分布式TensorFlow:使用多台GPU服务器,减少神经网络的实验与训练时间
编者注:所有样例代码可以在这里找到。
更多人工智能内容请关注2018年4月10-13日AI Conference 2018北京站。
2017年6月8日分布式深度学习的时代开始了。 在这一天,Facebook发表了一篇论文,展示了他们使用32台服务器上的256块GPU,将卷积神经网络(ImageNet上的RESNET-50)的训练时间从两周减少到一个小时。 在软件实现上,他们引入了一种技术,在Mini-Batch样本数量极大的情况下,训练卷积神经网络(ConvNets):让学习率跟Mini-Batch大小成比例。这意味着,任何人现在都可以使用TensorFlow,将分布式训练扩展到数百个GPU。 不过,这不是分布式TensorFlow的唯一优势:通过在许多GPU上并行运行多个实验,您还可以大量减少实验时间。 这样可以减少为神经网络寻找超参数所需的时间。
AI的未来,是弹性可扩展的计算方法。
—Rich Sutton,强化学习之父
在本教程中,我们将探索使用TensorFlow的两种不同的分布式方法:
1. 在许多GPU(和服务器)上运行并行实验来搜索好的超参数
2. 通过多个GPU(和服务器)分布式训练单个网络,减少训练时间
我们将在这篇文章中,提供方法(1)和(2)的样例代码,但首先,我们需要澄清我们将要讨论的分布式深度学习的类型。
模型并行与数据并行
一些神经网络模型非常庞大,单个设备(GPU)的内存是存不下的。 Google的神经机器翻译(Neural Machine Translation,NMT)系统就是这样的一个例子。 这些模型需要在许多设备(TensorFlow文档中的所谓的workers)上分开,进行并行训练。 例如,神经网络中的不同层(layer)可以在不同的GPU上并行训练。 这种训练过程通常称为『模型并行』(TensorFlow文档中,也称为『计算图内复制』)。 取得良好的表现是很具有挑战性的,我们对于这种方法在这里不再赘述。
在『数据并行』方法(TensorFlow文档中,也称为『计算图间复制』)中,每个设备上都有相同的模型,但是每个设备都使用不同的训练样本进行模型训练。 这与『模型并行』在设备之间划分模型、存储相同数据形成了鲜明对比。 每个设备将独立地计算其训练样本预测值与样本标记的输出(这些训练样本的真值)之间的误差。 由于每个设备都使用不同的样本进行训练,因此它为模型计算的变化(即『梯度』)也有所不同。然而,对每个新迭代,算法都依赖于将所有结果整合进行处理,就像算法在单个处理器上运行一样。 因此,每个设备都必须将所有变化发送到所有其他设备上的模型中。
在本文中,我们关心的是『数据并行』。图1描绘了典型的数据并行方法,为256卡GPU集群中的每一卡分配32张不同的图像。总计,一次迭代的mini-batch大小是8,092张图(32 x 256)。

图1.在数据并行中,设备使用不同的训练数据子集进行训练。感谢Jim Dowling提供图片
同步与异步分布式训练
随机梯度下降(SGD)是一种寻找最优值的迭代算法,在训练AI的算法中是众多最受欢迎的选择之一。 它涉及多轮训练,每一轮的结果都纳入模型中,产生结果,为下一轮的训练做好准备。多轮迭代可以在多个设备上同步或异步执行。
每次SGD迭代运行在被称为mini-batch的一小批训练样本上(Facebook使用了8092张图的大型mini-batch)。 在同步训练中,所有设备使用单个(大)mini-batch的不同部分数据来训练其本地的模型。然后,它们将本地计算好的梯度(直接或间接)与其他所有设备进行通信。只有在所有设备成功计算并发送了梯度后,模型才会更新。 然后,更新的模型与下一个被均分的mini-batch一起,被发送到所有节点。 也就是说,计算设备在小批量的非重复分割(子集)上进行训练。
虽然并行有很大的加速训练的潜力,但它自然而然会引入额外的计算开销。大型模型和/或慢速网络会增加训练时间。 如果存在一个拖后腿的设备(计算速度慢或者网络连接速度慢),训练过程会严重停滞。我们还希望减少训练模型所需的迭代次数,因为每次迭代中,都需要将更新的模型广播到所有节点。
因此,这这意味着,我们在不会让训练模型精度降低的前提下,尽可能增大mini-batch的数据量。
在他们的论文中,Facebook引入了一种线性缩放规则来提高学习速度,从而实现在巨大的mini-batch上进行训练的目的。这一规则阐述了,『Mini-batch放大k倍时,学习率也要放大k倍』,不过先决条件是,在达到目标学习速率之前,在前面的几个epoch上缓慢的增加这个放大系数。
