Spring 数据入口(第一部分)
参考文档的这一部分涉及数据访问和数据访问层与业务或服务层之间的交互。
本文详细介绍了Spring的全面事务管理支持,然后全面介绍了Spring框架集成的各种数据访问框架和技术。
1. 事务管理
全面的事务支持是使用Spring框架的最重要原因之一。Spring框架为事务管理提供了一致的抽象,提供了以下好处:
- 跨不同事务API(如Java事务API (JTA)、JDBC、Hibernate和Java持久性API (JPA))的一致编程模型。
- 支持声明式事务管理。
- 用于程序化事务管理的API比复杂事务API(如JTA)更简单。
- 与Spring数据访问抽象的优秀集成。
以下部分描述了Spring框架的事务特性和技术:
- Spring框架事务支持模型的优点描述了为什么要使用Spring框架的事务抽象,而不是EJB容器管理的事务(CMT)或选择通过专有API(如Hibernate)驱动本地事务。
- 理解Spring框架事务抽象概述了核心类,并描述了如何配置和从各种数据源获取数据源实例。
- 将资源与事务同步描述应用程序代码如何确保正确地创建、重用和清理资源。
- 声明性事务管理描述了对声明性事务管理的支持。
- 程序化事务管理包括对程序化(即显式编码)事务管理的支持。
- 事务绑定事件描述如何在事务中使用应用程序事件。
本章还讨论了最佳实践、应用服务器集成和常见问题的解决方案。
1.1 Spring框架的事务支持模型的优点
传统上,Java EE开发人员在事务管理方面有两种选择:全局事务或本地事务,两者都有很大的局限性。在接下来的两部分中,将回顾全局和本地事务管理,然后讨论Spring框架的事务管理支持如何解决全局和本地事务模型的限制。
1.1.1 全局事务
全局事务允许您使用多个事务资源,通常是关系数据库和消息队列。应用服务器通过JTA管理全局事务,JTA是一个繁琐的API(部分原因是它的异常模型)。此外,JTA UserTransaction通常需要从JNDI获得,这意味着您也需要使用JNDI来使用JTA。全局事务的使用限制了应用程序代码的任何潜在重用,因为JTA通常只在应用程序服务器环境中可用。
以前,使用全局事务的首选方法是通过EJB CMT(容器管理事务)。CMT是声明式事务管理的一种形式(与程序化事务管理不同)。EJB CMT消除了对与事务相关的JNDI查找的需要,尽管使用EJB本身需要使用JNDI。它消除了编写Java代码来控制事务的大部分(但不是全部)需求。其显著的缺点是CMT与JTA和应用服务器环境绑定在一起。而且,只有在选择在EJB中实现业务逻辑(或者至少在事务EJB facade之后)时,才可以使用它。EJB的负面影响通常如此之大,以至于这不是一个有吸引力的命题,特别是在声明性事务管理的替代方案面前。
1.1.2 本地事务
本地事务是特定于资源的,例如与JDBC连接相关联的事务。本地事务可能更容易使用,但有一个明显的缺点:它们不能跨多个事务资源工作。例如,使用JDBC连接管理事务的代码不能在全局JTA事务中运行。由于应用服务器不参与事务管理,因此它无法帮助确保多个资源之间的正确性。(值得注意的是,大多数应用程序使用单一事务资源。)另一个缺点是,本地事务对编程模型具有侵入性。
1.1.3 Spring框架的一致编程模型
Spring解决了全局事务和本地事务的缺点。它允许应用程序开发人员在任何环境中使用一致的编程模型。您只需编写一次代码,就可以从不同环境中的不同事务管理策略中获益。Spring框架同时提供了声明式和程序化事务管理。大多数用户更喜欢声明式事务管理,我们在大多数情况下推荐这种管理。
通过程序化事务管理,开发人员可以使用Spring框架事务抽象,它可以在任何底层事务基础设施上运行。使用首选的声明性模型,开发人员通常只编写很少或根本不编写与事务管理相关的代码,因此不依赖于Spring Framework事务API或任何其他事务API。
您需要一个应用程序服务器来进行事务管理吗?
Spring框架的事务管理支持改变了企业Java应用程序何时需要应用服务器的传统规则。
特别是,您不需要一个应用服务器来通过ejb进行声明性事务。实际上,即使您的应用程序服务器具有强大的JTA功能,您也可能认为Spring框架的声明性事务比EJB CMT提供了更强大的功能和更高效的编程模型。
通常,只有在应用程序需要处理跨多个资源的事务时,才需要应用服务器的JTA功能,而这对于许多应用程序来说并不是必需的。许多高端应用程序使用单一的、高度可伸缩的数据库(如Oracle RAC)。独立事务管理器(如Atomikos事务和JOTM)是其他选项。当然,您可能需要其他应用服务器功能,比如Java Message Service (JMS)和Java EE Connector Architecture (JCA)。
Spring框架允许您选择何时将应用程序扩展到完全加载的应用服务器。使用EJB CMT或JTA的唯一替代方法是使用本地事务(例如JDBC连接上的事务)编写代码,如果需要这些代码在全局的、容器管理的事务中运行,那么就需要进行大量的返工,这样的日子已经一去不复返了。在Spring框架中,只需要更改配置文件中的一些bean定义(而不需要更改代码)。
1.2 理解Spring框架事务抽象
Spring事务抽象的关键是事务策略的概念。事务策略由org.springframe .transaction定义。PlatformTransactionManager接口,如下所示:
public interface PlatformTransactionManager {
TransactionStatus getTransaction(TransactionDefinition definition) throws TransactionException;
void commit(TransactionStatus status) throws TransactionException;
void rollback(TransactionStatus status) throws TransactionException;
}这主要是一个服务提供者接口(SPI),尽管您可以从应用程序代码中以编程方式使用它。因为PlatformTransactionManager是一个接口,它可以根据需要轻松地模拟或存根。它不与查找策略(如JNDI)绑定。PlatformTransactionManager实现的定义与Spring框架IoC容器中的任何其他对象(或bean)一样。仅这一点就使Spring框架事务成为有价值的抽象,即使在使用JTA时也是如此。您可以比直接使用JTA更容易地测试事务代码。
同样,为了与Spring的理念保持一致,可以由任何PlatformTransactionManager接口的方法抛出的TransactionException是未选中的(也就是说,它扩展了java.lang。RuntimeException类)。事务基础架构失败几乎总是致命的。在极少数情况下,应用程序代码实际上可以从事务失败中恢复,应用程序开发人员仍然可以选择捕获和处理TransactionException。重要的一点是,开发人员并不是被迫这样做的。
getTransaction(..)方法根据TransactionDefinition参数返回一个TransactionStatus对象。如果当前调用堆栈中存在匹配的事务,则返回的TransactionStatus可以表示新事务,也可以表示现有事务。后一种情况的含义是,与Java EE事务上下文一样,TransactionStatus与执行线程相关联。
TransactionDefinition接口指定:
- 传播:通常,在事务范围内执行的所有代码都在该事务中运行。但是,如果在事务上下文已经存在时执行事务方法,则可以指定行为。例如,代码可以继续在现有事务中运行(通常情况下),或者可以挂起现有事务并创建一个新事务。Spring提供了所有与EJB CMT相似的事务传播选项。要了解Spring中事务传播的语义,请参阅事务传播。
- 隔离:此事务与其他事务的工作隔离的程度。例如,该事务是否可以看到来自其他事务的未提交写操作?
- 超时:此事务在超时并由基础事务基础设施自动回滚之前运行的时间。
- 只读状态:当代码读取但不修改数据时,可以使用只读事务。在某些情况下,例如使用Hibernate时,只读事务可能是一种有用的优化。
这些设置反映了标准的事务概念。如果需要,请参阅讨论事务隔离级别和其他核心事务概念的参考资料。理解这些概念对于使用Spring框架或任何事务管理解决方案都是必不可少的。
TransactionStatus接口为事务代码提供了一种简单的方法来控制事务执行并查询事务状态。这些概念应该很熟悉,因为它们对于所有事务api都是通用的。下面的清单显示了TransactionStatus接口:
public interface TransactionStatus extends SavepointManager {
boolean isNewTransaction();
boolean hasSavepoint();
void setRollbackOnly();
boolean isRollbackOnly();
void flush();
boolean isCompleted();
}无论您在Spring中选择声明式事务管理还是程序化事务管理,定义正确的PlatformTransactionManager实现都是绝对必要的。通常通过依赖项注入定义此实现。
PlatformTransactionManager实现通常需要了解其工作环境:JDBC、JTA、Hibernate等。下面的例子展示了如何定义一个本地的PlatformTransactionManager实现(在本例中,使用的是普通JDBC)。
你可以通过创建一个类似如下的bean来定义JDBC数据源:
然后,相关的PlatformTransactionManager bean定义有一个对数据源定义的引用。它应该类似于下面的例子:
如果您在Java EE容器中使用JTA,那么您将与Spring的JtaTransactionManager一起使用通过JNDI获得的容器数据源。下面的示例显示了JTA和JNDI查找版本的外观:
JtaTransactionManager不需要知道数据源(或任何其他特定资源),因为它使用容器的全局事务管理基础结构。
注意:前面的数据源bean定义使用了jee名称空间中的
您还可以轻松地使用Hibernate本地事务,如下面的示例所示。在这种情况下,您需要定义一个Hibernate LocalSessionFactoryBean,您的应用程序代码可以使用它来获得Hibernate会话实例。
DataSource bean定义类似于前面显示的本地JDBC示例,因此在下面的示例中没有显示。
注意:如果数据源(由任何非jta事务管理器使用)通过JNDI查找并由Java EE容器管理,那么它应该是非事务性的,因为是Spring框架(而不是Java EE容器)管理事务。
本例中的txManager bean是HibernateTransactionManager类型。与DataSourceTransactionManager需要对数据源的引用一样,HibernateTransactionManager需要对SessionFactory的引用。下面的例子声明了sessionFactory和txManager bean:
org/springframework/samples/petclinic/hibernate/petclinic.hbm.xml
hibernate.dialect=${hibernate.dialect}
如果您使用Hibernate和Java EE容器管理的JTA事务,您应该使用与前面的JTA JDBC示例相同的JtaTransactionManager,如下面的示例所示:
注意:如果您使用JTA,那么您的事务管理器定义应该看起来是一样的,不管您使用什么数据访问技术,它是JDBC、Hibernate JPA还是任何其他受支持的技术。这是因为JTA事务是全局事务,它可以征募任何事务资源。
在所有这些情况下,应用程序代码不需要更改。您可以仅通过更改配置来更改事务的管理方式,即使更改意味着从本地事务转移到全局事务,或者反之亦然。
1.3。将资源与事务同步
如何创建不同的事务管理器,以及如何将它们链接到需要同步到事务的相关资源(例如,DataSourceTransactionManager到JDBC数据源,HibernateTransactionManager到Hibernate SessionFactory,等等)现在应该很清楚了。本节描述应用程序代码(通过使用JDBC、Hibernate或JPA等持久性API,直接或间接地)如何确保正确地创建、重用和清理这些资源。本节还讨论了如何(可选地)通过相关的PlatformTransactionManager触发事务同步。
1.3.1。高级的同步方法
首选的方法是使用Spring最高级的基于模板的持久性集成api,或者使用带有事务感知的工厂bean或代理的本机ORM api来管理本机资源工厂。这些事务感知解决方案在内部处理资源的创建和重用、清理、资源的可选事务同步和异常映射。因此,用户数据访问代码不必处理这些任务,但可以只关注非样板持久性逻辑。通常,您使用本机ORM API,或者通过使用JdbcTemplate采用JDBC访问的模板方法。这些解决方案将在本参考文档的后续章节中详细介绍。
1.3.2。低级的同步方法
诸如DataSourceUtils(用于JDBC)、EntityManagerFactoryUtils(用于JPA)、SessionFactoryUtils(用于Hibernate)等类存在于较低的级别。当你想让应用程序代码直接处理原生资源类型的持久性API,您使用这些类来确保适当的Spring Framework-managed实例,事务是(可选)同步的,在这个过程中发生的和异常正确映射到一个一致的API。
例如,对于JDBC,您可以使用Spring的org.springframe . JDBC . DataSource,而不是调用数据源上的getConnection()方法的传统JDBC方法。DataSourceUtils类,如下:
Connection conn = DataSourceUtils.getConnection(dataSource);
如果现有事务已经有一个与之同步(链接)的连接,则返回该实例。否则,方法调用将触发新连接的创建,该连接(可选地)与任何现有事务同步,并可用于随后在同一事务中重用。如前所述,任何SQLException都被包装在Spring框架中,无法获得jdbcconnectionexception,这是Spring框架中未检查的DataAccessException类型的层次结构之一。这种方法提供的信息比从SQLException获得的信息要多,并且确保了跨数据库甚至跨不同持久性技术的可移植性。
这种方法也可以在没有Spring事务管理的情况下工作(事务同步是可选的),因此无论您是否将Spring用于事务管理,都可以使用它。
当然,一旦您使用了Spring的JDBC支持、JPA支持或Hibernate支持,您通常不喜欢使用DataSourceUtils或其他帮助类,因为您更乐于使用Spring抽象而不是直接使用相关api。例如,如果您使用Spring JdbcTemplate或jdbc。为了简化JDBC的使用,正确的连接检索是在后台进行的,不需要编写任何特殊的代码。
1.3.3。TransactionAwareDataSourceProxy
最底层是TransactionAwareDataSourceProxy类。这是目标数据源的代理,它包装目标数据源以增加对spring管理的事务的感知。在这方面,它类似于Java EE服务器提供的事务性JNDI数据源。
除了必须调用现有代码并传递标准的JDBC数据源接口实现时,您几乎不需要或不想使用这个类。在这种情况下,这段代码可能是可用的,但是参与了spring管理的事务。您可以使用前面提到的高级抽象来编写新代码。
1.4。声明式事务管理
注意:大多数Spring框架用户选择声明式事务管理。这个选项对应用程序代码的影响最小,因此最符合无创轻量级容器的理想。
Spring框架的声明性事务管理是通过Spring面向方面编程(AOP)实现的。但是,由于事务性方面的代码是随Spring框架发布而来的,并且可以以样板方式使用,所以AOP概念通常不需要理解就可以有效地使用这些代码。
Spring框架的声明式事务管理类似于EJB CMT,因为您可以在单个方法级别指定事务行为(或缺少事务行为)。如果需要,可以在事务上下文中调用setRollbackOnly()。两种类型的事务管理的区别是:
- 与绑定到JTA的EJB CMT不同,Spring框架的声明性事务管理可以在任何环境中工作。它可以使用JTA事务或本地事务(通过使用JDBC、JPA或Hibernate调整配置文件)。
- 您可以将Spring框架声明性事务管理应用于任何类,而不仅仅是ejb之类的特殊类。
- Spring框架提供了声明式回滚规则,这是一个没有等效EJB的特性。提供了对回滚规则的程序性和声明性支持。
- Spring框架允许您使用AOP定制事务行为。例如,您可以在事务回滚的情况下插入自定义行为。您还可以添加任意的建议以及事务建议。使用EJB CMT,您不能影响容器的事务管理,除非使用setRollbackOnly()。
- 与高端应用服务器不同,Spring框架不支持在远程调用之间传播事务上下文。如果您需要此功能,我们建议您使用EJB。但是,在使用这种特性之前要仔细考虑,因为通常不希望事务跨越远程调用。
回滚规则的概念非常重要。它们允许您指定哪些异常(以及可抛出的异常)应该导致自动回滚。您可以在配置中以声明的方式指定它,而不是在Java代码中。因此,尽管您仍然可以调用TransactionStatus对象上的setRollbackOnly()来回滚当前事务,但通常您可以指定一条规则,即MyApplicationException必须总是导致回滚。此选项的显著优点是业务对象不依赖于事务基础结构。例如,它们通常不需要导入Spring事务api或其他Spring api。
虽然EJB容器默认行为会自动回滚系统异常上的事务(通常是运行时异常),但是EJB CMT不会自动回滚应用程序异常上的事务(即除java.rmi.RemoteException之外的已检查异常)。虽然声明性事务管理的Spring默认行为遵循EJB约定(仅在未检查的异常时自动回滚),但是定制此行为通常很有用。
1.4.1。理解Spring框架的声明性事务实现
仅仅告诉您使用@Transactional注释注释您的类、将@EnableTransactionManagement添加到您的配置并期望您理解它是如何工作的是不够的。为了提供更深入的理解,本节将解释在发生与事务相关的问题时Spring框架的声明性事务基础结构的内部工作方式。
关于Spring框架的声明性事务支持,需要掌握的最重要的概念是,这种支持是通过AOP代理启用的,而事务通知是由元数据(目前是基于XML或注释的)驱动的。AOP与事务元数据的结合产生了一个AOP代理,它使用一个TransactionInterceptor和一个适当的PlatformTransactionManager实现来驱动围绕方法调用的事务。
AOP部分将讨论Spring AOP。
下图显示了调用事务代理上的方法的概念视图:
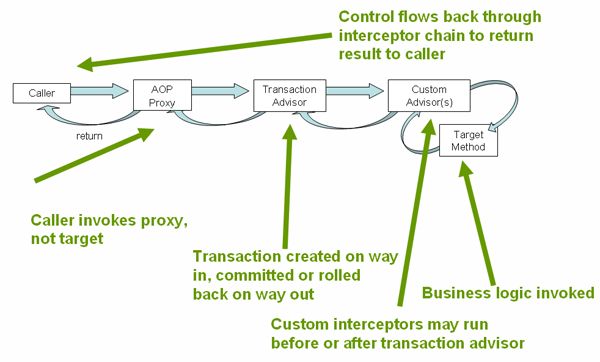
1.4.2。声明性事务实现的示例
考虑以下接口及其伴随的实现。本例使用Foo和Bar类作为占位符,这样您就可以专注于事务的使用,而不必关注特定的域模型。对于本例,DefaultFooService类在每个实现的方法体中抛出UnsupportedOperationException实例的事实是好的。该行为允许您查看创建的事务,然后回滚到UnsupportedOperationException实例中。下面的清单显示了FooService接口:
// the service interface that we want to make transactional
package x.y.service;
public interface FooService {
Foo getFoo(String fooName);
Foo getFoo(String fooName, String barName);
void insertFoo(Foo foo);
void updateFoo(Foo foo);
}下面的例子展示了上述接口的实现:
package x.y.service;
public class DefaultFooService implements FooService {
@Override
public Foo getFoo(String fooName) {
// ...
}
@Override
public Foo getFoo(String fooName, String barName) {
// ...
}
@Override
public void insertFoo(Foo foo) {
// ...
}
@Override
public void updateFoo(Foo foo) {
// ...
}
}假设FooService接口的前两个方法getFoo(String)和getFoo(String, String)必须在具有只读语义的事务上下文中执行,而其他方法insertFoo(Foo)和updateFoo(Foo)必须在具有读写语义的事务上下文中执行。下面几段详细解释了以下配置:
检查前面的配置。它假设您希望使一个服务对象(fooService bean)成为事务性的。要应用的事务语义封装在
注意:如果您想要连接的平台transactionManager的bean名称为transactionManager,那么您可以在事务通知(
在
一个常见的需求是使整个服务层具有事务性。最好的方法是改变切入点表达式来匹配服务层中的任何操作。下面的例子演示了如何做到这一点:
注意:在前面的示例中,假设所有服务接口都在x.y中定义。服务包。有关更多细节,请参见AOP部分。
现在我们已经分析了配置,您可能会问自己,“所有这些配置实际上做了什么?”
前面显示的配置用于围绕从fooService bean定义创建的对象创建事务代理。代理使用事务通知进行配置,以便在代理上调用适当的方法时,根据与该方法关联的事务配置启动、挂起、标记为只读等事务。请考虑以下测试驱动前面显示的配置的程序:
public final class Boot {
public static void main(final String[] args) throws Exception {
ApplicationContext ctx = new ClassPathXmlApplicationContext("context.xml", Boot.class);
FooService fooService = (FooService) ctx.getBean("fooService");
fooService.insertFoo (new Foo());
}
}运行上述程序的输出应该类似于以下内容(为了清晰起见,已截断了DefaultFooService类的insertFoo(..)方法抛出的UnsupportedOperationException的Log4J输出和堆栈跟踪):
[AspectJInvocationContextExposingAdvisorAutoProxyCreator] - Creating implicit proxy for bean 'fooService' with 0 common interceptors and 1 specific interceptors
[JdkDynamicAopProxy] - Creating JDK dynamic proxy for [x.y.service.DefaultFooService]
[TransactionInterceptor] - Getting transaction for x.y.service.FooService.insertFoo
[DataSourceTransactionManager] - Creating new transaction with name [x.y.service.FooService.insertFoo]
[DataSourceTransactionManager] - Acquired Connection [org.apache.commons.dbcp.PoolableConnection@a53de4] for JDBC transaction
[RuleBasedTransactionAttribute] - Applying rules to determine whether transaction should rollback on java.lang.UnsupportedOperationException
[TransactionInterceptor] - Invoking rollback for transaction on x.y.service.FooService.insertFoo due to throwable [java.lang.UnsupportedOperationException]
[DataSourceTransactionManager] - Rolling back JDBC transaction on Connection [org.apache.commons.dbcp.PoolableConnection@a53de4]
[DataSourceTransactionManager] - Releasing JDBC Connection after transaction
[DataSourceUtils] - Returning JDBC Connection to DataSource
Exception in thread "main" java.lang.UnsupportedOperationException at x.y.service.DefaultFooService.insertFoo(DefaultFooService.java:14)
at $Proxy0.insertFoo(Unknown Source)
at Boot.main(Boot.java:11)1.4.3 回滚声明性事务
前一节概述了如何在应用程序中声明性地为类(通常是服务层类)指定事务设置的基础知识。本节描述如何以简单的声明式方式控制事务的回滚。
要向Spring框架的事务基础结构表明要回滚事务的工作,建议的方法是从当前在事务上下文中执行的代码抛出异常。Spring框架的事务基础结构代码在弹出调用堆栈并决定是否将事务标记为回滚时捕获任何未处理的异常。
在其缺省配置中,Spring框架的事务基础结构代码仅在运行时未检查异常的情况下将事务标记为回滚。也就是说,当抛出的异常是RuntimeException的一个实例或子类时。(默认情况下,错误实例也会导致回滚)。从事务方法抛出的已检查异常不会导致默认配置中的回滚。
您可以准确地配置哪些异常类型将事务标记为回滚,包括已检查的异常。下面的XML片段演示如何为已检查的、特定于应用程序的异常类型配置回滚:
如果在抛出异常时不希望事务回滚,还可以指定“无回滚规则”。下面的例子告诉Spring框架的事务基础结构,即使面对未处理的InstrumentNotFoundException,也要提交相应的事务:
当Spring框架的事务基础结构捕获异常并参考配置的回滚规则以确定是否将事务标记为回滚时,最强的匹配规则获胜。因此,在以下配置的情况下,除了一个仪表notfoundexception之外的任何异常都会导致相应事务的回滚:
您还可以通过编程方式指示所需的回滚。尽管这个过程很简单,但是它具有很强的侵入性,并且将您的代码与Spring框架的事务基础结构紧密地耦合在一起。下面的示例演示如何以编程方式指示所需的回滚:
public void resolvePosition() {
try {
// some business logic...
