some suanfa
BF算法:O(MN)
RK算法:O(MN)
KMP算法:O(N)
BM算法:O(N)
==================================================================================================================================================================
字符串匹配算法研究
2009年06月16日 11:47:00 yifan403 阅读数:4138
摘要:随着互联网的日渐庞大,信息也是越来越多,如何在海量的信息中快速查找自己所要的信息是网络搜索研究的热点所在,在这其中,字符串匹配算法起着非常 重要的作用,一个高效的字符串匹配算法,可以极大的提高搜索的效率和质量,本文力图阐明字符串匹配算法的发展过程,并介绍了各个算法的特点,并给予了适当 的比较和分析。
关键字:字符串匹配 前缀 后缀 kmp算法 后缀树
Abstract: with internet booming, the amount of information gets more and more. How to find the target information in such tramendous data is the key in web searching develepment. In this end the string matching algorithm takes the key role. An efficient string matching algorithm can improve web searching service greatly. The author try to introduce the developing of the string matching algorithm and emphasis on kmp and suffix tree algorithm.
Keywords: string matching suffix prefix KMP suffix tree
1.引言
查找模式字符串在文本中的所有出现是文本编辑软件经常要面对的一个问题。一般而言文本就是要编辑的文档,而模式字符串往往由用户来指定,高效的字符串匹配 算法可以提高程序的响应性能,当然字符串匹配算法的应用远远不止于此,例如在生物计算科学中查找特定的DNA序列,也是字符串匹配算法的一个重要应用。
我们可以如下定义字符串匹配问题,我们假定文本是一个长度为n的字符数组T[1..n],而模式字符串也是一个字符数组P[1..m],并且m <= n。进一步的,我们假定T所包含的所有字符构成一个有限的字符表E,|E|表示字符表所包含的自负的个数。
本文所提及的字符串匹配算法除了朴素字符串匹配算法以外都需要一定的预处理时间,此预处理时间根据算法的不同也不尽相同,图1展示了本文将要提到的各个算 法所需要的预处理时间以及匹配的时间,可以大致看出字符串匹配算法的演变过程,而且会发现后缀树算法与其他算法有很大的不同,而正是由于这一点使得后缀树 的应用更加贴近于今天互联网的大环境。
2.朴素字符串匹配算法
朴素字符串匹配算法的思想非常直白,既然是查找模式字符串在文本字符串中的出现,那么我么就从文本字符串的每一位开始一次判断是否与模式字符串相同,如果 相同那么就找到了模式字符串的一次出现,可以看出此算法的时间复杂度为O(mn),m,n分别为文本字符串与模式字符串的长度,但是通过更加深入的分析可 以得出此算法的平均时间复杂度为O(n+m),所以此算法在模式字符串与文本字符串都是随即选择的情况下工作地是相当的不错,还有就是此算法并没有其他算 法所必须的预处理时间。
3.Rabin-Karp算法
Rabin-Karp算法是由Rabin和Karp[1]提出的一个在实际中有比较好应用的字符串匹配算法,此算法的预处理时间为O(m),但它的在最坏 情况下的时间复杂度为O((2n-m+1)m),而平均复杂度接近O(m+n),此算法的主要思想就是通过对字符串进行哈稀运算,使得算法可以容易的派出 大量的不相同的字符串,假设模式字符串的长度为m,利用
Horner法则p = p[m] + 10(p[m -1] + 10(p[m-2]+...+10(p[2]+10p[1])...)),求出模式字符串的哈稀值p,而对于文本字符串来说,对应于每个长度为m的子串的 哈稀值为t(s+1)=10(t(s)-10^(m-1)T[s+1])+T[s+m+1],然后比较此哈稀值与模式字符串的哈稀值是否相等,若不相同, 则字符串一定不同,若相同,则需要进一步的按位比较,所以它的最坏情况下的时间复杂度为O(mn)。
4.字符串匹配自动机
与字符串相关的自动机[2]是一个五元组(Q,q,A,E,%)其中Q是状态的有限集合,q
5.KMP算法
现在要提到一个伟大的算法,它的出现归功于Knuth,Morris和Pratt的伟大工作[3],此算法采用类似上面所提到的字符串自动机的原理,但完 全避免了计算转移函数,它仅仅用了一个只需要O(m)就能计算出来的辅助函数pai[1..m]就达到了搜索时间复杂度为O(n).
函数pai称为前缀函数,是根据模式字符串构造的,对于一个给定的模式字符串p[1..m],它的前缀函数定义如下:pai[q] = max{k:k p(q)}即:pai[q]是p的最长的与后缀p(q)相同的前缀。
通过均摊分析可以证明计算前缀函数的时间复杂度为O(m),而同样把此方法用于分析KMP算法的时间复杂度分析,我们可以得出KMP匹配算法的时间复杂度为O(m+n)。
6.后缀树算法
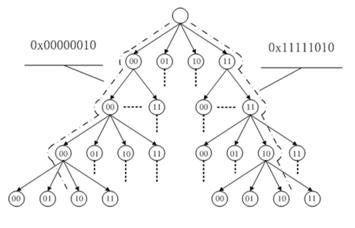
Trie,又经常叫前缀树,字典树等等。它有很多变种,如后缀树,Radix Tree/Trie,PATRICIA tree,以及bitwise版本的crit-bit tree。
6-1后缀字典树算法
对于目标字符串的所有后缀,可以把他们构造成字典树,此字典树的每一个节点(除叶子节点外),都可能有|E|个分支,这样在目标字符串中搜索模式字符串的 出现变得非常的简单,只需要从字典树的跟节点出发,按照对应的分支向下查找,最多比较m次,就可以确定此模式字符串是否在目标字符串钟出现。所以查找字符 串的时间复杂度为O(m)与目标字符串n无关,这种好处是非常明现的,它意味着对于一个目标字符串一旦建立它的后缀字典树后,以后在此目标字符串查找任意 字符串都只需要O(m)的比较,但是构造后缀字典树无疑是很花费时间与空间的,通过分析可以知道,构造此字典树的时空花费为O(n^2),对于很大的目标 字符串来说,这是无法忍受的。
6-2非在线后缀树算法
为了减少构造后缀字典树所花费的时间与空间,Edward McGreight[4] 1976年发表了后缀树的论文,此后缀树与后缀字典树在代表的含义上完全相同,但由于它采用了路径压缩的方法,即每条边不只代表一个字符,有可能是一个字 符串,大大节省了构造此后缀树所花的时间与空间,可以证明此后缀树最多有2n个节点,构造的时间为O(n),但是此算法有个非常明显的缺点,就是它的倒序 处理字符串的,也就是它是非在线的。
6-3在线后缀树算法
1995年Ukkonen[5]提出了在线的后缀树算法,支持从左到右的输入字符串,并在输入的同时构造出后缀树,至此给后缀树画上了完美的句号,通过分析可以知道基于后缀树的字符串匹配算法的时间复杂度为O(m+n)。
7.总结
通过上面的阐述,我们可以清出的看出一个问题的提出经常半随着一个新算法的出现,而一个新算法的出现又会带来一些新的问题。前面所述的这些算法虽然从理论 上来说一个比一个高效,但是在实际应用中,每个算法都有自己独特的价值,即便是最原始的朴素字符串匹配算法也仍然有较好的应用,因为它的平均性能很好,而 且不需要预处理时间。而Rabin-Karp算法则往往用于单个模式字符串在多个目标字符串中的同时查找,以及模糊匹配。KMP无疑是应用最广的而且它的 实现也很简单,几乎无所不在。后缀树算法对于在同一个目标文本中查找多个模式字符串则非常的适合,尤其对于很大的目标文本,工作地非常好,所以在网络搜索 中成为了主流算法。目前后缀树的研究已经比较成熟,主要在进行后缀数组的研究,后缀数组与后缀树的想法相同,但是在实现上更加高效,不过它并不是O(n) 的算法,但是由于其简单的结构,高效的实现使得它的应用非常的诱人。字符串匹配算法还有很多,这里只是提到一些比较经典的算法,不过沿着字符串匹配算法的 轨迹,我们可以清楚的看到它的迷人之处。
================================================================================================================================================================================================
Trie(前缀树/字典树)及其应用
Trie,又经常叫前缀树,字典树等等。它有很多变种,如后缀树,Radix Tree/Trie,PATRICIA tree,以及bitwise版本的crit-bit tree。当然很多名字的意义其实有交叉。
定义
在计算机科学中,trie,又称前缀树或字典树,是一种有序树,用于保存关联数组,其中的键通常是字符串。与二叉查找树不同,键不是直接保存在节点中,而是由节点在树中的位置决定。一个节点的所有子孙都有相同的前缀,也就是这个节点对应的字符串,而根节点对应空字符串。一般情况下,不是所有的节点都有对应的值,只有叶子节点和部分内部节点所对应的键才有相关的值。
trie中的键通常是字符串,但也可以是其它的结构。trie的算法可以很容易地修改为处理其它结构的有序序列,比如一串数字或者形状的排列。比如,bitwise trie中的键是一串位元,可以用于表示整数或者内存地址
基本性质
1,根节点不包含字符,除根节点意外每个节点只包含一个字符。
2,从根节点到某一个节点,路径上经过的字符连接起来,为该节点对应的字符串。
3,每个节点的所有子节点包含的字符串不相同。
优点:
可以最大限度地减少无谓的字符串比较,故可以用于词频统计和大量字符串排序。
跟哈希表比较:
1,最坏情况时间复杂度比hash表好
2,没有冲突,除非一个key对应多个值(除key外的其他信息)
3,自带排序功能(类似Radix Sort),中序遍历trie可以得到排序。
缺点:
1,虽然不同单词共享前缀,但其实trie是一个以空间换时间的算法。其每一个字符都可能包含至多字符集大小数目的指针(不包含卫星数据)。
每个结点的子树的根节点的组织方式有几种。1>如果默认包含所有字符集,则查找速度快但浪费空间(特别是靠近树底部叶子)。2>如果用链接法(如左儿子右兄弟),则节省空间但查找需顺序(部分)遍历链表。3>alphabet reduction: 减少字符宽度以减少字母集个数。,4>对字符集使用bitmap,再配合链接法。
2,如果数据存储在外部存储器等较慢位置,Trie会较hash速度慢(hash访问O(1)次外存,Trie访问O(树高))。
3,长的浮点数等会让链变得很长。可用bitwise trie改进。
bit-wise Trie
类似于普通的Trie,但是字符集为一个bit位,所以孩子也只有两个。
可用于地址分配,路由管理等。
虽然是按bit位存储和判断,但因为cache-local和可高度并行,所以性能很高。跟红黑树比,红黑树虽然纸面性能更高,但是因为cache不友好和串行运行多,瓶颈在存储访问延迟而不是CPU速度。
压缩Trie
压缩分支条件:
1,Trie基本不变
2,只是查询
3,key跟结点的特定数据无关
4,分支很稀疏
若允许添加和删除,就可能需要分裂和合并结点。此时可能需要对压缩率和更新(裂,并)频率进行折中。
外存Trie
某些变种如后缀树适合存储在外部,另外还有B-trie等。
应用场景:
(1) 字符串检索
事先将已知的一些字符串(字典)的有关信息保存到trie树里,查找另外一些未知字符串是否出现过或者出现频率。
举例:
1,给出N 个单词组成的熟词表,以及一篇全用小写英文书写的文章,请你按最早出现的顺序写出所有不在熟词表中的生词。
2,给出一个词典,其中的单词为不良单词。单词均为小写字母。再给出一段文本,文本的每一行也由小写字母构成。判断文本中是否含有任何不良单词。例如,若rob是不良单词,那么文本problem含有不良单词。
3,1000万字符串,其中有些是重复的,需要把重复的全部去掉,保留没有重复的字符串。
(2)文本预测、自动完成,see also,拼写检查
(3)词频统计
1,有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16字节,内存限制大小是1M。返回频数最高的100个词。
2,一个文本文件,大约有一万行,每行一个词,要求统计出其中最频繁出现的前10个词,请给出思想,给出时间复杂度分析。
3,寻找热门查询:搜索引擎会通过日志文件把用户每次检索使用的所有检索串都记录下来,每个查询串的长度为1-255字节。假设目前有一千万个记录,这些查询串的重复度比较高,虽然总数是1千万,但是如果去除重复,不超过3百万个。一个查询串的重复度越高,说明查询它的用户越多,也就越热门。请你统计最热门的10个查询串,要求使用的内存不能超过1G。
(1) 请描述你解决这个问题的思路;
(2) 请给出主要的处理流程,算法,以及算法的复杂度。
==》若无内存限制:Trie + “k-大/小根堆”(k为要找到的数目)。
否则,先hash分段再对每一个段用hash(另一个hash函数)统计词频,再要么利用归并排序的某些特性(如partial_sort),要么利用某使用外存的方法。参考
“海量数据处理之归并、堆排、前K方法的应用:一道面试题” http://www.dataguru.cn/thread-485388-1-1.html。
“算法面试题之统计词频前k大” http://blog.csdn.net/u011077606/article/details/42640867
算法导论笔记——第九章 中位数和顺序统计量
(4)排序
Trie树是一棵多叉树,只要先序遍历整棵树,输出相应的字符串便是按字典序排序的结果。
比如给你N 个互不相同的仅由一个单词构成的英文名,让你将它们按字典序从小到大排序输出。
(5)字符串最长公共前缀
Trie树利用多个字符串的公共前缀来节省存储空间,当我们把大量字符串存储到一棵trie树上时,我们可以快速得到某些字符串的公共前缀。
举例:
给出N 个小写英文字母串,以及Q 个询问,即询问某两个串的最长公共前缀的长度是多少?
解决方案:首先对所有的串建立其对应的字母树。此时发现,对于两个串的最长公共前缀的长度即它们所在结点的公共祖先个数,于是,问题就转化为了离线(Offline)的最近公共祖先(Least Common Ancestor,简称LCA)问题。
而最近公共祖先问题同样是一个经典问题,可以用下面几种方法:
1. 利用并查集(Disjoint Set),可以采用采用经典的Tarjan 算法;
2. 求出字母树的欧拉序列(Euler Sequence )后,就可以转为经典的最小值查询(Range Minimum Query,简称RMQ)问题了;
(6)字符串搜索的前缀匹配
trie树常用于搜索提示。如当输入一个网址,可以自动搜索出可能的选择。当没有完全匹配的搜索结果,可以返回前缀最相似的可能。
Trie树检索的时间复杂度可以做到n,n是要检索单词的长度,
如果使用暴力检索,需要指数级O(n2)的时间复杂度。
(7) 作为其他数据结构和算法的辅助结构
如后缀树,AC自动机等
后缀树可以用于全文搜索
转一篇关于几种Trie速度比较的文章:http://www.hankcs.com/nlp/performance-comparison-of-several-trie-tree.html
Trie树和其它数据结构的比较 http://www.raychase.net/1783
参考:
[1] 维基百科:Trie, https://en.wikipedia.org/wiki/Trie
[2] LeetCode字典树(Trie)总结, http://www.jianshu.com/p/bbfe4874f66f
[3] 字典树(Trie树)的实现及应用, http://www.cnblogs.com/binyue/p/3771040.html#undefined
[4] 6天通吃树结构—— 第五天 Trie树, http://www.cnblogs.com/huangxincheng/archive/2012/11/25/2788268.html
===========================================================================================================================================================================================================================================================================
几种Trie树性能比较
码农场 > 自然语言处理 2014-05-02 阅读(7552) 评论(3)
目录
- 测试代码如下:
- 输出:
- 插入耗时
- 查询耗时
- 结论
最近正在做一个自己的NLP库,刚起步的第一个问题就是字典的储存与查询。毫无疑问,最佳的数据结构是Trie树,同时为了平衡效率和空间,决定使用双数组Trie树。现在的问题是,双数组Trie树是一个压缩的Trie树,在插入的时候需要递归调整base与check中的冲突,无异于重新压缩一次。所以在动态的词典场景下,需要一个支持快速插入、同时查询速度还行的结构。我调查了很多开源实现,发现“首字直接分配内存,之后用动态数组二分”与“Radix and Crit Bit Tree”两种比较有实用价值。在此对两种方法做个比较,同时与标准的DoubleArrayTrie树一起比较一下速度。
二分法采用的实现是ansj的tree_split,Radix and Crit Bit Tree采用的是patricia-trie,标准的DoubleArrayTrie树采用了Jada和darts(两个库都是日本人写的),另外digitalstain的Datrie简直太糟糕了在测试中指针越界,懒得看那坨shit一样的代码。
我用一个真实的词典做为输入,连续查找100000000次一个词来比较查询速度
测试代码如下:
- package com.hankcs;
- import darts.DoubleArrayTrie;
- import love.cq.domain.Forest;
- import love.cq.library.Library;
- import love.cq.splitWord.GetWord;
- import net.reduls.jada.Trie;
- import net.reduls.jada.TrieBuilder;
- import org.ardverk.collection.PatriciaTrie;
- import org.ardverk.collection.StringKeyAnalyzer;
- import org.digitalstain.datrie.DoubleArrayTrieImpl;
- import org.digitalstain.datrie.SearchResult;
- import org.digitalstain.datrie.store.IntegerArrayList;
- import java.io.*;
- import java.util.ArrayList;
- import java.util.Collections;
- import java.util.List;
- public class Main
- {
- static int testTimes = 100000000;
- public static void main(String[] args) throws Exception
- {
- List
wordList = new ArrayList (); - BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream("data/WordList.txt")));
- String line = null;
- while ((line = br.readLine()) != null)
- {
- wordList.add(line);
- }
- br.close();
- // Collections.sort(wordList);
- // BufferedWriter writer = new BufferedWriter(new FileWriter("data/WordList.txt", false));
- // for (String w : wordList)
- // {
- // writer.write(w);
- // writer.newLine();
- // }
- // writer.close();
- System.out.println("单词表大小:" + wordList.size());
- long start = System.currentTimeMillis();
- // 测试ansj的tire
- Forest forest = new Forest();
- for (String w : wordList)
- {
- Library.insertWord(forest, w);
- }
- System.out.println("ansj插入耗时:" + (System.currentTimeMillis() - start));
- start = System.currentTimeMillis();
- for (int i = 0; i < testTimes; ++i)
- {
- if (forest.getWord("好好").getAllWords().equals("好好") == false)
- {
- throw new RuntimeException("ansj没找到该有的词");
- }
- }
- System.out.println("ansj查询耗时:" + (System.currentTimeMillis() - start));
- start = System.currentTimeMillis();
- PatriciaTrie
- for (String w : wordList)
- {
- trie.put(w, w);
- }
- System.out.println("PatriciaTrie插入耗时:" + (System.currentTimeMillis() - start));
- start = System.currentTimeMillis();
- for (int i = 0; i < testTimes; ++i)
- {
- if (trie.containsKey("好好") == false)
- {
- throw new RuntimeException("PatriciaTrie没找到该有的词");
- }
- }
- System.out.println("PatriciaTrie查询耗时:" + (System.currentTimeMillis() - start));
- start = System.currentTimeMillis();
- TrieBuilder builder = new TrieBuilder(wordList);
- Trie trieJada = builder.build();
- System.out.println("Jada插入耗时:" + (System.currentTimeMillis() - start));
- start = System.currentTimeMillis();
- for (int i = 0; i < testTimes; ++i)
- {
- if (trieJada.search("好好") == -1)
- {
- throw new RuntimeException("Jada没找到该有的词");
- }
- }
- System.out.println("Jada查询耗时:" + (System.currentTimeMillis() - start));
- start = System.currentTimeMillis();
- DoubleArrayTrie dat = new DoubleArrayTrie();
- dat.build(wordList);
- System.out.println("darts插入耗时:" + (System.currentTimeMillis() - start));
- start = System.currentTimeMillis();
- for (int i = 0; i < testTimes; ++i)
- {
- if (dat.exactMatchSearch("加油") == -1)
- {
- throw new RuntimeException("darts没找到该有的词");
- }
- }
- System.out.println("darts查询耗时:" + (System.currentTimeMillis() - start));
- // digitalstainDatrie is a piece of shit!
- // start = System.currentTimeMillis();
- // DoubleArrayTrieImpl digitalstainDatrie = new DoubleArrayTrieImpl(wordList.size());
- // digitalstainDatrie.add(wordList);
- // System.out.println("digitalstainDatrie插入耗时:" + (System.currentTimeMillis() - start));
- //
- // start = System.currentTimeMillis();
- // for (int i = 0; i < testTimes; ++i)
- // {
- // if (digitalstainDatrie.containsPrefix(new IntegerArrayList("加油")) != SearchResult.PERFECT_MATCH)
- // {
- // throw new RuntimeException("digitalstainDatrie没找到该有的词");
- // }
- // }
- // System.out.println("darts查询耗时:" + (System.currentTimeMillis() - start));
- }
- }
输出:
- 单词表大小:275909
- ansj插入耗时:189
- ansj查询耗时:7756
- PatriciaTrie插入耗时:156
- PatriciaTrie查询耗时:13960
- Jada插入耗时:1711
- Jada查询耗时:3463
- darts插入耗时:1444
- darts查询耗时:1479
插入耗时
可见在20万词的词典插入中,二分法和基数树表现得非常突出,双数组Trie树因为要压缩(甚至解决冲突,如Jada)就多花了一个数量级的时间。不过这也没什么大不了的,因为分词词典就加载一次。
查询耗时
这才是重头戏,在查询中双数组Trie树表现得非常突出,二分法次之,而基数树则是二分法的两倍。
结论
二分法小巧实用。
====================================================================================================================================================================================================================================================================================================================================================================
trie树(前缀树)
问题描述:
Trie树,即字典树,又称单词查找树或键树,是一种树形结构,是一种哈希树的变种。典型应用是用于统计和排序大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:最大限度地减少无谓的字符串比较,查询效率比哈希表高。
Trie的核心思想是空间换时间。利用字符串的公共前缀来降低查询时间的开销以达到提高效率的目的。
它有3个基本性质:
- 根节点不包含字符,除根节点外每一个节点都只包含一个字符。
- 从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串。
- 每个节点的所有子节点包含的字符都不相同。
参考资料:
http://blog.csdn.net/v_july_v/article/details/6897097
http://www.cnblogs.com/cherish_yimi/archive/2009/10/12/1581666.html
问题解决:
(1)前缀树的构建
举个在网上流传颇广的例子,如下:
题目:给你100000个长度不超过10的单词。对于每一个单词,我们要判断他出没出现过,如果出现了,求第一次出现在第几个位置。
分析:这题当然可以用hash来解决,但是本文重点介绍的是trie树,因为在某些方面它的用途更大。比如说对于某一个单词,我们要询问它的前缀是否出现过。这样hash就不好搞了,而用trie还是很简单。
现在回到例子中,如果我们用最傻的方法,对于每一个单词,我们都要去查找它前面的单词中是否有它。那么这个算法的复杂度就是O(n^2)。显然对于100000的范围难以接受。现在我们换个思路想。假设我要查询的单词是abcd,那么在他前面的单词中,以b,c,d,f之类开头的我显然不必考虑。而只要找以a开头的中是否存在abcd就可以了。同样的,在以a开头中的单词中,我们只要考虑以b作为第二个字母的,一次次缩小范围和提高针对性,这样一个树的模型就渐渐清晰了。
好比假设有b,abc,abd,bcd,abcd,efg,hii 这6个单词,我们构建的树就是如下图这样的:
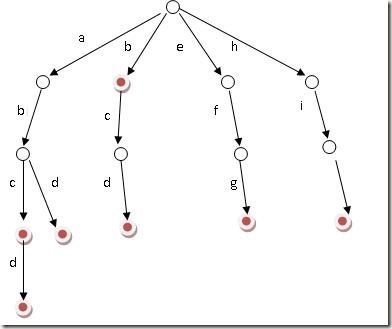
当时第一次看到这幅图的时候,便立马感到此树之不凡构造了。单单从上幅图便可窥知一二,好比大海搜人,立马就能确定东南西北中的到底哪个方位,如此迅速缩小查找的范围和提高查找的针对性,不失为一创举。
ok,如上图所示,对于每一个节点,从根遍历到他的过程就是一个单词,如果这个节点被标记为红色,就表示这个单词存在,否则不存在。
那么,对于一个单词,我只要顺着他从根走到对应的节点,再看这个节点是否被标记为红色就可以知道它是否出现过了。把这个节点标记为红色,就相当于插入了这个单词。
这样一来我们查询和插入可以一起完成(重点体会这个查询和插入是如何一起完成的,稍后,下文具体解释),所用时间仅仅为单词长度,在这一个样例,便是10。
我们可以看到,trie树每一层的节点数是26^i级别的。所以为了节省空间。我们用动态链表,或者用数组来模拟动态。空间的花费,不会超过单词数×单词长度。
(2)前缀查询
上文中提到”比如说对于某一个单词,我们要询问它的前缀是否出现过。这样hash就不好搞了,而用trie还是很简单“。下面,咱们来看看这个前缀查询问题:
已知n个由小写字母构成的平均长度为10的单词,判断其中是否存在某个串为另一个串的前缀子串。下面对比3种方法:
- 最容易想到的:即从字符串集中从头往后搜,看每个字符串是否为字符串集中某个字符串的前缀,复杂度为O(n^2)。
- 使用hash:我们用hash存下所有字符串的所有的前缀子串,建立存有子串hash的复杂度为O(n*len),而查询的复杂度为O(n)* O(1)= O(n)。
- 使用trie:因为当查询如字符串abc是否为某个字符串的前缀时,显然以b,c,d....等不是以a开头的字符串就不用查找了。所以建立trie的复杂度为O(n*len),而建立+查询在trie中是可以同时执行的,建立的过程也就可以成为查询的过程,hash就不能实现这个功能。所以总的复杂度为O(n*len),实际查询的复杂度也只是O(len)。(说白了,就是Trie树的平均高度h为len,所以Trie树的查询复杂度为O(h)=O(len)。好比一棵二叉平衡树的高度为logN,则其查询,插入的平均时间复杂度亦为O(logN))。
(3)查询
Trie树是简单但实用的数据结构,通常用于实现字典查询。我们做即时响应用户输入的AJAX搜索框时,就是Trie开始。本质上,Trie是一颗存储多个字符串的树。相邻节点间的边代表一个字符,这样树的每条分支代表一则子串,而树的叶节点则代表完整的字符串。和普通树不同的地方是,相同的字符串前缀共享同一条分支。下面,再举一个例子。给出一组单词,inn, int, at, age, adv, ant, 我们可以得到下面的Trie:

可以看出:
- 每条边对应一个字母。
- 每个节点对应一项前缀。叶节点对应最长前缀,即单词本身。
- 单词inn与单词int有共同的前缀“in”, 因此他们共享左边的一条分支,root->i->in。同理,ate, age, adv, 和ant共享前缀"a",所以他们共享从根节点到节点"a"的边。
查询操纵非常简单。比如要查找int,顺着路径i -> in -> int就找到了。
搭建Trie的基本算法也很简单,无非是逐一把每则单词的每个字母插入Trie。插入前先看前缀是否存在。如果存在,就共享,否则创建对应的节点和边。比如要插入单词add,就有下面几步:
- 考察前缀"a",发现边a已经存在。于是顺着边a走到节点a。
- 考察剩下的字符串"dd"的前缀"d",发现从节点a出发,已经有边d存在。于是顺着边d走到节点ad
- 考察最后一个字符"d",这下从节点ad出发没有边d了,于是创建节点ad的子节点add,并把边ad->add标记为d。
(4)Trie树的应用
除了本文引言处所述的问题能应用Trie树解决之外,Trie树还能解决下述问题(节选自此文:海量数据处理面试题集锦与Bit-map详解):
- 3、有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16字节,内存限制大小是1M。返回频数最高的100个词。
- 9、1000万字符串,其中有些是重复的,需要把重复的全部去掉,保留没有重复的字符串。请怎么设计和实现?
- 10、 一个文本文件,大约有一万行,每行一个词,要求统计出其中最频繁出现的前10个词,请给出思想,给出时间复杂度分析。
- 13、寻找热门查询:搜索引擎会通过日志文件把用户每次检索使用的所有检索串都记录下来,每个查询串的长度为1-255字节。假设目前有一千万个记录,这些查询串的重复读比较高,虽然总数是1千万,但是如果去除重复和,不超过3百万个。一个查询串的重复度越高,说明查询它的用户越多,也就越热门。请你统计最热门的10个查询串,要求使用的内存不能超过1G。
(1) 请描述你解决这个问题的思路;
(2) 请给出主要的处理流程,算法,以及算法的复杂度。
有了Trie,后缀树就容易理解了。本文接下来的第二部分,介绍后缀树。
(5)前缀树的实现



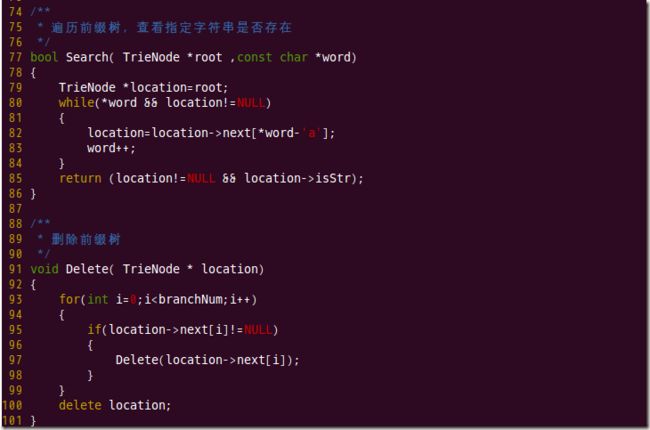
注:
前缀树实现,依据是:

程序源文件: