Python_Scrapy_执行文件不生成json文件和TypeError: write() argument must be str, not bytes错误及解决
使用刚安装好的scrapy做第一个案例遇到了一堆bug,代码如下:
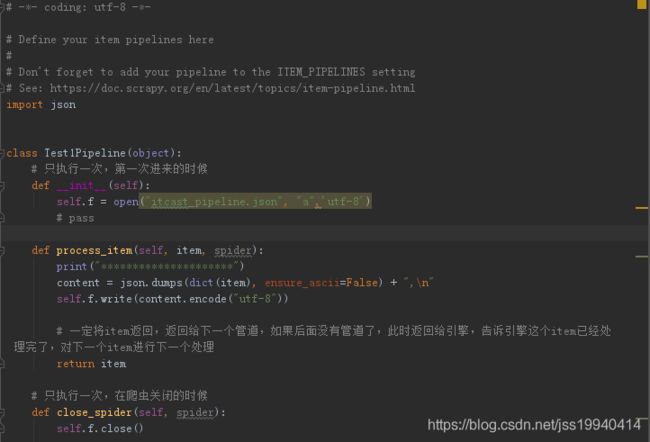
pipelines.py
item.py
我的爬虫文件:
test_itcast.py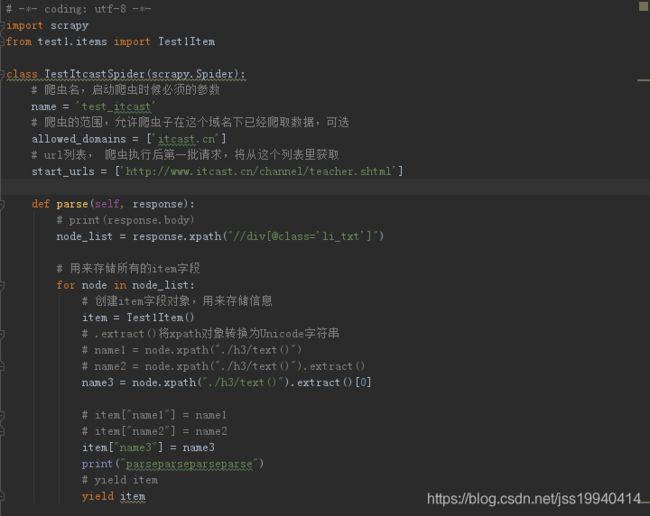
1.实行代码的时候,scrapy crawl test_itcast,实行结果如下:
(venv) E:\Scrapy\test1\test1>scrapy crawl test_itcast
2018-12-08 16:15:48 [scrapy.utils.log] INFO: Scrapy 1.5.1 started (bot: test1)
2018-12-08 16:15:48 [scrapy.utils.log] INFO: Versions: lxml 4.1.1.0, libxml2 2.9.7, cssselect 1.0.3, parsel 1.5.1, w3lib 1.19.0, Twisted
18.9.0, Python 3.6.4 |Anaconda, Inc.| (default, Jan 16 2018, 10:22:32) [MSC v.1900 64 bit (AMD64)], pyOpenSSL 17.5.0 (OpenSSL 1.0.2n 7 D
ec 2017), cryptography 2.1.4, Platform Windows-7-6.1.7601-SP1
2018-12-08 16:15:48 [scrapy.crawler] INFO: Overridden settings: {'BOT_NAME': 'test1', 'NEWSPIDER_MODULE': 'test1.spiders', 'SPIDER_MODULE
S': ['test1.spiders']}
2018-12-08 16:15:48 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.logstats.LogStats']
2018-12-08 16:15:48 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2018-12-08 16:15:48 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2018-12-08 16:15:48 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2018-12-08 16:15:48 [scrapy.core.engine] INFO: Spider opened
2018-12-08 16:15:48 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2018-12-08 16:15:48 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023
2018-12-08 16:15:49 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None)
parseparseparseparse
2018-12-08 16:15:49 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.itcast.cn/channel/teacher.shtml>
{'name3': '朱老师'}
parseparseparseparse
2018-12-08 16:15:49 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.itcast.cn/channel/teacher.shtml>
{'name3': '郭老师'}
parseparseparseparse
2018-12-08 16:15:49 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.itcast.cn/channel/teacher.shtml>
{'name3': '曾老师'}
parseparseparseparse
2018-12-08 16:15:49 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.itcast.cn/channel/teacher.shtml>
{'name3': '梁老师'}
parseparseparseparse
2018-12-08 16:15:49 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.itcast.cn/channel/teacher.shtml>
{'name3': '闫老师'}
parseparseparseparse
2018-12-08 16:15:49 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.itcast.cn/channel/teacher.shtml>
{'name3': '杨老师'}
parseparseparseparse
2018-12-08 16:15:49 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.itcast.cn/channel/teacher.shtml>
{'name3': '黄老师'}
parseparseparseparse
2018-12-08 16:15:49 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.itcast.cn/channel/teacher.shtml>
{'name3': '汪老师'}
parseparseparseparse
2018-12-08 16:15:49 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.itcast.cn/channel/teacher.shtml>
{'name3': '伍老师'}
parseparseparseparse
