Python爬虫豆瓣租房信息
任务描述
使用python爬虫,实现获取豆瓣“深圳租房团”的租房信息,并筛选适合个人的房源存入Excel。
实现方案
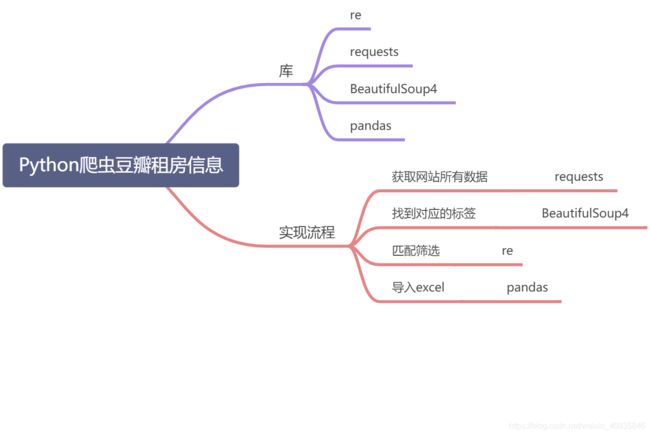
获取网站所有数据 requests
多个网站时,无法输入参数,使用 idx 来索引需要的网页,然后循环获取
import requests
def download_all_htmls():
"""
获取所有列表页面的HTML,用于后续的分析
"""
htmls = []
for idx in page_indexs:
url = f"https://www.douban.com/group/106955/discussion?start={idx}"
print("craw html:", url)
r = requests.get(url,
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)"})
if r.status_code != 200:
raise Exception("error")
htmls.append(r.text)
return htmls
htmls = download_all_htmls()
若只需要获取单个网站,可以直接把网址当做参数输入
import requests
def download_specific_htmls(url):
print("craw html:", url)
r = requests.get(url,
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)"})
if r.status_code != 200:
raise Exception("error")
html = r.text
return html
找到对应标签 BeautifulSoup4
利用 find 、find_all 两个函数来找到对应的标签, get_text 来获取文本。
from bs4 import BeautifulSoup
def parse_single_html(html):
"""
解析单个HTML,得到数据
@return list({"link", "title", [label]})
"""
soup = BeautifulSoup(html, 'html.parser')
article_items = (
soup.find("table", class_="olt")
.find_all("tr", class_="")
)
datas = []
for article_item in article_items:
#rank = article_item.find("div", class_="pic").find("em").get_text()
#info = article_item.find("div", class_="info")
title = article_item.find("td", class_="title").get_text()
link = article_item.find("a")["href"]
datas.append({
"title":title,
"link":link
})
return datas
匹配筛选 re
中文很难使用 re.match 进行匹配,一直纠结在各种编码上,最后使用了 re.search 函数来代替
title = article_item.find("td", class_="title").get_text()
link = article_item.find("a")["href"]
res1 = re.search("前海湾|临海|宝华|宝安中心|翻身|灵芝|洪浪北",title)
res2 = re.search("求租|合租",title)
res3 = re.search("1[0-9][0-9][0-9]", title)
res4 = re.search("2[0-5][0-9][0-9]", title)
res5 = re.search("一房一厅|一厅一房|一室一厅|一厅一室", title)
if res1 is not None and res2 is None:
if res3 or res4 is not None:
if res5 is not None:
datas.append({
"title":title,
"link":link
})
else:
#html_specific = []
html_specific = download_specific_htmls(link)
soup_specific = BeautifulSoup(html_specific, 'html.parser')
article_box = soup_specific.find("div", class_="article").find("div", class_="topic-content clearfix").find("div",class_="topic-doc").find("div",class_="topic-content").find("div",class_="topic-richtext")
text = article_box.get_text()
print(text)
res_specific1 = re.search("一房一厅|一厅一房|一室一厅|一厅一室",text)
res_specific2 = re.search("合租",text)
if res_specific1 is not None and res_specific2 is None:
datas.append({
"title":title,
"link":link
})
导入excel pandas
使用pandas进行导入
all_datas = []
for html in htmls:
all_datas.extend(parse_single_html(html))
#print(all_datas)
df = pd.DataFrame(all_datas)
df.to_excel("test.xlsx")
结果

完整代码
import requests
from bs4 import BeautifulSoup
import pandas as pd
import re
page_indexs = range(0,10000,25)
def download_all_htmls():
"""
下载所有列表页面的HTML,用于后续的分析
"""
htmls = []
for idx in page_indexs:
url = f"https://www.douban.com/group/106955/discussion?start={idx}"
print("craw html:", url)
r = requests.get(url,
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)"})
if r.status_code != 200:
raise Exception("error")
htmls.append(r.text)
return htmls
htmls = download_all_htmls()
def download_specific_htmls(url):
"""
下载所有列表页面的HTML,用于后续的分析
"""
print("craw html:", url)
r = requests.get(url,
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)"})
if r.status_code != 200:
raise Exception("error")
html = r.text
return html
def parse_single_html(html):
"""
解析单个HTML,得到数据
@return list({"link", "title", [label]})
"""
soup = BeautifulSoup(html, 'html.parser')
article_items = (
soup.find("table", class_="olt")
.find_all("tr", class_="")
)
datas = []
for article_item in article_items:
#rank = article_item.find("div", class_="pic").find("em").get_text()
#info = article_item.find("div", class_="info")
title = article_item.find("td", class_="title").get_text()
link = article_item.find("a")["href"]
res1 = re.search("前海湾|临海|宝华|宝安中心|翻身|灵芝|洪浪北",title)
res2 = re.search("求租|合租",title)
res3 = re.search("1[0-9][0-9][0-9]", title)
res4 = re.search("2[0-5][0-9][0-9]", title)
res5 = re.search("一房一厅|一厅一房|一室一厅|一厅一室", title)
if res1 is not None and res2 is None:
if res3 or res4 is not None:
if res5 is not None:
datas.append({
"title":title,
"link":link
})
else:
#html_specific = []
html_specific = download_specific_htmls(link)
soup_specific = BeautifulSoup(html_specific, 'html.parser')
article_box = soup_specific.find("div", class_="article").find("div", class_="topic-content clearfix").find("div",class_="topic-doc").find("div",class_="topic-content").find("div",class_="topic-richtext")
text = article_box.get_text()
print(text)
res_specific1 = re.search("一房一厅|一厅一房|一室一厅|一厅一室",text)
res_specific2 = re.search("合租",text)
if res_specific1 is not None and res_specific2 is None:
datas.append({
"title":title,
"link":link
})
return datas
all_datas = []
for html in htmls:
all_datas.extend(parse_single_html(html))
#print(all_datas)
df = pd.DataFrame(all_datas)
df.to_excel("test.xlsx")