valgrind工具简单使用
1概述
1.1 介绍
Valgrind是一套Linux下,开放源代码(GPL V2)的仿真调试工具的集合。Valgrind由内核(core)以及基于内核的其他调试工具组成。内核类似于一个框架(framework),它模拟了一个CPU环境,并提供服务给其他工具;而其他工具则类似于插件 (plug-in),利用内核提供的服务完成各种特定的内存调试任务。Valgrind的体系结构如下图所示:
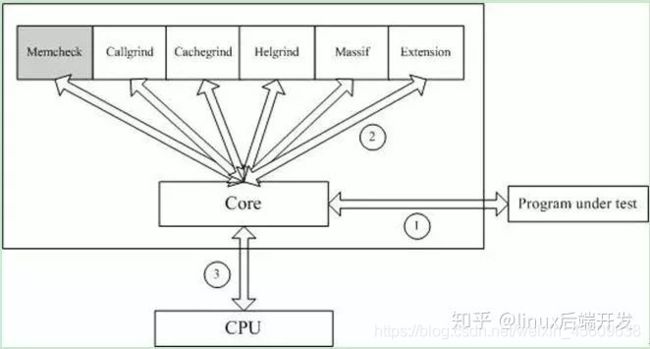
1.2 工具
Valgrind它一般包含下列工具:
1.Memcheck
最常用的工具,用来检测程序中出现的内存问题,所有对内存的读写都会被检测到,一切对malloc()/free()/new/delete的调用都会被捕获。所以,它能检测以下问题:
对未初始化内存的使用;
读/写释放后的内存块;
读/写超出malloc分配的内存块;
读/写不适当的栈中内存块;
内存泄漏,指向一块内存的指针永远丢失;
不正确的malloc/free或new/delete匹配;
memcpy()相关函数中的dst和src指针重叠。
2.Callgrind
和gprof类似的分析工具,但它对程序的运行观察更是入微,能给我们提供更多的信息。和gprof不同,它不需要在编译源代码时附加特殊选项,但加上调试选项是推荐的。Callgrind收集程序运行时的一些数据,建立函数调用关系图,还可以有选择地进行cache模拟。在运行结束时,它会把分析数据写入一个文件。callgrind_annotate可以把这个文件的内容转化成可读的形式。
3.Cachegrind
Cache分析器,它模拟CPU中的一级缓存I1,Dl和二级缓存,能够精确地指出程序中cache的丢失和命中。如果需要,它还能够为我们提供cache丢失次数,内存引用次数,以及每行代码,每个函数,每个模块,整个程序产生的指令数。这对优化程序有很大的帮助。
4.Helgrind
它主要用来检查多线程程序中出现的竞争问题。Helgrind寻找内存中被多个线程访问,而又没有一贯加锁的区域,这些区域往往是线程之间失去同步的地方,而且会导致难以发掘的错误。Helgrind实现了名为“Eraser”的竞争检测算法,并做了进一步改进,减少了报告错误的次数。不过,Helgrind仍然处于实验阶段。
5.Massif
堆栈分析器,它能测量程序在堆栈中使用了多少内存,告诉我们堆块,堆管理块和栈的大小。Massif能帮助我们减少内存的使用,在带有虚拟内存的现代系统中,它还能够加速我们程序的运行,减少程序停留在交换区中的几率。
此外,lackey和nulgrind也会提供。Lackey是小型工具,很少用到;Nulgrind只是为开发者展示如何创建一个工具。
1.3 原理
Memcheck 能够检测出内存问题,关键在于其建立了两个全局表。Valid-Value 表
对于进程的整个地址空间中的每一个字节(byte),都有与之对应的 8 个 bits;对于CPU的每个寄存器,也有一个与之对应的bit向量。这些bits负责记录该字节或者寄存器值是否具有有效的、已初始化的值。
Valid-Address 表
对于进程整个地址空间中的每一个字节(byte),还有与之对应的1个bit,负责记录该地址是否能够被读写。
检测原理:
当要读写内存中某个字节时,首先检查这个字节对应的 A bit。如果该A bit显示该位置是无效位置,memcheck则报告读写错误。
内核(core)类似于一个虚拟的 CPU 环境,这样当内存中的某个字节被加载到真实的 CPU 中时,该字节对应的 V bit 也被加载到虚拟的 CPU 环境中。一旦寄存器中的值,被用来产生内存地址,或者该值能够影响程序输出,则 memcheck 会检查对应的V bits,如果该值尚未初始化,则会报告使用未初始化内存错误。
2 安装使用
2.1安装
从官网http://www.valgrind.org下载最新版本
#tar xvf valgrind-3.15.0.tar.bz2
#cd valgrind-3.15.0
#./configure --prefix=/usr/local/valgrind--指定安装目录
#make
#make install
3.实际用例
3.1.Memcheck
源码如下:
int main(void)
{
char *p = malloc(1);
*p = 'a';
char c = *p;
printf("\n [%c]\n",c);
free(p);
c = *p;
return 0;
}
编译运行监测
gcc -g test1.c
valgrind/bin/valgrind --tool=memcheck --leak-check=full ./a.out
运行结果如下:
==53979== Memcheck, a memory error detector
==53979== Copyright (C) 2002-2017, and GNU GPL'd, by Julian Seward et al.
==53979== Using Valgrind-3.15.0 and LibVEX; rerun with -h for copyright info
==53979== Command: ./a.out
==53979==
==53979== Invalid write of size 4
==53979== at 0x400544: k (test1.c:5)
==53979== by 0x400555: main (test1.c:10)
==53979== Address 0x5205064 is 4 bytes after a block of size 32 alloc'd
==53979== at 0x4C2DE96: malloc (vg_replace_malloc.c:309)
==53979== by 0x400537: k (test1.c:4)
==53979== by 0x400555: main (test1.c:10)
==53979==
==53979==
==53979== HEAP SUMMARY:
==53979== in use at exit: 32 bytes in 1 blocks
==53979== total heap usage: 1 allocs, 0 frees, 32 bytes allocated
==53979==
==53979== 32 bytes in 1 blocks are definitely lost in loss record 1 of 1
==53979== at 0x4C2DE96: malloc (vg_replace_malloc.c:309)
==53979== by 0x400537: k (test1.c:4)
==53979== by 0x400555: main (test1.c:10)
==53979==
==53979== LEAK SUMMARY:
==53979== definitely lost: 32 bytes in 1 blocks
==53979== indirectly lost: 0 bytes in 0 blocks
==53979== possibly lost: 0 bytes in 0 blocks
==53979== still reachable: 0 bytes in 0 blocks
==53979== suppressed: 0 bytes in 0 blocks
==53979==
==53979== For lists of detected and suppressed errors, rerun with: -s
==53979== ERROR SUMMARY: 2 errors from 2 contexts (suppressed: 0 from 0)
2.Callgrind
源码callgrind_test.c
#include 编译运行
gcc -g callgrind_test.c -o callgrind_test
valgrind/bin/valgrind --tool=callgrind ./callgrind_test --dump-instr=yes --trace-jump=yes
在linux上安装kcachegrind
sudo apt install valgrind kcachegrind
运行kcachegrind并打开callgrind.out.54101
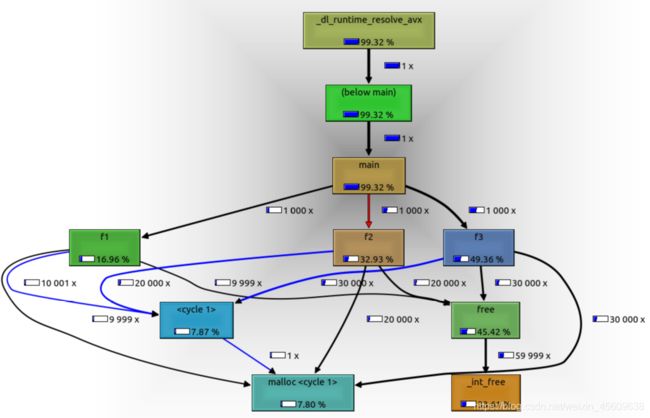
3.Cachegrind
cache1.c
#include 编译cache1.c运行分析:
gcc -g cache1.c -o cache1.out
valgrind --tool=cachegrind ./cache1.out
==54031== Cachegrind, a cache and branch-prediction profiler
==54031== Copyright (C) 2002-2017, and GNU GPL'd, by Nicholas Nethercote et al.
