节点。
2.4.INode类实现了INodeAttributes接口,清单如下:
| 序号 | 方法名 |
返回类型 |
描述 |
|---|---|---|---|
| 1 |
isDirectory |
boolean |
是否是目录 |
| 2 |
getLocalNameBytes |
byte[] |
返回用户名(byte [] 类型) |
| 3 |
getUserName |
String |
文件/目录所属用户名。 |
| 4 |
getGroupName |
String |
文件/目录所属组名。 |
| 5 |
getFsPermission |
FsPermission |
返回权限 (FsPermission 类型) |
| 6 |
getFsPermissionShort |
short |
返回权限(short 类型) |
| 7 |
getPermissionLong |
long |
返回权限(long 类型) |
| 8 |
getAclFeature |
AclFeature |
安全相关。 |
| 9 |
getXAttrFeature |
XAttrFeature |
当前文件/目录的扩展属性(ExtendedAttributes)。 文件系统扩展属性是目前流行的POSIX系统中文件系统具有的一项特殊功能, 可以给文件、 文件夹添加额外的key/value键值对, 键和值都是字符串并且有一定长度的限制。 文件系统扩展属性使得现有的文件系统得以支持在原始设计中未提供的功能。 |
| 10 |
getModificationTime |
getModificationTime |
文件/目录上次修改时间。 |
| 11 |
getAccessTime |
getAccessTime |
文件/目录上次访问时间。 |
2.5.抽象类INodeWithAdditionalFields
INode这个根接口类,但是INode类只定义了一个字段parent,其余字段的值都是通过抽象的get()方法获得的,并且留给了子类来定义。
如下图,INodeWithAdditionalFields里面定义了具体的属性字段,比如: id、 name、 permission、modificationTime、 accessTime等.

permission字段是long类型的, 其中前16个比特用来存放文件权限标识(mode, 类似于Linux中的777) , 中间24个比特用来存放用户组标识(group) , 最后24个比特用来存放用户名标识(user) 。
在HDFS中, 用户名和用户标识的对应关系、 用户组名和用户组标识的对应关系都保存在SerialNumberManager类中。 通过SerialNumberManager类, 名字节点不必在INode对象中保存字符串形式的用户名和用户组名, 只需将整型的用户名标识和用户组名标识放入permission字段中即可。
enum PermissionStatusFormat implements LongBitFormat.Enum {
MODE(null, 16),
GROUP(MODE.BITS, 24),
USER(GROUP.BITS, 24);
final LongBitFormat BITS;
private PermissionStatusFormat(LongBitFormat previous, int length) {
BITS = new LongBitFormat(name(), previous, length, 0);
}
//提取最后24个比特的user信息,并通过SerialNumberManager获取用户名
static String getUser(long permission) {
//代码略....
}
//提取中间24个比特的group信息,并通过SerialNumberManager获取用户组名
static String getGroup(long permission) {
//代码略....
}
//提取前16个比特的mode信息
static short getMode(long permission) {
//代码略....
}
/**
* 将一个PermissionStatus类,转换成long类型的permission信息
*
* Encode the {@link PermissionStatus} to a long. */
static long toLong(PermissionStatus ps) {
//代码略....
}
static PermissionStatus toPermissionStatus(long id,
SerialNumberManager.StringTable stringTable) {
//代码略....
}
@Override
public int getLength() {
return BITS.getLength();
}
}
2.6.INodeDirectory类
INodeDirectory抽象了HDFS文件系统中的目录, 目录是文件系统中的一个虚拟容器,里面保存了一组文件和其他一些目录。 在INodeDirectory的实现中, 添加了成员变量children, 用来保存目录中所有子目录项的INode对象
//使用一个children字段保存该目录中所有孩子节点的INode对象 : ArrayList实例
private List children = null;
■children字段的增、 删、 改、 查方法: 用于向当前目录添加、 删除、 替换、 查找子目录项等操作, 包括addChild()、 removeChild()、 replaceChild()、 getChild()、clearChildren()、 cleanSubtreeRecursively()等方法。
■ 特性(Feature) 相关方法: 用于向当前INodeDirectory添加新的Feature对象, 以及获取指定Feature对象的方法, 包括addDirectoryWithQuotaFeature()、getDirectoryWith QuotaFeature()、 addSnapshottableFeature()、
addSnapshotFeature()、getDirectorySnapshottableFeature()、getDirectoryWithSnapshotFeature()等方法。
■ 快照(Snapshot) 相关方法: 用于向当前目录添加、 删除或者更改快照等操作,包括isSnapshottable()、 getSnapshot()、 setSnapshotQuota()、 addSnapshot()、removeSnapshot()等方法。
2.7.INodeFile类
在文件系统目录树中, 使用INodeFile类抽象一个HDFS文件, INodeFile类继承自INodeWithAdditionalFields类.