} catch (NoProductInStockException ex) {
// trigger rollback programmatically
TransactionAspectSupport.currentTransactionStatus().setRollbackOnly();
}
}强烈建议您尽可能使用声明性方法回滚。如果您绝对需要,编程回滚是可用的,但是它的使用与实现一个干净的基于pojo的体系结构背道而驰。
1.4.4 为不同的bean配置不同的事务语义
考虑这样一种场景:您有许多服务层对象,并且希望对每个对象应用完全不同的事务配置。可以通过定义不同的
作为比较,首先假设所有服务层类都定义在根x.y中。服务包。要使所有在该包(或子包)中定义的类实例以及名称以服务结尾的bean具有默认的事务配置,您可以编写以下代码:
下面的示例展示了如何使用完全不同的事务设置配置两个不同的bean:
1.4.5
本节总结了可以使用
- 传播设置是必需的。
- 隔离级别是默认的。
- 事务是读写的。
- 事务超时默认为底层事务系统的默认超时,如果不支持超时,则为none。
- 任何RuntimeException都会触发回滚,而任何已检查的异常则不会。
您可以更改这些默认设置。下表总结了嵌套在
| Attribute | Required? | Default | Description |
|---|---|---|---|
|
|
Yes |
要与事务属性关联的方法名。通配符(*)可用于将相同的事务属性设置与许多方法(例如,get*、handle*、on*Event等)关联起来。 | |
|
|
No |
|
事务传播行为。 |
|
|
No |
|
事务超时(秒)。仅适用于传播REQUIRED或REQUIRES_NEW。 |
|
|
No |
-1 |
Transaction timeout (seconds). Only applicable to propagation |
|
|
No |
false |
读写事务与只读事务。仅适用于REQUIRED或REQUIRES_NEW。 |
|
|
No |
触发回滚的异常实例的逗号分隔列表。例如,com.foo.MyBusinessException ServletException。 |
|
|
|
No |
|
1.4.6 使用@Transactional
除了基于xml的声明式事务配置方法之外,还可以使用基于注释的方法。直接在Java源代码中声明事务语义使声明更接近受影响的代码。不存在过多耦合的危险,因为以事务方式使用的代码几乎总是以这种方式部署的。
注意:标准javax.transaction.Transactional注释作为Spring自己的注释的替代。更多细节请参阅JTA 1.2文档。
使用@Transactional注释所提供的易用性最好通过一个示例来说明,下面的文本将对此进行解释。考虑以下类定义:
// the service class that we want to make transactional
@Transactional
public class DefaultFooService implements FooService {
Foo getFoo(String fooName) {
// ...
}
Foo getFoo(String fooName, String barName) {
// ...
}
void insertFoo(Foo foo) {
// ...
}
void updateFoo(Foo foo) {
// ...
}
}如上所述,该注释用于类级别,它表示声明类(及其子类)的所有方法的默认值。另外,每个方法都可以得到单独的注释。请注意,类级别的注释不应用于类层次结构上的祖先类;在这种情况下,为了参与子类级别的注释,需要在本地重新声明方法。
当像上面这样的POJO类在Spring上下文中定义为bean时,您可以通过@Configuration类中的@EnableTransactionManagement注释使bean实例具有事务性。有关详细信息,请参阅 javadoc。
在XML配置中,
注意:如果要连接的平台transactionManager的bean名称为transactionManager,则可以省略
方法可见性和@Transactional
使用代理时,应该只将@Transactional注释应用于具有公共可见性的方法。如果使用@Transactional注释注释受保护的、私有的或包可见的方法,则不会引发错误,但是注释的方法不显示配置的事务设置。如果需要注释非公共方法,可以考虑使用AspectJ(后面会介绍)。
您可以将@Transactional注释应用于接口定义、接口上的方法、类定义或类上的公共方法。然而,仅仅存在@Transactional注释并不足以激活事务行为。@Transactional注释只是一些运行时基础设施可以使用的元数据,这些运行时基础设施支持@ transaction,并且可以使用元数据配置适当的bean和事务行为。在前面的示例中,
注意:Spring团队建议只使用@Transactional注释注释具体类(和具体类的方法),而不是注释接口。当然,您可以将@Transactional注释放在接口(或接口方法)上,但这仅在使用基于接口的代理时才有效。Java注释的事实并不意味着继承接口,如果使用基于类的代理(proxy-target-class = " true ")或weaving-based方面(模式=“aspectj”),事务设置不认可的代理和编织的基础设施,和对象不是包在一个事务代理。
在代理模式(这是缺省模式)中,只拦截通过代理传入的外部方法调用。这意味着自调用(实际上,目标对象中的一个方法调用目标对象的另一个方法)在运行时不会导致实际的事务,即使被调用的方法被标记为@Transactional。另外,代理必须被完全初始化以提供预期的行为,因此您不应该在初始化代码(即@PostConstruct)中依赖该特性。
如果您希望自调用也用事务包装,那么可以考虑使用AspectJ模式(请参阅下表中的mode属性)。在这种情况下,首先没有代理。相反,目标类被编织(即其字节码被修改)来将@Transactional转换为任何类型方法的运行时行为。
| XML Attribute | Annotation Attribute | Default | Description |
|---|---|---|---|
|
|
N/A (see |
|
要使用的事务管理器的名称。只有在事务管理器的名称不是transactionManager时才需要,如前面的示例所示。 |
|
|
|
|
默认模式(代理)处理要通过使用Spring的AOP框架代理的带注释的bean(遵循代理语义,如前所述,仅应用于通过代理传入的方法调用)。替代模式(aspectj)用Spring的aspectj事务方面编织受影响的类,修改目标类的字节码以应用于任何类型的方法调用。AspectJ编织需要类路径中的spring-aspect .jar以及启用加载时编织(或编译时编织)。(有关如何设置加载时编织的详细信息,请参阅Spring配置)。 |
|
|
|
|
仅适用于代理模式。控制使用@Transactional注释为类创建什么类型的事务代理。如果将proxy-target-class属性设置为true,则创建基于类的代理。如果proxy-target-class为false,或者属性被省略,那么就会创建标准的JDK基于接口的代理。(有关不同代理类型的详细检查,请参阅代理机制。) |
|
|
|
|
定义应用于使用@Transactional注释的bean的事务通知的顺序。(有关AOP通知排序的规则的更多信息,请参见通知排序。)没有指定的顺序意味着AOP子系统决定通知的顺序。 |
注意:处理@Transactional注释的默认通知模式是proxy,它只允许通过代理拦截调用。同一类内的本地调用不能通过这种方式被截获。对于更高级的拦截模式,可以考虑结合编译时或加载时编织切换到aspectj模式。
注意:代理目标类属性控制使用@Transactional注释为类创建什么类型的事务代理。如果将代理目标类设置为true,则创建基于类的代理。如果proxy-target-class为false,或者该属性被省略,则创建标准JDK基于接口的代理。(参见[aop-proxy - ying]讨论不同的代理类型。)
注意:@EnableTransactionManagement和
在计算方法的事务设置时,最派生的位置优先。在下面的示例中,DefaultFooService类在类级别使用只读事务的设置进行注释,但是同一类中updateFoo(Foo)方法上的@Transactional注释优先于在类级别定义的事务设置。
@Transactional(readOnly = true)
public class DefaultFooService implements FooService {
public Foo getFoo(String fooName) {
// ...
}
// these settings have precedence for this method
@Transactional(readOnly = false, propagation = Propagation.REQUIRES_NEW)
public void updateFoo(Foo foo) {
// ...
}
}@Transactional设置
@Transactional注释是指定接口、类或方法必须具有事务语义的元数据(例如,“在调用此方法时启动全新的只读事务,挂起任何现有事务”)。默认的@Transactional设置如下:
- 传播设置是PROPAGATION_REQUIRED。
- 隔离级别是ISOLATION_DEFAULT。
- 事务是读写的。
- 事务超时默认为底层事务系统的默认超时,如果不支持超时,则为none。
- 任何RuntimeException都会触发回滚,而任何已检查的异常则不会。
您可以更改这些默认设置。下表总结了@Transactional注释的各种属性:
| Property | Type | Description |
|---|---|---|
| value |
|
指定要使用的事务管理器的可选限定符。 |
| propagation |
|
Optional propagation setting. |
|
|
|
Optional isolation level. Applies only to propagation values of |
|
|
|
Optional transaction timeout. Applies only to propagation values of |
|
|
|
Read-write versus read-only transaction. Only applicable to values of |
|
|
Array of |
Optional array of exception classes that must cause rollback. |
|
|
Array of class names. The classes must be derived from |
Optional array of names of exception classes that must cause rollback. |
|
|
Array of |
Optional array of exception classes that must not cause rollback. |
|
|
Array of |
Optional array of names of exception classes that must not cause rollback. |
目前,您不能显式地控制事务的名称,其中“名称”表示出现在事务监视器(如WebLogic的事务监视器)和日志输出中的事务名称。对于声明性事务,事务名始终是完全限定的类名+。事务通知类的方法名。例如,如果BusinessService类的handlePayment(..)方法启动了一个事务,该事务的名称将是:com.example.BusinessService.handlePayment。
使用@Transactional的多个事务管理器
大多数Spring应用程序只需要一个事务管理器,但是在某些情况下,您可能希望在一个应用程序中有多个独立的事务管理器。您可以使用@Transactional注释的value属性选择性地指定要使用的PlatformTransactionManager的标识。这可以是bean名,也可以是事务管理器bean的限定符值。例如,使用限定符符号,您可以在应用程序上下文中将下列Java代码与下列事务管理器bean声明结合起来:
public class TransactionalService {
@Transactional("order")
public void setSomething(String name) { ... }
@Transactional("account")
public void doSomething() { ... }
}下面的清单显示了bean声明:
...
...
在本例中,TransactionalService上的两个方法在单独的事务管理器下运行,由订单和帐户限定符区分。如果没有找到特别符合条件的PlatformTransactionManager bean,则仍然使用缺省的
自定义快捷键的注释
如果您发现在许多不同的方法上重复使用与@Transactional相同的属性,Spring的元注释支持允许您为特定的用例定义自定义快捷注释。例如,考虑以下注释定义:
@Target({ElementType.METHOD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Transactional("order")
public @interface OrderTx {
}
@Target({ElementType.METHOD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Transactional("account")
public @interface AccountTx {
}前面的注释让我们把上一节的例子写成如下:
public class TransactionalService {
@OrderTx
public void setSomething(String name) {
// ...
}
@AccountTx
public void doSomething() {
// ...
}
}在前面的示例中,我们使用语法来定义事务管理器限定符,但是我们也可以包含传播行为、回滚规则、超时和其他特性。
1.4.7 事务传播
本节描述Spring中事务传播的一些语义。注意,本节并不是对事务传播的介绍。相反,它详细描述了Spring中关于事务传播的一些语义。
在spring管理的事务中,请注意物理事务和逻辑事务之间的差异,以及传播设置如何应用于这种差异。
理解PROPAGATION_REQUIRED
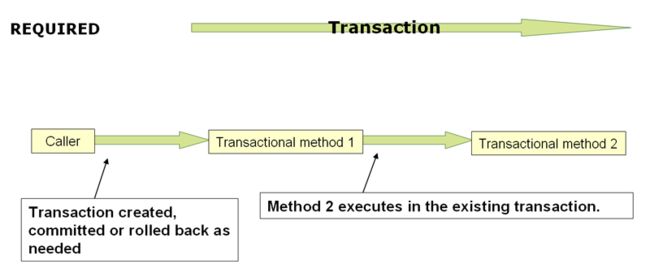
PROPAGATION_REQUIRED执行物理事务,如果当前范围内还不存在事务,则在本地执行物理事务,或者参与为更大范围定义的现有“外部”事务。在同一线程中的公共调用堆栈安排中,这是一个很好的默认设置(例如,一个服务facade,它将委托给几个存储库方法,其中所有底层资源都必须参与服务级事务)。
注意:默认情况下,参与事务连接外部范围的特征,默认忽略本地隔离级别、超时值或只读标志(如果有的话)。如果您希望在参与具有不同隔离级别的现有事务时拒绝隔离级别声明,请考虑在您的事务管理器上将validateExistingTransactions标志切换为true。这种非宽松模式还拒绝只读不匹配(即,内部的读写事务试图参与只读外部范围)。
当propagation设置为PROPAGATION_REQUIRED时,将为应用该设置的每个方法创建一个逻辑事务范围。每个这样的逻辑事务范围都可以单独确定仅回滚的状态,外部事务范围在逻辑上独立于内部事务范围。对于标准的PROPAGATION_REQUIRED行为,所有这些作用域都映射到同一个物理事务。因此,内部事务范围中设置的仅回滚标记确实会影响外部事务实际提交的机会。
但是,在内部事务范围设置仅回滚标记的情况下,外部事务没有决定回滚本身,因此回滚(由内部事务范围静默触发)是意外的。这时抛出一个对应的tedrollbackexception。这是预期的行为,因此事务的调用者永远不会被误导,以为提交是在实际没有执行的情况下执行的。因此,如果一个内部事务(外部调用者不知道它的存在)悄悄地将一个事务标记为仅回滚,那么外部调用者仍然调用commit。外部调用者需要接收一个意想不到的drollbackexception,以清楚地表明执行了回滚。
理解PROPAGATION_REQUIRES_NEW

与PROPAGATION_REQUIRED不同,PROPAGATION_REQUIRES_NEW总是为每个受影响的事务范围使用独立的物理事务,而从不参与外部范围的现有事务。在这种安排中,底层的资源事务是不同的,因此可以独立地提交或回滚,外部事务不受内部事务回滚状态的影响,内部事务的锁在完成后立即释放。这样一个独立的内部事务还可以声明自己的隔离级别、超时和只读设置,而不会继承外部事务的特征。
理解PROPAGATION_NESTED
propagation_嵌套使用一个具有多个保存点的物理事务,它可以回滚到这些保存点。这样的部分回滚允许内部事务范围触发其范围的回滚,而外部事务能够继续物理事务,尽管已经回滚了一些操作。该设置通常映射到JDBC保存点,因此它只适用于JDBC资源事务。看看Spring的 DataSourceTransactionManager。
1.4.8 建议事务操作
假设您希望同时执行事务操作和一些基本的分析建议。如何在
当您调用updateFoo(Foo)方法时,您希望看到以下操作:
- 启动已配置的概要方面。
- 执行事务通知。
- 执行被建议对象上的方法。
- 事务提交。
- 分析方面报告整个事务方法调用的确切持续时间。
本章不涉及对AOP的任何详细解释(除非它适用于事务)。有关AOP配置和AOP的详细内容,请参阅AOP。
下面的代码显示了前面讨论的简单概要方面:
package x.y;
import org.aspectj.lang.ProceedingJoinPoint;
import org.springframework.util.StopWatch;
import org.springframework.core.Ordered;
public class SimpleProfiler implements Ordered {
private int order;
// allows us to control the ordering of advice
public int getOrder() {
return this.order;
}
public void setOrder(int order) {
this.order = order;
}
// this method is the around advice
public Object profile(ProceedingJoinPoint call) throws Throwable {
Object returnValue;
StopWatch clock = new StopWatch(getClass().getName());
try {
clock.start(call.toShortString());
returnValue = call.proceed();
} finally {
clock.stop();
System.out.println(clock.prettyPrint());
}
return returnValue;
}
}通知的排序通过有序接口进行控制。有关通知订购的详细信息,请参 Advice ordering.。
下面的配置创建了一个fooService bean,它按照所需的顺序应用了分析和事务方面:
您可以以类似的方式配置任意数量的附加方面。
下面的示例创建了与前两个示例相同的设置,但使用的是纯XML声明方法:
前面的配置的结果是一个fooService bean,它按照这个顺序应用了分析和事务方面。如果希望分析建议在事务建议之后执行,在事务建议之前执行,那么可以交换分析方面bean的order属性的值,使其高于事务建议的order值。
您可以以类似的方式配置其他方面。
1.4.9。通过AspectJ使用@Transactional
您还可以通过AspectJ方面在Spring容器之外使用Spring框架的@Transactional支持。为此,首先使用@Transactional注释注释您的类(以及可选的类方法),然后使用在spring-aspects.jar文件中org.springframework.transaction.aspectj.AnnotationTransactionAspect。您还必须使用事务管理器配置方面。您可以使用Spring框架的IoC容器来处理依赖注入方面。配置事务管理方面的最简单方法是使用
注意:在继续之前,您可能希望分别使用@Transactional和AOP进行阅读。
下面的例子演示了如何创建事务管理器并配置AnnotationTransactionAspect来使用它:
// construct an appropriate transaction manager
DataSourceTransactionManager txManager = new DataSourceTransactionManager(getDataSource());
// configure the AnnotationTransactionAspect to use it; this must be done before executing any transactional methods
AnnotationTransactionAspect.aspectOf().setTransactionManager(txManager);注意:当您使用这个方面时,您必须注释实现类(或该类中的方法或两者),而不是类实现的接口(如果有的话)。AspectJ遵循Java的规则,接口上的注释不是继承的。
类上的@Transactional注释为类中任何公共方法的执行指定默认的事务语义。
类中的方法上的@Transactional注释覆盖类注释(如果存在)给出的默认事务语义。您可以注释任何方法,而不管其可见性如何。
要使用AnnotationTransactionAspect编织应用程序,必须使用AspectJ构建应用程序(请参阅AspectJ开发指南),或者使用加载时编织。有关使用AspectJ进行加载时编织的讨论,请参阅Spring框架中使用AspectJ进行加载时编织。
1.5 编程式事务管理
Spring框架提供了两种程序化事务管理的方法,它们是:
- TransactionTemplate。
- 一个直接的PlatformTransactionManager实现。
Spring团队通常建议使用TransactionTemplate进行程序化事务管理。第二种方法类似于使用JTA UserTransaction API,尽管异常处理没有那么麻烦。
1.5.1 使用TransactionTemplate
TransactionTemplate采用与其他Spring模板(如JdbcTemplate)相同的方法。它使用回调方法(将应用程序代码从必须进行样板获取和释放事务性资源的过程中解放出来),并生成由意图驱动的代码,因为您的代码只关注您想要做的事情。
注意:如下面的示例所示,使用TransactionTemplate绝对可以将您与Spring的事务基础结构和api结合起来。程序化事务管理是否适合您的开发需求是您必须自己做出的决定。
必须在事务上下文中执行并显式使用TransactionTemplate的应用程序代码类似于下面的示例。作为应用程序开发人员,您可以编写一个TransactionCallback实现(通常表示为一个匿名内部类),其中包含需要在事务上下文中执行的代码。然后可以将定制TransactionCallback的实例传递给TransactionTemplate上公开的execute(..)方法。下面的例子演示了如何做到这一点:
public class SimpleService implements Service {
// single TransactionTemplate shared amongst all methods in this instance
private final TransactionTemplate transactionTemplate;
// use constructor-injection to supply the PlatformTransactionManager
public SimpleService(PlatformTransactionManager transactionManager) {
this.transactionTemplate = new TransactionTemplate(transactionManager);
}
public Object someServiceMethod() {
return transactionTemplate.execute(new TransactionCallback() {
// the code in this method executes in a transactional context
public Object doInTransaction(TransactionStatus status) {
updateOperation1();
return resultOfUpdateOperation2();
}
});
}
}如果没有返回值,可以使用方便的TransactionCallbackWithoutResult类和一个匿名类,如下所示:
transactionTemplate.execute(new TransactionCallbackWithoutResult() {
protected void doInTransactionWithoutResult(TransactionStatus status) {
updateOperation1();
updateOperation2();
}
});回调中的代码可以通过调用提供的TransactionStatus对象上的setRollbackOnly()方法来回滚事务,如下所示:
transactionTemplate.execute(new TransactionCallbackWithoutResult() {
protected void doInTransactionWithoutResult(TransactionStatus status) {
try {
updateOperation1();
updateOperation2();
} catch (SomeBusinessException ex) {
status.setRollbackOnly();
}
}
});指定事务设置
可以在TransactionTemplate上以编程方式或在配置中指定事务设置(例如传播模式、隔离级别、超时等)。默认情况下,TransactionTemplate实例具有默认的事务设置 default transactional settings。下面的示例显示了对特定TransactionTemplate的事务设置的程序化自定义:
public class SimpleService implements Service {
private final TransactionTemplate transactionTemplate;
public SimpleService(PlatformTransactionManager transactionManager) {
this.transactionTemplate = new TransactionTemplate(transactionManager);
// the transaction settings can be set here explicitly if so desired
this.transactionTemplate.setIsolationLevel(TransactionDefinition.ISOLATION_READ_UNCOMMITTED);
this.transactionTemplate.setTimeout(30); // 30 seconds
// and so forth...
}
}下面的例子通过使用Spring XML配置定义了带有一些自定义事务设置的TransactionTemplate:
然后您可以将sharedTransactionTemplate注入到需要的任意数量的服务中。
最后,TransactionTemplate类的实例是线程安全的,在这种情况下,实例不维护任何会话状态。然而,TransactionTemplate实例维护配置状态。因此,虽然许多类可能共享一个TransactionTemplate实例,但是如果一个类需要使用具有不同设置的TransactionTemplate(例如,不同的隔离级别),则需要创建两个不同的TransactionTemplate实例。
1.5.2 使用PlatformTransactionManager
您还可以使用org.springframe .transaction。PlatformTransactionManager直接管理您的事务。为此,通过一个bean引用将您使用的PlatformTransactionManager的实现传递给bean。然后,通过使用TransactionDefinition和TransactionStatus对象,您可以启动事务、回滚和提交。下面的例子演示了如何做到这一点:
DefaultTransactionDefinition def = new DefaultTransactionDefinition();
// explicitly setting the transaction name is something that can be done only programmatically
def.setName("SomeTxName");
def.setPropagationBehavior(TransactionDefinition.PROPAGATION_REQUIRED);
TransactionStatus status = txManager.getTransaction(def);
try {
// execute your business logic here
}
catch (MyException ex) {
txManager.rollback(status);
throw ex;
}
txManager.commit(status);1.6 在程序性和声明性事务管理之间进行选择
编程式事务管理通常是一个好主意,只有当您有少量的事务操作时。例如,如果您的web应用程序只需要事务来执行某些更新操作,那么您可能不希望使用Spring或任何其他技术来设置事务代理。在这种情况下,使用TransactionTemplate可能是一种很好的方法。能够显式地设置事务名称也只能通过使用程序化的事务管理方法来完成。
另一方面,如果您的应用程序有许多事务操作,那么声明性事务管理通常是值得的。它将事务管理置于业务逻辑之外,并且易于配置。当使用Spring框架而不是EJB CMT时,声明性事务管理的配置成本将大大降低。
1.7 Transaction-bound事件
从Spring 4.2开始,事件的侦听器可以绑定到事务的某个阶段。典型的例子是在事务成功完成时处理事件。这样做可以在当前事务的结果对侦听器很重要时更灵活地使用事件。
可以使用@EventListener注释注册常规事件监听器。如果需要将其绑定到事务,请使用@TransactionalEventListener。这样做时,默认情况下侦听器被绑定到事务的提交阶段。
下一个例子展示了这个概念。假设组件发布了一个订单创建的事件,并且我们希望定义一个侦听器,该侦听器应该只在发布该事件的事务成功提交后才处理该事件。下面的例子设置了这样一个事件监听器:
@Component
public class MyComponent {
@TransactionalEventListener
public void handleOrderCreatedEvent(CreationEvent creationEvent) {
// ...
