记一下机器学习笔记 Rosenblatt感知机
一入ML深似海啊…
这里主要是《神经网络与机器学习》(Neural Networks and Learning Machines,以下简称《神机》)的笔记,以及一些周志华的《机器学习》的内容,可能夹杂有自己的吐槽,以及自己用R语言随便撸的实现。
话说这个《神经网络与机器学习》还真是奇书,不知是作者风格还是翻译问题,一眼望去看不到几句人话(也许是水利狗看不懂),感觉我就是纯买来自虐的。
作为开始当然是最古老的机器学习算法之一,神经网络的板砖感知机,对应《神机》的第一章。
因为是Rosenblatt提出的模型所以就加上了他名字作为前缀。这是一个有监督学习,也就是不仅给出自变量还要给出结果值让机器自个拟合的模型,而且是一个二分类模型。再说清楚一点,这玩意只能分线性可分的样本,也就是对于二维的数据,它只能搞一条直线把样本分开,对于三维的数据,只能搞个平面把样本分开。
所以像居然连异或运算都不能弄之类的对它的吐槽历来不少。
感知机概念
感知机由一个线性组合器(说白了就是把一系列输入值加权求和)以及一个硬限幅器(说白了就是拿前面的求和取符号)组成。具体样子参考下图(来自《神机》):