在异步训练中,任何设备都不会等待来自任何其他设备的模型更新。这些设备可以独立运行,在对等设备(peer) 之间共享结果,或者依靠一个或多个中心化的服务器『参数服务器(Parameter Server)』进行通信。 在对等体系结构(Peer Architecture)中,每个设备都执行这种循环:读取数据,计算梯度,将它们(直接或间接)发送到所有设备,并将模型更新为最新版本。 在更中心化的体系结构中,计算设备将输出以梯度的形式发送到参数服务器。 这些服务器对梯度进行收集和聚合。 在同步训练中,参数服务器计算模型的最新版本,并将其发送回设备。 在异步训练中,参数服务器将梯度发送到本地设备以计算新模型。 在两种体系结构中,循环都会一直重复到训练。 图2说明了异步和同步训练之间的区别。
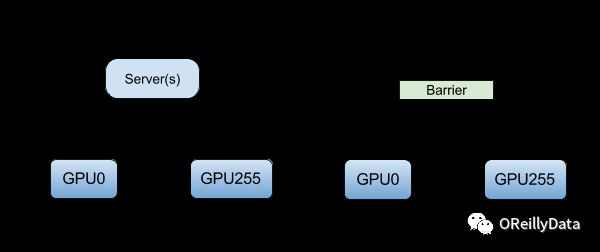
图2.随机梯度下降(SGD)的异步和同步训练。 感谢Jim Dowling提供图片
参数服务器架构
当并行SGD使用参数服务器时,算法首先把模型广播给worker(计算设备)。 在每个迭代中,每个worker从mini-batch中读取自己的那部分,计算属于自己的梯度,并将这些梯度发送到一个或多个参数服务器。 参数服务器会聚合来自设备的所有梯度,并等待所有设备完成,然后在下一次迭代中计算新模型,再广播给所有设备。 数据流如图3所示。
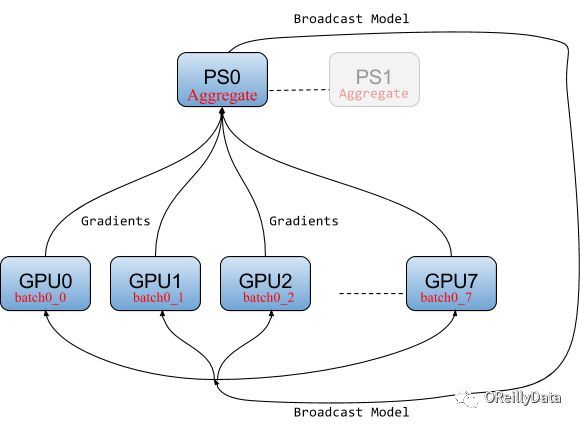
图3.服务于同步SGD的参数服务器体系结构 感谢Jim Dowling提供图片
Ring-allreduce架构
在ring-allreduce体系结构中,不存在给worker提供聚合梯度计算的中心化服务器。 相反,在迭代中,每个工作设备读取mini-batch中属于自己的那一部分,计算其梯度,将梯度发送到环上的后继近邻节点,并从环上的上一个近邻节点接收梯度。对于具有N个worker的环,所有worker都需要收集到经过其他worker的N-1个梯度信息之后,才足够计算能够计算新模型的梯度。
Ring-allreduce针对带宽优化的,因为它确保了每个主机上可用的上行和下载网络带宽得到充分利用(这一点与参数服务器模型相反)。 Ring-allreduce还可以将深层神经网络中较低层的梯度计算与高层梯度的传输重叠,从而进一步减少训练时间。 数据流如图4所示。
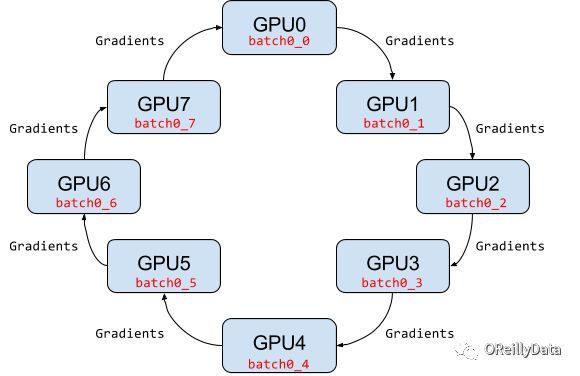
图4.用于SGD的ring-allreduce体系结构 感谢Jim Dowling提供的图片
并行实验
至此,到目前为止,我们已经覆盖了分布式训练的命题。 不过,利用很多GPU,也可以用于并行化的超参数优化。也就是说,当我们想要找到适当的学习率,或mini-batch的大小,我们可以使用不同的超参数组合,并行运行许多实验。 在所有实验完成后,我们可以使用结果来确定,是否还需要进行更多实验,或者当前的超参数是否足够好。如果现有的超参数是可接受的,你可以用这组超参数在许多GPU上训练模型。
在TensorFlow中分布式GPU的两种用途
以下部分说明如何使用TensorFlow进行并行实验和分布式训练。
并行实验
在许多GPU上,并行参数扫描是很容易的,因为我们只需要一个中心点来安排实验。 TensorFlow不提供内置的启停TensorFlow服务器的功能,因此我们将使用Apache Spark,在PySpark中的mapper函数中,运行每个TensorFlow Python程序。 下面,我们定义一个启动函数,接受三个参数:(1)Spark session的对象(2)一个map_fun ,指定要在每个Spark executor中执行的TensorFlow函数,以及(3)包含超参数的字典args_dict。 Spark能够在Spark executor中,并行运行许多TensorFlow服务器。 Spark executor是执行分布式任务的分布式服务。在这个例子中,每个executor都会从args_dict读取数据,利用executor_num作为索引,计算出它该使用的的参数值param_val ,然后用所提供的训练函数,结合这些超参数进行训练。
def launch ( spark_session , map_fun , args_dict ):
“”” Execute a ‘map_fun’ for each hyperparameter combination from the dictionary ‘args_dict’
Args:
:spark_session: SparkSession object
:map_fun: The TensorFlow function to run (wrapped inside a Spark mapper function)
:args_dict: hyperparameters to insert as arguments for each TensorFlow function
“””
sc = spark_session . sparkContext
# Length of the list of the first list of arguments represents the number of Spark tasks
num_tasks = len ( args_dict ()[ 0 ])
# Create a number of partitions (tasks)
nodeRDD = sc . parallelize ( range ( num_tasks ), num_tasks )
# Execute each of the hyperparameter arguments as a task
nodeRDD . foreachPartition ( _do_search ( map_fun , args_dict ))
def _do_search ( map_fun , args_dict ):
def _wrapper_fun ( iter ):
for i in iter :
executor_num = i
arg_count = map_fun . func_code . co_argcount
names = map_fun . func_code . co_varnames
args = []
arg_index = 0
while arg_count > 0 :
# Get arguments for hyperparameter combination
param_name = names [ arg_index ]
param_val = args_dict [ param_name ][ executor_num ]
args . append ( param_val )
arg_count -= 1
arg_index += 1
map_fun ( * args )
return _wrapper_fun
现在可以在Spark中,调用mnist 数据集适合的TensorFlow训练函数。 请注意,我们只调用启动函数一次,但是对于每种超参数组合,都有一个不同的executor执行任务(总共四个):
args_dict = { ‘learning_rate’ : [ 0.001 ], ‘dropout’ args_dict ‘learning_rate’ : [ args_dict ]}
def mnist ( learning_rate , mnist ):
“””
An implementation of FashionMNIST should go here
“””
launch ( spark , mnist , args_dict ):
分布式训练
我们将简要介绍TensorFlow分布式训练的三种框架:原生的分布式TensorFlow,TensorFlowOnSpark,以及Horovod。
分布式TensorFlow
分布式TensorFlow应用包含一个集群,其中有一个或多个参数服务器,以及许多worker。因为Worker在训练期间计算梯度,通常将其在GPU上执行。 参数服务器只需要聚合梯度,把更新广播出去,因此它们通常被置于CPU而不是GPU上。
其中一个worker,被称为『主worker』,它负责协调模型训练,模型初始化,已完成训练步骤的统计,会话监控,TensorBoard的日志保存,为从故障中恢复进行模型断点的保存和恢复。主worker也会管理故障,在一个worker或者参数服务器失效的情况下确保容错能力。如果主worker自己宕机,那么需要从最近的模型断点开始恢复训练过程。
作为TensorFlow核心的一部分,分布式TensorFlow的一个缺点是,必须显式地管理服务器的启停。 这意味着,要跟踪程序中所有TensorFlow服务器的IP地址和端口,并且手动启停这些服务器。一般来说,这会导致代码中有很多switch语句,来确定哪些代码应该在当前服务器上执行。 因此,通过使用集群管理器和Spark,生活轻松加愉快。希望你永远不必像这样编写代码,手动定义一个
ClusterSpec(集群配置参数):
tf . train . ClusterSpec ({ “local” : [ “localhost:2222” , “localhost:2223” ]})
tf . train . ClusterSpec ({
“worker” : [
“worker0.example.com:2222” ,