2018-12-08 16:15:49 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.itcast.cn/channel/teacher.shtml>
{'name3': '江老师'}
parseparseparseparse
2018-12-08 16:15:49 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.itcast.cn/channel/teacher.shtml>
{'name3': '段老师'}
parseparseparseparse
2018-12-08 16:15:49 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.itcast.cn/channel/teacher.shtml>
{'name3': '刘老师'}
parseparseparseparse
2018-12-08 16:15:49 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.itcast.cn/channel/teacher.shtml>
{'name3': '彭老师'}
parseparseparseparse
2018-12-08 16:15:49 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.itcast.cn/channel/teacher.shtml>
{'name3': '李老师'}
parseparseparseparse
2018-12-08 16:15:49 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.itcast.cn/channel/teacher.shtml>
{'name3': '苏老师'}
parseparseparseparse
2018-12-08 16:15:49 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.itcast.cn/channel/teacher.shtml>
{'name3': '王老师'}
parseparseparseparse
2018-12-08 16:15:49 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.itcast.cn/channel/teacher.shtml>
{'name3': '吴老师'}
parseparseparseparse
2018-12-08 16:15:49 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.itcast.cn/channel/teacher.shtml>
{'name3': '沈老师'}
parseparseparseparse
2018-12-08 16:15:49 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.itcast.cn/channel/teacher.shtml>
{'name3': '周老师'}
parseparseparseparse
2018-12-08 16:15:49 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.itcast.cn/channel/teacher.shtml>
{'name3': '赵老师'}
parseparseparseparse
2018-12-08 16:15:49 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.itcast.cn/channel/teacher.shtml>
{'name3': '潘老师'}
parseparseparseparse
2018-12-08 16:15:49 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.itcast.cn/channel/teacher.shtml>
{'name3': '胡老师'}
2018-12-08 16:15:49 [scrapy.core.engine] INFO: Closing spider (finished)
2018-12-08 16:15:49 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 233,
'downloader/request_count': 1,
'downloader/request_method_count/GET': 1,
'downloader/response_bytes': 137571,
'downloader/response_count': 1,
'downloader/response_status_count/200': 1,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2018, 12, 8, 8, 15, 49, 349038),
'item_scraped_count': 221,
'log_count/DEBUG': 223,
'log_count/INFO': 7,
'response_received_count': 1,
'scheduler/dequeued': 1,
'scheduler/dequeued/memory': 1,
'scheduler/enqueued': 1,
'scheduler/enqueued/memory': 1,
'start_time': datetime.datetime(2018, 12, 8, 8, 15, 48, 454924)}
2018-12-08 16:15:49 [scrapy.core.engine] INFO: Spider closed (finished)
哎~~没有问题??,是我想太多!!
json文件都没有生成
下面开始寻找问题
1.百度发现你的爬虫文件中必须要有返回给管道的值,让管道文件进行数据保存或其它,代码中有yield item 没有问题。
2.百度发现你的管道文件在数据保存操作后必须然会当前item,返回给下一个管道,如果后面没有管道了,此时返回给引擎,告诉引擎这个item已经处理完了,对下一个item进行下一个处理。代码中有return item没有问题。
3.最重要一点,你的settings中是否将管道文件的配置注释解开,默认是关闭的!!!