INodeFile类中保存了HDFS文件最重要的两个信息: 文件头header字段和文件对应的数据块信息blocks字段。 header字段保存了当前文件有多少个副本, 以及文件数据块的大小(header字段的处理类似于INode中的permission字段, 前4个比特用于保存存储策略,中间12个比特用于保存文件备份系数[ 1 + 11 (最高的1位来确定该块是副本还是擦除编码, 0 副本, 1擦除编码 . 对于复制块,尾11位存储复制因子。 对于擦除编码块,尾11位存储EC策略ID ) ], 后48个比特用于保存数据块大小。 使用内部类HeaderFormat处理) ; blocks字段是一个BlockInfo类型的数组, 保存了当前文件对应的所有数据块信息。
//文件头信息
// header字段保存了当前文件有多少个副本,
// 以及文件数据块的大小
// (header字段的处理类似于INode中的permission字段,
// 前4个比特用于保存存储策略,
// 中间12个比特用于保存文件备份系数,
// 后48个比特用于保存数据块大小。
// 使用内部类HeaderFormat处理);
private long header = 0L;
//文件数据块信息
//文件对应的 数据块信息blocks字段
private BlockInfo[] blocks;构造方法
INodeFile(long id, byte[] name, PermissionStatus permissions, long mtime,
long atime, BlockInfo[] blklist, Short replication, Byte ecPolicyID,
long preferredBlockSize, byte storagePolicyID, BlockType blockType) {
super(id, name, permissions, mtime, atime);
final long layoutRedundancy = HeaderFormat.getBlockLayoutRedundancy(
blockType, replication, ecPolicyID);
// 构建头信息
header = HeaderFormat.toLong(preferredBlockSize, layoutRedundancy,
storagePolicyID);
// 设置blocks信息
if (blklist != null && blklist.length > 0) {
for (BlockInfo b : blklist) {
Preconditions.checkArgument(b.getBlockType() == blockType);
}
}
setBlocks(blklist);
}
2.6.INodeReference类
INodeReference是一个抽象类, 继承INode抽象类. 当HDFS文件/ 目录处于某个快照中, 并且这个文件/ 目录被重命名或者移动到其他路径时, 该文件/ 目录就会存在多条访问路径。WithName、 WithCount、 DstReference都是INodeReference的子类, 同时也是INodeReference的内部类。 WithName对象用于替代重命名操作前源路径中的INode对象, DstReference对象则用于替代重命名操作后目标路径中的INode对象。WithName和DstReference同指向了一个WithCount对象, WithCount对象则指向了文件系统目录树中真正的INode对象.
在INodeReference抽象类上有一段声明,翻一下:
此类及其子类用于支持多个访问路径。
当文件/目录存储在某些快照中并重命名/移动到其他位置时,它可能具有多个访问路径。
(1)假设我们有/abc/foo,假设foo的inode是inode(id=1000,name=foo)
(2)为/abc创建快照s0
(3)mv/abc/foo/xyz/bar,即inode(id=1000,name=…)将“foo”重命名到“bar”,它的父对象变成/xyz。
然后,/xyz/bar和/abc/.snapshot/s0/foo是指向同一inode,inode(id=1000,name=bar)的两条不同的访问路径。
关于references[引用],我们可以得到以下信息:
1. /abc 有一个子引用 (id : 1001,name: foo)
2. /xyz 有一个子引用 (id : 1002)
3. 引用(id : 1001,name: foo) 和引用(id : 1002) 指向同一个引用 (id:1003, count: 2)
4. 最后(id:1003, count: 2) 执行inode (id:1000,name: bar)
注意:
1. 对于没有名称的引用,例如ref(id=1002),它使用被引用inode的名称。
2. getParent()总是返回当前状态的父对象,例如 : inode(id:1000,name:bar.getParent()返回/xyz而不是/abc。

感谢 :
Hadoop 2.X HDFS源码剖析-徐鹏
深度剖析Hadoop HDFS -林意群