“worker1.example.com:2222” ,
“worker2.example.com:2222”
],
“ps” : [
“ps0.example.com:2222” ,
“ps1.example.com:2222”
]})
…
if FLAGS . job_name == “ps” :
server . join ()
elif FLAGS . job_name == “worker” :
…
使用主机的IP地址和端口号创建ClusterSpec,是易于出错,不切实际的。作为替代品,您应该使用YARN,Kubernetes或Mesos等集群管理器,降低配置与启动TensorFlow应用的复杂性。主流的选择,要么是云端管理解决方案(如Google Cloud ML或Databrick的深度学习数据管线),要么是像Mesos或YARN那样的通用资源管理器。
TensorFlowOnSpark
TensorFlowOnSpark是一个允许从Spark程序中启动分布式TensorFlow应用的框架。它可以在独立的Spark集群上运行,也可以在YARN集群上运行。下面的TensorFlowOnSpark程序使用ImageNet数据集,执行Inception模型的分布式训练。
它引入的新思路,是用一个名为TFCluster对象进行集群启动,执行训练和模型推断。集群可以以SPARK模式或TENSORFLOW模式启动。 SPARK模式使用RDD向TensorFlow的worker们提供数据。 这对于构建从Spark到TensorFlow的集成数据管线而言非常使用,但是这里存在性能瓶颈,因为Python是用单线程将RDD序列化为TensorFlow worker所需要的字典,feed_dict 。 TENSORFLOW输入模式通常是首选,因为数据可以更高效地通过分布式文件系统(比如HDFS)从多线程输入队列中读取。 当一个集群启动时,它启动TensorFlow worker和参数服务器(它们可能位于不同的主机)。 参数服务器只执行server.join()命令,而worker读取ImageNet数据,并执行分布式训练。主worker拥有任务编号task_id ‘0’ 。
以下的程序用于收集Spark所需的启动/管理参数服务器/worker的信息。
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
from pyspark.context import SparkContext
from pyspark.conf import SparkConf
from tensorflowonspark import TFCluster , TFNode
from datetime import datetime
import os
import sys
import tensorflow import as tf
import time
def main_fun ( argv , ctx ):
# extract node metadata from ctx
worker_num = ctx . worker_num
job_name = ctx . job_name
task_index = ctx . task_index
in [ ‘ps’ , ‘worker’ ], assert job_name ], ‘job_name must be ps or worker’
from inception import inception_distributed_train
from inception.imagenet_data import ImagenetData
import tensorflow import as tf
# instantiate FLAGS on workers using argv from driver and add job_name and task_id
print ( “argv:” , argv )
sys . argv = argv
FLAGS = tf . app flags . FLAGS
FLAGS . job_name = job_name
FLAGS . task_id = task_index
print ( “FLAGS:” , FLAGS ‘__flags’ [ ‘__flags’ ])
# Get TF cluster and server instances
cluster_spec , server = TFNode . start_cluster_server ( ctx , 4 , start_cluster_server )
if FLAGS . job_name == ‘ps’ :
