想要好好写sql需要知道的优化常识
一:sql语句的小技巧
1.使用group by 分组查询时,默认分组后,还会排序,可能会降低速度,在group by 后面增加 order by null 就可以防止排序。
2.有些情况下,可以使用连接来替代子查询。因为使用join,MySQL不需要在内存中创建临时表。
如:select * from dept, emp where dept.deptno=emp.deptno;
// 替换成
select * from dept left join emp on dept.deptno=emp.deptno;
二:分表技术
1.什么情况下需要分表?
(1) 如果一个表的每条记录的内容很大,那么就需要更多的IO操作,如果字段值比较大,而使用频率相对比较低,可以将大字段移到另一张表中,当查询不查大字段的时候,这样就减少了I/O操作;
(2)如果表的数据量非常非常大,那么查询就变的比较慢;也就是表的数据量影响到查询的性能;
(3)表中的数据本来就有独立性,例如分别记录各个地区的数据或者不同时期的数据,特别是有些数据常用,而另外一些数据不常用;
(4) 分表技术有两种水平分割和垂直分割;
垂直分割
垂直分割是指数据表列的拆分,把一张表列比较多的表拆分为多张表。垂直分割一般用于拆分大字段和访问频率低的字段,分离冷热数据。
垂直分割比较常见:例如博客系统中的文章表,比如文章tbl_articles
(id, titile, summary, content, user_id, create_time),因为文章中的内容content会比较长,放在tbl_articles中会严重影响表的查询速度,所以将内容放到tbl_articles_detail(article_id, content),像文章列表只需要查询tbl_articles中的字段即可。
垂直拆分的优点:可以使得行数据变小,在查询时减少读取的Block数,减少I/O次数。此外,垂直分区可以简化表的结构,易于维护。
垂直拆分的缺点:主键会出现冗余,需要管理冗余列,并会引起join操作,可以通过在应用层进行join来解决。此外,垂直分区会让事务变得更加复杂。
水平分割
水平拆分是指数据表行数据的拆分,表的行数超过500万行或者单表容量超过10GB时,查询就会变慢,这时可以把一张的表的数据拆成多张表来存放。水平分表尽可能使每张表的数据量相当,比较均匀。
水平拆分会给应用增加复杂度,它通常在查询是需要多个表名,查询所有数据需要union操作。在许多数据库应用中,这种复杂性会超过它带来的优点。
因为只要索引关键字不大,则在索引用于查询时,表中增加2-3倍数据量,查询时也就增加读一个索引层的磁盘次数,所以水平拆分要考虑数据量的增长速度,根据实际情况决定是否需要对表进行水平拆分。
水平分割最重要的是找到分割的标准,不同的表应根据业务找出不同的标准
-
用户表可以根据用户的手机号段进行分割如user151、user150、user153等,每个号段就是一张表
-
用户表也可以根据用户的id进行分割,加入分3张表user0,user1,user2,如果用户的id%3=0就查询user0表,
如果用户的id%3=1就查询user1表 -
对于订单表可以按照订单的时间进行分
三:读写分离技术
实现mysql读写分离的前提是我们已经将mysql主从复制配置完毕,读写分离实现方式:
(1)配置多数据源。
(2)使用mysql的proxy中间件代理工具,如mysql-proxy等
前提条件:必须要部署主从复制。
主从复制的原理
mysql的主从复制和读写分离两者有着紧密的联系,首先要部署主从复制,只有主从复制完成了才能在此基础上进行数据的读写分离。
读写分离的原理
读写分离就是只在主服务器上写,只在从服务器上读。基本原理是让主数据库处理事务性insert、update、delete查询,而从服务器处理select查询。数据库复制用来把事务性查询导致的变更同步到从数据库中。
四:索引优化
索引分类
-
普通索引:最基本的索引。
-
组合索引:多个字段上建立的索引,能够加速复合查询条件的检索。
-
唯一索引:与普通索引类似,但索引列的值必须唯一,允许有空值。
-
组合唯一索引:列值的组合必须唯一。
-
主键索引:特殊的唯一索引,用于唯一标识数据表中的某一条记录,不允许有空值,一般用primary key约束。
-
全文索引:用于海量文本的查询,MySQL5.6之后的InnoDB和MyISAM均支持全文索引。由于查询精度以及扩展性不佳,更多的企业选择Elasticsearch。
索引优化
-
分页查询很重要,如果查询数据量超过30%,MYSQL不会使用索引。
-
单表索引数不超过5个、单个索引字段数不超过5个。
-
字符串可使用前缀索引,前缀长度控制在5-8个字符。
-
字段唯一性太低,增加索引没有意义,如:是否删除、性别。
合理使用覆盖索引,如下所示:
select login_name, nick_name from member where login_name = ?
login_name, nick_name两个字段建立组合索引,比login_name简单索引要更快。、
五:操作符优化
操作符<>优化
通常<>操作符无法使用索引,举例如下,查询金额不为100元的订单:
select id from orders where amount != 100;如果金额为100的订单极少,这种数据分布严重不均的情况下,有可能使用索引。鉴于这种不确定性,采用union聚合搜索结果,改写方法如下:
(select id from orders where amount > 100)
union all
(select id from orders where amount < 100 and amount > 0)
OR优化
在Innodb引擎下or无法使用组合索引,比如:
select id,product_name from orders where mobile_no = '15321589999' or user_id = 100;OR无法命中mobile_no + user_id的组合索引,可采用union,如下所示:
(select id,product_name from orders where mobile_no = '15321589999')
union
(select id,product_name from orders where user_id = 100);此时id和product_name字段都有索引,查询才最高效。
IN优化
IN适合主表大子表小,EXIST适合主表小子表大。由于查询优化器的不断升级,很多场景这两者性能差不多一样了。
尝试改为join查询,举例如下:
select id from orders where user_id in (select id from user where level = 'VIP');采用JOIN如下所示:
select o.id from orders o left join user u on o.user_id = u.id where u.level = 'VIP';不做列运算
通常在查询条件列运算会导致索引失效,如下所示:
查询当日订单
select id from order where date_format(create_time,'%Y-%m-%d') = '2019-01-01';date_format函数会导致这个查询无法使用索引,改写后:
select id from order where create_time between '2019-01-01 00:00:00'Like优化
like用于模糊查询,举个例子(field已建立索引):
SELECT column FROM table WHERE field like '%keyword%';这个查询未命中索引,换成下面的写法:
SELECT column FROM table WHERE field like 'keyword%';去除了前面的%查询将会命中索引,但是产品经理一定要前后模糊匹配呢?全文索引fulltext可以尝试一下,但Elasticsearch才是终极武器。
Join优化
join的实现是采用Nested Loop Join算法,就是通过驱动表的结果集作为基础数据,通过该结数据作为过滤条件到下一个表中循环查询数据,然后合并结果。如果有多个join,则将前面的结果集作为循环数据,再次到后一个表中查询数据。
驱动表和被驱动表尽可能增加查询条件,满足ON的条件而少用where,用小结果集驱动大结果集。
被驱动表的join字段上加上索引,无法建立索引的时候,设置足够的Join Buffer Size。
禁止join连接三个以上的表,尝试增加冗余字段。
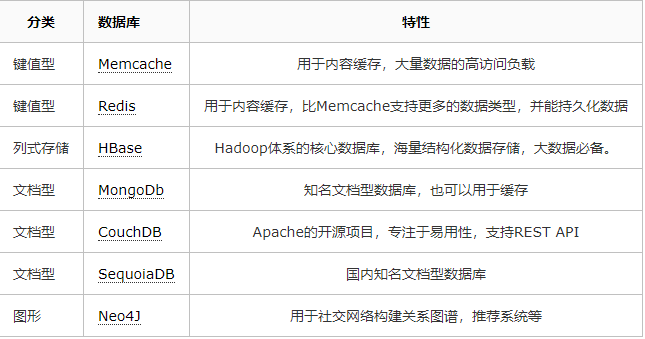
其他数据库
作为一名后端开发人员,不但要精通关系型数据库,同时也要积极关注NoSQL非关系型数据库,他们已经足够成熟并被广泛采用,能解决特定场景下的性能瓶颈。