论文分享--A Strong Baseline for Re-ID
https://zhuanlan.zhihu.com/p/65631409
https://zhuanlan.zhihu.com/p/61831669
分享最近读到的一篇论文Bag of Tricks and A Strong Baseline for Deep Person Re-identification,这篇文章对person reid问题中的训练技巧进行了一个很好的总结,并提出了一个性能强大的baseline,在Market1501数据集上实现了rank-1 = 94.5%的准确率。
论文链接:https://arxiv.org/pdf/1903.07071.pdf
代码链接:https://github.com/michuanhaohao/reid-strong-baseline
作者:Hao Luo1∗, Youzhi Gu1∗, Xingyu Liao2∗, Shenqi Lai3, Wei Jiang1 1 Zhejiang University, 2 Chinese Academy of Sciences, 3 Xi’an Jiaotong University
Motivation
[1] We surveyed many works published on top conferences and found most of them were expanded on poor baselines.
对person re-id领域目前性能最好的方法进行了调研,发现大多数方法的baseline都比较低。
[2] For the academia, we hope to provide a strong baseline for researchers to achieve higher accuracies in person ReID.
对学术界,希望能够提供一个强大的baseline。
[3] For the community, we hope to give reviewers some references that what tricks will affect the performance of the ReID model. We suggest that when comparing the performance of the different methods, reviewers need to take these tricks into account.
对学术圈,希望让reviewer了解到trick的重要性。
[4] For the industry, we hope to provide some effective tricks to acquire better models without too much extra consumption.
对工业界,希望能够提供一个简单而有效的模型。
Contribution
[1] We collect some effective training tricks for person ReID. Among them, we design a new neck structure named as BNNeck. In addition, we evaluate the improvements from each trick on two widely used datasets.
本文总结了person re-id任务的一些训练技巧。同时提出了一个结构,BNNeck。
[2] We provide a strong ReID baseline, which achieves 94.5% and 85.9% mAP on Market1501. It is worth mentioned that the results are obtained with global features provided by ResNet50 backbone. To our best knowledge, it is the best performance acquired by global features in person ReID.
提出了一个强大的baseline并在Market1501上实现rank-1 = 94.5%, mAP = 85.9%。
[3] As a supplement, we evaluate the influences of the image size and the number of batch size on the performance of ReID models.
进行实验探究了图片尺寸和batch size大小对性能的影响。
Standard Baseline
[1] We initialize the ResNet50 with pre-trained parameters on ImageNet and change the dimension of the fully connected layer to N. N denotes the number of identities in the training dataset. 采用ImageNet上预训练过的ResNet50作为backbone。
[2] We randomly sample P identities and K images of per person to constitute a training batch. Finally the batch size equals to B = P×K. In this paper, we set P = 16 and K = 4.
为了使用triplet loss,每个batch中包括16个人,每个人4张图。
[3] We resize each image into 256 × 128 pixels and pad the resized image 10 pixels with zero values. Then randomly crop it into a 256 × 128 rectangular image.
图片预处理中采用了resize和random crop。
[4] Each image is flipped horizontally with 0.5 probability.
图片预处理中还采用了随机水平翻转。
[5] Each image is decoded into 32-bit floating point raw pixel values in [0, 1]. Then we normalize RGB channels by subtracting 0.485, 0.456, 0.406 and dividing by 0.229, 0.224, 0.225, respectively.
图片预处理中采用了归一化,使像素值分布满足均值为0,方差为1。
[6] The model outputs ReID features f and ID prediction logits p.
模型的输出包括特征f和预测ID概率p。
[7] ReID features f is used to calculate triplet loss. ID prediction logits p is used to calculated cross entropy loss. The margin m of triplet loss is set to be 0.3.
模型的输出f用于计算triplet loss,p用于计算交叉熵损失。
[8] Adam method is adopted to optimize the model. The initial learning rate is set to be 0.00035 and is decreased by 0.1 at the 40th epoch and 70th epoch respectively. Totally there are 120 training epochs.
优化器采用Adam,另一篇总结video based reid的文章[2]也使用了Adam作为优化器。
Training Tricks
Warmup Learning Rate

如图所示,就是前几轮的学习率有一个逐渐增大的过程,之前在一些其他的文章[1]里也看到有提到这一方法。
Random Erasing Augmentation
Zhun Zhong等人在[3]中提出的数据增强手段,本文设置参数 p = 0.5, 0.02
Label Smoothing

由[4]提出,目的是使标签更为平滑。本文将ε设置为0.1。
Last Stride
将ResNet50最后一个卷积层的步长由2改为1,从而增大输出feature map的尺寸。这一做法增加的计算量极少且不会增加训练参数,但对性能提升有明显帮助。
BNNeck

大多数结合ID loss和triplet loss的方法都采用了上图(a)所示的结构,两个损失函数对同一特征f进行约束。
作者则指出,前置研究发现,ID loss本质是在特征空间中学习几个超平面,将不同类别的特征分配到不同子空间里,将特征归一化到超球面,再采用ID loss进行优化会取得更好的效果。Triplet loss则适合在自由的欧式空间中进行约束。
因此作者提出了BNNeck,如上图(b)所示。BNNeck中triplet loss优化的特征仍然是原先的特征,即图中的ft。ID loss优化的则是ft经一个BN层归一化后生成的特征fi,通过归一化使得fi近似在超球面表面分布。
Center Loss

Triplet loss存在一个缺点,即只考虑样本对之间的相对距离,没有考虑到绝对距离。作者提出再增加Center loss,其数学形式如上所示,即使特征ft与该类特征的中心更为接近。
Experimental Results
Influences of Each Trick(Same domain)
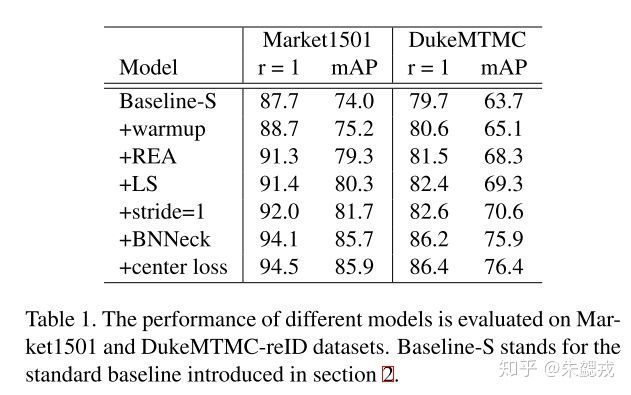
各个trick带来的性能提升。其中可以看到random erasing和BNNeck带来提升较大,各有2-3%。Random erasing笔者在image reid上使用时也有明显提升,但换到video reid上没有效果。BNNeck值得尝试。
Analysis of BNNeck

主要对加BNNeck后的ft、fi两个特征分别用欧式距离和余弦距离给出了实验结果。结果显示两个特征分别在两种metric下测出的四个性能相当,均相比于不加BNNeck有2个点左右的提升。
Influences of Each Trick (Cross domain)

same domain下可能会出现过拟合问题,性能提升的说服力有限,因此作者还进行了cross domain的实验。
结果表明,warmup、label smooth、BNNeck对cross domain下性能提升有较明显的帮助。Random erasing则影响了性能,去除之后性能更高,原因推测是过拟合了。
Comparison of State-of-the-Arts

和state-of-the-art相比,本文最终实现了rank 1 = 94.5%的性能,而且只用了全局特征。
Influences of the Number of Batch Size

本文还对batch size的不同设置进行了测试。整体来看batch size越大性能越好,但是在达到64之后感觉提升不大。
Influences of Image Size

本文还对image size对性能的影响进行了实验,最终结果显示image size对最终性能基本无影响。我之前实验的感受是,resize之后的尺寸小于原始尺寸时,增大size对性能提升有帮助,超过原始尺寸后继续增大就没什么效果了。
Summary
总的来说,本文对Reid任务中的神经网络设计及训练的trick作了很好的总结,提出的BNNeck值得尝试。
参考文献
[1] Bag of Tricks for Image Classification with Convolutional Neural Networks
[2] Revisiting Temporal Modeling for Video-based Person ReID
[3] Random Erasing Data Augmentation
[4] Rethinking the inception architecture for computer vision