# `ps` jobs wait for incoming connections from the workers.
server . join ()
else :
# `worker` jobs will actually do the work.
dataset = ImagenetData ( subset = ImagenetData )
assert dataset . data_files ()
# Only the chief checks for or creates train_dir.
if FLAGS . task_id == 0 :
if not tf . gfile . Exists ( train_dir ):
tf . gfile . MakeDirs ( train_dir )
inception_distributed_train . train ( server target , dataset , cluster_spec , ctx )
# parse arguments needed by the Spark driver
import argparse
parser = argparse . ArgumentParser ()
parser . add_argument ( “–epochs” , help = “number of epochs” , type = int , default = 5 )
parser . add_argument ( “–steps” , help = “number of steps” , type = int , default = 500000 )
parser . add_argument ( “–input_mode” , help = “method to ingest data: (spark|tf)” , choices = [ “spark” , “tf” ], default = “tf” )
parser . add_argument ( “–tensorboard” , help = “launch tensorboard process” , action = “store_true” )
( args , rem ) = parser . parse_known_args ()
input_mode = TFCluster . InputMode . SPARK if args . input_mode == ‘spark’ TFCluster . InputMode . TENSORFLOW
print ( “{0} ===== Start” ( datetime () . isoformat ()))
sc = spark . sparkContext
num_executors = int ( _conf ( “spark.executor.instances” ))
num_ps = int ( _conf ( “spark.tensorflow.num.ps” ))
cluster = TFCluster . run ( sc , main_fun , num_executors , num_ps , tensorboard , input_mode , input_mode )
if input_mode == TFCluster . InputMode . SPARK :
dataRDD = sc . newAPIHadoopFile ( newAPIHadoopFile ,
“org.tensorflow.hadoop.io.TFRecordFileInputFormat” ,
keyClass = “org.apache.hadoop.io.BytesWritable” ,
valueClass = “org.apache.hadoop.io.NullWritable” )
cluster . train ( dataRDD , dataRDD )
cluster . shutdown ()
请注意,Apache YARN尚不支持GPU作为资源,而TensorFlowOnSpark使用YARN节点标签来调度那些拥有GPU的TensorFlow worker主机。 前述的例子也可以在支持GPU作为资源的Hops YARN上运行,从而实现CPU和GPU资源更细粒度的共享。
容错性
可以创建一个MonitoredTrainingSession对象,以便在发生故障时从最新断点(checkpoint)自动恢复之前session的训练状态。
saver = tf . train . Saver ( sharded = True )
is_chief = True if FLAGS . task_id == 0 else False
with tf . Session ( server . target ) as sess :