}
} @TransactionalEventListener注释公开了一个phase属性,该属性允许您自定义应该将侦听器绑定到的事务的阶段。有效的阶段是BEFORE_COMMIT、AFTER_COMMIT(默认)、AFTER_ROLLBACK和AFTER_COMPLETION,它们聚合事务完成(无论是提交还是回滚)。
如果没有事务在运行,则根本不会调用侦听器,因为我们不能遵从所需的语义。但是,您可以通过将注释的fallbackExecution属性设置为true来覆盖该行为。
1.8 特定于应用服务器的集成
Spring的事务抽象通常与应用服务器无关。此外,Spring的JtaTransactionManager类(可以选择性地对JTA UserTransaction和TransactionManager对象执行JNDI查找)自动检测后一个对象的位置,该位置随应用服务器的不同而不同。访问JTA TransactionManager允许增强事务语义——特别是支持事务暂停。有关详细信息,请参阅JtaTransactionManager javadoc。
pring的JtaTransactionManager是在Java EE应用服务器上运行的标准选择,并且可以在所有通用服务器上运行。高级功能(如事务暂停)也可以在许多服务器上工作(包括GlassFish、JBoss和Geronimo),而不需要任何特殊配置。然而,对于完全支持的事务挂起和进一步的高级集成,Spring包含用于WebLogic Server和WebSphere的特殊适配器。下面几节将讨论这些适配器。
对于标准场景,包括WebLogic Server和WebSphere,考虑使用方便的
1.8.1 IBM WebSphere
在WebSphere 6.1.0.9及以上版本中,推荐使用的Spring JTA事务管理器是WebSphereUowTransactionManager。这个特殊适配器使用IBM的UOWManager API,该API在WebSphere Application Server 6.1.0.9及更高版本中可用。有了这个适配器,IBM正式支持spring驱动的事务挂起(由PROPAGATION_REQUIRES_NEW启动的挂起和恢复)。
1.8.2 Oracle WebLogic Server
在WebLogic Server 9.0或更高版本上,您通常会使用WebLogicJtaTransactionManager而不是股票JtaTransactionManager类。常规JtaTransactionManager的这个特殊的特定于weblogic的子类支持Spring在weblogic管理的事务环境中的事务定义的全部功能,超越了标准的JTA语义。特性包括事务名称、每个事务的隔离级别,以及在所有情况下正确恢复事务。
1.9 常见问题的解决方案
本节描述一些常见问题的解决方案。
1.9.1 为特定数据源使用错误的事务管理器
根据您对事务技术和需求的选择,使用正确的PlatformTransactionManager实现。如果使用得当,Spring框架仅仅提供了一个简单且可移植的抽象。如果使用全局事务,则必须使用org.springframe .transaction.jta。用于所有事务操作的JtaTransactionManager类(或其特定于应用程序服务器的子类)。否则,事务基础结构将尝试对容器数据源实例等资源执行本地事务。这样的本地事务没有意义,好的应用程序服务器会将它们视为错误。
1.10 进一步的资源
有关Spring框架的事务支持的更多信息,请参见:
- Spring中的分布式事务,有和没有XA是一个JavaWorld演示,其中Spring的David Syer指导您了解Spring应用程序中分布式事务的七个模式,其中三个带有XA,四个没有。
- 《Java事务设计策略》是InfoQ提供的一本书,该书对Java事务进行了节奏紧凑的介绍。它还附带了一些示例,说明如何使用Spring框架和EJB3配置和使用事务。
2. DAO支持
Spring中的数据访问对象(DAO)支持旨在以一致的方式简化数据访问技术(如JDBC、Hibernate或JPA)的使用。这使您可以相当容易地在上述持久性技术之间进行切换,而且还使您不必担心捕获特定于每种技术的异常。
2.1 一致的异常层次结构
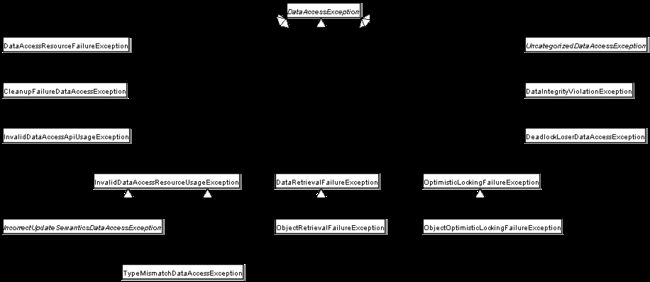
Spring提供了从特定于技术的异常(比如SQLException)到它自己的异常类层次结构的方便转换,后者将DataAccessException作为根异常。这些异常封装了原始的异常,这样就不会有丢失关于可能出错的任何信息的风险。
除了JDBC异常,Spring还可以包装JPA和hibernate特定的异常,将它们转换成一组集中的运行时异常。这使您可以仅在适当的层中处理大多数不可恢复的持久性异常,而不必在DAOs中使用烦人的样板捕获抛出块和异常声明。(不过,您仍然可以在任何需要的地方捕获和处理异常。)如上所述,JDBC异常(包括特定于数据库的方言)也被转换为相同的层次结构,这意味着您可以在一致的编程模型中使用JDBC执行某些操作。
前面的讨论适用于Spring对各种ORM框架的支持中的各种模板类。如果使用基于拦截器的类,应用程序必须关心如何处理hibernateexception和persistenceexception本身,最好分别委托给SessionFactoryUtils的convertHibernateAccessException(..)或convertJpaAccessException()方法。这些方法将异常转换为与org.springframework中的异常兼容的异常。dao异常层次结构。当persistenceexception未被检查时,它们也会被抛出(尽管在异常方面牺牲了一般的DAO抽象)。
下图显示了Spring提供的异常层次结构。(注意,图中详细描述的类层次结构仅显示整个DataAccessException层次结构的一个子集。)
2.2 用于配置DAO或存储库类的注释
确保数据访问对象(DAOs)或存储库提供异常转换的最佳方法是使用@Repository注释。该注释还允许组件扫描支持查找和配置DAOs和存储库,而不必为它们提供XML配置项。下面的例子演示了如何使用@Repository注释:
@Repository
public class SomeMovieFinder implements MovieFinder {
// ...
}任何DAO或存储库实现都需要访问持久性资源,这取决于使用的持久性技术。例如,基于JDBC的存储库需要访问JDBC数据源,而基于jpa的存储库需要访问EntityManager。完成此任务的最简单方法是通过使用@Autowired、@Inject、@Resource或@PersistenceContext注释之一注入此资源依赖项。下面的例子适用于JPA存储库:
@Repository
public class JpaMovieFinder implements MovieFinder {
@PersistenceContext
private EntityManager entityManager;
// ...
}如果你使用经典的Hibernate api,你可以注入SessionFactory,如下面的例子所示:
@Repository
public class HibernateMovieFinder implements MovieFinder {
private SessionFactory sessionFactory;
@Autowired
public void setSessionFactory(SessionFactory sessionFactory) {
this.sessionFactory = sessionFactory;
}
// ...
}我们在这里展示的最后一个例子是典型的JDBC支持。可以将数据源注入到初始化方法或构造函数中,通过使用该数据源创建JdbcTemplate和其他数据访问支持类(如SimpleJdbcCall和其他类)。下面的例子自动装配一个数据源:
@Repository
public class JdbcMovieFinder implements MovieFinder {
private JdbcTemplate jdbcTemplate;
@Autowired
public void init(DataSource dataSource) {
this.jdbcTemplate = new JdbcTemplate(dataSource);
}
// ...
}
注意:有关如何配置应用程序上下文以利用这些注释的详细信息,请参阅每种持久性技术的具体内容。
3.使用JDBC访问数据
Spring Framework JDBC抽象提供的值最好由下表中列出的操作序列来显示。该表显示了Spring负责哪些操作以及哪些操作是您的职责。
表4 Spring JDBC--谁来做什么?
| Action | Spring | You |
|---|---|---|
| Define connection parameters. |
X |
|
| Open the connection. |
X |
|
| Specify the SQL statement. |
X |
|
| Declare parameters and provide parameter values |
X |
|
| Prepare and execute the statement. |
X |
|
| Set up the loop to iterate through the results (if any). |
X |
|
| Do the work for each iteration. |
X |
|
| Process any exception. |
X |
|
| Handle transactions. |
X |
|
| Close the connection, the statement, and the resultset. |
X |
Spring框架负责处理所有底层细节,正是这些细节使得JDBC成为如此乏味的API。
3.1 为JDBC数据库访问选择一种方法
您可以在几种方法中进行选择,以形成JDBC数据库访问的基础。除了三种风格的JdbcTemplate之外,一种新的SimpleJdbcInsert和SimpleJdbcCall方法对数据库元数据进行了优化,RDBMS对象风格采用了一种与JDO查询设计类似的更面向对象的方法。一旦您开始使用这些方法中的一种,您仍然可以混合和匹配以包含来自不同方法的特性。所有的方法都需要兼容JDBC 2.0的驱动程序,一些高级特性需要JDBC 3.0驱动程序。
- JdbcTemplate是经典的、最流行的Spring JDBC方法。这种“最低级别”的方法和所有其他方法都在幕后使用JdbcTemplate。
- NamedParameterJdbcTemplate包装了一个JdbcTemplate来提供命名参数,而不是传统的JDBC ?占位符。当您有一个SQL语句的多个参数时,这种方法提供了更好的文档和易用性。
- SimpleJdbcInsert和SimpleJdbcCall优化数据库元数据以限制必要配置的数量。这种方法简化了编码,因此只需要提供表或过程的名称,并提供与列名匹配的参数映射。只有当数据库提供了足够的元数据时,这才能工作。如果数据库不提供此元数据,则必须提供参数的显式配置。
- RDBMS对象,包括MappingSqlQuery、SqlUpdate和StoredProcedure,要求您在初始化数据访问层期间创建可重用的、线程安全的对象。此方法模仿JDO查询,其中定义查询字符串、声明参数并编译查询。一旦您这样做了,就可以使用各种参数值多次调用execute方法。
3.2 包的层次结构
Spring框架的JDBC抽象框架由四个不同的包组成:
- core:org.springframework.jdbc。核心包包含JdbcTemplate类及其各种回调接口,以及各种相关的类。一个名为org.springframework.jdbc.core的子包。simple包含SimpleJdbcInsert和SimpleJdbcCall类。另一个名为org.springframework.jdbc.core.namedparam的子包包含NamedParameterJdbcTemplate类和相关的支持类。请参阅使用JDBC核心类来控制基本的JDBC处理和错误处理、JDBC批处理操作以及使用SimpleJdbc类简化JDBC操作。
- datasource:org.springframework.jdbc.datasource包包含一个实用程序类,用于简单的数据源访问和各种简单的数据源实现,您可以使用它在Java EE容器外测试和运行未经修改的JDBC代码。一个名为org.springfamework.jdbc.datasource的子包。嵌入式提供了通过使用Java数据库引擎(如HSQL、H2和Derby)创建嵌入式数据库的支持。参见控制数据库连接和嵌入式数据库支持。
- object:org.springframework.jdbc。对象包包含表示RDBMS查询、更新和存储过程的类,这些类是线程安全的、可重用的对象。请参阅将JDBC操作建模为Java对象。此方法由JDO建模,尽管查询返回的对象自然与数据库断开连接。这种高层的JDBC抽象依赖于org.springframework.jdbc.core包中的低层抽象。
- support:org.springframework.jdbc.support包提供了SQLException翻译功能和一些实用工具类。JDBC处理期间抛出的异常被转换成org.springframework中定义的异常。dao包。这意味着使用Spring JDBC抽象层的代码不需要实现JDBC或特定于rdbms的错误处理。所有转换后的异常都是未选中的,这为您提供了捕获异常的选项,您可以从中恢复,同时让其他异常传播到调用者。使用SQLExceptionTranslator看到。
3.3 使用JDBC核心类来控制基本的JDBC处理和错误处理
本节介绍如何使用JDBC核心类来控制基本的JDBC处理,包括错误处理。它包括下列主题:
-
Using
JdbcTemplate -
Using
NamedParameterJdbcTemplate -
Using
SQLExceptionTranslator -
Running Statements
-
Running Queries
-
Updating the Database
-
Retrieving Auto-generated Keys
3.3.1 使用JdbcTemplate
JdbcTemplate是JDBC核心包中的中心类。它处理资源的创建和释放,这有助于避免常见的错误,比如忘记关闭连接。它执行核心JDBC工作流的基本任务(如语句创建和执行),留下应用程序代码来提供SQL和提取结果。JdbcTemplate类:
- 运行SQL查询
- 更新语句和存储过程调用
- 对ResultSet实例执行迭代并提取返回的参数值。
- 捕获JDBC异常,并将它们转换为org.springframework中定义的通用的、信息更丰富的异常层次结构。dao包。(参见一致的异常层次结构。)
当您为代码使用JdbcTemplate时,您只需要实现回调接口,给它们一个明确定义的契约。对于由JdbcTemplate类提供的连接,PreparedStatementCreator回调接口创建一个准备好的语句,提供SQL和任何必要的参数。对于创建可调用语句的CallableStatementCreator接口也是如此。RowCallbackHandler接口从ResultSet的每一行中提取值。
您可以通过直接实例化数据源引用在DAO实现中使用JdbcTemplate,也可以在Spring IoC容器中配置它,并将其作为bean引用提供给DAOs。
注意:数据源应该始终在Spring IoC容器中配置为bean。在第一种情况下,bean直接提供给服务;在第二种情况下,它被提供给准备好的模板。
这个类发出的所有SQL都记录在调试级别,对应于模板实例的完全限定类名(通常是JdbcTemplate,但是如果使用JdbcTemplate类的自定义子类,情况可能会有所不同)。
以下部分提供了一些使用JdbcTemplate的示例。这些示例并不是JdbcTemplate公开的所有功能的详尽列表。请参阅相关的javadoc。
Querying (SELECT)
下面的查询获取关系中的行数:
int rowCount = this.jdbcTemplate.queryForObject("select count(*) from t_actor", Integer.class);以下查询使用绑定变量:
int countOfActorsNamedJoe = this.jdbcTemplate.queryForObject(
"select count(*) from t_actor where first_name = ?", Integer.class, "Joe");下面的查询查找一个字符串:
String lastName = this.jdbcTemplate.queryForObject(
"select last_name from t_actor where id = ?",
new Object[]{1212L}, String.class);以下查询查找并填充单个域对象:
Actor actor = this.jdbcTemplate.queryForObject(
"select first_name, last_name from t_actor where id = ?",
new Object[]{1212L},
new RowMapper() {
public Actor mapRow(ResultSet rs, int rowNum) throws SQLException {
Actor actor = new Actor();
actor.setFirstName(rs.getString("first_name"));
actor.setLastName(rs.getString("last_name"));
return actor;
}
}); 以下查询查找并填充大量域对象:
List actors = this.jdbcTemplate.query(
"select first_name, last_name from t_actor",
new RowMapper() {
public Actor mapRow(ResultSet rs, int rowNum) throws SQLException {
Actor actor = new Actor();
actor.setFirstName(rs.getString("first_name"));
actor.setLastName(rs.getString("last_name"));
return actor;
}
}); 如果最后两个片段代码实际上存在于相同的应用程序,它将意义删除重复出现在两个RowMapper匿名内部类和他们提取到一个单独的类(通常是一个静态嵌套类),然后可以引用的DAO方法。例如,最好将前面的代码片段写成如下:
public List findAllActors() {
return this.jdbcTemplate.query( "select first_name, last_name from t_actor", new ActorMapper());
}
private static final class ActorMapper implements RowMapper {
public Actor mapRow(ResultSet rs, int rowNum) throws SQLException {
Actor actor = new Actor();
actor.setFirstName(rs.getString("first_name"));
actor.setLastName(rs.getString("last_name"));
return actor;
}
} Updating (INSERT, UPDATE, and DELETE) with JdbcTemplate
使用JdbcTemplate更新(插入、更新和删除)
可以使用update(..)方法执行插入、更新和删除操作。参数值通常作为变量参数或对象数组提供。
下面的例子插入了一个新条目:
this.jdbcTemplate.update(
"insert into t_actor (first_name, last_name) values (?, ?)",
"Leonor", "Watling");下面的例子更新了一个现有的条目:
this.jdbcTemplate.update(
"update t_actor set last_name = ? where id = ?",
"Banjo", 5276L);下面的例子删除了一个条目:
this.jdbcTemplate.update(
"delete from actor where id = ?",
Long.valueOf(actorId));其他JdbcTemplate操作
您可以使用execute(..)方法来运行任意SQL。因此,该方法通常用于DDL语句。它被带有回调接口、绑定变量数组等的变量重载。下面的例子创建了一个表:
this.jdbcTemplate.execute("create table mytable (id integer, name varchar(100))");下面的例子调用了一个存储过程:
this.jdbcTemplate.update(
"call SUPPORT.REFRESH_ACTORS_SUMMARY(?)",
Long.valueOf(unionId));稍后将介绍更复杂的存储过程支持。
JdbcTemplate最佳实践
配置后,JdbcTemplate类的实例是线程安全的。这很重要,因为这意味着您可以配置一个JdbcTemplate的单个实例,然后安全地将这个共享引用注入到多个DAOs(或存储库)中。JdbcTemplate是有状态的,因为它维护对数据源的引用,但是这种状态不是会话状态。
使用JdbcTemplate类(以及相关的NamedParameterJdbcTemplate类)时的一个常见实践是在Spring配置文件中配置一个数据源,然后将该共享数据源bean依赖地注入到DAO类中。JdbcTemplate是在数据源的setter中创建的。这将导致类似于以下的dao:
public class JdbcCorporateEventDao implements CorporateEventDao {
private JdbcTemplate jdbcTemplate;
public void setDataSource(DataSource dataSource) {
this.jdbcTemplate = new JdbcTemplate(dataSource);
}
// JDBC-backed implementations of the methods on the CorporateEventDao follow...
}下面的例子展示了相应的XML配置:
显式配置的另一种替代方法是使用组件扫描和注释支持依赖项注入。在这种情况下,您可以使用@Repository来注释类(这使它成为组件扫描的候选对象),并使用@Autowired来注释DataSource setter方法。下面的例子演示了如何做到这一点:
@Repository
public class JdbcCorporateEventDao implements CorporateEventDao {
private JdbcTemplate jdbcTemplate;
@Autowired
public void setDataSource(DataSource dataSource) {
this.jdbcTemplate = new JdbcTemplate(dataSource);
}
// JDBC-backed implementations of the methods on the CorporateEventDao follow...
}- 用@Repository注释类。
- 使用@Autowired注解数据源setter方法。
- 使用数据源创建一个新的JdbcTemplate。
下面的例子展示了相应的XML配置:
如果您使用Spring的JdbcDaoSupport类,并且您的各种jdbc支持的DAO类都是从它扩展而来,那么您的子类将继承来自JdbcDaoSupport类的setDataSource(..)方法。您可以选择是否从该类继承。提供JdbcDaoSupport类只是为了方便。
无论您选择使用(或不使用)上述哪一种模板初始化样式,在每次希望运行SQL时都很少需要创建JdbcTemplate类的新实例。配置之后,JdbcTemplate实例就是线程安全的。如果您的应用程序访问多个数据库,您可能需要多个JdbcTemplate实例,这需要多个数据源,然后需要多个不同配置的JdbcTemplate实例。
3.3.2 使用NamedParameterJdbcTemplate
NamedParameterJdbcTemplate类通过使用命名参数来增加对JDBC语句编程的支持,而不是仅使用传统占位符('?')参数来编写JDBC语句。NamedParameterJdbcTemplate类包装了一个JdbcTemplate并将其委托给包装好的JdbcTemplate来完成其大部分工作。本节只描述NamedParameterJdbcTemplate类中与JdbcTemplate本身不同的部分—即通过使用命名参数来编写JDBC语句。下面的例子展示了如何使用NamedParameterJdbcTemplate:
// some JDBC-backed DAO class...
private NamedParameterJdbcTemplate namedParameterJdbcTemplate;
public void setDataSource(DataSource dataSource) {
this.namedParameterJdbcTemplate = new NamedParameterJdbcTemplate(dataSource);
}
public int countOfActorsByFirstName(String firstName) {
String sql = "select count(*) from T_ACTOR where first_name = :first_name";
SqlParameterSource namedParameters = new MapSqlParameterSource("first_name", firstName);
return this.namedParameterJdbcTemplate.queryForObject(sql, namedParameters, Integer.class);
}注意,在分配给sql变量的值和插入到namedParameters变量(类型为MapSqlParameterSource)的对应值中使用了命名参数表示法。
或者,可以使用基于映射的样式将命名参数及其对应的值传递给NamedParameterJdbcTemplate实例。NamedParameterJdbcOperations公开并由NamedParameterJdbcTemplate类实现的其余方法遵循类似的模式,本文不讨论。
下面的例子展示了如何使用基于地图的样式:
// some JDBC-backed DAO class...
private NamedParameterJdbcTemplate namedParameterJdbcTemplate;
public void setDataSource(DataSource dataSource) {
this.namedParameterJdbcTemplate = new NamedParameterJdbcTemplate(dataSource);
}
public int countOfActorsByFirstName(String firstName) {
String sql = "select count(*) from T_ACTOR where first_name = :first_name";
Map namedParameters = Collections.singletonMap("first_name", firstName);
return this.namedParameterJdbcTemplate.queryForObject(sql, namedParameters, Integer.class);
} 与NamedParameterJdbcTemplate(存在于同一个Java包中)相关的一个很好的特性是SqlParameterSource接口。您已经在前面的一个代码片段(MapSqlParameterSource类)中看到了此接口的实现示例。SqlParameterSource是NamedParameterJdbcTemplate的命名参数值的源。MapSqlParameterSource类是一个简单的实现,它是一个围绕java.util的适配器。Map,其中键是参数名,值是参数值。
另一个SqlParameterSource实现是BeanPropertySqlParameterSource类。这个类包装一个任意的JavaBean(即,一个遵循JavaBean约定的类的实例),并使用包装的JavaBean的属性作为命名参数值的源。
下面的例子展示了一个典型的JavaBean:
public class Actor {
private Long id;
private String firstName;
private String lastName;
public String getFirstName() {
return this.firstName;
}
public String getLastName() {
return this.lastName;
}
public Long getId() {
return this.id;
}
// setters omitted...
}下面的示例使用NamedParameterJdbcTemplate返回前一个示例中显示的类成员的计数:
// some JDBC-backed DAO class...