我们将一组输入值记为 x1,x2,...,xm ,相应的权值记为 w1,w2,w3...wm ,另外还要有个偏置值 b (相当于线性回归里边的截距)。把这些输入到感知机里边进行加权求和:
加权和 v 称为 诱导局部域。
然后对这个 v 取符号,也就是大于0取1,小于0取-1,就这样决定这组输入值归为哪类:
可以用逼格更高的矩阵形式简洁表示:
x 和 w 就是把 w1,w2,w3...wm 和 x1,x2,...,xm 写成一列阵,然后把前者转置为横阵再两矩阵相乘,也就是两者对应的每一项相乘再求和。
那么每组输入值 x 就各是一个样本。
又或者从几何角度理解:在m维空间上有这么一个超平面 wTx+b=0 , x=[x1,x2,...,xm]T 是这个空间上的一个点,这个点在超平面的一边归为一类,若在另一边归为另一类。
所以说样本必须线性可分的才可以被它分类。
感知机收敛定理
然后这玩意的学习方式是不断的误差修正,称为误差修正学习原则。
当一个样本被正确分类的时候就没啥事,要是被错误分类了就根据样本的各个分量调整权值,就这样把整套样本丢进去跑几趟直到误差收敛为止。
现在干脆把偏置 b 弄进样本 x 里去,定义第n个输入样本:
然后根据迭代步数n把权值向量这样定义:
其中 w0(n) 即对应偏置 b 。这样输出可以简约的改成:
经过学习之后的感知机应该有这么一套权值 w :
所以感知机的权值修改策略是这样子的:
否则如果分类错了,就进行如下修改:
也就是分类错误的时候就把权值向量 w 相应的加上或减去该次迭代的乘上一个系数 η 后的输入样本向量 x 。
其中系数 η 称为 学习率参数。
将一批N个样本挨个输入到感知机中挨个调整权值的过程称为一次迭代,迭代的过程就是把这批样本不断输进去重复迭代多次。只要这些样本是线性可分的,那么经过若干次迭代之后最终必定能让感知机正确分类全部样本,也就是收敛。这就是感知机收敛定理。
证明详见《神机》第1.3节…
具体一点,将 d(n) 定义为量化的第n个样本应归的类,称为量化期望响应,即:
那么权值向量 w(n) 的逐步修正可以这样表示:
d(n)−y(n) 为误差信号,学习率参数 η 是正常数,值大于0并小于等于1。在这里可以这样理解,上式右边的后半部分里, [d(n)−y(n)]x(n) 定义的是修正权值一个方向,而 η 定义的是朝着这个方向走的一步的大小。
所以学习率参数 η 的大小设定一直都是纠结的,太大了走起来不稳定,太小了又走得太慢…
R代码实现
我知道不用Python而是用R这么个非主流的语言一定会有很多人吐槽,毕竟R的可读性是硬伤…这里使用R的原因有二:一是借助R原生的向量和矩阵运算功能和其他各种统计函数实现起来可以简洁些,二是我实在是不熟悉Python…
《神机》上边演示各种算法时用的是一对非对称的面对面又有些错开的“双月牙”二维数据集,分布在上月牙的样本归为一个类,下月牙的归为另一个类,然后用各种算法分离这两个月牙。
首先生成双月数据集,先设定样本数量为2000,两个月牙距离为1,半径10,宽度6,样本坐标为月牙内随机生成:
library(ggplot2)# 先导入作图包
R = 10 #月牙半径
wid = 6 #月牙宽度
dis = 1 #月牙距离
N = 2000 #样本数量
i = 0
x1=c()
x2=c()
d=c() #
# 在月牙范围内随机生成点
while(i < N/2){
xi = runif(1,-R-wid/2,R+wid/2); xj = runif(1,0,R+wid/2)
r = sqrt(xi*xi+xj*xj)
if(R+wid/2 >= r && R-wid/2 <= r){
i=i+1
x1[i]=xi; x2[i]=xj; d[i]=-1
}
}#生成上半月牙
while(i < N){
xi = runif(1,-wid/2,2*R+wid/2); xj = runif(1,-dis-R-wid,-dis)
r = sqrt((xi-R)*(xi-R)+(xj+dis)*(xj+dis))
if(R+wid/2 >= r && R-wid/2 <= r){
i=i+1
x1[i]=xi; x2[i]=xj; d[i]=1
}
}#生成下半月牙
# 没什么特别的,就是拿来打乱数据顺序
rndodr = order(runif(N))
x1=x1[rndodr]
x2=x2[rndodr]
d=d[rndodr]
qplot(x1,x2,color=factor(d))#可视化
# 生成矩阵形式的数据集
dat = as.matrix(data.frame(x1,x2))其中x1和x2分别是样本点的横纵坐标,d为样本点的归类。
可视化之后如下:
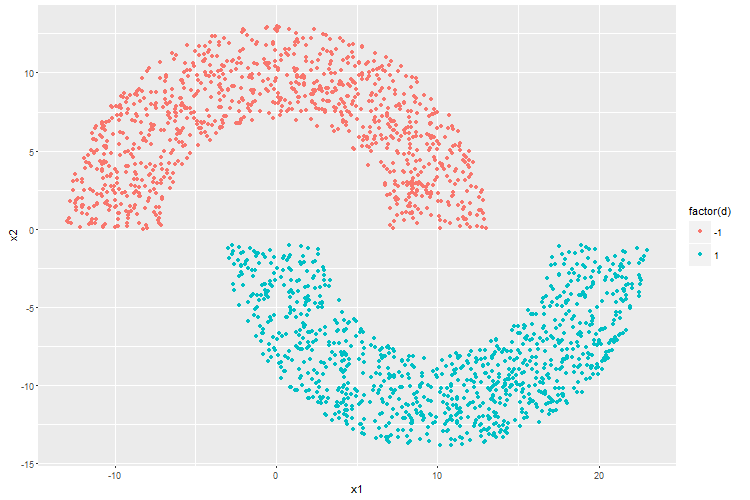
然后就是定义感知机和训练。根据《神机》分类误差用均方差表示。
# 感知机,输入为一个长度2的向量。
perceptron = function(x) sign(t(w) %*% c(x,+1))
# 之所以将偏置项+1放到最后面是因为R是从1开始索引的而不是0...
w=c(0,0,0) # 初始化权值
n=50 #迭代次数
eta = seq(1e-1,1e-5,length.out = n)#学习率参数eta设为从1E-1到1E-5的线性退火
MSE = c()#记录每次迭代后的均方差
# 训练
for(j in 1:n){
for(i in 1:N){
x = dat[i,]
y = perceptron(x)
w = w + eta[j] * (d[i] - y) * c(x,1)
}# 丢入数据集中的每一个数据进行训练
# 迭代完一次就对数据集进行分类然后计算均方差
e = d - apply(dat,1,perceptron)
mse = sqrt(sum(e*e)/n)
MSE=append(MSE,mse)
}训练完输出结果:
# 绘制均方差随迭代次数的变化曲线
qplot(x=c(1:n),y=MSE,geom = 'line')
# 绘制直观的样本划分情况
y = apply(dat,1,perceptron)
qplot(x1,x2,color=factor(y)) + geom_abline(intercept = -w[3]/w[2], slope = -w[1]/w[2])
# 统计误识别率
length(e[e!=0])/N然后这是训练完的分类结果。
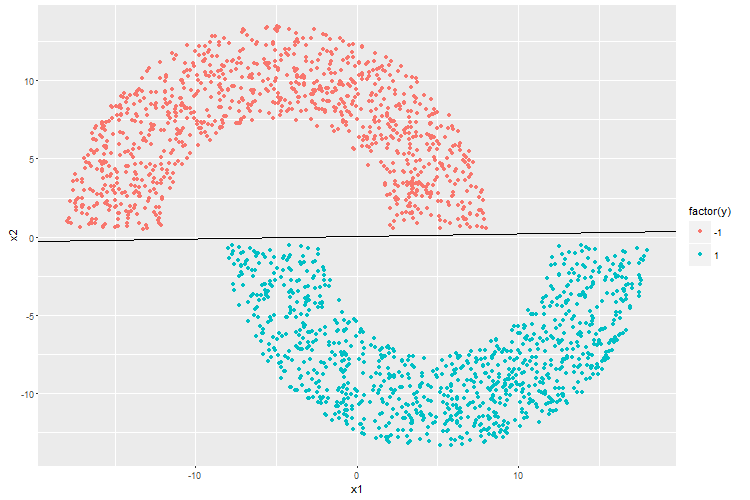
可见感知机很轻易的就把俩月牙完好得分开了。