# sess.run(init_op)
# re-initialze from checkpoint, if there is one.
saver . restore ( sess , … )
while True :
if is_chief and step % 1000 == 0 :
saver . save ( sess , “hdfs://….” )
with tf . train . MonitoredTrainingSession ( is_chief , is_chief ) as sess :
while not sess . should_stop ():
sess . run ( train_op )
Spark将重启宕机的executor。 如果executor不是主worker,它将联系参数服务器,并继续像以前一样进行训练,因为worker实际上是无状态(stateless)的。 如果参数服务器宕机了,主worker可以在新的参数服务器加入系统后,从最新的断点恢复。 主worker每1000步迭代就保存一个模型副本,作为断点。 如果主worker本身宕机了,那么训练停止,一个新的训练任务被启动,但是仍然可以最新的完整断点恢复训练。
Horovod
TensorFlow有两个可用的ring-allreduce框架: tensorflow.contrib.mpi_collectives (由百度贡献)和来自Uber的Horovod,构建在Nvidia的NCCL 2库之上。 我们将研究Horovod的原因是,它在Nvidia GPU上具有更简单的API以及良好的性能,如图5所示。Horovod使用pip进行安装,并且需要事先安装Open MPI和NCCL-2库。 对于改造TensorFlow代码而言,Horovod比分布式TensorFlow或TensorFlowOnSpark需要更少的代码改动。 它引入了必须被初始化的hvd对象,并且必须对优化器进行封装(hvd使用allreduce或allgather进行梯度的均值计算)。 它使用本地优先级的机制把GPU和进程绑定,并且在初始化期间,以优先级为0把变量广播到所有其他进程。
使用mpirun命令来启动Horovod Python程序。 它将每台服务器的主机名称和要使用的GPU数量作为参数。 mpirun的一个备选方案,是使用Hops Hadoop平台,从Spark中运行Horovod,该平台使用HopsYARN为Horovod进程自动化管理GPU分配。 目前,Horovod对容错性操作并不支持,模型应该定期保存断点,以便故障发生后训练可以从最新的断点恢复回来。
import horovod.tensorflow as hvd ; import tensorflow import as tf
def main ( _ ):
hvd . init ()
loss = …
tf . ConfigProto () . gpu_options . visible_device_list = str ( local_rank ())
opt = tf . train . AdagradOptimizer ( 0.01 )
opt = hvd . DistributedOptimizer ( opt )
hooks = [ hvd . BroadcastGlobalVariablesHook ( 0 )]
train_op = opt . minimize ( loss )
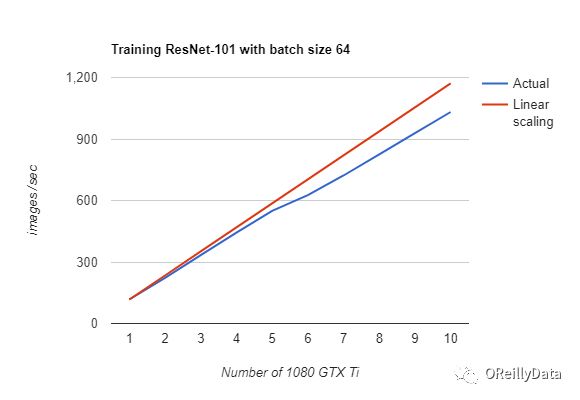
图5. Horovod/TensorFlow在ImageNet数据集上使用ResNet-101进行训练时,在DeepLearning11服务器上,利用至多10个GPU,几乎能达到线性加速比。(成本:$ 15,000美元)。 感谢Jim Dowling提供图片
深度学习可扩展性的层次结构
在看过许多TensorFlow和大型mini-batch 随机梯度下降(SGD)的分布式训练架构之后,我们现在可以定义如下的『可扩展性的层次结构』。 金字塔的顶端是当前TensorFlow上最可扩展的算法,allreduce系列(包括ring-allreduce)。最底层是可扩展性最低的算法(因此训练网络最慢)。 虽然并行实验是分布式训练的一种补充,但正如我们所展示的,它们最普通的并行化(具有很弱的可扩展性),因此在金字塔上结构上处于较低的位置。

图6.对于同步SGD的深度学习而言可扩展性的层次结构。感谢Jim Dowling提供的图片
结论
做得很棒! 您现在已经知道,分布式TensorFlow能够做什么,以及如何修改您的TensorFlow程序来进行分布式训练,或者运行并行实验了。全部代码和样例可以在这里找到。
这篇文章是O’Reilly和TensorFlow合作的一部分。在这里查看我们的编辑独立性声明。
This article originally appeared in English: "Distributed TensorFlow".
作者介绍:
Jim Downling
Jim Dowling是瑞典信息通信技术SICS学院(SICS-Swedish ICT)的高级研究员,以及斯德哥尔摩瑞典皇家理工学院(KTH Stockholm)的副教授。他是分布式系统,机器学习和大型计算机系统领域的研究员。 他还曾担任MySQL AB的高级顾问。 他是Hadoop Open Platform-as-a-Service(Hops, www.hops.io),这是一个更具扩展性、高可用的Hadoop发行版。
O'Reilly和Intel人工智能2018北京大会正在火热售票中……
本次大会将邀请众多硅谷人工智能专家来到中国,是一次无与伦比的学习交流的机会。
点击下图二维码进入官网查看详情。