==54031== Using Valgrind-3.15.0 and LibVEX; rerun with -h for copyright info
==54031== Command: ./cache1.out
==54031==
--54031-- warning: L3 cache found, using its data for the LL simulation.
Starting!
Completed!
==54031==
==54031== I refs: 768,207,507
==54031== I1 misses: 862
==54031== LLi misses: 853
==54031== I1 miss rate: 0.00%
==54031== LLi miss rate: 0.00%
==54031==
==54031== D refs: 448,081,602 (384,062,315 rd + 64,019,287 wr)
==54031== D1 misses: 4,002,891 ( 2,330 rd + 4,000,561 wr)
==54031== LLd misses: 4,002,490 ( 1,969 rd + 4,000,521 wr)
==54031== D1 miss rate: 0.9% ( 0.0% + 6.2% )//0.9%
==54031== LLd miss rate: 0.9% ( 0.0% + 6.2% )
==54031==
==54031== LL refs: 4,003,753 ( 3,192 rd + 4,000,561 wr)
==54031== LL misses: 4,003,343 ( 2,822 rd + 4,000,521 wr)
==54031== LL miss rate: 0.3% ( 0.0% + 6.2% )
cache2.c
#include 编译cache2.c运行分析:
gcc -g cache2.c -o cache2.out
valgrind --tool=cachegrind ./cache2.out
==54042== Cachegrind, a cache and branch-prediction profiler
==54042== Copyright (C) 2002-2017, and GNU GPL'd, by Nicholas Nethercote et al.
==54042== Using Valgrind-3.15.0 and LibVEX; rerun with -h for copyright info
==54042== Command: ./cache2.out
==54042==
--54042-- warning: L3 cache found, using its data for the LL simulation.
Starting!
Completed!
==54042==
==54042== I refs: 768,207,507
==54042== I1 misses: 862
==54042== LLi misses: 853
==54042== I1 miss rate: 0.00%
==54042== LLi miss rate: 0.00%
==54042==
==54042== D refs: 448,081,602 (384,062,315 rd + 64,019,287 wr)
==54042== D1 misses: 64,002,890 ( 2,330 rd + 64,000,560 wr)
==54042== LLd misses: 4,010,489 ( 1,969 rd + 4,008,520 wr)
==54042== D1 miss rate: 14.3% ( 0.0% + 100.0% ) //14.3%
==54042== LLd miss rate: 0.9% ( 0.0% + 6.3% )
==54042==
==54042== LL refs: 64,003,752 ( 3,192 rd + 64,000,560 wr)
==54042== LL misses: 4,011,342 ( 2,822 rd + 4,008,520 wr)
==54042== LL miss rate: 0.3% ( 0.0% + 6.3% )
显然是cache1的cache miss rate较低,程序的代码质量更高效.
4.Massif
源码massif_test.c
#include 编译运行测试
gcc -g massif_test.c -o massif_test
valgrind --tool=massif --time-unit=B ./massif_test
massif.out.57230
--------------------------------------------------------------------------------
Command: ./massif_test
Massif arguments: --time-unit=B
ms_print arguments: massif.out.57250
--------------------------------------------------------------------------------
B
112^ ############
| #
| #
| #
| #
| #
| #
| #
| #
| #
| @@@@@@@@@@@@ ::::::::::::# :::::::::::
| @ : # :
| @ : # :
| @ : # :
| @ : # :
| @ : # :
| @ : # :
| @ : # :
| @ : # :
| @ : # :
0 +----------------------------------------------------------------------->B
0 336
本文参考:
https://zhuanlan.zhihu.com/p/75416381
http://blog.chinaunix.net/uid-29242873-id-4065255.html
https://www.jianshu.com/p/9e14e9936ff1?tdsourcetag=s_pctim_aiomsg
https://blog.csdn.net/u010168781/article/details/83788559