大数据名词解释
大数据名词解释
- 大数据知识体系架构
-
- 第一阶段:Hadoop
-
- 一、ELK技术栈:
- 二、HDFS:Hadoop分布式文件系统
- 三、MapReduce:
- 四、Apache Hive:
- 五、Apache HBase:
- 六、Apache Sqoop:
- 七、Zeppelin可视化:
- 第二阶段:Spark
-
- 一、Scala编程
- 二、Spark 生态框架
- 三、Flume
- 四、Apache Kafka
- 第三阶段:离线数据平台
-
- 一、Hive ETL处理
- 二、Oozie
- 工作流:
- 三、Tableau可视化
- 四、Cassandra/Redis/MongoDB
- 第四阶段:实时流处理平台
- 核心技术小结
-
- Hadoop
- Spark
- Flink
- Hive
- ELK
- Scala
大数据知识体系架构
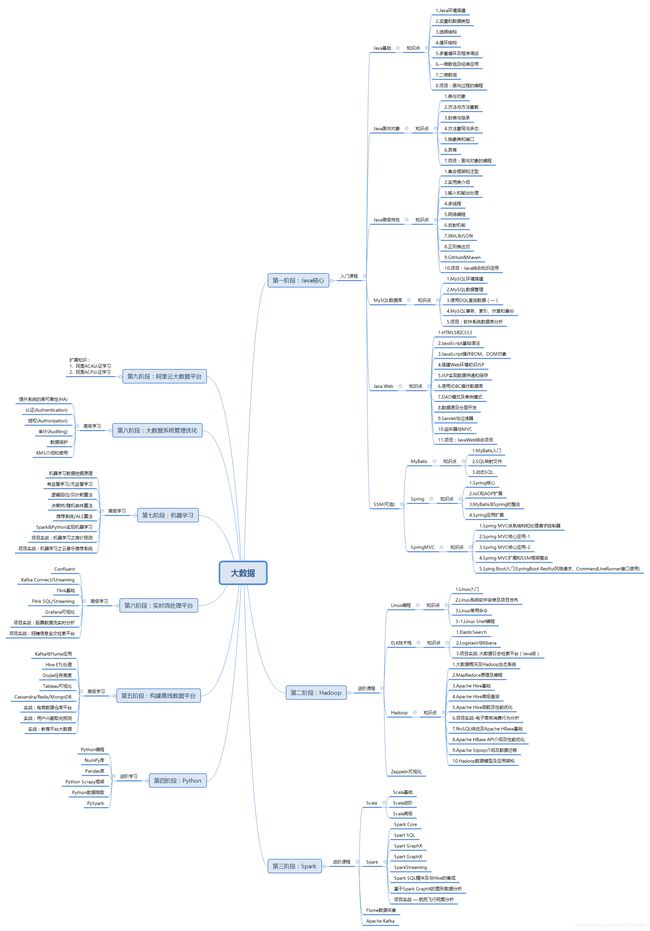
第一阶段:Hadoop
一、ELK技术栈:
ELK Stack 是 Elasticsearch、Logstash、Kibana 三个开源软件的组合。在实时数据检索和分析场合,三者通常是配合共用。
Elasticsearch:分布式搜索和分析引擎,具有高可伸缩、高可靠和易管理等特点。基于 Apache Lucene 构建,能对大容量的数据进行接近实时的存储、搜索和分析操作。通常被用作某些应用的基础搜索引擎,使其具有复杂的搜索功能;
Logstash:数据处理引擎,它支持动态的从各种数据源搜集数据,并对数据进行过滤、分析、丰富、统一格式等操作,然后存储到 ES;
Kibana:数据分析和可视化平台。与 Elasticsearch 配合使用,对数据进行搜索、分析和以统计图表的方式展示;
Filebeat:ELK 协议栈的新成员,一个轻量级开源日志文件数据搜集器。在需要采集日志数据的 server 上安装 Filebeat,并指定日志目录或日志文件后,Filebeat 就能读取数据,迅速发送到 Logstash 进行解析。
二、HDFS:Hadoop分布式文件系统
HDFS(Hadoop Distributed File System)是hadoop生态系统中最基础的一部分,是hadoop中的的存储组件。
HDFS是一个分布式文件系统,以流式数据访问模式存储超大文件,将数据分块存储到一个商业硬件集群内的不同机器上。
HDFS涉及到数据存储,MapReduce等计算模型都要依赖于存储在HDFS中的数据。
HDFS的特点>
(1)超大文件。目前的hadoop集群能够存储几百TB甚至PB级的数据。
(2)流式数据访问。HDFS的访问模式是:一次写入,多次读取,更加关注的是读取整个数据集的整体时间。
(3)商用硬件。HDFS集群的设备不需要多么昂贵和特殊,只要是一些日常使用的普通硬件即可。
(4)不支持低时间延迟的数据访问。hdfs关心的是高数据吞吐量,不适合那些要求低时间延迟数据访问的应用。
(5)单用户写入。hdfs的数据以读为主,只支持单个写入者,写操作总是以添加的形式在文末追加,不支持在任意位置进行修改。
HDFS由四部分组成:
HDFS Client、NameNode、DataNode和Secondary NameNode。
HDFS是一个主/从(Mater/Slave)体系结构。
HDFS集群拥有一个NameNode和一些DataNode。NameNode管理文件系统的元数据,DataNode存储实际的数据。
三、MapReduce:
MapReduce是面向大数据并行处理的计算模型、框架和平台,主要用于大规模数据集(大于1TB)的并行运算。
MapReduce是一种编程模板,编写MapReduce程序的主要目的是进行数据处理。
MapReduce程序进行一次数据处理称为MR任务,它包含两个处理阶段:map阶段和reduce阶段。每一阶段的输入和输出的数据格式均为键/值对。
数据处理的具体步骤如下:
1.MR框架从HDFS中读取相关文件,并将数据分片,对每个分片的数据转化为key-value集合,送入map节点;
2.map节点获取key-value集合后,MR框架调用程序员编写好的map函数,对每一个key-value数据进行处理,生成新的key-value数据集合;
3.MR框架对map阶段输出的key-value数据集合进行排序、分组处理,进入reduce阶段;
4.MR框架调用编写好的reduce函数进行数据处理。最后输出的key-value数据集合即最终的数据处理结果。
四、Apache Hive:
Hive是基于hadoop的一个数据仓库工具可以将结构化数据文件映射为一张数据库表,并提供类SQL查询功能.Hive的主要用途:用于海量数据的离线数据分析,比直接使用MapReduce开发效率更高.