果然,解掉后在执行。
2.运行结果还是出错,报错如下
(venv) E:\Scrapy\test1\test1>scrapy crawl test_itcast
2018-12-08 16:41:12 [scrapy.utils.log] INFO: Scrapy 1.5.1 started (bot: test1)
2018-12-08 16:41:12 [scrapy.utils.log] INFO: Versions: lxml 4.1.1.0, libxml2 2.9.7, cssselect 1.0.3, parsel 1.5.1, w3lib 1.19.0, Twisted
18.9.0, Python 3.6.4 |Anaconda, Inc.| (default, Jan 16 2018, 10:22:32) [MSC v.1900 64 bit (AMD64)], pyOpenSSL 17.5.0 (OpenSSL 1.0.2n 7 D
ec 2017), cryptography 2.1.4, Platform Windows-7-6.1.7601-SP1
2018-12-08 16:41:12 [scrapy.crawler] INFO: Overridden settings: {'BOT_NAME': 'test1', 'NEWSPIDER_MODULE': 'test1.spiders', 'SPIDER_MODULE
S': ['test1.spiders']}
2018-12-08 16:41:13 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.logstats.LogStats']
2018-12-08 16:41:15 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2018-12-08 16:41:15 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
Unhandled error in Deferred:
2018-12-08 16:41:15 [twisted] CRITICAL: Unhandled error in Deferred:
Traceback (most recent call last):
File "e:\anaconda3\lib\site-packages\scrapy\crawler.py", line 171, in crawl
return self._crawl(crawler, *args, **kwargs)
File "e:\anaconda3\lib\site-packages\scrapy\crawler.py", line 175, in _crawl
d = crawler.crawl(*args, **kwargs)
File "e:\anaconda3\lib\site-packages\twisted\internet\defer.py", line 1613, in unwindGenerator
return _cancellableInlineCallbacks(gen)
File "e:\anaconda3\lib\site-packages\twisted\internet\defer.py", line 1529, in _cancellableInlineCallbacks
_inlineCallbacks(None, g, status)
--- ---
File "e:\anaconda3\lib\site-packages\twisted\internet\defer.py", line 1418, in _inlineCallbacks
result = g.send(result)
File "e:\anaconda3\lib\site-packages\scrapy\crawler.py", line 80, in crawl
self.engine = self._create_engine()
File "e:\anaconda3\lib\site-packages\scrapy\crawler.py", line 105, in _create_engine
return ExecutionEngine(self, lambda _: self.stop())
File "e:\anaconda3\lib\site-packages\scrapy\core\engine.py", line 70, in __init__
self.scraper = Scraper(crawler)
File "e:\anaconda3\lib\site-packages\scrapy\core\scraper.py", line 71, in __init__
self.itemproc = itemproc_cls.from_crawler(crawler)
File "e:\anaconda3\lib\site-packages\scrapy\middleware.py", line 58, in from_crawler
return cls.from_settings(crawler.settings, crawler)
File "e:\anaconda3\lib\site-packages\scrapy\middleware.py", line 40, in from_settings
mw = mwcls()
File "E:\Scrapy\test1\test1\pipelines.py", line 13, in __init__
self.f = open("itcast_pipeline.json", "a",'utf-8')
builtins.TypeError: an integer is required (got type str)
2018-12-08 16:41:15 [twisted] CRITICAL:
Traceback (most recent call last):
File "e:\anaconda3\lib\site-packages\twisted\internet\defer.py", line 1418, in _inlineCallbacks
result = g.send(result)
File "e:\anaconda3\lib\site-packages\scrapy\crawler.py", line 80, in crawl
self.engine = self._create_engine()
File "e:\anaconda3\lib\site-packages\scrapy\crawler.py", line 105, in _create_engine
return ExecutionEngine(self, lambda _: self.stop())
File "e:\anaconda3\lib\site-packages\scrapy\core\engine.py", line 70, in __init__
self.scraper = Scraper(crawler)
File "e:\anaconda3\lib\site-packages\scrapy\core\scraper.py", line 71, in __init__
self.itemproc = itemproc_cls.from_crawler(crawler)
File "e:\anaconda3\lib\site-packages\scrapy\middleware.py", line 58, in from_crawler
return cls.from_settings(crawler.settings, crawler)
File "e:\anaconda3\lib\site-packages\scrapy\middleware.py", line 40, in from_settings
mw = mwcls()
File "E:\Scrapy\test1\test1\pipelines.py", line 13, in __init__
self.f = open("itcast_pipeline.json", "a",'utf-8')
TypeError: an integer is required (got type str)
报错位置pipelines.py line 13
报错原因:
open函数的参数
open(file, mode='r', buffering=None, encoding=None, errors=None, newline=None, closefd=True): ![]()
编码格式必须使用关键字传参
修改后代码
![]()
果然,修改后在执行。
3.还是报错,如下:
*********************
2018-12-08 16:48:55 [scrapy.core.scraper] ERROR: Error processing {'name3': '沈老师'}
Traceback (most recent call last):
File "e:\anaconda3\lib\site-packages\twisted\internet\defer.py", line 654, in _runCallbacks
current.result = callback(current.result, *args, **kw)
File "E:\Scrapy\test1\test1\pipelines.py", line 19, in process_item
self.f.write(content.encode("utf-8"))
TypeError: write() argument must be str, not bytes
parseparseparseparse
*********************
2018-12-08 16:48:55 [scrapy.core.scraper] ERROR: Error processing {'name3': '周老师'}
Traceback (most recent call last):
File "e:\anaconda3\lib\site-packages\twisted\internet\defer.py", line 654, in _runCallbacks
current.result = callback(current.result, *args, **kw)
File "E:\Scrapy\test1\test1\pipelines.py", line 19, in process_item
self.f.write(content.encode("utf-8"))
TypeError: write() argument must be str, not bytes
parseparseparseparse
*********************
2018-12-08 16:48:55 [scrapy.core.scraper] ERROR: Error processing {'name3': '赵老师'}
Traceback (most recent call last):
File "e:\anaconda3\lib\site-packages\twisted\internet\defer.py", line 654, in _runCallbacks
current.result = callback(current.result, *args, **kw)
File "E:\Scrapy\test1\test1\pipelines.py", line 19, in process_item
self.f.write(content.encode("utf-8"))
TypeError: write() argument must be str, not bytes
parseparseparseparse
*********************
2018-12-08 16:48:55 [scrapy.core.scraper] ERROR: Error processing {'name3': '潘老师'}
Traceback (most recent call last):
File "e:\anaconda3\lib\site-packages\twisted\internet\defer.py", line 654, in _runCallbacks
current.result = callback(current.result, *args, **kw)
File "E:\Scrapy\test1\test1\pipelines.py", line 19, in process_item
self.f.write(content.encode("utf-8"))
TypeError: write() argument must be str, not bytes
parseparseparseparse
*********************
2018-12-08 16:48:55 [scrapy.core.scraper] ERROR: Error processing {'name3': '胡老师'}
Traceback (most recent call last):
File "e:\anaconda3\lib\site-packages\twisted\internet\defer.py", line 654, in _runCallbacks
current.result = callback(current.result, *args, **kw)
File "E:\Scrapy\test1\test1\pipelines.py", line 19, in process_item
self.f.write(content.encode("utf-8"))
TypeError: write() argument must be str, not bytes
2018-12-08 16:48:55 [scrapy.core.engine] INFO: Closing spider (finished)
2018-12-08 16:48:55 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 233,
'downloader/request_count': 1,
'downloader/request_method_count/GET': 1,
'downloader/response_bytes': 137571,
'downloader/response_count': 1,
'downloader/response_status_count/200': 1,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2018, 12, 8, 8, 48, 55, 656767),
'log_count/DEBUG': 2,
'log_count/ERROR': 221,
'log_count/INFO': 7,
'response_received_count': 1,
'scheduler/dequeued': 1,
'scheduler/dequeued/memory': 1,
'scheduler/enqueued': 1,
'scheduler/enqueued/memory': 1,
'start_time': datetime.datetime(2018, 12, 8, 8, 48, 54, 782656)}
2018-12-08 16:48:55 [scrapy.core.engine] INFO: Spider closed (finished)
pipelines.py, line 19
TypeError: write() argument must be str, not bytes
![]()
写入的时候必须是字符串,不能是字节
修改后代码:
![]()
继续执行!
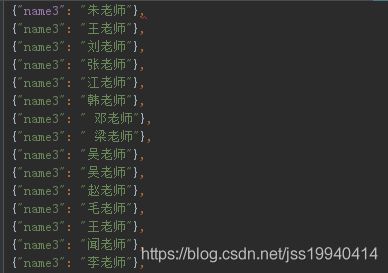
没有报错成功完成
json文件如下(部分截图):