private NamedParameterJdbcTemplate namedParameterJdbcTemplate;
public void setDataSource(DataSource dataSource) {
this.namedParameterJdbcTemplate = new NamedParameterJdbcTemplate(dataSource);
}
public int countOfActors(Actor exampleActor) {
// notice how the named parameters match the properties of the above 'Actor' class
String sql = "select count(*) from T_ACTOR where first_name = :firstName and last_name = :lastName";
SqlParameterSource namedParameters = new BeanPropertySqlParameterSource(exampleActor);
return this.namedParameterJdbcTemplate.queryForObject(sql, namedParameters, Integer.class);
}记住,NamedParameterJdbcTemplate类包装了一个经典的JdbcTemplate模板。如果需要访问包装好的JdbcTemplate实例来访问仅在JdbcTemplate类中出现的功能,那么可以使用getJdbcOperations()方法通过JdbcOperations接口访问包装好的JdbcTemplate。
有关在应用程序上下文中使用NamedParameterJdbcTemplate类的指南,请参阅JdbcTemplate最佳实践。
3.3.3 使用SQLExceptionTranslator
SQLExceptionTranslator是一个由类实现的接口,可以在SQLExceptions和Spring自己的org.springframe .dao之间进行转换。DataAccessException,它与数据访问策略无关。实现可以是通用的(例如,为JDBC使用SQLState代码),也可以是专用的(例如,使用Oracle错误代码),以获得更高的精度。
SQLErrorCodeSQLExceptionTranslator是默认使用的SQLExceptionTranslator的实现。此实现使用特定的供应商代码。它比SQLState实现更精确。错误代码的转换基于JavaBean类型类SQLErrorCodes中的代码。这个类是由一个SQLErrorCodesFactory创建和填充的,它(顾名思义)是一个根据名为sql-error-code .xml的配置文件内容创建SQLErrorCodes的工厂。此文件使用供应商代码填充,并基于从DatabaseMetaData获取的DatabaseProductName。使用您正在使用的实际数据库的代码。
SQLErrorCodeSQLExceptionTranslator按照以下顺序应用匹配规则:
- 由子类实现的任何自定义翻译。通常使用提供的具体SQLErrorCodeSQLExceptionTranslator,因此不适用此规则。它只适用于您实际提供了一个子类实现的情况。
- 作为SQLErrorCodes类的customSqlExceptionTranslator属性提供的SQLExceptionTranslator接口的任何自定义实现。
- 将搜索CustomSQLErrorCodesTranslation类(为SQLErrorCodes类的customtranslate属性提供)的实例列表以查找匹配项。
- 应用错误代码匹配。
- 使用后备翻译器。SQLExceptionSubclassTranslator是默认的回退转换器。如果这个翻译不可用,那么下一个后备翻译器是SQLStateSQLExceptionTranslator。
注意:默认情况下,SQLErrorCodesFactory用于定义错误代码和自定义异常转换。它们在类路径中名为sql-error-codes.xml的文件中查找,匹配的SQLErrorCodes实例根据使用的数据库元数据中的数据库名称定位。
您可以扩展SQLErrorCodeSQLExceptionTranslator,如下面的示例所示:
public class CustomSQLErrorCodesTranslator extends SQLErrorCodeSQLExceptionTranslator {
protected DataAccessException customTranslate(String task, String sql, SQLException sqlEx) {
if (sqlEx.getErrorCode() == -12345) {
return new DeadlockLoserDataAccessException(task, sqlEx);
}
return null;
}
}在前面的示例中,翻译特定的错误代码(-12345),而其他错误则由默认的转换器实现进行翻译。要使用这个自定义转换器,必须通过setExceptionTranslator方法将其传递给JdbcTemplate,并且必须在需要这个转换器的所有数据访问处理中使用这个JdbcTemplate。下面的例子展示了如何使用这个自定义翻译:
private JdbcTemplate jdbcTemplate;
public void setDataSource(DataSource dataSource) {
// create a JdbcTemplate and set data source
this.jdbcTemplate = new JdbcTemplate();
this.jdbcTemplate.setDataSource(dataSource);
// create a custom translator and set the DataSource for the default translation lookup
CustomSQLErrorCodesTranslator tr = new CustomSQLErrorCodesTranslator();
tr.setDataSource(dataSource);
this.jdbcTemplate.setExceptionTranslator(tr);
}
public void updateShippingCharge(long orderId, long pct) {
// use the prepared JdbcTemplate for this update
this.jdbcTemplate.update("update orders" +
" set shipping_charge = shipping_charge * ? / 100" +
" where id = ?", pct, orderId);
}为了在sql-error-code .xml中查找错误代码,向自定义转换器传递一个数据源。
3.3.4 运行报表
运行SQL语句只需要很少的代码。您需要一个数据源和一个JdbcTemplate,包括JdbcTemplate提供的便利方法。下面的例子展示了创建新表的最小但功能完整的类需要包含什么:
import javax.sql.DataSource;
import org.springframework.jdbc.core.JdbcTemplate;
public class ExecuteAStatement {
private JdbcTemplate jdbcTemplate;
public void setDataSource(DataSource dataSource) {
this.jdbcTemplate = new JdbcTemplate(dataSource);
}
public void doExecute() {
this.jdbcTemplate.execute("create table mytable (id integer, name varchar(100))");
}
}3.3.5 运行查询
一些查询方法返回单个值。要从一行中检索一个计数或特定值,可以使用queryForObject(..)。后者将返回的JDBC类型转换为作为参数传入的Java类。如果类型转换无效,则抛出InvalidDataAccessApiUsageException。下面的示例包含两个查询方法,一个用于int,另一个用于查询字符串:
import javax.sql.DataSource;
import org.springframework.jdbc.core.JdbcTemplate;
public class RunAQuery {
private JdbcTemplate jdbcTemplate;
public void setDataSource(DataSource dataSource) {
this.jdbcTemplate = new JdbcTemplate(dataSource);
}
public int getCount() {
return this.jdbcTemplate.queryForObject("select count(*) from mytable", Integer.class);
}
public String getName() {
return this.jdbcTemplate.queryForObject("select name from mytable", String.class);
}
}除了单个结果查询方法之外,还有几个方法为查询返回的每一行返回一个带有条目的列表。最通用的方法是queryForList(..),它返回一个列表,其中每个元素是一个映射,每个列包含一个条目,使用列名作为键。如果在前面的示例中添加一个方法来检索所有行的列表,它可能如下所示:
private JdbcTemplate jdbcTemplate;
public void setDataSource(DataSource dataSource) {
this.jdbcTemplate = new JdbcTemplate(dataSource);
}
public List> getList() {
return this.jdbcTemplate.queryForList("select * from mytable");
} 返回的列表如下:
[{name=Bob, id=1}, {name=Mary, id=2}]3.3.6 更新数据库
下面的示例更新某个主键的列:
import javax.sql.DataSource;
import org.springframework.jdbc.core.JdbcTemplate;
public class ExecuteAnUpdate {
private JdbcTemplate jdbcTemplate;
public void setDataSource(DataSource dataSource) {
this.jdbcTemplate = new JdbcTemplate(dataSource);
}
public void setName(int id, String name) {
this.jdbcTemplate.update("update mytable set name = ? where id = ?", name, id);
}
}在前面的示例中,SQL语句的行参数有占位符。您可以将参数值作为变量传递,或者作为对象数组传递。因此,应该在原语包装器类中显式地包装原语,或者应该使用自动装箱。
3.3.7 获取自动生成的键
update()便利方法支持检索数据库生成的主键。这种支持是JDBC 3.0标准的一部分。详见本规范第13.6章。该方法的第一个参数是PreparedStatementCreator,这是指定所需insert语句的方式。另一个参数是KeyHolder,它包含更新成功返回时生成的密钥。没有标准的单一方法来创建适当的PreparedStatement(这解释了为什么方法签名是这样的)。下面的例子适用于Oracle,但可能不适用于其他平台:
final String INSERT_SQL = "insert into my_test (name) values(?)";
final String name = "Rob";
KeyHolder keyHolder = new GeneratedKeyHolder();
jdbcTemplate.update(
new PreparedStatementCreator() {
public PreparedStatement createPreparedStatement(Connection connection) throws SQLException {
PreparedStatement ps = connection.prepareStatement(INSERT_SQL, new String[] {"id"});
ps.setString(1, name);
return ps;
}
},
keyHolder);
// keyHolder.getKey() now contains the generated key3.4 控制数据库连接
本节将介绍:
-
Using
DataSource -
Using
DataSourceUtils -
Implementing
SmartDataSource -
Extending
AbstractDataSource -
Using
SingleConnectionDataSource -
Using
DriverManagerDataSource -
Using
TransactionAwareDataSourceProxy -
Using
DataSourceTransactionManager
3.4.1. Using DataSource
Spring通过数据源获得到数据库的连接。数据源是JDBC规范的一部分,是一个通用的连接工厂。它允许容器或框架从应用程序代码中隐藏连接池和事务管理问题。作为开发人员,您不需要知道如何连接到数据库的详细信息。这是设置数据源的管理员的责任。您很可能在开发和测试代码时同时担任这两个角色,但是您不必了解如何配置生产数据源。
当您使用Spring的JDBC层时,您可以从JNDI获得数据源,或者您可以使用第三方提供的连接池实现来配置您自己的数据源。流行的实现是Apache Jakarta Commons DBCP和C3P0。Spring发行版中的实现仅用于测试目的,不提供池。
本节使用Spring的DriverManagerDataSource实现,后面将介绍几个其他实现。
注意:您应该只将DriverManagerDataSource类用于测试目的,因为它不提供池,并且在发出一个连接的多个请求时性能很差。
配置一个DriverManagerDataSource:
- 获得与DriverManagerDataSource的连接,就像通常获得JDBC连接一样。
- 指定JDBC驱动程序的完全限定类名,以便驱动程序管理器可以加载驱动程序类。
- 提供一个在JDBC驱动程序之间变化的URL。(有关正确的值,请参阅驱动程序的文档。)
- 提供连接到数据库的用户名和密码。
下面的例子展示了如何在Java中配置一个DriverManagerDataSource:
DriverManagerDataSource dataSource = new DriverManagerDataSource();
dataSource.setDriverClassName("org.hsqldb.jdbcDriver");
dataSource.setUrl("jdbc:hsqldb:hsql://localhost:");
dataSource.setUsername("sa");
dataSource.setPassword("");下面的例子展示了相应的XML配置:
接下来的两个示例展示了DBCP和C3P0的基本连接和配置。要了解更多有助于控制池功能的选项,请参阅相应的连接池实现的产品文档。
下面的例子显示了DBCP配置:
下面的例子显示了C3P0配置:
3.4.2 使用DataSourceUtils
DataSourceUtils类是一个方便而强大的助手类,它提供了从JNDI获取连接的静态方法,并在必要时关闭连接。它支持与DataSourceTransactionManager等线程绑定的连接。
3.4.3 实现SmartDataSource
SmartDataSource接口应该由能够提供到关系数据库连接的类来实现。它扩展了DataSource接口,让使用它的类可以查询给定操作之后是否应该关闭连接。当您知道需要重用一个连接时,这种用法是有效的。
3.4.4 延长AbstractDataSource
AbstractDataSource是Spring数据源实现的抽象基类。它实现对所有数据源实现都通用的代码。如果您编写自己的数据源实现,则应该扩展AbstractDataSource类。
3.4.5 使用SingleConnectionDataSource
SingleConnectionDataSource类是SmartDataSource接口的一个实现,它封装了一个在每次使用后都没有关闭的连接。这不是多线程的能力。
如果任何客户机代码调用都是基于池连接的假设(如使用持久性工具时),那么应该将suppressClose属性设置为true。此设置返回一个封装物理连接的关闭抑制代理。注意,您不能再将此转换为本机Oracle连接或类似对象。
SingleConnectionDataSource主要是一个测试类。例如,它支持与简单的JNDI环境一起在应用服务器外部轻松地测试代码。与DriverManagerDataSource不同,它始终重用相同的连接,避免过多地创建物理连接。
3.4.6 使用DriverManagerDataSource
DriverManagerDataSource类是标准DataSource接口的实现,它通过bean属性配置普通JDBC驱动程序,每次都返回一个新连接。
此实现对于Java EE容器外部的测试和独立环境非常有用,可以作为Spring IoC容器中的数据源bean,也可以与简单的JNDI环境结合使用。close()调用close连接,因此任何数据源感知的持久性代码都可以工作。然而,使用javabean风格的连接池(例如commons-dbcp)非常简单,甚至在测试环境中也是如此,因此在DriverManagerDataSource上使用这样的连接池几乎总是可取的。
3.4.7 使用TransactionAwareDataSourceProxy
TransactionAwareDataSourceProxy是目标数据源的代理。代理包装了目标数据源,以增加对spring管理的事务的感知。在这方面,它类似于Java EE服务器提供的事务性JNDI数据源。
注意:很少需要使用这个类,除非已经存在的代码必须被调用并传递一个标准的JDBC数据源接口实现。在这种情况下,您仍然可以让这些代码可用,同时让这些代码参与Spring管理的事务。通过使用更高级别的资源管理抽象(如JdbcTemplate或DataSourceUtils)来编写自己的新代码通常是更好的选择。
有关详细信息,请参阅TransactionAwareDataSourceProxy javadoc。
3.4.8。使用DataSourceTransactionManager
DataSourceTransactionManager类是单个JDBC数据源的平台transactionmanager实现。它将指定数据源的JDBC连接绑定到当前执行的线程,这可能允许每个数据源有一个线程连接。
要通过datasourceutil . getconnection (DataSource)而不是Java EE的标准DataSource. getconnection检索JDBC连接,需要应用程序代码。它抛出未检查的org.springframework。dao异常,而不是已检查的SQLExceptions。所有框架类(如JdbcTemplate)都隐式地使用此策略。如果没有与此事务管理器一起使用,则查找策略的行为与普通策略完全相同。因此,它可以在任何情况下使用。
DataSourceTransactionManager类支持作为适当的JDBC语句查询超时应用的自定义隔离级别和超时。要支持后一种方法,应用程序代码必须使用JdbcTemplate或为每个创建的语句调用datasourceutil . applytransactiontimeout(..)方法。
在单资源的情况下,您可以使用这个实现代替JtaTransactionManager,因为它不需要容器来支持JTA。如果您坚持使用所需的连接查找模式,则在两者之间进行切换只是配置问题。JTA不支持自定义隔离级别。
3.5 JDBC批处理操作
如果您批量处理对同一预备语句的多个调用,大多数JDBC驱动程序都可以提供更好的性能。通过将更新分组为批,可以限制到数据库的往返次数。
3.5.1 使用JdbcTemplate进行基本的批处理操作
通过实现一个特殊接口的两个方法BatchPreparedStatementSetter来完成JdbcTemplate批处理,并将该实现作为batchUpdate方法调用中的第二个参数传递。您可以使用getBatchSize方法来提供当前批处理的大小。可以使用setValues方法设置准备好的语句的参数值。调用此方法的次数是在getBatchSize调用中指定的次数。下面的示例根据列表中的条目更新actor表,整个列表用作批处理:
public class JdbcActorDao implements ActorDao {
private JdbcTemplate jdbcTemplate;
public void setDataSource(DataSource dataSource) {
this.jdbcTemplate = new JdbcTemplate(dataSource);
}
public int[] batchUpdate(final List actors) {
return this.jdbcTemplate.batchUpdate(
"update t_actor set first_name = ?, last_name = ? where id = ?",
new BatchPreparedStatementSetter() {
public void setValues(PreparedStatement ps, int i) throws SQLException {
Actor actor = actors.get(i);
ps.setString(1, actor.getFirstName());
ps.setString(2, actor.getLastName());
ps.setLong(3, actor.getId().longValue());
}
public int getBatchSize() {
return actors.size();
}
});
}
// ... additional methods
} 如果您处理更新流或从文件读取数据,您可能有一个首选的批大小,但最后一批可能没有那么多的条目。在这种情况下,您可以使用InterruptibleBatchPreparedStatementSetter接口,它允许您在输入源耗尽后中断批处理。isbatch方法允许您发出批处理结束的信号。
3.5.2 使用对象列表进行批处理操作
JdbcTemplate和NamedParameterJdbcTemplate都提供了提供批量更新的替代方法。不需要实现特殊的批处理接口,而是将调用中的所有参数值作为列表提供。框架循环遍历这些值并使用内部准备好的语句setter。根据是否使用命名参数,API会有所不同。对于已命名的参数,您提供一个SqlParameterSource数组,其中每个成员有一个条目。您可以使用SqlParameterSourceUtils。createBatch方便的方法来创建这个数组,传入一个bean样式的对象数组(带有与参数相对应的getter方法),字符串键控的映射实例(包含作为值的相应参数),或者两者混合。
下面的例子显示了一个使用命名参数的批量更新:
public class JdbcActorDao implements ActorDao {
private NamedParameterTemplate namedParameterJdbcTemplate;
public void setDataSource(DataSource dataSource) {
this.namedParameterJdbcTemplate = new NamedParameterJdbcTemplate(dataSource);
}
public int[] batchUpdate(List actors) {
return this.namedParameterJdbcTemplate.batchUpdate(
"update t_actor set first_name = :firstName, last_name = :lastName where id = :id",
SqlParameterSourceUtils.createBatch(actors));
}
// ... additional methods
} 对于使用classic的SQL语句?占位符,传递一个包含对象数组和更新值的列表。对于SQL语句中的每个占位符,这个对象数组必须有一个条目,并且它们必须与SQL语句中定义的顺序相同。
下面的示例与前面的示例相同,不同之处是它使用了经典JDBC ?占位符:
public class JdbcActorDao implements ActorDao {
private JdbcTemplate jdbcTemplate;
public void setDataSource(DataSource dataSource) {
this.jdbcTemplate = new JdbcTemplate(dataSource);
}
public int[] batchUpdate(final List actors) {
List batch = new ArrayList();
for (Actor actor : actors) {
Object[] values = new Object[] {
actor.getFirstName(), actor.getLastName(), actor.getId()};
batch.add(values);
}
return this.jdbcTemplate.batchUpdate(
"update t_actor set first_name = ?, last_name = ? where id = ?",
batch);
}
// ... additional methods
} 我们前面描述的所有批处理更新方法都返回一个int数组,其中包含每个批处理条目的受影响行数。这个计数由JDBC驱动程序报告。如果计数不可用,JDBC驱动程序将返回一个-2值。
注意:在这种情况下,通过在底层PreparedStatement上自动设置值,需要从给定的Java类型派生出每个值的对应JDBC类型。虽然这通常工作得很好,但也存在潜在的问题(例如,使用包含映射的空值)。默认情况下,Spring调用参数元数据。在这种情况下,getParameterType对于JDBC驱动程序来说非常昂贵。您应该使用最新的驱动程序版本,并考虑设置spring.jdbc.getParameterType。忽略属性为true(作为JVM系统属性或在spring中)。如果您遇到性能问题—例如,如Oracle 12c (sprl -16139)报告的那样。
或者,您可能会考虑显式地指定相应的JDBC类型,通过“BatchPreparedStatementSetter”(如图所示),通过显式类型数组给基于“列表< Object[] >”,通过“registerSqlType”自定义“MapSqlParameterSource”实例上调用,或通过“BeanPropertySqlParameterSource”SQL类型来自Java-declared属性类型即使对于一个null值。
3.5.3 具有多个批次的批处理操作
前面的批处理更新示例处理的批非常大,您希望将它们分成几个较小的批。您可以通过多次调用batchUpdate方法来使用前面提到的方法,但是现在有一个更方便的方法。除了SQL语句外,此方法还使用包含参数的对象集合、每个批处理的更新次数和ParameterizedPreparedStatementSetter来设置准备好的语句的参数值。框架循环遍历提供的值,并将更新调用分成指定大小的批。
下面的例子展示了一个批量更新,它使用的批量大小为100:
public class JdbcActorDao implements ActorDao {
private JdbcTemplate jdbcTemplate;
public void setDataSource(DataSource dataSource) {
this.jdbcTemplate = new JdbcTemplate(dataSource);
}
public int[][] batchUpdate(final Collection actors) {
int[][] updateCounts = jdbcTemplate.batchUpdate(
"update t_actor set first_name = ?, last_name = ? where id = ?",
actors,
100,
new ParameterizedPreparedStatementSetter() {
public void setValues(PreparedStatement ps, Actor argument) throws SQLException {
ps.setString(1, argument.getFirstName());
ps.setString(2, argument.getLastName());
ps.setLong(3, argument.getId().longValue());
}
});
return updateCounts;
}
// ... additional methods
} 此调用的批处理更新方法返回一个int数组,其中包含每个批处理的一个数组条目,以及每个更新的受影响行数的数组。第一级数组的长度表示执行的批数,第二级数组的长度表示该批中的更新数。每个批中的更新数量应该是为所有批提供的批大小(最后一个批大小可能更小),这取决于所提供的更新对象的总数。每个更新语句的更新计数是JDBC驱动程序报告的更新计数。如果计数不可用,JDBC驱动程序将返回一个-2值。
3.6 使用SimpleJdbc类简化JDBC操作
SimpleJdbcInsert和SimpleJdbcCall类通过利用可以通过JDBC驱动程序检索的数据库元数据来提供简化的配置。这意味着您需要预先配置的内容更少,尽管如果希望在代码中提供所有细节,您可以覆盖或关闭元数据处理。
3.6.1。使用SimpleJdbcInsert插入数据
我们首先查看带有最少配置选项的SimpleJdbcInsert类。您应该在数据访问层的初始化方法中实例化SimpleJdbcInsert。对于本例,初始化方法是setDataSource方法。您不需要子类化SimpleJdbcInsert类。相反,您可以创建一个新实例,并使用withTableName方法设置表名。该类的配置方法遵循返回SimpleJdbcInsert实例的流体样式,该实例允许您链接所有配置方法。下面的示例只使用了一种配置方法(稍后我们将展示多种方法的示例):
public class JdbcActorDao implements ActorDao {
private SimpleJdbcInsert insertActor;
public void setDataSource(DataSource dataSource) {
this.insertActor = new SimpleJdbcInsert(dataSource).withTableName("t_actor");
}
public void add(Actor actor) {
Map parameters = new HashMap(3);
parameters.put("id", actor.getId());
parameters.put("first_name", actor.getFirstName());
parameters.put("last_name", actor.getLastName());
insertActor.execute(parameters);
}
// ... additional methods
} 这里使用的execute方法采用普通java.util。Map是它唯一的参数。这里需要注意的重要一点是,用于映射的键必须与数据库中定义的表的列名匹配。这是因为我们读取元数据来构造实际的insert语句。
3.6.2 使用SimpleJdbcInsert检索自动生成的密钥
下一个示例使用与前一个示例相同的insert,但是它检索自动生成的密钥并将其设置在新的Actor对象上,而不是传递id。当它创建SimpleJdbcInsert时,除了指定表名之外,它还使用usingGeneratedKeyColumns方法指定生成的键列的名称。下面的清单展示了它是如何工作的:
public class JdbcActorDao implements ActorDao {
private SimpleJdbcInsert insertActor;
public void setDataSource(DataSource dataSource) {
this.insertActor = new SimpleJdbcInsert(dataSource)
.withTableName("t_actor")
.usingGeneratedKeyColumns("id");
}
public void add(Actor actor) {
Map parameters = new HashMap(2);
parameters.put("first_name", actor.getFirstName());
parameters.put("last_name", actor.getLastName());
Number newId = insertActor.executeAndReturnKey(parameters);
actor.setId(newId.longValue());
}
// ... additional methods
} 使用第二种方法运行插入时的主要区别是,不向映射添加id,而是调用executeAndReturnKey方法。这将返回java.lang。对象,您可以使用该对象创建在域类中使用的数值类型的实例。在这里,您不能依赖所有数据库来返回特定的Java类。. lang。Number是您可以依赖的基类。如果您有多个自动生成的列,或者生成的值是非数值的,那么您可以使用从executeAndReturnKeyHolder方法返回的KeyHolder。
3.6.3。为SimpleJdbcInsert指定列
您可以通过使用usingColumns方法指定列名列表来限制插入的列,如下面的示例所示:
public class JdbcActorDao implements ActorDao {
private SimpleJdbcInsert insertActor;
public void setDataSource(DataSource dataSource) {
this.insertActor = new SimpleJdbcInsert(dataSource)
.withTableName("t_actor")
.usingColumns("first_name", "last_name")
.usingGeneratedKeyColumns("id");
}
public void add(Actor actor) {
Map parameters = new HashMap(2);
parameters.put("first_name", actor.getFirstName());
parameters.put("last_name", actor.getLastName());
Number newId = insertActor.executeAndReturnKey(parameters);
actor.setId(newId.longValue());
}
// ... additional methods
} 插入的执行与依赖元数据来决定使用哪些列是一样的。
3.6.4。使用SqlParameterSource提供参数值
使用映射来提供参数值工作得很好,但是它不是最方便使用的类。Spring提供了SqlParameterSource接口的两个实现,您可以使用它们。第一个是BeanPropertySqlParameterSource,如果您有一个兼容javabean的类,其中包含您的值,那么它是一个非常方便的类。它使用相应的getter方法来提取参数值。下面的例子展示了如何使用BeanPropertySqlParameterSource:
public class JdbcActorDao implements ActorDao {
private SimpleJdbcInsert insertActor;
public void setDataSource(DataSource dataSource) {
this.insertActor = new SimpleJdbcInsert(dataSource)
.withTableName("t_actor")
.usingGeneratedKeyColumns("id");
}
public void add(Actor actor) {
SqlParameterSource parameters = new BeanPropertySqlParameterSource(actor);
Number newId = insertActor.executeAndReturnKey(parameters);
actor.setId(newId.longValue());
}
// ... additional methods
}另一个选项是MapSqlParameterSource,它类似于映射,但提供了更方便的addValue方法,可以将其链接起来。下面的例子展示了如何使用它:
public class JdbcActorDao implements ActorDao {
private SimpleJdbcInsert insertActor;
public void setDataSource(DataSource dataSource) {
this.insertActor = new SimpleJdbcInsert(dataSource)
.withTableName("t_actor")
.usingGeneratedKeyColumns("id");
}
public void add(Actor actor) {
SqlParameterSource parameters = new MapSqlParameterSource()
.addValue("first_name", actor.getFirstName())
.addValue("last_name", actor.getLastName());
Number newId = insertActor.executeAndReturnKey(parameters);
actor.setId(newId.longValue());
}
// ... additional methods
}正如您所看到的,配置是相同的。只有执行中的代码需要更改才能使用这些替代输入类。
3.6.5 使用SimpleJdbcCall调用存储过程
SimpleJdbcCall类使用数据库中的元数据来查找in和out参数的名称,这样您就不必显式地声明它们。您可以声明参数,如果您愿意这样做,或者如果您有参数(例如数组或结构)没有自动映射到Java类的话。第一个示例展示了一个简单的过程,该过程仅从MySQL数据库返回VARCHAR和日期格式的标量值。示例过程读取指定的actor条目,并以out参数的形式返回first_name、last_name和birth_date列。下面的清单显示了第一个例子:
CREATE PROCEDURE read_actor (
IN in_id INTEGER,
OUT out_first_name VARCHAR(100),
OUT out_last_name VARCHAR(100),
OUT out_birth_date DATE)
BEGIN
SELECT first_name, last_name, birth_date
INTO out_first_name, out_last_name, out_birth_date
FROM t_actor where id = in_id;
END;in_id参数包含您正在查找的参与者的id。out参数返回从表中读取的数据。
您可以以类似于声明SimpleJdbcInsert的方式声明SimpleJdbcCall。您应该在数据访问层的初始化方法中实例化和配置该类。与StoredProcedure类相比,您不需要创建子类,也不需要声明可以在数据库元数据中查找的参数。下面的SimpleJdbcCall配置示例使用前面的存储过程(除了数据源之外,惟一的配置选项是存储过程的名称):