再看均方根误差的变化曲线,可以看到第一轮迭代就已经收敛。
之后再试试俩月牙的距离为0的情况。这时俩月牙情况如下:

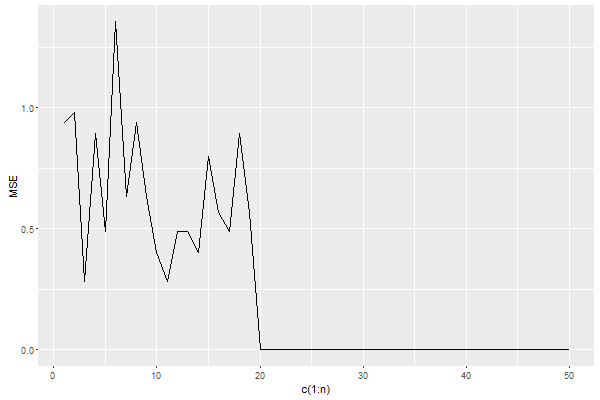
经过50轮迭代之后也顺利收敛,误识别率依然为0(因为随机生成点的关系不太可能有几个点同时在边界上)。

可以看到大概是在第20轮迭代之后收敛的。
再接下来就试试月牙间距离为-4的情况。这时候俩月牙已经不是线性可分了,看看感知机会如何整?
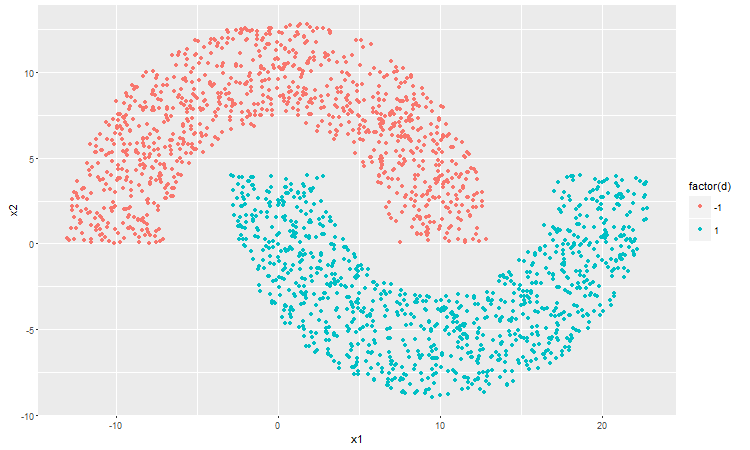
迭代完发现虽然不能做到但是感知机还是尽力地让俩月牙的点尽量分开了,于是成了这个样子。

均方根误差是酱紫抖动的。

再看看误识别率:
> length(e[e!=0])/N
[1] 0.0945有9.45%的样本被错误分类了。
顺便附上月牙距离分别为0和-4时感知机训练过程的动图:
这里是距离为0的:
这里是距离为-4的: