Linux缓存相关知识整理(史上最全!!)
- 1. 相关概念
- 页
- 页缓存和块缓存概念
- 页缓存(page cache)
- 块缓存(buffer cache)
- 缓存机制的利弊
- 写缓存
- 2. 数据同步(刷缓存)
- flush内核线程
- 可调参数
- flush/sync/fsync系列API及命令介绍
- sync 系统命令
- sync()
- fsync()
- fdatasync()
- open()之O_SYNC/O_DSYNC选项
- msync()
- fflush()
- 3. 页面回收(page reclaim)
-
- 缓存回收策略
- 双LRU
- 系统触发页面回收
- 手动清理缓存
- 应用
-
- 4. 相关工具
- 查看缓存中的文件
- free命令
- free命令各个指标含义
- /proc/meminfo
- 5. 参考资料
1. 相关概念
页
- 页的概念 : 内核把物理页作为内存管理的基本单位. 通常32位系统页大小为4KB, 64位是8KB
- 如何查看当前系统页大小:
# getconf PAGESIZE
4096页缓存和块缓存概念
- 内核为块设备提供两种通用缓存方案:
页缓存(page cache)
- 缓存的是内存页面,缓存中的页来自于对正规文件、块设备文件和内存映射文件的读写。也就是说页缓存中包含最近被访问的文件数据块。我们通常所说的系统cache主要就是指页缓存。
- 在进行一个读操作前(如read),内核会检查数据是否已经在页缓存中,如果在,就可以从内存中快速返回所需的页,而不是从磁盘上读取。
块缓存(buffer cache)
- 以块(块设备的block)为操作单位。在进行IO操作时,存取的单位是单个块设备的各个块,而不是整个内存页。
- 早期版本写文件,先经过页缓存,刷盘时再同步到块缓存最后再落盘. 即:如果用dd写裸盘,则不经过页缓存。
- 从linux内核2.4开始二者统一起来了,缓存用页映射块,块缓存实际上就在页缓存中了。
缓存机制的利弊
- 好处:
- 提高性能(且对应用程序透明)
- 写缓存,可将零碎IO聚齐起来
- ……
- 负面影响:
- 物理内存通常远小于块设备,必须仔细挑选缓存哪些数据
- 缓存在一定程度上会影响应用程序实际可用的内存容量
- 如果系统崩溃,缓存的数据可能来不及刷回块设备(硬盘/ssd等),造成数据丢失
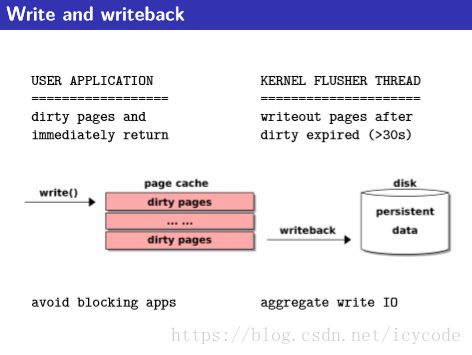
写缓存
- 通常缓存有三种实现策略:
- 不缓存(很少使用)
- 写透缓存(write-through cache):写操作会立刻穿透缓存存到磁盘中
- 回写(writeback):即linux采取的策略,写操作后将对应缓存页面标记为“dirty”,由回写进程周期性刷到磁盘
- “脏页”这个词有误导性,实际上脏的是磁盘上的数据而不是缓存中的数据。准确讲应该叫“未同步的页”。
2. 数据同步(刷缓存)
- 数据总是在物理内存中操作,随后在适当的时机点写回(或刷出)到磁盘,以持久化保存修改
- 几种不同的刷出数据机制:
- 周期性内核线程将扫描脏页链表,并根据页面变脏的时间,选择一些页会写
- 如系统中脏页太多,内核将触发进一步机制对脏页与后备存储器进行同步,直到脏页降低到一个可接受的程度
- 内核各个组件要求数据必须在特定事件发生时同步,例如重新装在文件系统
flush内核线程
- 上述刷新机制前2条由flusher线程实现。内核中每个磁盘设备对应一个flush线程,通过块设备号区分,
[flush-8:48]。 - 如何查看块设备号,可参考 http://www.lenky.info/archives/2012/02/1141 ,块设备一般都是8开头
- 历史上(2.6以前)还有bdflush,kupdated和pdflush等.其中pdflush线程数量不固定,而现在flush线程通常和磁盘一一对应,这样有助于在某个磁盘拥塞情况下避免所有IO拥塞,并简化处理逻辑。
- 关于线程数量和磁盘对应关系,以及周期性创建flush线程这部分逻辑,2.6前后内核版本有一定改动。查阅了几本内核的参考书,这部分介绍都不完全相同。
- 有些资料中提到,如1秒内没有空闲的flusher线程可用,内核将创建新的线程;如某个线程空闲超过1秒,将被销毁.flush线程数量一般被限制在2-8个
可调参数
- 可通过
/proc/sys/vm/目录下的内核参数控制脏页回写行为:
| 参数 | 描述 |
|---|---|
| dirty_background_ratio | 占全部内存的百分比,当脏页数量超过该比例时,pdflush机制开始(在后台)回写脏页.此时对write调用没有影响 |
| dirty_background_bytes | 同上,以字节描述。与dirty_background_ratio不可同时生效 |
| dirty_writeback_centisecs | pdflush线程运行的频率,单位1/100秒。默认500,即pdflush两次调用间隔是5秒。早期版本该参数可能是 dirty_writeback_interval |
| dirty_ratio | 脏页占全部内存的比例,超出该阈值时脏页开始刷出。此时新的IO请求可能会被阻塞直到脏页刷完 |
| dirty_bytes | 同上,以字节描述。与dirty_ratio不可同时生效 |
| dirty_expire_centisecs | 以百分之一秒为单位,默认3000.即超时30秒的脏页将会被pdflush线程写出,或者说一个脏页在回写之前,保持脏页状态最长可达30秒 |
- 在写密集的系统中,通常可配置dirty_ratio较高(如60)以增大可用缓存、dirty_background_ratio较低(如20)以遍在后台及时将数据刷入磁盘。同时保持dirty_writeback_centisecs较高(如5秒)
- 内核源码中好像有一个检查,dirty_background_ratio不能大于dirty_ratio的1/2,否则内核会自动调整为后者的1/2.参见内核代码global_dirty_limits() 函数:
void global_dirty_limits(unsigned long *pbackground, unsigned long *pdirty)
{
……
if (background >= dirty)
background = dirty / 2;
……
}- 效果示意图:

flush/sync/fsync系列API及命令介绍
sync 系统命令
- Force changed blocks to disk, update the super block.
sync()
- 允许进程把所有脏缓冲区刷新到磁盘.网上有说:
sync函数只是将所有修改过的块缓冲区排入写队列,然后就返回,它并不等待实际写磁盘操作结束。通常称为update的系统守护进程会周期性地(一般每隔30秒)调用sync函数
- 但从代码看,
do_sync()会调用2次sync_inodes()和sync_filesystems(),第一次传参数0,表示异步执行;第二次传参数1,表示同步执行.
fsync()
- 允许进程把属于特定打开文件的所有块刷新到磁盘. 它等待写磁盘操作结束,然后返回(The call blocks until the device reports that the transfer has completed. It also flushes metadata information associated with the file)。fsync可用于数据库这样的应用程序.
- 但正由于它会将元数据也刷回磁盘,所以相比
fdatasync()它多了一次IO操作。对于机械盘来说,这个耗时通常是毫秒(平均10ms左右)级别的!! fync()不保证其所在目录也被刷到磁盘,因此针对其所在目录显示调用一次fsync()是有必要的
fdatasync()
- 与fsync()类似,但不刷新文件的索引节点块(inode等)
- 诸如对文件access time等的修改,不会被fsync刷回磁盘; 但对文件大小的改变,由于会影响到后面的读数据,会被刷回磁盘。
- 通过这种机制减少不必要的磁盘IO,提高性能
- 网上提到,数据库系统中为了使用fdatasync来记录WAL日志的方法(因为日志都是追加写,文件长度会不断变化,不太适合直接用fdatasync):(https://www.cnblogs.com/hadis-yuki/p/5961949.html)
1.每个log文件固定为10MB大小,从1开始编号,名称格式为“log.%010d”
2.每次log文件创建时,先写文件的最后1个page,将log文件扩展为10MB大小
3.向log文件中追加记录时,由于文件的尺寸不发生变化,使用fdatasync可以大大优化写log的效率
4.如果一个log文件写满了,则新建一个log文件,也只有一次同步metadata的开销 - 看了Postgresql,默认也是使用fdatasync,并且可配置:
#define PLATFORM_DEFAULT_SYNC_METHOD_STR "fdatasync"
#define DEFAULT_SYNC_METHOD_STR PLATFORM_DEFAULT_SYNC_METHOD_ST
const char XLOG_sync_method_default[] = DEFAULT_SYNC_METHOD_STR;
static struct config_string ConfigureNamesString[] =
{
……
{
{"wal_sync_method", PGC_SIGHUP, WAL_SETTINGS,
gettext_noop("Selects the method used for forcing WAL updates to disk."),
NULL,
GUC_NOT_IN_SAMPLE | GUC_NO_SHOW_ALL | GUC_DISALLOW_USER_SET
},
&XLOG_sync_method,
XLOG_sync_method_default, assign_xlog_sync_method, NULL
},
……
}#wal_sync_method = fsync # the default is the first option
# supported by the operating system:
# open_datasync
# fdatasync (default on Linux)
# fsync
# fsync_writethrough
# open_sync
- 但glibc中fdatasync函数的实现已经和fsync一摸一样(至少到glibc2.24中都是如此。既然这样,不知道数据库中调用fdatasync是否还有意义?)
int
fdatasync (int fildes)
{
return fsync (fildes);
}open()之O_SYNC/O_DSYNC选项
- open的参数O_SYNC/O_DSYNC有着和fsync/fdatasync类似的含义:使每次write都会阻塞等待硬盘IO完成
- O_SYNC 使每次write等待物理I/O操作完成,包括由write操作引起的文件属性更新所需的I/O
- O_DSYNC 使每次write等待物理I/O操作完成,但是如果该写操作并不影响读取刚写入的数据,则不需等待文件属性被更新
- 相对于fsync/fdatasync,这样的设置不够灵活,应该很少使用
msync()
- 通常用于内存映射文件的同步,需要精确控制同步的内存地址、长度
int msync(void *addr, size_t length, int flags);
fflush()
- fflush() 是C库提供的接口,它只是从C库的缓冲区刷到内核缓冲区. 接下来还需要通过sync()/fsync()等调用才能刷到磁盘
3. 页面回收(page reclaim)
- 页交换(swapping) : 将很少使用的内存换出到块设备
- 与块设备同步 : 如一个很少使用的页对应后端存储器是一个块设备(如文件的内存映射),则可以直接与块设备同步。腾出来的页可重用。
- 丢弃: 例如页的后端存储器是文件且不能在内存中修改该文件(如二进制文件数据),在当前不使用的情况下课直接丢失该页。
缓存回收策略
- 缓存回收是通过选择干净页(不脏)进行简单替换。如没有足够的干净页面,则强制进行回写操作,以腾出更多干净可用页面
- 难点在于如何决定哪些页面该回收。理想策略是回收以后不可能使用的页面。
- LRU策略:对于许多文件被访问一次就不再被访问的场景,LRU表现很差
双LRU
- 物理内存被划分为多个zone(如ZONE_DMA,ZONE_DMA32,ZONE_NORMAL).每个zone都有一组lru链表,页面都被放到自己对应的zone的LRU中。
- 一组LRU由几对链表组成,有磁盘高速缓存页面(包括文件映射页面)的链表、匿名映射页面的链表等。
- 一对链表实际上是active和inactive两个链表,前者是最近使用过的页面、后者是最近未使用的页面
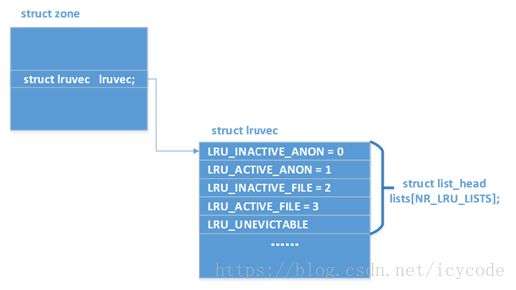
- 页面根据其活跃程度会在active链表和inactive链表之间来回移动: 初始状态两个链表都为空,当某个页面第一次被访问时会先进入inactive链表。在第二次被引用的时候,被提升到了active链表。
- 下图出自《深入理解Linux内核架构》18.6.3章节,P850
- 内核使用两个标识位,
PG_referenced和PG_active.如果只用一个active标识位,为了清除该标志,不得不设置大量内核定时器 - 上述标识位,一个表示当前活动程度,一个表示该页最近是否被引用过

- 内存管理器将可用的内存公平的分发给两个队列,尽量在保护active链表(频繁访问的页面)和inactive链表(探测最近使用的页面)之间达到一个折衷的平衡。换言之,内核为频率队列保留了50%的可用内存
- see: https://blog.csdn.net/zouxiaoting/article/details/8824896
系统触发页面回收
- 一种是内核检测到某个操作期间内存严重不足,调用
try_to_free_pages - 另一种是后台守护进程kswapd(可能有多个,每个NUMA节点对应一个实例)会定期检查内存使用情况,并检测即将发生的内存不足,可使用该守护进程换出页,作为预防措施, 防止内核在执行其他操作期间发生严重内存不足
- 上述两种机制触发入口函数不同,但代码路径上在
shrink_zone()函数中合并 - 如前面讲到,会优先选择非dirty的页。但也可能选择脏页,此时需要将这些页先回写到后备设备(如磁盘设备).如因任何原因无法回写,会将这些页放回LRU的inactive链表.

手动清理缓存
- To free pagecache : -
echo 1 > /proc/sys/vm/drop_caches - To free dentries and inodes :
echo 2 > /proc/sys/vm/drop_caches - To free pagecache, dentries and inodes :
echo 3 > /proc/sys/vm/drop_caches - 1和2的区别: 2针对的是目录、文件inode的缓存,1针对文件数据内容的缓存。
- 具体说明:在一个目录如test下,创建3万个子目录,在每个子目录中创建100个文件,并随机写入几个字节的数据。即test目录中共有大约300万文件:
- 多次执行
time find /home/hailong/cache_test -name file* | wc -l,观察耗时 - 执行
echo 1 > /proc/sys/vm/drop_caches之后再次执行上述命令,观察耗时 - 执行
echo 2 > /proc/sys/vm/drop_caches之后再次执行上述命令,观察耗时 - 测试结果:
echo 1对上述命令执行没有影响。但echo 2之后该命令执行耗时明显变长。同理,echo 3也类似。 - Note: 在一些特殊场景下,比如只想清除inode缓存,或只想清除数据缓存,区别使用上述几个命令是非常有意义的。
- 多次执行
应用
- 思考: 考虑实际业务场景,假设首先从数据库中查询4.1-4.30号数据,并进行多次分析计算。然后查询3.1-3.31号数据,那么查询3月份数据时,系统会马上将4月对应数据的缓存淘汰掉吗?(假设3月和4月的数据量都是刚好接近缓存大小上限)
- see: http://blog.jobbole.com/52898/
- 实际验证: 系统稳定状态下内存情况如下表,构造两个32GB大小的文本文件。先多次执行
time wc -l file1.csv,观察每次执行所用时间。然后再不清理缓存情况下,多次执行time wc -l file2.csv,观察每次执行所用时间。
[root~]# free -g
total used free shared buffers cached
Mem: 62 10 52 0 0 2
-/+ buffers/cache: 7 55
Swap: 31 0 31[root]# ls -lhtr
total 64G
-rw-r--r-- 1 root root 32G May 3 14:36 file1.csv
-rw-r--r-- 1 root root 32G May 3 14:45 file2.csvPS:执行结果可知,上述链接中提到的问题已经修复(CentOS 6.5)。但和我们预期的简单LRU可能不太一样,并非访问一次file2就完全淘汰file1的cache。事实上,由于file1曾经被多次访问、已经占据了active链表,file2是随着访问增加,一点一点将file1从cache中“赶”出去的,这也符合上述连接相关的patch修复描述。 但作为对比,如果一开始file1仅被访问1次,然后就wc -l file2,那么file1会马上被“赶出”cache.
4. 相关工具
查看缓存中的文件
- linux-ftools工具集中的
linux-fincore命令:
[root]#./linux-fincore --pages=false --summarize --only-cached *
filename size total_pages min_cached page cached_pages cached_size cached_perc
-------- ---- ----------- --------------- ------------ ----------- -----------
aclocal.m4 34,611 9 0 9 36,864 100.00
Could not mmap file: autom4te.cache: No such device
config.log 19,768 5 0 5 20,480 100.00
config.status 29,788 8 0 8 32,768 100.00
configure 171,672 42 0 42 172,032 100.00
configure.ac 864 1 0 1 4,096 100.00free命令
free命令各个指标含义

- Buffer: 指写缓冲、还未刷入磁盘的部分.
# 图中是在某测试环境中(写入速度大约30MB/s)抓取到的数据.
root@Storage:~# free
total used free shared buffers
Mem: 7800312 7212832 587480 0 12176
Swap: 0 0 0
Total: 7800312 7212832 587480- Cache : 从磁盘中读出来的数据,暂时缓存以备后面再次使用。
free的”cache”里也包括了“已使用的”共享内存数据。“已使用的”共享内存数据 是指shmget申请下来后真正写过的数据。
共享内存其实是通过mmap file来实现的,而所有的mmap的内存都是属于file back的,这些内存理所当然的就被统计进cache里了
/proc/meminfo
- 基本上涵盖系统内存的各种状态信息
root@Storage:~# cat /proc/meminfo
MemTotal: 7800312 kB
MemFree: 605236 kB
Buffers: 12192 kB
Cached: 3821896 kB
SwapCached: 0 kB
Active: 4074880 kB
Inactive: 1904592 kB
Active(anon): 2240692 kB
Inactive(anon): 59436 kB
Active(file): 1834188 kB
Inactive(file): 1845156 kB
Unevictable: 0 kB
Mlocked: 0 kB
SwapTotal: 0 kB
SwapFree: 0 kB
Dirty: 358764 kB
Writeback: 0 kB
AnonPages: 2144676 kB
……5. 参考资料
- 《深入Linux内核架构》 16、17、18章
- 《深入理解Linux内核》第三版 第15章
- 《Linux内核设计与实现》 第三版 第12、16章
- https://events.static.linuxfound.org/images/stories/pdf/lcjp2012_wu.pdf
- https://blog.csdn.net/zouxiaoting/article/details/8824896
- https://www.cnblogs.com/liudehao/p/6647674.html
- https://www.cnblogs.com/hadis-yuki/p/5961949.html
- http://blog.jobbole.com/52898/
- https://lkml.org/lkml/2013/11/24/133