public class JdbcActorDao implements ActorDao {
private SimpleJdbcCall procReadActor;
public void setDataSource(DataSource dataSource) {
this.procReadActor = new SimpleJdbcCall(dataSource)
.withProcedureName("read_actor");
}
public Actor readActor(Long id) {
SqlParameterSource in = new MapSqlParameterSource()
.addValue("in_id", id);
Map out = procReadActor.execute(in);
Actor actor = new Actor();
actor.setId(id);
actor.setFirstName((String) out.get("out_first_name"));
actor.setLastName((String) out.get("out_last_name"));
actor.setBirthDate((Date) out.get("out_birth_date"));
return actor;
}
// ... additional methods
}为执行调用而编写的代码涉及创建一个包含IN参数的SqlParameterSource。必须将为输入值提供的名称与存储过程中声明的参数名称相匹配。这种情况不需要匹配,因为您使用元数据来确定如何在存储过程中引用数据库对象。在源中为存储过程指定的不一定是存储在数据库中的方式。一些数据库将名称转换为全大写,而其他数据库使用小写或指定的大小写。
execute方法接受IN参数并返回一个映射,其中包含按名称键控的所有out参数,如存储过程中指定的那样。在本例中,它们是out_first_name、out_last_name和out_birth_date。
execute方法的最后一部分创建一个Actor实例,用于返回检索到的数据。同样,在存储过程中声明out参数时使用它们的名称也很重要。此外,存储在结果映射中的out参数名称的大小写与数据库中的out参数名称的大小写相匹配,而数据库之间的out参数名称可能有所不同。为了使您的代码更具可移植性,您应该执行不区分大小写的查找,或者指示Spring使用LinkedCaseInsensitiveMap。要实现后者,您可以创建自己的JdbcTemplate并将setResultsMapCaseInsensitive属性设置为true。然后可以将这个定制的JdbcTemplate实例传递到SimpleJdbcCall的构造函数中。下面的例子显示了这种配置:
public class JdbcActorDao implements ActorDao {
private SimpleJdbcCall procReadActor;
public void setDataSource(DataSource dataSource) {
JdbcTemplate jdbcTemplate = new JdbcTemplate(dataSource);
jdbcTemplate.setResultsMapCaseInsensitive(true);
this.procReadActor = new SimpleJdbcCall(jdbcTemplate)
.withProcedureName("read_actor");
}
// ... additional methods
}通过执行此操作,可以避免在使用返回的out参数的名称时出现冲突。
3.6.6 显式声明SimpleJdbcCall使用的参数
在本章的前面,我们描述了如何从元数据推导参数,但是如果愿意,您可以显式地声明它们。您可以通过使用declareParameters方法创建和配置SimpleJdbcCall来实现这一点,该方法将可变数量的SqlParameter对象作为输入。有关如何定义SqlParameter的详细信息,请参阅下一节。
注意:如果使用的数据库不是spring支持的数据库,则需要显式声明。目前,Spring支持以下数据库的存储过程调用的元数据查询:Apache Derby、DB2、MySQL、Microsoft SQL Server、Oracle和Sybase。我们还支持MySQL、Microsoft SQL Server和Oracle存储函数的元数据查询。
您可以选择显式地声明一个、一些或所有参数。在没有显式声明参数的情况下,仍然使用参数元数据。要绕过对潜在参数的所有元数据查找处理,只使用声明的参数,可以调用方法withoutprocedure recolumnmetadataaccess作为声明的一部分。假设您为一个数据库函数声明了两个或多个不同的调用签名。在这种情况下,您可以调用useInParameterNames来指定要包含给定签名的参数名称列表。
下面的例子展示了一个完整声明的过程调用,并使用了来自前一个例子的信息:
public class JdbcActorDao implements ActorDao {
private SimpleJdbcCall procReadActor;
public void setDataSource(DataSource dataSource) {
JdbcTemplate jdbcTemplate = new JdbcTemplate(dataSource);
jdbcTemplate.setResultsMapCaseInsensitive(true);
this.procReadActor = new SimpleJdbcCall(jdbcTemplate)
.withProcedureName("read_actor")
.withoutProcedureColumnMetaDataAccess()
.useInParameterNames("in_id")
.declareParameters(
new SqlParameter("in_id", Types.NUMERIC),
new SqlOutParameter("out_first_name", Types.VARCHAR),
new SqlOutParameter("out_last_name", Types.VARCHAR),
new SqlOutParameter("out_birth_date", Types.DATE)
);
}
// ... additional methods
}这两个示例的执行和最终结果是相同的。第二个示例显式地指定所有细节,而不是依赖于元数据。
3.6.7 如何定义SqlParameters
要为SimpleJdbc类和RDBMS操作类(在将JDBC操作建模为Java对象中涉及到)定义一个参数,可以使用SqlParameter或它的一个子类。为此,通常要在构造函数中指定参数名称和SQL类型。SQL类型是通过使用java.sql指定的。类型的常量。在本章的前面,我们看到了类似以下的声明:
new SqlParameter("in_id", Types.NUMERIC),
new SqlOutParameter("out_first_name", Types.VARCHAR),带有SqlParameter的第一行声明了一个IN参数。通过使用SqlQuery及其子类(在理解SqlQuery中有所涉及),可以在存储过程调用和查询中使用参数。
第二行(带有SqlOutParameter)声明一个out参数,用于存储过程调用。InOut参数还有一个SqlInOutParameter(为过程提供IN值并返回值的参数)。
注意:只有声明为SqlParameter和SqlInOutParameter的参数才用于提供输入值。这与StoredProcedure类不同,后者(出于向后兼容的原因)允许为声明为SqlOutParameter的参数提供输入值。
对于IN参数,除了名称和SQL类型外,还可以为数字数据指定比例,或为自定义数据库类型指定类型名称。对于out参数,您可以提供一个行映射器来处理从REF游标返回的行映射。另一个选项是指定SqlReturnType,它提供了一个机会来定义对返回值的自定义处理。
3.6.8 使用SimpleJdbcCall调用存储函数
您可以以几乎与调用存储过程相同的方式调用存储函数,只不过提供的是函数名而不是过程名。您可以使用withFunctionName方法作为配置的一部分,以指示您想要对一个函数进行调用,并生成相应的函数调用字符串。专门的执行调用(executeFunction)用于执行函数,它将函数返回值作为指定类型的对象返回,这意味着不必从结果映射中检索返回值。对于只有一个out参数的存储过程,也可以使用类似的便利方法(名为executeObject)。下面的示例(对于MySQL)基于一个名为get_actor_name的存储函数,该函数返回一个参与者的全名:
CREATE FUNCTION get_actor_name (in_id INTEGER)
RETURNS VARCHAR(200) READS SQL DATA
BEGIN
DECLARE out_name VARCHAR(200);
SELECT concat(first_name, ' ', last_name)
INTO out_name
FROM t_actor where id = in_id;
RETURN out_name;
END;为了调用这个函数,我们再次在初始化方法中创建一个SimpleJdbcCall,如下面的示例所示:
public class JdbcActorDao implements ActorDao {
private JdbcTemplate jdbcTemplate;
private SimpleJdbcCall funcGetActorName;
public void setDataSource(DataSource dataSource) {
this.jdbcTemplate = new JdbcTemplate(dataSource);
JdbcTemplate jdbcTemplate = new JdbcTemplate(dataSource);
jdbcTemplate.setResultsMapCaseInsensitive(true);
this.funcGetActorName = new SimpleJdbcCall(jdbcTemplate)
.withFunctionName("get_actor_name");
}
public String getActorName(Long id) {
SqlParameterSource in = new MapSqlParameterSource()
.addValue("in_id", id);
String name = funcGetActorName.executeFunction(String.class, in);
return name;
}
// ... additional methods
}使用的executeFunction方法返回一个字符串,该字符串包含函数调用的返回值。
3.6.9。从SimpleJdbcCall返回ResultSet或REF游标
调用返回结果集的存储过程或函数有点棘手。一些数据库在JDBC结果处理期间返回结果集,而另一些则需要显式注册特定类型的out参数。这两种方法都需要额外的处理来遍历结果集并处理返回的行。使用SimpleJdbcCall,您可以使用returningResultSet方法,并声明一个用于特定参数的行映射器实现。如果在结果处理期间返回结果集,则没有定义名称,因此返回的结果必须与声明RowMapper实现的顺序匹配。指定的名称仍然用于将处理过的结果列表存储在从execute语句返回的结果映射中。
下一个例子(对于MySQL)使用了一个存储过程,它不接受参数,并返回t_actor表中的所有行:
CREATE PROCEDURE read_all_actors()
BEGIN
SELECT a.id, a.first_name, a.last_name, a.birth_date FROM t_actor a;
END;要调用此过程,可以声明行映射器。因为要映射到的类遵循JavaBean规则,所以可以使用BeanPropertyRowMapper,它是通过在newInstance方法中传递需要映射到的类而创建的。下面的例子演示了如何做到这一点:
public class JdbcActorDao implements ActorDao {
private SimpleJdbcCall procReadAllActors;
public void setDataSource(DataSource dataSource) {
JdbcTemplate jdbcTemplate = new JdbcTemplate(dataSource);
jdbcTemplate.setResultsMapCaseInsensitive(true);
this.procReadAllActors = new SimpleJdbcCall(jdbcTemplate)
.withProcedureName("read_all_actors")
.returningResultSet("actors",
BeanPropertyRowMapper.newInstance(Actor.class));
}
public List getActorsList() {
Map m = procReadAllActors.execute(new HashMap(0));
return (List) m.get("actors");
}
// ... additional methods
} execute调用传递一个空映射,因为这个调用不接受任何参数。然后从结果映射检索参与者列表并返回给调用者。
3.7 将JDBC操作建模为Java对象
org.springframework.jdbc。object package包含一些类,这些类允许您以一种更面向对象的方式访问数据库。例如,您可以执行查询并将结果作为包含业务对象的列表返回,其中关系列数据映射到业务对象的属性。您还可以运行存储过程和运行更新、删除和插入语句。
注意:许多Spring开发人员认为,下面描述的各种RDBMS操作类(StoredProcedure类除外)通常可以用直接的JdbcTemplate调用替换。通常,直接调用JdbcTemplate上的方法的DAO方法更简单(与将查询封装为完整的类相反)。
但是,如果您从使用RDBMS操作类中获得可度量的价值,那么您应该继续使用这些类。
3.7.1。理解SqlQuery
SqlQuery是一个可重用的、线程安全的类,它封装了一个SQL查询。子类必须实现newRowMapper(..)方法,以提供一个RowMapper实例,该实例可以在查询执行期间创建的ResultSet上迭代获得的每一行中创建一个对象。SqlQuery类很少直接使用,因为MappingSqlQuery子类为将行映射到Java类提供了更方便的实现。扩展SqlQuery的其他实现有MappingSqlQueryWithParameters和UpdatableSqlQuery。
3.7.2章。使用MappingSqlQuery
MappingSqlQuery是一个可重用的查询,具体的子类必须实现抽象的mapRow(..)方法来将提供的ResultSet的每一行转换成指定类型的对象。下面的示例显示了一个自定义查询,该查询将来自t_actor关系的数据映射到Actor类的一个实例:
public class ActorMappingQuery extends MappingSqlQuery {
public ActorMappingQuery(DataSource ds) {
super(ds, "select id, first_name, last_name from t_actor where id = ?");
declareParameter(new SqlParameter("id", Types.INTEGER));
compile();
}
@Override
protected Actor mapRow(ResultSet rs, int rowNumber) throws SQLException {
Actor actor = new Actor();
actor.setId(rs.getLong("id"));
actor.setFirstName(rs.getString("first_name"));
actor.setLastName(rs.getString("last_name"));
return actor;
}
} 该类使用Actor类型扩展了参数化的MappingSqlQuery。此客户查询的构造函数将数据源作为惟一的参数。在这个构造函数中,可以使用DataSource调用超类的构造函数,并调用应该执行的SQL来检索此查询的行。此SQL用于创建PreparedStatement,因此它可能包含占位符,用于在执行期间传入的任何参数。您必须使用传递SqlParameter的declareParameter方法来声明每个参数。SqlParameter接受名称和java.sql.Types中定义的JDBC类型。在定义所有参数之后,可以调用compile()方法,以便准备语句并稍后运行。该类在编译后是线程安全的,因此,只要在初始化DAO时创建了这些实例,就可以将它们作为实例变量保存并重用。下面的例子展示了如何定义这样一个类:
private ActorMappingQuery actorMappingQuery;
@Autowired
public void setDataSource(DataSource dataSource) {
this.actorMappingQuery = new ActorMappingQuery(dataSource);
}
public Customer getCustomer(Long id) {
return actorMappingQuery.findObject(id);
}前面示例中的方法检索具有作为惟一参数传入的id的客户。因为我们只想返回一个对象,所以我们调用了id作为参数的findObject便利方法。如果我们有一个返回对象列表并获取额外参数的查询,那么我们将使用其中一个execute方法,该方法获取作为varargs传递的参数值数组。下面的例子展示了这样一个方法:
public List searchForActors(int age, String namePattern) {
List actors = actorSearchMappingQuery.execute(age, namePattern);
return actors;
} 3.7.3。使用SqlUpdate
SqlUpdate类封装了一个SQL更新。与查询一样,更新对象是可重用的,并且与所有RdbmsOperation类一样,更新可以有参数,并且是在SQL中定义的。这个类提供了许多类似于查询对象的execute(..)方法的update(..)方法。SQLUpdate类是具体的。它可以被子类化——例如,添加一个自定义更新方法。但是,您不必子类化SqlUpdate类,因为可以通过设置SQL和声明参数轻松地对它进行参数化。下面的示例创建了一个名为execute的自定义更新方法:
import java.sql.Types;
import javax.sql.DataSource;
import org.springframework.jdbc.core.SqlParameter;
import org.springframework.jdbc.object.SqlUpdate;
public class UpdateCreditRating extends SqlUpdate {
public UpdateCreditRating(DataSource ds) {
setDataSource(ds);
setSql("update customer set credit_rating = ? where id = ?");
declareParameter(new SqlParameter("creditRating", Types.NUMERIC));
declareParameter(new SqlParameter("id", Types.NUMERIC));
compile();
}
/**
* @param id for the Customer to be updated
* @param rating the new value for credit rating
* @return number of rows updated
*/
public int execute(int id, int rating) {
return update(rating, id);
}
}3.7.4。使用StoredProcedure
StoredProcedure类是用于RDBMS存储过程的对象抽象的超类。
该类是抽象的,它的各种execute(..)方法具有保护访问权限,除了通过提供更严格的类型的子类之外,还可以防止使用其他方法。
继承的sql属性是RDBMS中存储过程的名称。
要为StoredProcedure类定义参数,可以使用SqlParameter或它的一个子类。您必须在构造函数中指定参数名和SQL类型,如下面的代码片段所示:
new SqlParameter("in_id", Types.NUMERIC),
new SqlOutParameter("out_first_name", Types.VARCHAR),SQL类型是使用java.sql指定的。类型的常量。
第一行(带有SqlParameter)声明了一个IN参数。可以在参数中使用存储过程调用和使用SqlQuery及其子类(在理解SqlQuery中涉及)的查询。
第二行(带有SqlOutParameter)声明一个out参数,用于存储过程调用。InOut参数还有一个SqlInOutParameter(为过程提供in值并返回值的参数)。
对于in参数,除了名称和SQL类型外,还可以为数字数据指定比例,或为自定义数据库类型指定类型名称。对于out参数,您可以提供一个行映射器来处理从REF游标返回的行映射。另一个选项是指定SqlReturnType,它允许您定义对返回值的自定义处理。
下一个简单DAO示例使用StoredProcedure调用函数(sysdate()),该函数随任何Oracle数据库一起提供。要使用存储过程功能,您必须创建一个扩展StoredProcedure的类。在本例中,StoredProcedure类是一个内部类。但是,如果需要重用StoredProcedure,可以将其声明为顶级类。这个示例没有输入参数,但是通过使用SqlOutParameter类将输出参数声明为日期类型。execute()方法运行这个过程,并从结果映射中提取返回的日期。通过使用参数名作为键,结果映射的每个声明的输出参数都有一个条目(在本例中只有一个)。下面的清单显示了我们自定义的StoredProcedure类:
import java.sql.Types;
import java.util.Date;
import java.util.HashMap;
import java.util.Map;
import javax.sql.DataSource;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.jdbc.core.SqlOutParameter;
import org.springframework.jdbc.object.StoredProcedure;
public class StoredProcedureDao {
private GetSysdateProcedure getSysdate;
@Autowired
public void init(DataSource dataSource) {
this.getSysdate = new GetSysdateProcedure(dataSource);
}
public Date getSysdate() {
return getSysdate.execute();
}
private class GetSysdateProcedure extends StoredProcedure {
private static final String SQL = "sysdate";
public GetSysdateProcedure(DataSource dataSource) {
setDataSource(dataSource);
setFunction(true);
setSql(SQL);
declareParameter(new SqlOutParameter("date", Types.DATE));
compile();
}
public Date execute() {
// the 'sysdate' sproc has no input parameters, so an empty Map is supplied...
Map results = execute(new HashMap());
Date sysdate = (Date) results.get("date");
return sysdate;
}
}
} 下面的StoredProcedure示例有两个输出参数(在本例中是Oracle REF游标):
import java.util.HashMap;
import java.util.Map;
import javax.sql.DataSource;
import oracle.jdbc.OracleTypes;
import org.springframework.jdbc.core.SqlOutParameter;
import org.springframework.jdbc.object.StoredProcedure;
public class TitlesAndGenresStoredProcedure extends StoredProcedure {
private static final String SPROC_NAME = "AllTitlesAndGenres";
public TitlesAndGenresStoredProcedure(DataSource dataSource) {
super(dataSource, SPROC_NAME);
declareParameter(new SqlOutParameter("titles", OracleTypes.CURSOR, new TitleMapper()));
declareParameter(new SqlOutParameter("genres", OracleTypes.CURSOR, new GenreMapper()));
compile();
}
public Map execute() {
// again, this sproc has no input parameters, so an empty Map is supplied
return super.execute(new HashMap());
}
} 注意,在TitlesAndGenresStoredProcedure构造函数中使用的declareParameter(..)方法的重载变体是如何被传递给RowMapper实现实例的。这是一种非常方便和强大的重用现有功能的方法。下面的两个示例提供了两种RowMapper实现的代码。
TitleMapper类为提供的ResultSet中的每一行将一个ResultSet映射到一个Title域对象,如下所示:
import java.sql.ResultSet;
import java.sql.SQLException;
import com.foo.domain.Title;
import org.springframework.jdbc.core.RowMapper;
public final class TitleMapper implements RowMapper {
public Title mapRow(ResultSet rs, int rowNum) throws SQLException {
Title title = new Title();
title.setId(rs.getLong("id"));
title.setName(rs.getString("name"));
return title;
}
}</code></pre>
<p>GenreMapper类为提供的ResultSet中的每一行将一个ResultSet映射到一个类型域对象,如下所示:</p>
<pre class="has"><code>import java.sql.ResultSet;
import java.sql.SQLException;
import com.foo.domain.Genre;
import org.springframework.jdbc.core.RowMapper;
public final class GenreMapper implements RowMapper<Genre> {
public Genre mapRow(ResultSet rs, int rowNum) throws SQLException {
return new Genre(rs.getString("name"));
}
}</code></pre>
<p>要将参数传递给在RDBMS中定义有一个或多个输入参数的存储过程,您可以编写一个强类型的execute(..)方法,该方法将委托给超类中的非类型化的execute(Map)方法,如下面的示例所示:</p>
<pre class="has"><code>import java.sql.Types;
import java.util.Date;
import java.util.HashMap;
import java.util.Map;
import javax.sql.DataSource;
import oracle.jdbc.OracleTypes;
import org.springframework.jdbc.core.SqlOutParameter;
import org.springframework.jdbc.core.SqlParameter;
import org.springframework.jdbc.object.StoredProcedure;
public class TitlesAfterDateStoredProcedure extends StoredProcedure {
private static final String SPROC_NAME = "TitlesAfterDate";
private static final String CUTOFF_DATE_PARAM = "cutoffDate";
public TitlesAfterDateStoredProcedure(DataSource dataSource) {
super(dataSource, SPROC_NAME);
declareParameter(new SqlParameter(CUTOFF_DATE_PARAM, Types.DATE);
declareParameter(new SqlOutParameter("titles", OracleTypes.CURSOR, new TitleMapper()));
compile();
}
public Map<String, Object> execute(Date cutoffDate) {
Map<String, Object> inputs = new HashMap<String, Object>();
inputs.put(CUTOFF_DATE_PARAM, cutoffDate);
return super.execute(inputs);
}
}</code></pre>
<p>3.8。参数和数据值处理的常见问题<br> 参数和数据值的常见问题存在于Spring Framework的JDBC支持提供的不同方法中。本节将介绍如何解决这些问题。</p>
<p>3.8.1。为参数提供SQL类型信息<br> 通常,Spring根据传入的参数类型确定参数的SQL类型。可以显式地提供设置参数值时使用的SQL类型。这有时对于正确设置空值是必要的。</p>
<p>您可以通过以下几种方式提供SQL类型信息:</p>
<ul>
<li>JdbcTemplate的许多更新和查询方法都采用int数组形式的附加参数。该数组用于通过使用java.sql中的常量值来指示相应参数的SQL类型。类型的类。为每个参数提供一个条目。</li>
<li>您可以使用SqlParameterValue类来包装需要此附加信息的参数值。为此,为每个值创建一个新实例,并在构造函数中传递SQL类型和参数值。还可以为数值提供可选的缩放参数。</li>
<li>对于使用命名参数的方法,可以使用SqlParameterSource类、BeanPropertySqlParameterSource或MapSqlParameterSource。它们都有用于注册任何指定参数值的SQL类型的方法。</li>
</ul>
<p>3.8.2。处理BLOB和CLOB对象<br> 您可以在数据库中存储图像、其他二进制数据和大块文本。这些大对象对于二进制数据称为blob(二进制大对象),对于字符数据称为clob(字符大对象)。在Spring中,您可以直接使用JdbcTemplate来处理这些大型对象,也可以使用RDBMS对象和SimpleJdbc类提供的高级抽象。所有这些方法都使用LobHandler接口的实现来实际管理LOB(大对象)数据。LobHandler通过getLobCreator方法提供对一个LobCreator类的访问,该方法用于创建要插入的新LOB对象。</p>
<p>LobCreator和LobHandler为LOB输入和输出提供以下支持:</p>
<p>BLOB</p>
<ul>
<li>byte[]: getBlobAsBytes和setBlobAsBytes</li>
<li>InputStream: getBlobAsBinaryStream和setBlobAsBinaryStream</li>
</ul>
<p>CLOB</p>
<ul>
<li>String:getClobAsString和setClobAsString</li>
<li>InputStream: getClobAsAsciiStream和setclobasasciream</li>
<li>Reader:getClobAsCharacterStream和setClobAsCharacterStream</li>
</ul>
<p>下一个示例展示如何创建和插入一个BLOB。稍后,我们将展示如何从数据库中读取它。<br> 本例使用了JdbcTemplate和abstractcreatingpreparedstatementcallback的实现。它实现了一个方法setValues。这个方法提供了一个LobCreator,我们使用它来设置SQL insert语句中的LOB列的值。</p>
<p>对于本例,我们假设有一个变量lobHandler,它已经被设置为DefaultLobHandler的一个实例。通常通过依赖项注入设置此值。<br> 下面的示例演示如何创建和插入一个BLOB:</p>
<pre class="has"><code>final File blobIn = new File("spring2004.jpg");
final InputStream blobIs = new FileInputStream(blobIn);
final File clobIn = new File("large.txt");
final InputStream clobIs = new FileInputStream(clobIn);
final InputStreamReader clobReader = new InputStreamReader(clobIs);
jdbcTemplate.execute(
"INSERT INTO lob_table (id, a_clob, a_blob) VALUES (?, ?, ?)",
new AbstractLobCreatingPreparedStatementCallback(lobHandler) { //1
protected void setValues(PreparedStatement ps, LobCreator lobCreator) throws SQLException {
ps.setLong(1, 1L);
lobCreator.setClobAsCharacterStream(ps, 2, clobReader, (int)clobIn.length()); //2
lobCreator.setBlobAsBinaryStream(ps, 3, blobIs, (int)blobIn.length()); //3
}
}
);
blobIs.close();
clobReader.close();</code></pre>
<ol>
<li>传入一个简单的DefaultLobHandler(在本例中)。</li>
<li>使用setClobAsCharacterStream方法传递CLOB的内容。</li>
<li>使用setBlobAsBinaryStream方法传入BLOB的内容。</li>
</ol>
<p>注意:如果您调用了DefaultLobHandler.getLobCreator()返回的LobCreator上的setBlobAsBinaryStream、setClobAsAsciiStream或setClobAsCharacterStream方法,您可以为contentLength参数指定一个负值。如果指定的内容长度为负,则DefaultLobHandler使用集流方法的JDBC 4.0变体,但不使用长度参数。否则,它将指定的长度传递给驱动程序。</p>
<p>请参阅用于验证它是否支持不提供内容长度的LOB流的JDBC驱动程序的文档。</p>
<p>现在该从数据库读取LOB数据了。同样,使用具有相同实例变量lobHandler和对DefaultLobHandler的引用的JdbcTemplate。下面的例子演示了如何做到这一点:</p>
<pre class="has"><code>List<Map<String, Object>> l = jdbcTemplate.query("select id, a_clob, a_blob from lob_table",
new RowMapper<Map<String, Object>>() {
public Map<String, Object> mapRow(ResultSet rs, int i) throws SQLException {
Map<String, Object> results = new HashMap<String, Object>();
String clobText = lobHandler.getClobAsString(rs, "a_clob");
results.put("CLOB", clobText);
byte[] blobBytes = lobHandler.getBlobAsBytes(rs, "a_blob");
results.put("BLOB", blobBytes);
return results;
}
});</code></pre>
<p>使用getClobAsString方法检索CLOB的内容。<br> 使用getBlobAsBytes方法检索BLOB的内容。</p>
<p>3.8.3。传入in子句的值列表<br> SQL标准允许根据包含变量值列表的表达式选择行。一个典型的例子是select * from T_ACTOR,其中id在(1,2,3)中。不能声明数量不定的占位符。您需要准备大量的占位符,或者需要在知道需要多少占位符之后动态地生成SQL字符串。NamedParameterJdbcTemplate中提供的命名参数支持采用后一种方法。可以将值作为java.util.List传入。此列表用于插入所需的占位符并在语句执行期间传递值。</p>
<p>注意:在传递许多值时要小心。JDBC标准并不保证您可以为一个in表达式列表使用超过100个值。各种数据库都超过这个数字,但是它们通常对允许的值有一个硬限制。例如,Oracle的上限是1000。</p>
<p>除了值列表中的原语值之外,您还可以创建java.util。对象数组的列表。这个列表可以支持为in子句定义的多个表达式,比如select * from T_ACTOR where (id, last_name) in ((1, 'Johnson'), (2, 'Harrop'\))。当然,这需要数据库支持这种语法。</p>
<p>3.8.4。处理存储过程调用的复杂类型<br> 调用存储过程时,有时可以使用特定于数据库的复杂类型。为了适应这些类型,Spring提供了一个SqlReturnType,用于在从存储过程调用返回这些类型时处理它们,并在将它们作为参数传递给存储过程时处理SqlTypeValue。</p>
<p>SqlReturnType接口有一个必须实现的方法(名为getTypeValue)。此接口用作SqlOutParameter声明的一部分。下面的示例显示了返回用户声明类型ITEM_TYPE的Oracle STRUCT对象的值:</p>
<pre class="has"><code>public class TestItemStoredProcedure extends StoredProcedure {
public TestItemStoredProcedure(DataSource dataSource) {
// ...