Hive的本质是将SQL转换为MapReduce程序;Hive中所有的数据都存储在HDFS上,没有专门的数据存储格式;Hive可以利用HDFS存储,利用MapReduce计算;
Hive 组件主要包括:用户接口:包括 CLI、JDBC/ODBC、WebGUI。
元数据存储:Hive 将元数据存储在数据库中。Hive 中的元数据包括表的名字和属性,列和分区及其属性,表的数据所在目录等。 解释器、编译器、优化器、执行器:完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS 中,并在随MapReduce 调用执行。
五、Apache HBase:
HBase是一个分布式的、面向列的开源数据库。
它是一个适合于非结构化数据存储的数据库。
HBase使用HDFS作为存储,数据访问速度快,响应时间约2-20毫秒。支持每个节点20k到100k以上ops/s的数据库读写操作,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群,可扩展到20,000多个节点。
六、Apache Sqoop:
sqoop是一款用于hadoop和关系型数据库之间数据导入导出的工具。
可以通过sqoop把数据从数据库(比如mysql,oracle)导入到hdfs中;也可以把数据从hdfs中导出到关系型数据库中。
sqoop通过Hadoop的MapReduce导入导出,可以提供了很高的并行性能以及良好的容错性。
七、Zeppelin可视化:
Zeppelin 是一个可以进行大数据可视化分析的交互式开发系统。
可以完成数据接入、数据发现、数据分析、数据可视化、数据协作等功能。
多语言后端:Zeppelin解释器允许将任何语言/数据处理后端插入到Zeppelin中。包括Spark,Python,JDBC,Shell等。
可视化前端:包含了一些基本图表。可视化不限于Spark SQL查询,任何语言后端的任何输出都可以被识别和可视化。
第二阶段:Spark
一、Scala编程
Scala语言是一种能够运行于 JVM 和.Net 平台之上的通用编程语言
可用于大规模应用程序开发,也可用于脚本编程。
Scala 支持面向对象和函数式编程。学习它的主要目的是为了进行开源大数据内存计算引擎 Spark 的源代码编程。
Scala的源代码会被编译成 Java 字节码 (.class),然后运行于 JVM 之上,并可以调用现有的 Java 类库,实现两种语言的无缝对接。
二、Spark 生态框架
Spark是一个针对大规模数据处理的快速通用引擎。
Spark生态系统是一个包含多个子项目的集合,其中包含Spark SQL、Spark Streaming、GraphX等子项目。交互式查询(Spark SQL):兼容Hive数据仓库,提供统一的数据访问方式,将SQL查询与Spark程序无缝集成。
实时流处理(Spark Streaming):可以以实现高吞吐量的,具备容错机制的实时流数据处理。接收Kafka、Flume、HDFS等各种来源的实时输入数据,进行处理后,处理结构保存在HDFS等各种地方。
图计算(GraphX):图是一种数据结构,GraphX它是一个图计算引擎,它可以处理像倒排索引,推荐系统,最短路径,群体检测等应用。
三、Flume
Flume是一种高可靠,分布式的海量日志采集、聚合和传输的应用系统Flume可以高效率的将服务器中收集的日志信息存入HDFS/HBase中,同时,Flume提供对数据进行简单处理,并写到各种数据接受方的能力。
Flume系统中核心的角色是agent,agent本身是一个Java进程,一般运行在日志收集节点。flume有3大组件:
source(源端数据采集):用于跟数据源对接,以获取数据。
Channel(临时存储聚合数据):agent内部的数据传输通道,用于从source将数据传递到sink
Sink(移动数据到目标端):用于往最终存储系统传递数据;如HDFS、KAFKA以及自定义的sink
四、Apache Kafka
**Kafka是一种高吞吐量的分布式日志系统。**主要用于web/nginx日志、访问日志,消息服务等日志收集系统和消息系统应用。 它的最大的特性就是可以实时的处理海量数据以满足各种需求场景:日志收集:一个公司可以用Kafka可以收集各种服务的log,通过kafka以统一接口服务的方式开放给各种hadoop、Hbase等。
用户活动跟踪:记录web用户或者app用户的各种活动,(如浏览网页、搜索、点击),然后进行实时的监控分析,或者装载到hadoop、数据仓库中做离线分析和挖掘。
流式处理:比如spark streaming和storm。
第三阶段:离线数据平台
一、Hive ETL处理
ETL:用来描述将数据从来源端经过抽取(extract)、转换(transform)、加载(load)至目的端的过程。
也可以理解为ETL是指获取原始大数据流,然后对其进行解析,并产生可用输出数据集的过程。
Hive是基于hadoop的一个数据仓库工具,可以作为ETL的工具来应用。
二、Oozie
用于Hadoop平台的开源的工作流调度引擎,用来管理Hadoop作业,属于web应用程序。Oozie是大数据四大协作框架之一——任务调度框架,另外三个分别为数据转换工具Sqoop,文件收集库框架Flume,大数据WEB工具Hue。
它能够提供对Hadoop MapReduce和Pig Jobs的任务调度与协调。Oozie需要部署到Java Servlet容器中运行。功能相似的任务调度框架还有Azkaban和Zeus。
工作流:
一个完整的数据分析系统通常是由大量的任务单元组成,Shell脚本、Java程序、MapReduce程序、Hive脚本等等,各个任务单元之间存在时间先后及前后依赖关系。为了很好的组织这样的复杂执行计划,需要一个工作流调度系统来调用执行。简单的工作流调度:Liunx的crontab来定义,复杂的工作流调度:Oozie、Azakaban等
三、Tableau可视化
Tableau是用来做数据的管理和数据可视化的工具,以在快速生成美观的图表、坐标图、仪表盘与报告。
四、Cassandra/Redis/MongoDB
NoSQL技术,这是一种基于内存的数据库,并且提供一定的持久化功能。Redis和MongoDB是当前使用最广泛的NoSQL数据库。
Redis:
可以支持每秒十几万次的读/写操作,其性能远超数据库。
支持集群、分布式、主从同步等配置,原则上可以无限扩展。
它还支持一定的事务能力,这保证了高并发的场景下数据的安全和一致性
MongoDB:基于分布式文件存储的NoSQL数据库
Cassandra:是一套开源分布式NoSQL数据库系统。
适用于跨数据中心/云端的结构化数据、半结构化数据和非结构化数据的存储。
同时,Cassandra 高可用、线性可扩展、高性能、无单点故障。
第四阶段:实时流处理平台
Confluent:用来管理和组织不同数据源的流媒体平台,可以实时地把不同源和位置的数据集成到一个中心的事件流平台
Flink:用Java和Scala编写的分布式流数据处理引擎。Flink以数据并行和流水线方式执行批处理和流处理程序。
Grafana:采用 go 语言编写的开源应用,主要用于大规模指标数据的可视化展现,是网络架构和应用分析中最流行的时序数据展示工具。
核心技术小结
Hadoop
大数据平台的鼻祖,第一代大数据计算引擎。主要思想是通过增加计算机的数量提高计算能力,将单机运算以低成本的方式扩容到多机运算。他一般称为Hadoop生态圈,圈子里有很多小伙伴儿(称之为:组件):HDFS(分布式文件存储系统),MR(MapReduce计算框架),Hive(数据仓库分析工具)、Yarn(Hadoop生态圈中负责资源管理和作业调度的组件),另外需要强调的是:Hadoop是一个Java框架,所以学习大数据,还是需要有一定的Java基础。
Spark
第二代大数据计算引擎,相比Hadoop计算速度有了极大提升。目前应用最为广泛,但仍需要其他数据存储系统支持,比如Hadoop的文件系统。
Flink
第三代大数据计算引擎。为实时计算(流式计算)而生,真正意义上的实时计算,现由阿里主导开发,未来将会PK Spark。广泛应用于要求低延迟的数据处理场景:舆情监控、互联网金融、点击流日志处理等。
Hive
Hive为传统的数据库开发人员提供了一种大数据平台开发的途径。或者说对于不精通编程的开发人员提供了一种大数据开发的工具,只需了解SQL语言即可。Hive底层可以将SQL代码转换成Hadoop应用程序。
ELK
ELK是三个工具的简写(Elasticsearch , Logstash, Kibana),即数据检索、数据导入与数据展示三个工具。是一个近似实时的搜索平台,可快速处理大数据,其中核心是数据检索模块(Elasticsearch),利用它可以快速搭建专业级的海量数据全文检索(查找)系统,并提供数据统计(聚合分析)能力,在很大程度上弥补Hadoop在文件快速检索效率上的不足。
Scala
是一种开发语言,源自于Java,现在被广泛应用的Spark计算引擎便是由Scala编写完成,并且在Spark开发过程中通常也推荐使用Scala编码。