declareParameter(new SqlOutParameter("item", OracleTypes.STRUCT, "ITEM_TYPE",
new SqlReturnType() {
public Object getTypeValue(CallableStatement cs, int colIndx, int sqlType, String ) throws SQLException {
STRUCT struct = (STRUCT) cs.getObject(colIndx);
Object[] attr = struct.getAttributes();
TestItem item = new TestItem();
item.setId(((Number) attr[0]).longValue());
item.setDescription((String) attr[1]);
item.setExpirationDate((java.util.Date) attr[2]);
return item;
}
}));
// ...
}</code></pre>
<p>可以使用SqlTypeValue将Java对象(如睾丸)的值传递给存储过程。SqlTypeValue接口有一个必须实现的方法(名为createTypeValue)。活动连接被传递进来,您可以使用它来创建特定于数据库的对象,例如StructDescriptor实例或ArrayDescriptor实例。下面的例子创建了一个StructDescriptor实例:</p>
<pre class="has"><code>final TestItem testItem = new TestItem(123L, "A test item",
new SimpleDateFormat("yyyy-M-d").parse("2010-12-31"));
SqlTypeValue value = new AbstractSqlTypeValue() {
protected Object createTypeValue(Connection conn, int sqlType, String typeName) throws SQLException {
StructDescriptor itemDescriptor = new StructDescriptor(typeName, conn);
Struct item = new STRUCT(itemDescriptor, conn,
new Object[] {
testItem.getId(),
testItem.getDescription(),
new java.sql.Date(testItem.getExpirationDate().getTime())
});
return item;
}
};</code></pre>
<p>现在可以将这个SqlTypeValue添加到包含存储过程执行调用的输入参数的映射中。</p>
<p>SqlTypeValue的另一个用途是将值数组传递给Oracle存储过程。Oracle有自己的内部数组类,在这种情况下必须使用它,您可以使用SqlTypeValue创建Oracle数组的实例,并用Java数组中的值填充它,如下面的例子所示:</p>
<pre class="has"><code>final Long[] ids = new Long[] {1L, 2L};
SqlTypeValue value = new AbstractSqlTypeValue() {
protected Object createTypeValue(Connection conn, int sqlType, String typeName) throws SQLException {
ArrayDescriptor arrayDescriptor = new ArrayDescriptor(typeName, conn);
ARRAY idArray = new ARRAY(arrayDescriptor, conn, ids);
return idArray;
}
};</code></pre>
<p>3.9。嵌入式数据库的支持<br> org.springframework.jdbc.datasource。嵌入式包提供对嵌入式Java数据库引擎的支持。本地提供对HSQL、H2和Derby的支持。您还可以使用可扩展的API来插入新的嵌入式数据库类型和数据源实现。</p>
<p>3.9.1。为什么使用嵌入式数据库?<br> 嵌入式数据库在项目的开发阶段非常有用,因为它是轻量级的。它的优点包括配置简单、启动时间快、可测试性以及在开发过程中快速发展SQL的能力。</p>
<p>3.9.2。使用Spring XML创建嵌入式数据库<br> 如果您想在Spring ApplicationContext中将嵌入式数据库实例作为bean公开,您可以使用Spring -jdbc名称空间中的嵌入式数据库标记:</p>
<pre class="has"><code><jdbc:embedded-database id="dataSource" generate-name="true">
<jdbc:script location="classpath:schema.sql"/>
<jdbc:script location="classpath:test-data.sql"/>
</jdbc:embedded-database></code></pre>
<p>前面的配置创建了一个嵌入式HSQL数据库,该数据库使用来自模式的SQL填充。sql和测试数据。类路径根中的sql资源。此外,作为一种最佳实践,为嵌入式数据库分配一个惟一生成的名称。Spring容器可以使用嵌入式数据库作为javax.sql类型的bean。然后可以根据需要将数据源注入到数据访问对象中。</p>
<p>3.9.3。以编程方式创建嵌入式数据库<br> EmbeddedDatabaseBuilder类为以编程方式构建嵌入式数据库提供了一个流畅的API。当您需要在独立环境或独立集成测试中创建嵌入式数据库时,可以使用此功能,如下例所示:</p>
<pre class="has"><code>EmbeddedDatabase db = new EmbeddedDatabaseBuilder()
.generateUniqueName(true)
.setType(H2)
.setScriptEncoding("UTF-8")
.ignoreFailedDrops(true)
.addScript("schema.sql")
.addScripts("user_data.sql", "country_data.sql")
.build();
// perform actions against the db (EmbeddedDatabase extends javax.sql.DataSource)
db.shutdown()</code></pre>
<p>有关所有受支持选项的详细信息,请参阅EmbeddedDatabaseBuilder的javadoc。<br> 您还可以使用EmbeddedDatabaseBuilder通过使用Java配置来创建嵌入式数据库,如下面的示例所示:</p>
<pre class="has"><code>@Configuration
public class DataSourceConfig {
@Bean
public DataSource dataSource() {
return new EmbeddedDatabaseBuilder()
.generateUniqueName(true)
.setType(H2)
.setScriptEncoding("UTF-8")
.ignoreFailedDrops(true)
.addScript("schema.sql")
.addScripts("user_data.sql", "country_data.sql")
.build();
}
}</code></pre>
<p>3.9.4。选择嵌入式数据库类型<br> 本节介绍如何选择Spring支持的三种嵌入式数据库之一。它包括下列主题:</p>
<ul>
<li> <p>Using HSQL</p> </li>
<li> <p>Using H2</p> </li>
<li> <p>Using Derby</p> </li>
</ul>
<p>使用HSQL<br> Spring支持HSQL 1.8.0及以上版本。如果没有显式指定类型,则HSQL是默认的嵌入式数据库。要显式地指定HSQL,请将嵌入式数据库标记的type属性设置为HSQL。如果使用builder API,则使用EmbeddedDatabaseType. hsql调用setType(EmbeddedDatabaseType)方法。</p>
<p>使用H2<br> Spring支持H2数据库。要启用H2,请将嵌入数据库标记的type属性设置为H2。如果使用builder API,则使用EmbeddedDatabaseType. h2调用setType(EmbeddedDatabaseType)方法。</p>
<p>使用Derby<br> Spring支持Apache Derby 10.5及以上版本。要启用Derby,请将嵌入数据库标记的type属性设置为Derby。如果使用builder API,则使用EmbeddedDatabaseType. derby调用setType(EmbeddedDatabaseType)方法。</p>
<p>3.9.5。使用嵌入式数据库测试数据访问逻辑<br> 嵌入式数据库提供了一种测试数据访问代码的轻量级方法。下一个示例是使用嵌入式数据库的数据访问集成测试模板。当嵌入式数据库不需要跨测试类重用时,使用这样的模板对于一次性使用非常有用。然而,如果您希望创建一个共享的嵌入式数据库在一个测试套件,考虑使用Spring和TestContext框架和配置Spring ApplicationContext的嵌入式数据库作为一个bean创建所述嵌入式数据库通过使用Spring XML和创建嵌入式数据库编程。下面的清单显示了测试模板:</p>
<pre class="has"><code>public class DataAccessIntegrationTestTemplate {
private EmbeddedDatabase db;
@BeforeEach
public void setUp() {
// creates an HSQL in-memory database populated from default scripts
// classpath:schema.sql and classpath:data.sql
db = new EmbeddedDatabaseBuilder()
.generateUniqueName(true)
.addDefaultScripts()
.build();
}
@Test
public void testDataAccess() {
JdbcTemplate template = new JdbcTemplate(db);
template.query( /* ... */ );
}
@AfterEach
public void tearDown() {
db.shutdown();
}
}</code></pre>
<p>3.9.6。为嵌入式数据库生成唯一的名称<br> 如果开发团队的测试套件无意中试图重新创建相同数据库的其他实例,那么他们在使用嵌入式数据库时经常会遇到错误。这可以很容易地发生,如果一个XML配置文件或@<code>Configuration</code> 类负责创建嵌入式数据库和相应的配置然后重用跨多个相同测试套件中的测试场景(即在同一JVM进程)——例如,对嵌入式数据库的集成测试ApplicationContext配置不同只对bean定义概要文件是活跃的。</p>
<p>这些错误的根本原因是Spring的EmbeddedDatabaseFactory(由<jdbc: embeddatabase > XML namespace元素和用于Java配置的EmbeddedDatabaseBuilder在内部使用)将嵌入式数据库的名称设置为testdb(如果没有另外指定的话)。对于<jdbc:嵌入式数据库>,嵌入式数据库通常被分配一个与bean的id相等的名称(通常类似于dataSource)。因此,创建嵌入式数据库的后续尝试不会导致新的数据库。相反,重用相同的JDBC连接URL,并且尝试创建一个新的嵌入式数据库,实际上指向一个由相同配置创建的现有嵌入式数据库。</p>
<p>为了解决这个常见问题,Spring Framework 4.2提供了对为嵌入式数据库生成惟一名称的支持。要启用生成的名称,请使用以下选项之一。</p>
<ul>
<li> <p><code>EmbeddedDatabaseFactory.setGenerateUniqueDatabaseName()</code></p> </li>
<li> <p><code>EmbeddedDatabaseBuilder.generateUniqueName()</code></p> </li>
<li> <p><code><jdbc:embedded-database generate-name="true" … ></code></p> </li>
</ul>
<p>3.9.7。扩展嵌入式数据库支持<br> 您可以通过两种方式扩展Spring JDBC嵌入式数据库支持:</p>
<ul>
<li>实现EmbeddedDatabaseConfigurer来支持新的嵌入式数据库类型。</li>
<li>实现DataSourceFactory来支持新的数据源实现,比如管理嵌入式数据库连接的连接池。</li>
</ul>
<p>我们鼓励您在GitHub Issues上为Spring社区提供扩展。</p>
<p>3.10。初始化数据源<br> org.springframework.jdbc.datasource。init包提供对初始化现有数据源的支持。嵌入式数据库支持为创建和初始化应用程序的数据源提供了一个选项。但是,有时可能需要初始化某个服务器上运行的实例。</p>
<p>3.10.1。使用Spring XML初始化数据库<br> 如果你想要初始化一个数据库,你可以提供一个对DataSource bean的引用,你可以使用spring-jdbc命名空间中的initialize-database标签:</p>
<pre class="has"><code><jdbc:initialize-database data-source="dataSource">
<jdbc:script location="classpath:com/foo/sql/db-schema.sql"/>
<jdbc:script location="classpath:com/foo/sql/db-test-data.sql"/>
</jdbc:initialize-database></code></pre>
<p>前面的示例针对数据库运行两个指定的脚本。第一个脚本创建一个模式,第二个脚本用一个测试数据集填充表。脚本位置也可以是带有通配符的模式,通配符是Spring中用于资源的常见Ant样式(例如,classpath*:/com/foo/**/sql/*-data.sql)。如果使用模式,脚本将按照URL或文件名的词法顺序运行。</p>
<p>数据库初始化器的默认行为是无条件地运行提供的脚本。这可能不是您想要的—例如,如果您对一个已经包含测试数据的数据库运行脚本。通过遵循常见的模式(如前面所示),先创建表,然后插入数据,可以减少意外删除数据的可能性。如果表已经存在,则第一步将失败。</p>
<p>但是,为了获得对现有数据的创建和删除的更多控制,XML名称空间提供了一些附加选项。第一个是用来开关初始化的标志。您可以根据环境来设置它(例如从系统属性或环境bean中提取一个布尔值)。下面的示例从系统属性获取一个值:</p>
<pre class="has"><code><jdbc:initialize-database data-source="dataSource"
enabled="#{systemProperties.INITIALIZE_DATABASE}">
<jdbc:script location="..."/>
</jdbc:initialize-database></code></pre>
<p>控制现有数据所发生的情况的第二种选择是更加容忍失败。为此,可以控制初始化器忽略它从脚本执行的SQL中的某些错误,如下面的示例所示:</p>
<pre class="has"><code><jdbc:initialize-database data-source="dataSource" ignore-failures="DROPS">
<jdbc:script location="..."/>
</jdbc:initialize-database></code></pre>
<p>在前面的示例中,我们说的是,我们预期脚本有时会对空数据库运行,因此脚本中有一些DROP语句会失败。因此,失败的SQL DROP语句将被忽略,但其他失败将导致异常。如果您的SQL方言不支持DROP,如果存在(或类似的情况),但是您希望在重新创建之前无条件地删除所有测试数据,那么这是非常有用的。在这种情况下,第一个脚本通常是一组DROP语句,然后是一组CREATE语句。</p>
<p>可以将ignore-failure选项设置为NONE(默认值)、DROPS(忽略失败的drop)或ALL(忽略所有失败)。<br> 每个语句之间应该用;或新行,如果;角色在剧本中根本不存在。你可以控制全局或脚本的脚本,如下面的例子所示:</p>
<pre class="has"><code><jdbc:initialize-database data-source="dataSource" separator="@@">
<jdbc:script location="classpath:com/myapp/sql/db-schema.sql" separator=";"/>
<jdbc:script location="classpath:com/myapp/sql/db-test-data-1.sql"/>
<jdbc:script location="classpath:com/myapp/sql/db-test-data-2.sql"/>
</jdbc:initialize-database></code></pre>
<p>在这个例子中,两个测试数据脚本使用@@作为语句分隔符,并且只使用db-schema。sql使用;。此配置指定默认分隔符为@@,并覆盖了db-schema脚本的默认分隔符。<br> 如果需要比XML名称空间更多的控制,可以直接使用DataSourceInitializer并将其定义为应用程序中的组件。</p>
<p>依赖于数据库的其他组件的初始化<br> 大量的应用程序(那些在Spring上下文启动之后才使用数据库的应用程序)可以使用数据库初始化器,而不会带来更多的麻烦。如果您的应用程序不是其中之一,您可能需要阅读本节的其余部分。</p>
<p>数据库初始化器依赖于数据源实例并运行其初始化回调中提供的脚本(类似于XML bean定义中的init-method、组件中的@PostConstruct方法或实现InitializingBean的组件中的afterPropertiesSet()方法)。如果其他bean依赖于相同的数据源并在初始化回调中使用该数据源,则可能会出现问题,因为数据尚未初始化。一个常见的例子是在应用程序启动时急切地初始化并从数据库加载数据的缓存。</p>
<p>要解决这个问题,您有两个选项:将缓存初始化策略更改为稍后的阶段,或者确保先初始化数据库初始化器。<br> 如果应用程序在您的控制之下,则更改缓存初始化策略可能很容易,否则就不容易了。关于如何实现这一点,一些建议包括:</p>
<ul>
<li>让缓存在第一次使用时延迟初始化,这样可以提高应用程序的启动时间。</li>
<li>让你的缓存或一个单独的组件初始化缓存实现生命周期或SmartLifecycle。当应用程序上下文启动时,您可以通过设置它的autoStartup标志来自动启动一个SmartLifecycle,您还可以通过在封闭上下文上调用ConfigurableApplicationContext.start()来手动启动一个生命周期。</li>
<li>使用Spring ApplicationEvent或类似的自定义观察者机制来触发缓存初始化。ContextRefreshedEvent在准备使用时(在所有bean初始化之后)总是由上下文发布,所以这通常是一个有用的挂钩(默认情况下SmartLifecycle就是这样工作的)。</li>
</ul>
<p>确保首先初始化数据库初始化器也很容易。关于如何实施这一点,一些建议包括:</p>
<ul>
<li>依赖于Spring BeanFactory的默认行为,即bean是按注册顺序初始化的。您可以通过在XML配置中采用一组<import/>元素的常见实践来轻松地安排这些元素,这些元素对应用程序模块进行排序,并确保首先列出数据库和数据库初始化。</li>
<li>将数据源和使用它的业务组件分离,并通过将它们放在单独的ApplicationContext实例中来控制它们的启动顺序(例如,父上下文包含数据源,子上下文包含业务组件)。这种结构在Spring web应用程序中很常见,但可以更广泛地应用。</li>
</ul>
<p> </p>
</div>
</div>
</div>
</div>
</div>
<!--PC和WAP自适应版-->
<div id="SOHUCS" sid="1304462791184257024"></div>
<script type="text/javascript" src="/views/front/js/chanyan.js"></script>
<!-- 文章页-底部 动态广告位 -->
<div class="youdao-fixed-ad" id="detail_ad_bottom"></div>
</div>
<div class="col-md-3">
<div class="row" id="ad">
<!-- 文章页-右侧1 动态广告位 -->
<div id="right-1" class="col-lg-12 col-md-12 col-sm-4 col-xs-4 ad">
<div class="youdao-fixed-ad" id="detail_ad_1"> </div>
</div>
<!-- 文章页-右侧2 动态广告位 -->
<div id="right-2" class="col-lg-12 col-md-12 col-sm-4 col-xs-4 ad">
<div class="youdao-fixed-ad" id="detail_ad_2"></div>
</div>
<!-- 文章页-右侧3 动态广告位 -->
<div id="right-3" class="col-lg-12 col-md-12 col-sm-4 col-xs-4 ad">
<div class="youdao-fixed-ad" id="detail_ad_3"></div>
</div>
</div>
</div>
</div>
</div>
</div>
<div class="container">
<h4 class="pt20 mb15 mt0 border-top">你可能感兴趣的:(Spring,文档,Spring,Data,文档)</h4>
<div id="paradigm-article-related">
<div class="recommend-post mb30">
<ul class="widget-links">
<li><a href="/article/1892551831830196224.htm"
title="“深入浅出”系列之QT:(10)Qt接入Deepseek" target="_blank">“深入浅出”系列之QT:(10)Qt接入Deepseek</a>
<span class="text-muted">我真不会起名字啊</span>
<a class="tag" taget="_blank" href="/search/qt/1.htm">qt</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a>
<div>项目配置:在.pro文件中添加网络模块:QT+=corenetworkAPI配置:将apiUrl替换为实际的DeepSeekAPI端点将apiKey替换为你的有效API密钥根据API文档调整请求参数(模型名称、温度值等)功能说明:使用QNetworkAccessManager处理HTTP请求自动处理JSON序列化/反序列化支持异步请求处理包含基本的错误处理扩展建议:添加更完善的错误处理(HTTP状</div>
</li>
<li><a href="/article/1892550192041881600.htm"
title="Spring Bean 生命周期的执行流程" target="_blank">Spring Bean 生命周期的执行流程</a>
<span class="text-muted">涛粒子</span>
<a class="tag" taget="_blank" href="/search/spring/1.htm">spring</a><a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/%E5%90%8E%E7%AB%AF/1.htm">后端</a>
<div>1.Bean定义阶段解析配置元数据:Spring容器会读取配置信息,这些配置信息可以是XML文件、Java注解或者Java配置类。容器根据这些配置信息解析出Bean的定义,包括Bean的类名、作用域、依赖关系等。注册Bean定义:解析完成后,Spring会将Bean定义信息注册到BeanDefinitionRegistry中,BeanDefinitionRegistry是一个存储Bean定义的注册</div>
</li>
<li><a href="/article/1892546280924704768.htm"
title="uni-app使用websocket" target="_blank">uni-app使用websocket</a>
<span class="text-muted">外派叙利亚</span>
<a class="tag" taget="_blank" href="/search/uni-app/1.htm">uni-app</a><a class="tag" taget="_blank" href="/search/websocket/1.htm">websocket</a><a class="tag" taget="_blank" href="/search/%E7%BD%91%E7%BB%9C%E5%8D%8F%E8%AE%AE/1.htm">网络协议</a>
<div>点击发送请求离开页面exportdefault{onLoad(){//进入这个页面的时候创建websocket连接【整个页面随时使用】this.connectSocketInit();},data(){return{socketTask:null,//确保websocket是打开状态is_open_socket:false}},//关闭websocket【必须在实例销毁之前关闭,否则会是under</div>
</li>
<li><a href="/article/1892545777100713984.htm"
title="使用Druid连接池优化Spring Boot应用中的数据库连接" target="_blank">使用Druid连接池优化Spring Boot应用中的数据库连接</a>
<span class="text-muted">和烨</span>
<a class="tag" taget="_blank" href="/search/%E5%85%B6%E5%AE%83/1.htm">其它</a><a class="tag" taget="_blank" href="/search/spring/1.htm">spring</a><a class="tag" taget="_blank" href="/search/boot/1.htm">boot</a><a class="tag" taget="_blank" href="/search/%E6%95%B0%E6%8D%AE%E5%BA%93/1.htm">数据库</a><a class="tag" taget="_blank" href="/search/%E5%90%8E%E7%AB%AF/1.htm">后端</a>
<div>使用Druid连接池优化SpringBoot应用中的数据库连接使用Druid连接池优化SpringBoot应用中的数据库连接1.什么是Druid连接池?2.在SpringBoot中配置Druid连接池2.1添加依赖2.2配置Druid连接池2.3配置参数详解3.启用Druid监控4.总结使用Druid连接池优化SpringBoot应用中的数据库连接在现代的Java应用中,数据库连接管理是一个非常重</div>
</li>
<li><a href="/article/1892544893620908032.htm"
title="纯前端导入导出txt文件" target="_blank">纯前端导入导出txt文件</a>
<span class="text-muted">今天吃了嘛o</span>
<a class="tag" taget="_blank" href="/search/%E5%89%8D%E7%AB%AF%E5%AF%BC%E5%85%A5%E5%AF%BC%E5%87%BAtxt%E6%96%87%E4%BB%B6/1.htm">前端导入导出txt文件</a><a class="tag" taget="_blank" href="/search/javascript/1.htm">javascript</a><a class="tag" taget="_blank" href="/search/html/1.htm">html</a><a class="tag" taget="_blank" href="/search/html5/1.htm">html5</a>
<div>1.html部分导入导出{{alone}}2.js部分导出的时候我尝试了很多次改变编码格式为gb2312的,但是无果,所以我再读取的时候先读取文件判断了文件编码格式,然后再去根据编码格式读取文件并展示页面。exportdefault{data(){return{works:[],};},methods:{handleBeforeUpload(file){this.fileList=[file];c</div>
</li>
<li><a href="/article/1892543379292614656.htm"
title="vue中使用ueditor上传到服务器_vue+Ueditor集成 [前后端分离项目][图片、文件上传][富文本编辑]..." target="_blank">vue中使用ueditor上传到服务器_vue+Ueditor集成 [前后端分离项目][图片、文件上传][富文本编辑]...</a>
<span class="text-muted">小西超人</span>
<div>写在最前面的话:鉴于近期很多的博友讨论,说我按照文章的一步一步来,弄好之后,怎么会提示后端配置项http错误,文件上传会提示上传错误。这里提别申明一点,ueditor在前端配置好后,需要与后端部分配合进行,后端部分的项目代码git地址:https://github.com/coderliguoqing/UeditorSpringboot,然后将配置ueditor.config.js里的server</div>
</li>
<li><a href="/article/1892542618877882368.htm"
title="国产编辑器EverEdit - 独门暗器:自动监视剪贴板内容" target="_blank">国产编辑器EverEdit - 独门暗器:自动监视剪贴板内容</a>
<span class="text-muted">编辑器爱好者</span>
<a class="tag" taget="_blank" href="/search/%E5%A6%99%E7%94%A8%E7%BC%96%E8%BE%91%E5%99%A8/1.htm">妙用编辑器</a><a class="tag" taget="_blank" href="/search/%E7%BC%96%E8%BE%91%E5%99%A8/1.htm">编辑器</a><a class="tag" taget="_blank" href="/search/EverEdit/1.htm">EverEdit</a><a class="tag" taget="_blank" href="/search/EmEditor/1.htm">EmEditor</a><a class="tag" taget="_blank" href="/search/Notepad/1.htm">Notepad</a>
<div>1监视剪贴板1.1应用场景 如果需要对剪贴板的所有历史进行记录,并进行分析和回顾,则可以使用监视剪贴板功能,不仅在EverEdit中的复制会记录,在其他应用的复制也会记录。1.2使用方法 新建一个空文档(重要:防止扰乱正常文件),单击主菜单文档->监视剪贴板即可。该功能打开后,当前系统所有的复制内容,都会追加到用户指定的文档中。说明:监视剪贴板只会监控文本内容,图片、文档等非文本信息,不会追加</div>
</li>
<li><a href="/article/1892541358825074688.htm"
title="uniapp开发APP,主动连接mqtt,订阅消息" target="_blank">uniapp开发APP,主动连接mqtt,订阅消息</a>
<span class="text-muted">路痴先森</span>
<a class="tag" taget="_blank" href="/search/uni-app/1.htm">uni-app</a>
<div>一、安装依赖通过查阅资料,了解到现在mqtt.js库的最新版本已经是5,但是目前应该mqtt@3.0.0版本最为稳定,我项目开发中使用的也是mqtt@3.0.0版本npminstallmqtt@3.0.0参考插件:MQTT使用-模板项目-DCloud插件市场参考文档:GitHub-mqttjs/MQTT.js:TheMQTTclientforNode.jsandthebrowser二、封装一个工具</div>
</li>
<li><a href="/article/1892539211513393152.htm"
title="mac mini m1芯片 Xcode 15.3 各种报错的问题" target="_blank">mac mini m1芯片 Xcode 15.3 各种报错的问题</a>
<span class="text-muted">OKXLIN</span>
<a class="tag" taget="_blank" href="/search/macos/1.htm">macos</a><a class="tag" taget="_blank" href="/search/xcode/1.htm">xcode</a><a class="tag" taget="_blank" href="/search/ide/1.htm">ide</a>
<div>错误一:/Users/mac/Desktop/Test_project/mobile-ios/Test/Test-Bridging-Header.h:4:9failedtoemitprecompiledheader'/Users/mac/Library/Developer/Xcode/DerivedData/App-apvcgkuclncgfqdlzqcoffyaexos/Build/Interm</div>
</li>
<li><a href="/article/1892537949245992960.htm"
title="Python爬虫TLS" target="_blank">Python爬虫TLS</a>
<span class="text-muted">dme.</span>
<a class="tag" taget="_blank" href="/search/Python%E7%88%AC%E8%99%AB%E9%9B%B6%E5%9F%BA%E7%A1%80%E5%85%A5%E9%97%A8/1.htm">Python爬虫零基础入门</a><a class="tag" taget="_blank" href="/search/%E7%88%AC%E8%99%AB/1.htm">爬虫</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a>
<div>TLS指纹校验原理和绕过浏览器可以正常访问,但是用requests发送请求失败。后端是如何监测得呢?为什么浏览器可以返回结果,而requests模块不行呢?https://cn.investing.com/equities/amazon-com-inc-historical-data1.指纹校验案例1.1案例:ascii2dhttps://ascii2d.net/importrequestsres</div>
</li>
<li><a href="/article/1892536436008218624.htm"
title="图片粘贴上传实现" target="_blank">图片粘贴上传实现</a>
<span class="text-muted">SarinaDu</span>
<a class="tag" taget="_blank" href="/search/javascript/1.htm">javascript</a><a class="tag" taget="_blank" href="/search/html5/1.htm">html5</a>
<div>图片上传htmldemo直接粘贴本地运行查看效果即可,有看不懂的直接喂给deepseek会解释的很清晰粘贴图片上传示例-使用场景,粘贴桌面图片上传、粘贴word文档中图片上传、直接截图上传等body{font-family:Arial,sans-serif;padding:20px;}.upload-area{width:100%;height:200px;border:2pxdashed#ccc</div>
</li>
<li><a href="/article/1892533283338645504.htm"
title="深入浅出:基于SpringBoot和JWT的后端鉴权系统设计与实现" target="_blank">深入浅出:基于SpringBoot和JWT的后端鉴权系统设计与实现</a>
<span class="text-muted">Vcats</span>
<a class="tag" taget="_blank" href="/search/spring/1.htm">spring</a><a class="tag" taget="_blank" href="/search/boot/1.htm">boot</a><a class="tag" taget="_blank" href="/search/%E5%90%8E%E7%AB%AF/1.htm">后端</a><a class="tag" taget="_blank" href="/search/java/1.htm">java</a>
<div>文章目录什么是鉴权系统定义与作用主要组成部分工作原理常用技术和框架基于SpringBoot+JWT的鉴权系统设计与实现指南前言技术对比令牌技术JWT令牌实现全流程1.**依赖引入**2.**JWT工具类**3.**JWT拦截器(Interceptor)**4.**拦截器注册**5.**登录接口**什么是鉴权系统后端开发鉴权系统是一种用于验证和授权用户访问后端资源的系统,在保障系统安全和资源合理访问</div>
</li>
<li><a href="/article/1892530504545136640.htm"
title="使用vue3框架vue-next-admin导出表格excel(带图片)" target="_blank">使用vue3框架vue-next-admin导出表格excel(带图片)</a>
<span class="text-muted">乐多_L</span>
<a class="tag" taget="_blank" href="/search/vue.js/1.htm">vue.js</a><a class="tag" taget="_blank" href="/search/%E5%89%8D%E7%AB%AF/1.htm">前端</a><a class="tag" taget="_blank" href="/search/javascript/1.htm">javascript</a>
<div>想要使用vue3导出表格内容并且图片显示在表格中(如图):步骤如下:下载安装插件:安装命令:npminstalljs-table2excel引入插件:importtable2excelfrom'js-table2excel'使用插件直接上代码:onBatchExport方法中数据的key值要与data中保持一致,否则数据无法获取到,打印出的结果就回为undefined。我写了两种导出:一种是全部导</div>
</li>
<li><a href="/article/1892528737774268416.htm"
title="lombok在高版本idea中注解不生效的解决" target="_blank">lombok在高版本idea中注解不生效的解决</a>
<span class="text-muted">L_!!!</span>
<a class="tag" taget="_blank" href="/search/springboot/1.htm">springboot</a><a class="tag" taget="_blank" href="/search/maven/1.htm">maven</a><a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/%E6%9C%8D%E5%8A%A1%E5%99%A8/1.htm">服务器</a><a class="tag" taget="_blank" href="/search/%E5%89%8D%E7%AB%AF/1.htm">前端</a>
<div>环境:IntelliJIDEA2024.3.1.1+SpringBoot+Maven问题描述使用@AllArgsConstructor注解一个用户类,然后调用全参构造方法创建对象,出现错误:java:无法将类com.itheima.pojo.User中的构造器User应用到给定类型; 需要:没有参数 找到: java.lang.Integer,java.lang.String,java.lang</div>
</li>
<li><a href="/article/1892520036933890048.htm"
title="如何解决分布式应用数量庞大而导致数据库连接数满的问题?" target="_blank">如何解决分布式应用数量庞大而导致数据库连接数满的问题?</a>
<span class="text-muted">纵然间</span>
<a class="tag" taget="_blank" href="/search/%E6%95%B0%E6%8D%AE%E5%BA%93/1.htm">数据库</a>
<div>修改数据库服务器的配置文件或参数来增加最大连接数限制。例如,在MySQL中,可以通过修改my.cnf(Linux)或my.ini(Windows)文件中的max_connections参数来增加最大连接数。具体的操作方法可以参考数据库服务器的官方文档或相关技术支持。检查应用程序代码,确保在使用完数据库连接后及时释放连接资源,避免长时间占用连接而导致连接数不足。可以使用连接池技术来管理数据库连接,提</div>
</li>
<li><a href="/article/1892519658104352768.htm"
title="OpenMetadata MySQL 数据库使用率提取管道实现解析" target="_blank">OpenMetadata MySQL 数据库使用率提取管道实现解析</a>
<span class="text-muted">10年JAVA大数据技术研究者</span>
<a class="tag" taget="_blank" href="/search/%E6%95%B0%E6%8D%AE%E6%B2%BB%E7%90%86/1.htm">数据治理</a><a class="tag" taget="_blank" href="/search/%E6%95%B0%E6%8D%AE%E5%BA%93/1.htm">数据库</a><a class="tag" taget="_blank" href="/search/mysql/1.htm">mysql</a><a class="tag" taget="_blank" href="/search/openmetadata/1.htm">openmetadata</a><a class="tag" taget="_blank" href="/search/%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90/1.htm">源码分析</a>
<div>目录架构概述核心组件源码分析使用率指标定义数据提取流程图源码类图配置与扩展指南架构概述OpenMetadata通过可插拔的元数据摄取框架实现对MySQL使用率数据的采集,核心流程包含三个阶段:数据采集层:从MySQLperformance_schema和sysschema获取原始指标指标处理层:将原始数据转换为统一的使用率指标模型数据存储层:将处理后的指标持久化到OpenMetadata服务核心组</div>
</li>
<li><a href="/article/1892516757122379776.htm"
title="spring boot基于知识图谱的阿克苏市旅游管理系统python-计算机毕业设计" target="_blank">spring boot基于知识图谱的阿克苏市旅游管理系统python-计算机毕业设计</a>
<span class="text-muted">QQ1963288475</span>
<a class="tag" taget="_blank" href="/search/spring/1.htm">spring</a><a class="tag" taget="_blank" href="/search/boot/1.htm">boot</a><a class="tag" taget="_blank" href="/search/%E7%9F%A5%E8%AF%86%E5%9B%BE%E8%B0%B1/1.htm">知识图谱</a><a class="tag" taget="_blank" href="/search/%E6%97%85%E6%B8%B8/1.htm">旅游</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/vue.js/1.htm">vue.js</a><a class="tag" taget="_blank" href="/search/django/1.htm">django</a><a class="tag" taget="_blank" href="/search/flask/1.htm">flask</a>
<div>目录功能和技术介绍具体实现截图开发核心技术:开发环境开发步骤编译运行核心代码部分展示系统设计详细视频演示可行性论证软件测试源码获取功能和技术介绍该系统基于浏览器的方式进行访问,采用springboot集成快速开发框架,前端使用vue方式,基于es5的语法,开发工具IntelliJIDEAx64,因为该开发工具,内嵌了Tomcat服务运行机制,可不用单独下载Tomcatserver服务器。由于考虑到</div>
</li>
<li><a href="/article/1892512472749895680.htm"
title="基于JavaSpringboot+Vue实现前后端分离房屋租赁系统" target="_blank">基于JavaSpringboot+Vue实现前后端分离房屋租赁系统</a>
<span class="text-muted">网顺技术团队</span>
<a class="tag" taget="_blank" href="/search/%E6%88%90%E5%93%81%E7%A8%8B%E5%BA%8F%E9%A1%B9%E7%9B%AE/1.htm">成品程序项目</a><a class="tag" taget="_blank" href="/search/vue.js/1.htm">vue.js</a><a class="tag" taget="_blank" href="/search/%E5%89%8D%E7%AB%AF/1.htm">前端</a><a class="tag" taget="_blank" href="/search/javascript/1.htm">javascript</a><a class="tag" taget="_blank" href="/search/%E8%AF%BE%E7%A8%8B%E8%AE%BE%E8%AE%A1/1.htm">课程设计</a><a class="tag" taget="_blank" href="/search/spring/1.htm">spring</a><a class="tag" taget="_blank" href="/search/boot/1.htm">boot</a><a class="tag" taget="_blank" href="/search/mybatis/1.htm">mybatis</a>
<div>基于JavaSpringboot+Vue实现前后端分离房屋租赁系统作者主页网顺技术团队欢迎点赞收藏⭐留言文末获取源码联系方式查看下方微信号获取联系方式承接各种定制系统精彩系列推荐精彩专栏推荐订阅不然下次找不到哟Java毕设项目精品实战案例《1000套》感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人文章目录基于JavaSpringboot+</div>
</li>
<li><a href="/article/1892510469936181248.htm"
title="清华大学第四发《DeepSeek+DeepResearch 让科研像聊天一样简单》" target="_blank">清华大学第四发《DeepSeek+DeepResearch 让科研像聊天一样简单》</a>
<span class="text-muted"></span>
<a class="tag" taget="_blank" href="/search/%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD/1.htm">人工智能</a>
<div>当下科研领域,传统模式急需改变,清华大学第四版《DeepSeek+DeepResearch:让科研像聊天一样简单》全文一共86页,以下是文档的关键内容总结:一、智能组合优势DeepSeek与DeepResearch构建先进技术体系,有强大模型运算、智能数据处理和友好交互界面。模型在数据处理速度、精准度和泛化能力上远超传统模型。数据采集渠道广、处理快,能读取多种格式文件。数据分析深入,可视化直观,还</div>
</li>
<li><a href="/article/1892510328776880128.htm"
title="docker部署kafka(单节点) + Springboot集成kafka" target="_blank">docker部署kafka(单节点) + Springboot集成kafka</a>
<span class="text-muted">wsdhla</span>
<a class="tag" taget="_blank" href="/search/docker/1.htm">docker</a><a class="tag" taget="_blank" href="/search/kafka/1.htm">kafka</a><a class="tag" taget="_blank" href="/search/spring/1.htm">spring</a><a class="tag" taget="_blank" href="/search/boot/1.htm">boot</a><a class="tag" taget="_blank" href="/search/zookeeper/1.htm">zookeeper</a>
<div>环境:操作系统:win10Docker:DockerDesktop4.21.1(114176)、DockerEnginev24.0.2SpringBoot:2.7.15步骤1:创建网络:dockernetworkcreate--subnet=172.18.0.0/16net-kafka步骤2:安装zk镜像dockerpullzookeeper:latestdockerrun-d--restarta</div>
</li>
<li><a href="/article/1892502492609048576.htm"
title="CSS中五种定位方式(position)对比分析" target="_blank">CSS中五种定位方式(position)对比分析</a>
<span class="text-muted">七公子77</span>
<a class="tag" taget="_blank" href="/search/css/1.htm">css</a><a class="tag" taget="_blank" href="/search/css/1.htm">css</a><a class="tag" taget="_blank" href="/search/%E5%89%8D%E7%AB%AF/1.htm">前端</a>
<div>在CSS中,定位方式(position)决定了元素如何相对于其参照物进行定位,同时影响文档流的布局。以下是五种定位方式的对比、参照物说明及代码示例:1.position:static(默认定位)参照物:无,元素位于默认文档流中。文档流:元素按照HTML顺序自然排列。特点:top、right、bottom、left和z-index属性无效。示例:Box1Box2.box{width:100px;he</div>
</li>
<li><a href="/article/1892501862800748544.htm"
title="Centos7 搭建 Jupyter + Nginx 服务" target="_blank">Centos7 搭建 Jupyter + Nginx 服务</a>
<span class="text-muted">某龙兄</span>
<a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/nginx/1.htm">nginx</a><a class="tag" taget="_blank" href="/search/linux/1.htm">linux</a><a class="tag" taget="_blank" href="/search/centos/1.htm">centos</a>
<div>JupyterNotebook(此前被称为IPythonnotebook)是一个交互式笔记本,支持运行40多种编程语言。JupyterNotebook的本质是一个Web应用程序,便于创建和共享文学化程序文档,支持实时代码,数学方程,可视化和markdown。用途包括:数据清理和转换,数值模拟,统计建模,机器学习等等。本文讲述如何搭建Jupyter+Nginx服务,仅供学习与交流,请勿用于商业用途一</div>
</li>
<li><a href="/article/1892500097330114560.htm"
title="简易java调用DeepSeek Api教程" target="_blank">简易java调用DeepSeek Api教程</a>
<span class="text-muted">m0_62519278</span>
<a class="tag" taget="_blank" href="/search/%E5%AD%A6%E4%B9%A0%E5%B0%8F%E6%9C%AC%E6%9C%AC/1.htm">学习小本本</a><a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/%E6%95%B0%E6%8D%AE%E5%BA%93/1.htm">数据库</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a>
<div>一、请求格式首先观察官方文档给出的访问api的样例脚本curlhttps://api.deepseek.com/chat/completions\-H"Content-Type:application/json"\-H"Authorization:Bearer"\-d'{"model":"deepseek-chat","messages":[{"role":"system","content":"</div>
</li>
<li><a href="/article/1892484465444319232.htm"
title="heidisql连接远程数据库_【已解决】HeidiSQL连接(登录)MySQL数据库报错10061问题..." target="_blank">heidisql连接远程数据库_【已解决】HeidiSQL连接(登录)MySQL数据库报错10061问题...</a>
<span class="text-muted">weixin_39589511</span>
<a class="tag" taget="_blank" href="/search/heidisql%E8%BF%9E%E6%8E%A5%E8%BF%9C%E7%A8%8B%E6%95%B0%E6%8D%AE%E5%BA%93/1.htm">heidisql连接远程数据库</a>
<div>windows核心编程---第六章线程的调度每个线程都有一个CONTEXT结构,保存在线程内核对象中.大约每隔20mswindows就会查看所有当前存在的线程内核对象.并在可调度的线程内核对象中选择一个,将其保存在CONTEXT结构的值载入c...【转】SQLite提示databasediskimageismalformed的解决方法SQLite有一个很严重的缺点就是不提供Repair命令.导致死</div>
</li>
<li><a href="/article/1892482448659378176.htm"
title="【vue】Mammoth.js的使用:将.docx转换成HTML" target="_blank">【vue】Mammoth.js的使用:将.docx转换成HTML</a>
<span class="text-muted">暴富暴富暴富啦啦啦</span>
<a class="tag" taget="_blank" href="/search/1024%E7%A8%8B%E5%BA%8F%E5%91%98%E8%8A%82/1.htm">1024程序员节</a>
<div>mammoth.convertToHtml(input,options):把源文档转换为HTML文档mammoth.convertToMarkdown(input,options):把源文档转换为Markdown文档。mammoth.extractRawText(input):提取文档的原始文本。这将忽略文档中的所有格式。每个段落后跟两个换行符。npminstallelement-uimammot</div>
</li>
<li><a href="/article/1892479042192470016.htm"
title="快速复制A库表数据前10000行到B库" target="_blank">快速复制A库表数据前10000行到B库</a>
<span class="text-muted">musk1212</span>
<a class="tag" taget="_blank" href="/search/%E6%95%B0%E6%8D%AE%E5%BA%93/1.htm">数据库</a><a class="tag" taget="_blank" href="/search/sql/1.htm">sql</a><a class="tag" taget="_blank" href="/search/mysql/1.htm">mysql</a>
<div>提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档文章目录应用场景一、存储过程,快速复制A库表数据前10000行到B库二、使用优化点说明结构优化性能调整错误处理增强安全改进调用示例应用场景表结构可预先存在或不存在mysql5.7快速复制A库表数据前10000行到B库一、存储过程,快速复制A库表数据前10000行到B库/*设置自定义分隔符以处理存储过程中的分号*/DELIMITER$$</div>
</li>
<li><a href="/article/1892474123800604672.htm"
title="基于python使用scanpy分析单细胞转录组数据" target="_blank">基于python使用scanpy分析单细胞转录组数据</a>
<span class="text-muted">探序基因</span>
<a class="tag" taget="_blank" href="/search/%E5%8D%95%E7%BB%86%E8%83%9E%E5%88%86%E6%9E%90/1.htm">单细胞分析</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a>
<div>探序基因肿瘤研究院整理相关后缀的格式介绍:.h5ad:是一种用于存储单细胞数据的文件格式,可以通过anndata库在Python中处理.loom:高效的数据存储格式(.loom文件),使得用户可以轻松地存储、查询和分析大规模的单细胞数据集。Loompy的设计目标是提供一个快速、灵活且易于使用的工具,以支持生物信息学家和研究人员在单细胞水平上进行数据分析。python的单细胞转录组数据结构说明:da</div>
</li>
<li><a href="/article/1892473112734265344.htm"
title="在线预览 Word 文档" target="_blank">在线预览 Word 文档</a>
<span class="text-muted">你不讲 wood</span>
<a class="tag" taget="_blank" href="/search/word/1.htm">word</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a><a class="tag" taget="_blank" href="/search/%E5%89%8D%E7%AB%AF/1.htm">前端</a><a class="tag" taget="_blank" href="/search/vue.js/1.htm">vue.js</a><a class="tag" taget="_blank" href="/search/javascript/1.htm">javascript</a><a class="tag" taget="_blank" href="/search/node.js/1.htm">node.js</a><a class="tag" taget="_blank" href="/search/docx-preview/1.htm">docx-preview</a>
<div>引言随着互联网技术的发展,Web应用越来越复杂,用户对在线办公的需求也日益增加。在许多业务场景中,能够直接在浏览器中预览Word文档是一个非常实用的功能。这不仅可以提高用户体验,还能减少用户操作步骤,提升效率。实现原理1.后端服务假设后端服务已经提供了两个API接口:getFilesList:获取文件列表。previewFile:获取指定文件的内容。constexpress=require('ex</div>
</li>
<li><a href="/article/1892468067355652096.htm"
title="【Python系列】Python 解释器的站点配置" target="_blank">【Python系列】Python 解释器的站点配置</a>
<span class="text-muted">Kwan的解忧杂货铺@新空间代码工作室</span>
<a class="tag" taget="_blank" href="/search/s1/1.htm">s1</a><a class="tag" taget="_blank" href="/search/Python/1.htm">Python</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a>
<div>欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。推荐:kwan的首页,持续学习,不断总结,共同进步,活到老学到老导航檀越剑指大厂系列:全面总结java核心技术点,如集合,jvm,并发编程redis,kafka,Spring,微服务,Netty等常用开发工具系列:罗列常用的开发工具,如IDEA,M</div>
</li>
<li><a href="/article/1892462137901641728.htm"
title="鸢尾花分类项目 GUI" target="_blank">鸢尾花分类项目 GUI</a>
<span class="text-muted">编织幻境的妖</span>
<a class="tag" taget="_blank" href="/search/%E5%88%86%E7%B1%BB/1.htm">分类</a><a class="tag" taget="_blank" href="/search/%E6%95%B0%E6%8D%AE%E6%8C%96%E6%8E%98/1.htm">数据挖掘</a><a class="tag" taget="_blank" href="/search/%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD/1.htm">人工智能</a>
<div>1.机器学习的定义机器学习是一门人工智能的分支,专注于开发算法和统计模型,使计算机能够在没有明确编程的情况下从数据中自动学习和改进。通过识别数据中的模式和规律,机器学习系统可以做出预测或决策。常见的应用包括图像识别、语音识别、推荐系统等。2.为什么使用鸢尾花数据集(Irisdataset)鸢尾花数据集是一个经典的多类分类问题数据集,由英国统计学家和遗传学家RonaldFisher在1936年引入。</div>
</li>
<li><a href="/article/104.htm"
title="springmvc 下 freemarker页面枚举的遍历输出" target="_blank">springmvc 下 freemarker页面枚举的遍历输出</a>
<span class="text-muted">杨白白</span>
<a class="tag" taget="_blank" href="/search/enum/1.htm">enum</a><a class="tag" taget="_blank" href="/search/freemarker/1.htm">freemarker</a>
<div>spring mvc freemarker 中遍历枚举
1枚举类型有一个本地方法叫values(),这个方法可以直接返回枚举数组。所以可以利用这个遍历。
enum
public enum BooleanEnum {
TRUE(Boolean.TRUE, "是"), FALSE(Boolean.FALSE, "否");
</div>
</li>
<li><a href="/article/231.htm"
title="实习简要总结" target="_blank">实习简要总结</a>
<span class="text-muted">byalias</span>
<a class="tag" taget="_blank" href="/search/%E5%B7%A5%E4%BD%9C/1.htm">工作</a>
<div>来白虹不知不觉中已经一个多月了,因为项目还在需求分析及项目架构阶段,自己在这段
时间都是在学习相关技术知识,现在对这段时间的工作及学习情况做一个总结:
(1)工作技能方面
大体分为两个阶段,Java Web 基础阶段和Java EE阶段
1)Java Web阶段
在这个阶段,自己主要着重学习了 JSP, Servlet, JDBC, MySQL,这些知识的核心点都过
了一遍,也</div>
</li>
<li><a href="/article/358.htm"
title="Quartz——DateIntervalTrigger触发器" target="_blank">Quartz——DateIntervalTrigger触发器</a>
<span class="text-muted">eksliang</span>
<a class="tag" taget="_blank" href="/search/quartz/1.htm">quartz</a>
<div>转载请出自出处:http://eksliang.iteye.com/blog/2208559 一.概述
simpleTrigger 内部实现机制是通过计算间隔时间来计算下次的执行时间,这就导致他有不适合调度的定时任务。例如我们想每天的 1:00AM 执行任务,如果使用 SimpleTrigger,间隔时间就是一天。注意这里就会有一个问题,即当有 misfired 的任务并且恢复执行时,该执行时间</div>
</li>
<li><a href="/article/485.htm"
title="Unix快捷键" target="_blank">Unix快捷键</a>
<span class="text-muted">18289753290</span>
<a class="tag" taget="_blank" href="/search/unix/1.htm">unix</a><a class="tag" taget="_blank" href="/search/Unix%EF%BC%9B%E5%BF%AB%E6%8D%B7%E9%94%AE%3B/1.htm">Unix;快捷键;</a>
<div>复制,删除,粘贴:
dd:删除光标所在的行 &nbs</div>
</li>
<li><a href="/article/612.htm"
title="获取Android设备屏幕的相关参数" target="_blank">获取Android设备屏幕的相关参数</a>
<span class="text-muted">酷的飞上天空</span>
<a class="tag" taget="_blank" href="/search/android/1.htm">android</a>
<div>包含屏幕的分辨率 以及 屏幕宽度的最大dp 高度最大dp
TextView text = (TextView)findViewById(R.id.text);
DisplayMetrics dm = new DisplayMetrics();
text.append("getResources().ge</div>
</li>
<li><a href="/article/739.htm"
title="要做物联网?先保护好你的数据" target="_blank">要做物联网?先保护好你的数据</a>
<span class="text-muted">蓝儿唯美</span>
<a class="tag" taget="_blank" href="/search/%E6%95%B0%E6%8D%AE/1.htm">数据</a>
<div>根据Beecham Research的说法,那些在行业中希望利用物联网的关键领域需要提供更好的安全性。
在Beecham的物联网安全威胁图谱上,展示了那些可能产生内外部攻击并且需要通过快速发展的物联网行业加以解决的关键领域。
Beecham Research的技术主管Jon Howes说:“之所以我们目前还没有看到与物联网相关的严重安全事件,是因为目前还没有在大型客户和企业应用中进行部署,也就</div>
</li>
<li><a href="/article/866.htm"
title="Java取模(求余)运算" target="_blank">Java取模(求余)运算</a>
<span class="text-muted">随便小屋</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a>
<div> 整数之间的取模求余运算很好求,但几乎没有遇到过对负数进行取模求余,直接看下面代码:
/**
*
* @author Logic
*
*/
public class Test {
public static void main(String[] args) {
// TODO A</div>
</li>
<li><a href="/article/993.htm"
title="SQL注入介绍" target="_blank">SQL注入介绍</a>
<span class="text-muted">aijuans</span>
<a class="tag" taget="_blank" href="/search/sql%E6%B3%A8%E5%85%A5/1.htm">sql注入</a>
<div>二、SQL注入范例
这里我们根据用户登录页面
<form action="" > 用户名:<input type="text" name="username"><br/> 密 码:<input type="password" name="passwor</div>
</li>
<li><a href="/article/1120.htm"
title="优雅代码风格" target="_blank">优雅代码风格</a>
<span class="text-muted">aoyouzi</span>
<a class="tag" taget="_blank" href="/search/%E4%BB%A3%E7%A0%81/1.htm">代码</a>
<div>总结了几点关于优雅代码风格的描述:
代码简单:不隐藏设计者的意图,抽象干净利落,控制语句直截了当。
接口清晰:类型接口表现力直白,字面表达含义,API 相互呼应以增强可测试性。
依赖项少:依赖关系越少越好,依赖少证明内聚程度高,低耦合利于自动测试,便于重构。
没有重复:重复代码意味着某些概念或想法没有在代码中良好的体现,及时重构消除重复。
战术分层:代码分层清晰,隔离明确,</div>
</li>
<li><a href="/article/1247.htm"
title="布尔数组" target="_blank">布尔数组</a>
<span class="text-muted">百合不是茶</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/%E5%B8%83%E5%B0%94%E6%95%B0%E7%BB%84/1.htm">布尔数组</a>
<div>
androi中提到了布尔数组;
布尔数组默认的是false, 并且只会打印false或者是true
布尔数组的例子; 根据字符数组创建布尔数组
char[] c = {'p','u','b','l','i','c'};
//根据字符数组的长度创建布尔数组的个数
boolean[] b = new bool</div>
</li>
<li><a href="/article/1374.htm"
title="web.xml之welcome-file-list、error-page" target="_blank">web.xml之welcome-file-list、error-page</a>
<span class="text-muted">bijian1013</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/web.xml/1.htm">web.xml</a><a class="tag" taget="_blank" href="/search/servlet/1.htm">servlet</a><a class="tag" taget="_blank" href="/search/error-page/1.htm">error-page</a>
<div>welcome-file-list
1.定义:
<welcome-file-list>
<welcome-file>login.jsp</welcome>
</welcome-file-list>
2.作用:用来指定WEB应用首页名称。
error-page1.定义:
<error-page&g</div>
</li>
<li><a href="/article/1501.htm"
title="richfaces 4 fileUpload组件删除上传的文件" target="_blank">richfaces 4 fileUpload组件删除上传的文件</a>
<span class="text-muted">sunjing</span>
<a class="tag" taget="_blank" href="/search/clear/1.htm">clear</a><a class="tag" taget="_blank" href="/search/Richfaces+4/1.htm">Richfaces 4</a><a class="tag" taget="_blank" href="/search/fileupload/1.htm">fileupload</a>
<div> 页面代码
<h:form id="fileForm"> <rich:</div>
</li>
<li><a href="/article/1628.htm"
title="技术文章备忘" target="_blank">技术文章备忘</a>
<span class="text-muted">bit1129</span>
<a class="tag" taget="_blank" href="/search/%E6%8A%80%E6%9C%AF%E6%96%87%E7%AB%A0/1.htm">技术文章</a>
<div>Zookeeper
http://wenku.baidu.com/view/bab171ffaef8941ea76e05b8.html
http://wenku.baidu.com/link?url=8thAIwFTnPh2KL2b0p1V7XSgmF9ZEFgw4V_MkIpA9j8BX2rDQMPgK5l3wcs9oBTxeekOnm5P3BK8c6K2DWynq9nfUCkRlTt9uV</div>
</li>
<li><a href="/article/1755.htm"
title="org.hibernate.hql.ast.QuerySyntaxException: unexpected token: on near line 1解决方案" target="_blank">org.hibernate.hql.ast.QuerySyntaxException: unexpected token: on near line 1解决方案</a>
<span class="text-muted">白糖_</span>
<a class="tag" taget="_blank" href="/search/Hibernate/1.htm">Hibernate</a>
<div>文章摘自:http://blog.csdn.net/yangwawa19870921/article/details/7553181
在编写HQL时,可能会出现这种代码:
select a.name,b.age from TableA a left join TableB b on a.id=b.id
如果这是HQL,那么这段代码就是错误的,因为HQL不支持</div>
</li>
<li><a href="/article/1882.htm"
title="sqlserver按照字段内容进行排序" target="_blank">sqlserver按照字段内容进行排序</a>
<span class="text-muted">bozch</span>
<a class="tag" taget="_blank" href="/search/%E6%8C%89%E7%85%A7%E5%86%85%E5%AE%B9%E6%8E%92%E5%BA%8F/1.htm">按照内容排序</a>
<div>在做项目的时候,遇到了这样的一个需求:
从数据库中取出的数据集,首先要将某个数据或者多个数据按照地段内容放到前面显示,例如:从学生表中取出姓李的放到数据集的前面;
select * fro</div>
</li>
<li><a href="/article/2009.htm"
title="编程珠玑-第一章-位图排序" target="_blank">编程珠玑-第一章-位图排序</a>
<span class="text-muted">bylijinnan</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/%E7%BC%96%E7%A8%8B%E7%8F%A0%E7%8E%91/1.htm">编程珠玑</a>
<div>
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import java.io.Writer;
import java.util.Random;
public class BitMapSearch {
</div>
</li>
<li><a href="/article/2136.htm"
title="Java关于==和equals" target="_blank">Java关于==和equals</a>
<span class="text-muted">chenbowen00</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a>
<div>关于==和equals概念其实很简单,一个是比较内存地址是否相同,一个比较的是值内容是否相同。虽然理解上不难,但是有时存在一些理解误区,如下情况:
1、
String a = "aaa";
a=="aaa";
==> true
2、
new String("aaa")==new String("aaa</div>
</li>
<li><a href="/article/2263.htm"
title="[IT与资本]软件行业需对外界投资热情保持警惕" target="_blank">[IT与资本]软件行业需对外界投资热情保持警惕</a>
<span class="text-muted">comsci</span>
<a class="tag" taget="_blank" href="/search/it/1.htm">it</a>
<div>
我还是那个看法,软件行业需要增强内生动力,尽量依靠自有资金和营业收入来进行经营,避免在资本市场上经受各种不同类型的风险,为企业自主研发核心技术和产品提供稳定,温和的外部环境...
如果我们在自己尚未掌握核心技术之前,企图依靠上市来筹集资金,然后使劲往某个领域砸钱,然</div>
</li>
<li><a href="/article/2390.htm"
title="oracle 数据块结构" target="_blank">oracle 数据块结构</a>
<span class="text-muted">daizj</span>
<a class="tag" taget="_blank" href="/search/oracle/1.htm">oracle</a><a class="tag" taget="_blank" href="/search/%E5%9D%97/1.htm">块</a><a class="tag" taget="_blank" href="/search/%E6%95%B0%E6%8D%AE%E5%9D%97/1.htm">数据块</a><a class="tag" taget="_blank" href="/search/%E5%9D%97%E7%BB%93%E6%9E%84/1.htm">块结构</a><a class="tag" taget="_blank" href="/search/%E8%A1%8C%E7%9B%AE%E5%BD%95/1.htm">行目录</a>
<div>oracle 数据块是数据库存储的最小单位,一般为操作系统块的N倍。其结构为:
块头--〉空行--〉数据,其实际为纵行结构。
块的标准大小由初始化参数DB_BLOCK_SIZE指定。具有标准大小的块称为标准块(Standard Block)。块的大小和标准块的大小不同的块叫非标准块(Nonstandard Block)。同一数据库中,Oracle9i及以上版本支持同一数据库中同时使用标</div>
</li>
<li><a href="/article/2517.htm"
title="github上一些觉得对自己工作有用的项目收集" target="_blank">github上一些觉得对自己工作有用的项目收集</a>
<span class="text-muted">dengkane</span>
<a class="tag" taget="_blank" href="/search/github/1.htm">github</a>
<div>github上一些觉得对自己工作有用的项目收集
技能类
markdown语法中文说明
回到顶部
全文检索
elasticsearch
bigdesk elasticsearch管理插件
回到顶部
nosql
mapdb 支持亿级别map, list, 支持事务. 可考虑做为缓存使用
C</div>
</li>
<li><a href="/article/2644.htm"
title="初二上学期难记单词二" target="_blank">初二上学期难记单词二</a>
<span class="text-muted">dcj3sjt126com</span>
<a class="tag" taget="_blank" href="/search/english/1.htm">english</a><a class="tag" taget="_blank" href="/search/word/1.htm">word</a>
<div>dangerous 危险的
panda 熊猫
lion 狮子
elephant 象
monkey 猴子
tiger 老虎
deer 鹿
snake 蛇
rabbit 兔子
duck 鸭
horse 马
forest 森林
fall 跌倒;落下
climb 爬;攀登
finish 完成;结束
cinema 电影院;电影
seafood 海鲜;海产食品
bank 银行</div>
</li>
<li><a href="/article/2771.htm"
title="8、mysql外键(FOREIGN KEY)的简单使用" target="_blank">8、mysql外键(FOREIGN KEY)的简单使用</a>
<span class="text-muted">dcj3sjt126com</span>
<a class="tag" taget="_blank" href="/search/mysql/1.htm">mysql</a>
<div>一、基本概念
1、MySQL中“键”和“索引”的定义相同,所以外键和主键一样也是索引的一种。不同的是MySQL会自动为所有表的主键进行索引,但是外键字段必须由用户进行明确的索引。用于外键关系的字段必须在所有的参照表中进行明确地索引,InnoDB不能自动地创建索引。
2、外键可以是一对一的,一个表的记录只能与另一个表的一条记录连接,或者是一对多的,一个表的记录与另一个表的多条记录连接。
3、如</div>
</li>
<li><a href="/article/2898.htm"
title="java循环标签 Foreach" target="_blank">java循环标签 Foreach</a>
<span class="text-muted">shuizhaosi888</span>
<a class="tag" taget="_blank" href="/search/%E6%A0%87%E7%AD%BE/1.htm">标签</a><a class="tag" taget="_blank" href="/search/java%E5%BE%AA%E7%8E%AF/1.htm">java循环</a><a class="tag" taget="_blank" href="/search/foreach/1.htm">foreach</a>
<div>1. 简单的for循环
public static void main(String[] args) {
for (int i = 1, y = i + 10; i < 5 && y < 12; i++, y = i * 2) {
System.err.println("i=" + i + " y=" </div>
</li>
<li><a href="/article/3025.htm"
title="Spring Security(05)——异常信息本地化" target="_blank">Spring Security(05)——异常信息本地化</a>
<span class="text-muted">234390216</span>
<a class="tag" taget="_blank" href="/search/exception/1.htm">exception</a><a class="tag" taget="_blank" href="/search/Spring+Security/1.htm">Spring Security</a><a class="tag" taget="_blank" href="/search/%E5%BC%82%E5%B8%B8%E4%BF%A1%E6%81%AF/1.htm">异常信息</a><a class="tag" taget="_blank" href="/search/%E6%9C%AC%E5%9C%B0%E5%8C%96/1.htm">本地化</a>
<div>异常信息本地化
Spring Security支持将展现给终端用户看的异常信息本地化,这些信息包括认证失败、访问被拒绝等。而对于展现给开发者看的异常信息和日志信息(如配置错误)则是不能够进行本地化的,它们是以英文硬编码在Spring Security的代码中的。在Spring-Security-core-x</div>
</li>
<li><a href="/article/3152.htm"
title="DUBBO架构服务端告警Failed to send message Response" target="_blank">DUBBO架构服务端告警Failed to send message Response</a>
<span class="text-muted">javamingtingzhao</span>
<a class="tag" taget="_blank" href="/search/%E6%9E%B6%E6%9E%84/1.htm">架构</a><a class="tag" taget="_blank" href="/search/DUBBO/1.htm">DUBBO</a>
<div> 废话不多说,警告日志如下,不知道有哪位遇到过,此异常在服务端抛出(服务器启动第一次运行会有这个警告),后续运行没问题,找了好久真心不知道哪里错了。
WARN 2015-07-18 22:31:15,272 com.alibaba.dubbo.remoting.transport.dispatcher.ChannelEventRunnable.run(84)</div>
</li>
<li><a href="/article/3279.htm"
title="JS中Date对象中几个用法" target="_blank">JS中Date对象中几个用法</a>
<span class="text-muted">leeqq</span>
<a class="tag" taget="_blank" href="/search/JavaScript/1.htm">JavaScript</a><a class="tag" taget="_blank" href="/search/Date/1.htm">Date</a><a class="tag" taget="_blank" href="/search/%E6%9C%80%E5%90%8E%E4%B8%80%E5%A4%A9/1.htm">最后一天</a>
<div>近来工作中遇到这样的两个需求
1. 给个Date对象,找出该时间所在月的第一天和最后一天
2. 给个Date对象,找出该时间所在周的第一天和最后一天
需求1中的找月第一天很简单,我记得api中有setDate方法可以使用
使用setDate方法前,先看看getDate
var date = new Date();
console.log(date);
// Sat J</div>
</li>
<li><a href="/article/3406.htm"
title="MFC中使用ado技术操作数据库" target="_blank">MFC中使用ado技术操作数据库</a>
<span class="text-muted">你不认识的休道人</span>
<a class="tag" taget="_blank" href="/search/sql/1.htm">sql</a><a class="tag" taget="_blank" href="/search/mfc/1.htm">mfc</a>
<div>1.在stdafx.h中导入ado动态链接库
#import"C:\Program Files\Common Files\System\ado\msado15.dll" no_namespace rename("EOF","end")2.在CTestApp文件的InitInstance()函数中domodal之前写::CoIniti</div>
</li>
<li><a href="/article/3533.htm"
title="Android Studio加速" target="_blank">Android Studio加速</a>
<span class="text-muted">rensanning</span>
<a class="tag" taget="_blank" href="/search/android+studio/1.htm">android studio</a>
<div>Android Studio慢、吃内存!启动时后会立即通过Gradle来sync & build工程。
(1)设置Android Studio
a) 禁用插件
File -> Settings... Plugins 去掉一些没有用的插件。
比如:Git Integration、GitHub、Google Cloud Testing、Google Cloud</div>
</li>
<li><a href="/article/3660.htm"
title="各数据库的批量Update操作" target="_blank">各数据库的批量Update操作</a>
<span class="text-muted">tomcat_oracle</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/oracle/1.htm">oracle</a><a class="tag" taget="_blank" href="/search/sql/1.htm">sql</a><a class="tag" taget="_blank" href="/search/mysql/1.htm">mysql</a><a class="tag" taget="_blank" href="/search/sqlite/1.htm">sqlite</a>
<div>MyBatis的update元素的用法与insert元素基本相同,因此本篇不打算重复了。本篇仅记录批量update操作的
sql语句,懂得SQL语句,那么MyBatis部分的操作就简单了。 注意:下列批量更新语句都是作为一个事务整体执行,要不全部成功,要不全部回滚。
MSSQL的SQL语句
WITH R AS(
SELECT 'John' as name, 18 as</div>
</li>
<li><a href="/article/3787.htm"
title="html禁止清除input文本输入缓存" target="_blank">html禁止清除input文本输入缓存</a>
<span class="text-muted">xp9802</span>
<a class="tag" taget="_blank" href="/search/input/1.htm">input</a>
<div>多数浏览器默认会缓存input的值,只有使用ctl+F5强制刷新的才可以清除缓存记录。如果不想让浏览器缓存input的值,有2种方法:
方法一: 在不想使用缓存的input中添加 autocomplete="off"; eg: <input type="text" autocomplete="off" name</div>
</li>
</ul>
</div>
</div>
</div>
<div>
<div class="container">
<div class="indexes">
<strong>按字母分类:</strong>
<a href="/tags/A/1.htm" target="_blank">A</a><a href="/tags/B/1.htm" target="_blank">B</a><a href="/tags/C/1.htm" target="_blank">C</a><a
href="/tags/D/1.htm" target="_blank">D</a><a href="/tags/E/1.htm" target="_blank">E</a><a href="/tags/F/1.htm" target="_blank">F</a><a
href="/tags/G/1.htm" target="_blank">G</a><a href="/tags/H/1.htm" target="_blank">H</a><a href="/tags/I/1.htm" target="_blank">I</a><a
href="/tags/J/1.htm" target="_blank">J</a><a href="/tags/K/1.htm" target="_blank">K</a><a href="/tags/L/1.htm" target="_blank">L</a><a
href="/tags/M/1.htm" target="_blank">M</a><a href="/tags/N/1.htm" target="_blank">N</a><a href="/tags/O/1.htm" target="_blank">O</a><a
href="/tags/P/1.htm" target="_blank">P</a><a href="/tags/Q/1.htm" target="_blank">Q</a><a href="/tags/R/1.htm" target="_blank">R</a><a
href="/tags/S/1.htm" target="_blank">S</a><a href="/tags/T/1.htm" target="_blank">T</a><a href="/tags/U/1.htm" target="_blank">U</a><a
href="/tags/V/1.htm" target="_blank">V</a><a href="/tags/W/1.htm" target="_blank">W</a><a href="/tags/X/1.htm" target="_blank">X</a><a
href="/tags/Y/1.htm" target="_blank">Y</a><a href="/tags/Z/1.htm" target="_blank">Z</a><a href="/tags/0/1.htm" target="_blank">其他</a>
</div>
</div>
</div>
<footer id="footer" class="mb30 mt30">
<div class="container">
<div class="footBglm">
<a target="_blank" href="/">首页</a> -
<a target="_blank" href="/custom/about.htm">关于我们</a> -
<a target="_blank" href="/search/Java/1.htm">站内搜索</a> -
<a target="_blank" href="/sitemap.txt">Sitemap</a> -
<a target="_blank" href="/custom/delete.htm">侵权投诉</a>
</div>
<div class="copyright">版权所有 IT知识库 CopyRight © 2000-2050 E-COM-NET.COM , All Rights Reserved.
<!-- <a href="https://beian.miit.gov.cn/" rel="nofollow" target="_blank">京ICP备09083238号</a><br>-->
</div>
</div>
</footer>
<!-- 代码高亮 -->
<script type="text/javascript" src="/static/syntaxhighlighter/scripts/shCore.js"></script>
<script type="text/javascript" src="/static/syntaxhighlighter/scripts/shLegacy.js"></script>
<script type="text/javascript" src="/static/syntaxhighlighter/scripts/shAutoloader.js"></script>
<link type="text/css" rel="stylesheet" href="/static/syntaxhighlighter/styles/shCoreDefault.css"/>
<script type="text/javascript" src="/static/syntaxhighlighter/src/my_start_1.js"></script>
</body>
</html>