redis内存初窥
目录
一、内存统计
二、内存划分
2.1 对象内存
2.2内存碎片
三、内存消耗
四、缓冲内存
普通客户端缓冲区
slave客户端缓冲区
pubsub客户端缓冲区
复制缓冲区
AOF缓冲区
五、对象内存
六、内存碎片
七、子进程内存消耗
八、内存管理
设置内存上线
动态调整内存上线
内存回收策略
内存溢出控制策略
九、内存优化
内存分布
合理选择优化数据结构
客户端内存优化
其他方法
该不该使用redis
十、总结
一、内存统计

可以在 lua中自定义命令。
# Memory
used_memory:33805895736
used_memory_human:31.48G
used_memory_rss:42316582912
used_memory_rss_human:39.41G
used_memory_peak:44346475840
used_memory_peak_human:41.30G
total_system_memory:338519248896
total_system_memory_human:315.27G
used_memory_lua:37888
used_memory_lua_human:37.00K
maxmemory:200000000000
maxmemory_human:186.26G
maxmemory_policy:volatile-lru
mem_fragmentation_ratio:1.25
mem_allocator:jemalloc-4.0.3
二、内存划分

2.1 对象内存
Redis存储的所有值对象在内部定义为redisObject结构体,内部结构如下图所示:
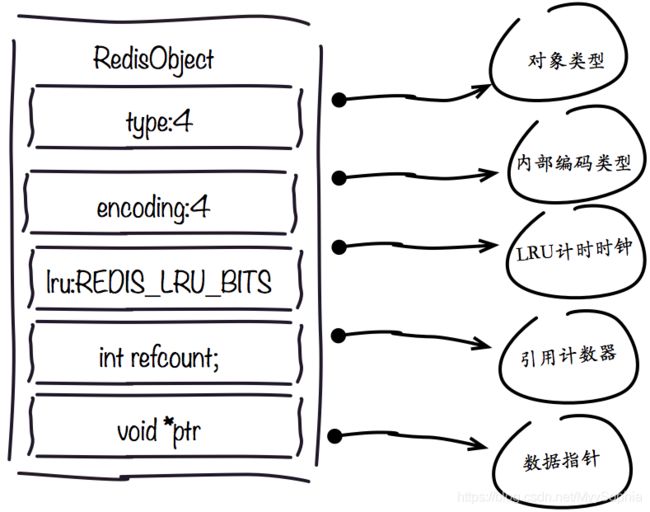
Redis存储的数据都使用redisObject来封装,包括string,hash,list,set,zset在内的所有数据类型。理解redisObject对内存优化非常有帮助,下面针对每个字段做详细说明:
1.type字段:
表示当前对象使用的数据类型,Redis主要支持5种数据类型:string,hash,list,set,zset(Redis内部针对不同类型存在编码的概念,所谓编码就是具体使用哪种底层数据结构来实现。编码不同将直接影响数据的内存占用和读写效率)。可以使用type {key}命令查看对象所属类型,type命令返回的是值对象类型,键都是string类型。
2.encoding字段:
表示Redis内部编码类型,encoding在Redis内部使用,代表当前对象内部采用哪种数据结构实现。理解Redis内部编码方式对于优化内存非常重要 ,同一个对象采用不同的编码实现内存占用存在明显差异,具体细节见之后编码优化部分。
3.lru字段:
记录对象最后一次被访问的时间,当配置了 maxmemory和maxmemory-policy=volatile-lru | allkeys-lru 时, 用于辅助LRU算法删除键数据。可以使用object idletime {key}命令在不更新lru字段情况下查看当前键的空闲时间。
开发提示:可以使用scan + object idletime 命令批量查询哪些键长时间未被访问,找出长时间不访问的键进行清理降低内存占用。
127.0.0.1:6381> set test 1
OK
127.0.0.1:6381> get test
"1"
# test 引用所储存的值的次数。
127.0.0.1:6381> OBJECT REFCOUNT test
(integer) 1
............
# test自储存以来的空转时间(idle, 没有被读取也没有被写入),以秒为单位
127.0.0.1:6381> OBJECT IDLETIME test
(integer) 284
127.0.0.1:6381> get test
"1"
127.0.0.1:6381> OBJECT REFCOUNT test
(integer) 1
127.0.0.1:6381> OBJECT IDLETIME test
(integer) 11
4.refcount字段:
记录当前对象被引用的次数,用于通过引用次数回收内存,当refcount=0时,可以安全回收当前对象空间。使用object refcount {key}获取当前对象引用。当对象为整数且范围在[0-9999]时,Redis可以使用共享对象的方式来节省内存。具体细节见之后共享对象池部分。
5. *ptr字段:
与对象的数据内容相关,如果是整数直接存储数据,否则表示指向数据的指针。Redis在3.0之后对值对象是字符串且长度<=39字节的数据,内部编码为embstr类型,字符串sds和redisObject一起分配,从而只要一次内存操作。
开发提示:高并发写入场景中,在条件允许的情况下建议字符串长度控制在39字节以内,减少创建redisObject内存分配次数从而提高性能
2.2内存碎片
内存碎片是操作系统分配给的内存和实际使用的内存的差值。
例如 存了一个string类型的key。
第一次set一个key value为5byte,第二次set 的value为10byte。当再次set 一个5byte的value时,是会分配给10byte,这是由于redis SDS数据结构的特性决定的。总之申请的可能比使用的多一点。

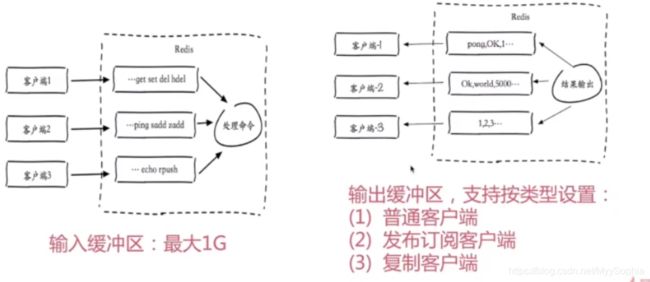
三、内存消耗

缓冲区内存主要是在redis-cli 执行命令所需要的内存,占用比最大的还是对象内存,其大小取决于数据规模。
四、缓冲内存
输出缓冲区配置
普通客户端缓冲区

查看客户端缓冲区
127.0.0.1:6379> client list
id=178784 addr=127.0.0.1:55911 fd=62 name= age=2422 idle=0 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=32768 obl=0 oll=0 omem=0 events=r cmd=client
其中有几个关键 qbuf=0 qbuf-free=32768 缓冲区参数,输出缓冲区的大小obl=0 oll=0,omem是输出缓冲区的内存。
查看输出缓冲区内存不为0的session
redis-cli -p 6379 client list|grep -v "omem=0"slave客户端缓冲区
主要作用就是同步主节点的写操作,或者是主从同步
在这个synced左边的小扳手就是对应client的 slaveof 命令。
slaveof ip port 就可以将从节点复制到主节点上面
slaveof no one 这个slave节点不能成为任何节点的从节点

这个timeout时截取的slave svr如下的log。
- ---------------------
- 21008:S 13 Jun 11:50:53.294 * Connecting to MASTER 10.50.10.153:6379
- 21008:S 13 Jun 11:50:53.294 * MASTER <-> SLAVE sync started
- 21008:S 13 Jun 11:50:53.300 * Non blocking connect for SYNC fired the event.
- 21008:S 13 Jun 11:50:53.306 * Master replied to PING, replication can continue...
- 21008:S 13 Jun 11:50:53.318 * Trying a partial resynchronization (request 1a0f3645b4f179f61f899aa37b37b0440006716b:60682116019).
- 21008:S 13 Jun 11:50:53.352 * Full resync from master: d50a53d5f6e9e45e16a368e3f1a7f8429738379b:1
- 21008:S 13 Jun 11:50:53.352 * Discarding previously cached master state.
- 21008:S 13 Jun 11:54:08.630 * MASTER <-> SLAVE sync: receiving 7926728912 bytes from master
- 21008:S 13 Jun 11:55:44.921 * MASTER <-> SLAVE sync: Flushing old data
- 21008:S 13 Jun 11:57:25.577 * MASTER <-> SLAVE sync: Loading DB in memory
- 21008:S 13 Jun 11:59:46.524 * MASTER <-> SLAVE sync: Finished with success
- 21008:S 13 Jun 11:59:46.886 * Background append only file rewriting started by pid 22896
- 21008:S 13 Jun 12:01:12.297 * AOF rewrite child asks to stop sending diffs.
- 22896:C 13 Jun 12:01:12.298 * Parent agreed to stop sending diffs. Finalizing AOF...
- 22896:C 13 Jun 12:01:12.298 * Concatenating 0.01 MB of AOF diff received from parent.
- 22896:C 13 Jun 12:01:12.298 * SYNC append only file rewrite performed
- 22896:C 13 Jun 12:01:12.561 * AOF rewrite: 128 MB of memory used by copy-on-write
- 21008:S 13 Jun 12:01:12.932 * Background AOF rewrite terminated with success
- 21008:S 13 Jun 12:01:12.932 * Residual parent diff successfully flushed to the rewritten AOF (0.00 MB)
- 21008:S 13 Jun 12:01:12.932 * Background AOF rewrite finished successfully
- ---------------------
- 26745:S 13 Jun 12:42:46.691 * Master replied to PING, replication can continue...
- 26745:S 13 Jun 12:42:46.711 * Partial resynchronization not possible (no cached master)
- 26745:S 13 Jun 12:42:46.872 * Full resync from master: d50a53d5f6e9e45e16a368e3f1a7f8429738379b:37683397
- 26745:S 13 Jun 12:44:16.827 # Timeout receiving bulk data from MASTER... If the problem persists try to set the 'repl-timeout' parameter in redis.conf to a larger value.
- 26745:S 13 Jun 12:44:16.827 * Connecting to MASTER 10.50.10.153:6379
- 26745:S 13 Jun 12:44:16.827 * MASTER <-> SLAVE sync started
在参数设定不正确的情况下这个timeout会引起全量复制。它会向master发送PSYNC:
PSYNC 命令是一个非常耗费资源的操作每次执行 PSYNC 命令,主从服务器需要执行以下动作:
1 )主服务器需要执行 BGSAVE 命令来生成 RDB 文件,这个生成操作会耗费主服务器大量的 CPU 、内存和磁盘 I/O 资源。
2 )主服务器需要将自己生成的 RDB 文件发送给从服务器,这个发送操作会耗费主从服务器大量的网络资源(带宽和流量),并对主服务器响应命令请求的时间产生影响。
3 )接收到 RDB 文件的从服务器需要载入主服务器发来的 RDB 文件,并且在载入期间,从服务器会因为阻塞而没办法处理命令请求。因为 SYNC 命令是一个如此耗费资源的操作,所以 Redis 有必要保证在真正有需要时才执行 PSYNC 命令
如果期间master还一直在写数据,且总是会超过1MB大小的repl-backlog-size,可能造成恶性循环 全量复制 - imeout - 全量复制。
这个该如何解决呢?
1、从log的第24 - 15行可知增量同步失败了(Partial resynchronization not possible (no cached master)),然后又重新从master进行全量同步,这是因为slave落后于master的offset超过了master维护的repl_backlog_size,这个是一个默认1MB的固定长度队列。类似于环形队列。
官方对这个参数的说明。
# Set the replication backlog size. The backlog is a buffer that accumulates
# slave data when slaves are disconnected for some time, so that when a slave
# wants to reconnect again, often a full resync is not needed, but a partial
# resync is enough, just passing the portion of data the slave missed while
# disconnected.
#
# The bigger the replication backlog, the longer the time the slave can be
# disconnected and later be able to perform a partial resynchronization.
#
# The backlog is only allocated once there is at least a slave connected.
#
# repl-backlog-size 1mb
固定长度队列的介绍

主从同步的时候,slave会落后master的时间 =(master执行rdb bgsave)+ (master发送rdb到slave) + (slave load rdb文件) 的时间之和。 然后如果在这个时间master的数据变更非常巨大,超过了replication backlog,那么老的数据变更命令就会被丢弃,导致需要全量同步。针对目前的这个参数固定1MB 显然是不够的,该参数经过测算,大约是每1mis0.7MB的写入量。基于此可根据实际情况设定。需要注意的是该参数仅仅是在部分同步时生效。
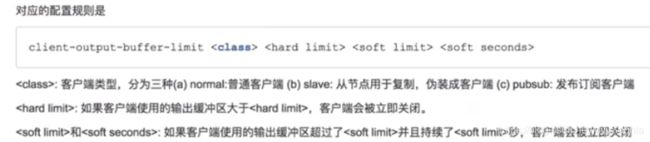
2、第二个参数是client-output-buffer-limit slave,这个参数官方解释
# A client is immediately disconnected once the hard limit is reached, or if
# the soft limit is reached and remains reached for the specified number of
# seconds (continuously).
# So for instance if the hard limit is 32 megabytes and the soft limit is
# 16 megabytes / 10 seconds, the client will get disconnected immediately
# if the size of the output buffers reach 32 megabytes, but will also get
# disconnected if the client reaches 16 megabytes and continuously overcomes
# the limit for 10 seconds.
...
# Both the hard or the soft limit can be disabled by setting them to zero.
复制数据占用服务器资源的大小client-output-buffer-limit参数就决定了客户端输出缓冲区内存使用量,默认client-output-buffer-limit slave 256mb 64mb 60.
可通过config set修改
127.0.0.1:6379> config set client-output-buffer-limit "slave 536870912 134217728 120"127.0.0.1:6379> config get client-output-buffer-limit
1) "client-output-buffer-limit"
2) "normal 0 0 0 slave 1073741824 268435456 120 pubsub 536870912 134217728 60"
127.0.0.1:6379>
目前这个设定的意思就是,如果主从同步时,如果该缓冲区超过了 1gb或者达到256mb 持续120s,主节点会马上断开从节点的连接。断开连接后,在60s之后(repl-timeout),从节点发现没有从主节点中获得数据,会重新启动复制。如果master上的写命令还都在repl-backlog中则部分复制就可以完成。
# The following option sets the replication timeout for:
#
# 1) Bulk transfer I/O during SYNC, from the point of view of slave.
# 2) Master timeout from the point of view of slaves (data, pings).
# 3) Slave timeout from the point of view of masters (REPLCONF ACK pings).
#
# It is important to make sure that this value is greater than the value
# specified for repl-ping-slave-period otherwise a timeout will be detected
# every time there is low traffic between the master and the slave.
#
# repl-timeout 60
slave节点的客户端连接被杀掉,由于超过了client-output-buffer-limit slave,cachecloud的使用的是512mb 128mb 60。由于分片比较大全量复制时间较长,且master写入量较大,所以slave节点的客户端被干掉了
60+120 s这个时间可能很容易达到,特别是当你有:
- 低速存储器:如果主服务器或从服务器是基于低速存储器的,如果是主服务器将导致后台进程花费很多时间;如果是服务器磁盘读写数据时间将延长。
- 大数据集:更大的数据集将需要更长的存储时间和传输时间。
- 网络性能:当主服务器和从服务器的网络链路有限制带宽和高延迟时,这会直接影响数据传输传输速率。
个人认为: master 也可能“沦为”slave,所以这个参数应该对所有服务器修改。
该参数调整使得主从同步变快了,但是当数据同步完成后最好将配置修改为原配置,避免占用服务器资源过高引起其他问题。
参考:https://baijiahao.baidu.com/s?id=1604054459547563109&wfr=spider&for=pc
输入缓冲区 (发送命令)

pubsub客户端缓冲区
发布订阅是2.8之后新增的一个功能。
- 如需要开启,需要打开这个参数,AKE 代表服务器发送所有类型的键空间通知和键事件通知。
- · 想让服务器发送所有类型的键空间通知,可以将选项的值设置为 AK 。 ·
- 想让服务器发送所有类型的键事件通知,可以将选项的值设置为 AE 。
- · 想让服务器只发送和字符串键有关的键空间通知,可以将选项的值设置为 K$ 。
- · 想让服务器只发送和列表键有关的键事件通知,可以将选项的值设置为 El
# notify test cim
#tify-keyspace-events" takes as argument a string that is composed
notify-keyspace-events AKE
bash1
127.0.0.1:6382> SUBSCRIBE __keyspace@0__:k1
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "__keyspace@0__:k1"
3) (integer) 1
1) "message"
2) "__keyspace@0__:k1"
3) "set"
1) "message"
2) "__keyspace@0__:k1"
3) "set"
1) "message"
2) "__keyspace@0__:k1"
3) "del"
1) "message"
2) "__keyspace@0__:k1"
3) "set"
1) "message"
2) "__keyspace@0__:k1"
3) "set"
bash2
127.0.0.1:6382> set k1 222
OK
127.0.0.1:6382> set k1 222222
OK
127.0.0.1:6382> del k1
(integer) 1
127.0.0.1:6382> set k1 222222
OK
127.0.0.1:6382> set k1 2222222
OK
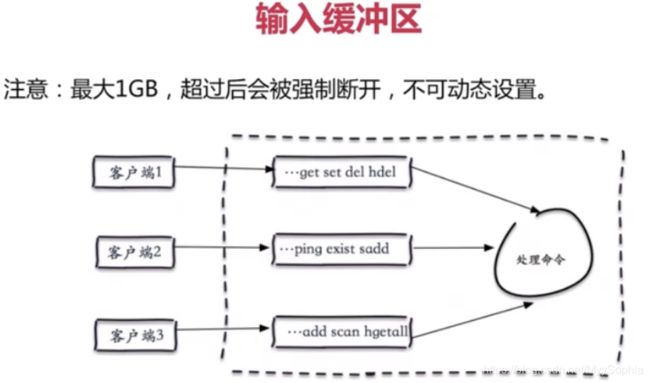
当输入缓冲区大于1G时一般会把session干掉,一般不会有问题。
复制缓冲区
复制缓冲区主从服务器同步数据时保存数据的内存区域。在一个完整的主从同步中,初始化阶段同步时,主服务器在复制缓冲区中保存数据的变化。初始化阶段完成后,缓冲的内容发送到从服务器。这个过程可能会遇到缓冲区的容量限制,达到最大容量时复制会重新开始。为了避免这种情况,缓冲区需要依据复制过程中变化的类型和数量进行初始化配置。
note:这也可以解释为何在dashboard上有时候已经快同步完了又重新同步。
全量复制:在主节点向从节点复制时,除了生成当前RDB文件,从节点通过这个RDB文件来实现复制,同样在主节点生成这个RDB文件的过程中,也可能还会有节点向主节点写入,这一部分写入的数据会被写入到一个缓冲区,再发送给slave节点RDB文件以后会再发送给slave节点缓冲区文件,这样就可以保证主从节点之间的完全同步。

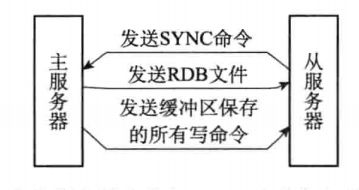
1.在slave第一次向master同步数据时,不知道master的run_id和offset,使用`psync ? -1`命令向master发起同步请求
2.master接受请求后,知道slave是做全量复制,master就会把run_id和offset响应给slave
3.slave保存master发送过来的run_id和offset
4.master响应slave后,执行BGSAVE命令把当前所有数据生成RDB文件,然后将RDB文件同步给slave
5.Redis中的repl_back_buffer复制缓冲区可以记录生成RDB文件之后到同步完成这个时间段时写入的数据,然后把这些数据也同步给slave
6.slave执行flushall命令清空slave中原有的数据,然后从RDB文件读取所有的数据,保证slave与master中数据的同步
部分复制,主要针对避免频繁的全量复制(要尽量避免全量复制,如果非要做全量复制,我们要尽量在小节点和低峰比如夜间这样的时间做全量复制),比如网络波动,丢失一小部分数据,就进行全量复制是非常不划算的。(这里主要利用的就是主节点在写入的时候会有一个缓冲区,这是一个队列,一般是1m大小,这个范围太小也会产生全量复制)
slave节点只用传输offset和runId可以避免全量复制带来的开销。

主服务器执行部分同步的过程:

1) 当主从节点之间网络出现中断时,如果超过了 repl-timeout 时间,主节点会认为从节点故障并中断复制连接。
2) 主从连接中断期间主节点依然响应命令,但因复制连接中断命令无法发送给从节点,不过主节点内部存在复制积压缓冲区( repl-backlog-buffer ),依然可以保存最近一段时间的写命令数据,默认最大缓存 1MB。
note:如果所有的slave(目前只有一个slave)都断开之后超过3600s,该缓冲区就会被清空。
127.0.0.1:6379> config get repl-backlog-size
1) "repl-backlog-size"
2) "1048576"
127.0.0.1:6379> config get repl-backlog-ttl
1) "repl-backlog-ttl"
2) "3600"3) 当主从节点网络恢复后,从节点会再次连上主节点。
4) 当主从连接恢复后,由于从节点之前保存了自身已复制的偏移量和主节点的运行ID。因此会把它们作为 psync 参数发送给主节点,要求进行补发复制操作。
5) 主节点接到 psync 命令后首先核对参数 runId 是否与自身一致,如果一致,说明之前复制的是当前主节点;之后根据参数 offset 在自身复制积压缓冲区查找,如果偏移量之后的数据存在缓冲区中,则对从节点发送 +CONTINUE 响应,表示可以进行部分复制。
6) 主节点根据偏移量把复制积压缓冲区里的数据发送给从节点,保证主从复制进入正常状态。
--------------------------------------------update 2020年6月16日17:25:30---------------------------------------------------------------
一直对主从复制有几个疑惑
1、slave同步master的数据的时候slave是如何判别要做全量还是增量?

2、slave 客户端
2、同步的时候slave 如何知道哪些是同步时写入的数据?
得益于copy on write技术,以下内容来自于https://www.cnblogs.com/ITPower/articles/12399999.html。
那么, 什么是copy-on-write呢? copy-on-write的原理.
redis有一个主进程, 在写数据, 这时候有一个命令过来了, 说要把数据持久化到磁盘.

我们知道redis的worker是单线程的, 如果要持久化这个行为也放在单线程里, 那么如果需要持久化数据特别多, 将会影响用户的使用. 所以单开一个进程专门来做持久化的操作.
那么写数据, 写什么呢? 肯定是要把redis内存中的数据写入. 这时候, 其实redis内存中的数据保存的是一个虚拟地址. 他真实指向的是物理内存的地址(绿色部分)

这时候, 要拷贝, 就是把真实数据的地址拷贝一份到需要持久化的进程中
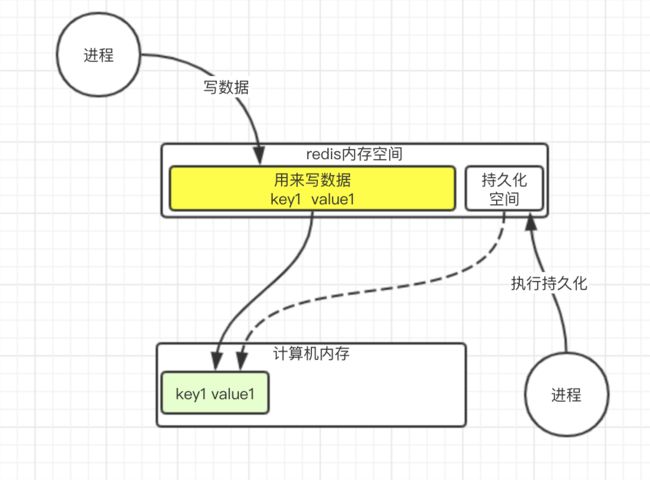
其实持久化进程这个时候只是指向了数据的地址, 内存消耗并不多. 如果这时候, 原来的数据修改了, 怎么办呢?
redis会开辟一块新的空间, 让写数据的地址指向新的空间

这样就不会影响持久化进程需要持久化的数据了.
------------------------------------------------------------------update 2020年6月16日17:31:17-----------------------------------------
AOF缓冲区

AOF 的缓冲区内存没有容量限制?
五、对象内存
key不宜过长。
coids的开发者曾经在答疑文章中这样说到:
Codis 并不太适合 key 少,但是 value 特别大的应用, 而且你的 key 越少, value 越大,最后就会退化成单个 redis 的模型 (性能还不如 raw redis),所以 Codis 更适合海量 Key, value比较小 (<= 1 MB) 的应用。
https://blog.csdn.net/MyySophia/article/details/105362844
六、内存碎片
1、必然存在; jemalloc
2、优化方式
- 避免频繁更新操作:append、setrange
- 安全重启,例如停掉slave 切到另外一台机器,再重启来解决,由于是Coid是读写分离,如果slave 和master 差距过大会导致重启slave瞬时读不到某些key。存在风险。官方给出大于1.4
七、子进程内存消耗

八、内存管理
设置内存上线
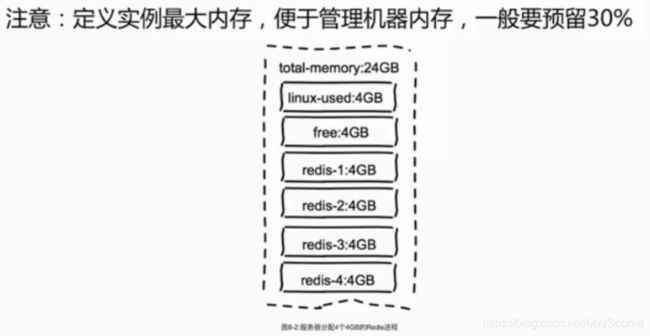
预留30%是为了防止fork子进程内存溢出,AOF缓冲区内存和bgsave。
客户端缓冲区max mem无法控制。
动态调整内存上线
[root@P1QMSPL2RTM01 ~]# redis-cli -p 6379
127.0.0.1:6379> config get maxmemory
1) "maxmemory"
2) "200000000000"

设定完内存后需要执行rewrite ,如果使用的内存大于修改的内存,执行rewrite存在丢数据的情况。
127.0.0.1:6382> config set maxmemory 200mb
OK
127.0.0.1:6382> info memory
# Memory
used_memory:104980536
used_memory_human:100.12M
used_memory_rss:129589248
used_memory_rss_human:123.59M
used_memory_peak:105615672
used_memory_peak_human:100.72M
total_system_memory:270895587328
total_system_memory_human:252.29G
used_memory_lua:37888
used_memory_lua_human:37.00K
maxmemory:209715200
maxmemory_human:200.00M
maxmemory_policy:volatile-lru
mem_fragmentation_ratio:1.23
mem_allocator:jemalloc-4.0.3
127.0.0.1:6382> config rewrite
OK
rewrite的log

内存回收策略
删除过期键
1、惰性删除:访问key -> expire dict -> del key
如果不访问是不会删除的?
超过了maxmemory后触发相应的策略,有maxmemory-policy控制来负责回收expire的空间。
2、定时删除:每秒运行10次,采样删除。

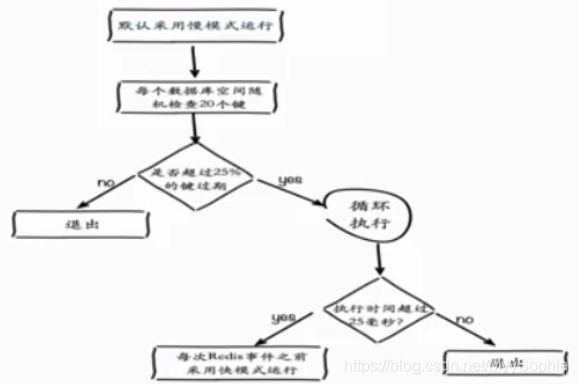

针对现有的业务,我认为可以通过TTL 命令来拼接key进行主动删除。另外一种方式就是选择在业务低峰的时候使用keys *来主动访问expire dictionary来释放内存。业务种设计过期键粒度较细,占用不少内存。
内存溢出控制策略
服务器上的配置获取方式
[root@P1QMSPL2RTM01 monitor]# redis-cli -p 6379
127.0.0.1:6379> CONFIG GET maxmemory
1) "maxmemory"
2) "200000000000"
127.0.0.1:6379> CONFIG GET maxmemory-policy
1) "maxmemory-policy"
2) "volatile-lru"
maxmemory的官方说法
# Don't use more memory than the specified amount of bytes.
# When the memory limit is reached Redis will try to remove keys
# according to the eviction policy selected (see maxmemory-policy).
#
# If Redis can't remove keys according to the policy, or if the policy is
# set to 'noeviction', Redis will start to reply with errors to commands
# that would use more memory, like SET, LPUSH, and so on, and will continue
# to reply to read-only commands like GET.
#
# This option is usually useful when using Redis as an LRU cache, or to set
# a hard memory limit for an instance (using the 'noeviction' policy).
#
# WARNING: If you have slaves attached to an instance with maxmemory on,
# the size of the output buffers needed to feed the slaves are subtracted
# from the used memory count, so that network problems / resyncs will
# not trigger a loop where keys are evicted, and in turn the output
# buffer of slaves is full with DELs of keys evicted triggering the deletion
# of more keys, and so forth until the database is completely emptied.
#
# In short... if you have slaves attached it is suggested that you set a lower
# limit for maxmemory so that there is some free RAM on the system for slave
# output buffers (but this is not needed if the policy is 'noeviction').
超过了maxmemory后触发相应的策略,由maxmemory-policy控制
policy的官方解释如下
# MAXMEMORY POLICY: how Redis will select what to remove when maxmemory
# is reached. You can select among five behaviors:
#
# volatile-lru -> remove the key with an expire set using an LRU algorithm
# allkeys-lru -> remove any key according to the LRU algorithm
# volatile-random -> remove a random key with an expire set
# allkeys-random -> remove a random key, any key
# volatile-ttl -> remove the key with the nearest expire time (minor TTL)
# noeviction -> don't expire at all, just return an error on write operations
#
# Note: with any of the above policies, Redis will return an error on write
# operations, when there are no suitable keys for eviction.
#
# At the date of writing these commands are: set setnx setex append
# incr decr rpush lpush rpushx lpushx linsert lset rpoplpush sadd
# sinter sinterstore sunion sunionstore sdiff sdiffstore zadd zincrby
# zunionstore zinterstore hset hsetnx hmset hincrby incrby decrby
# getset mset msetnx exec sort
- Noeviction:默认策略,不会删除任何数据,拒绝所有写入操作并返回错误信息: oom command not allowed when used memory,此时,redis只相应读操作。
- Volatile-lru:根据LRU(最近未被使用)算法删除设置了expire的键,直到腾出足够的空间为止,如果没有可删除的对象,回退到Noeviction策略
- allKeys-LRU:根据LRU()算法删除键,不管是否过期。
- allKeys-random:随机删除所有键
- volatile-random:随机删除过期健
- volatile-ttl: 根据键值对象的ttl属性,删除最近将要过期的数据,如果没有回退到策略1.
九、内存优化
内存分布
略
合理选择优化数据结构
需求:计算网站每天独立用户数
选择:集合、 bitmaps 、hyperloglog(https://www.jianshu.com/p/55defda6dcd2)

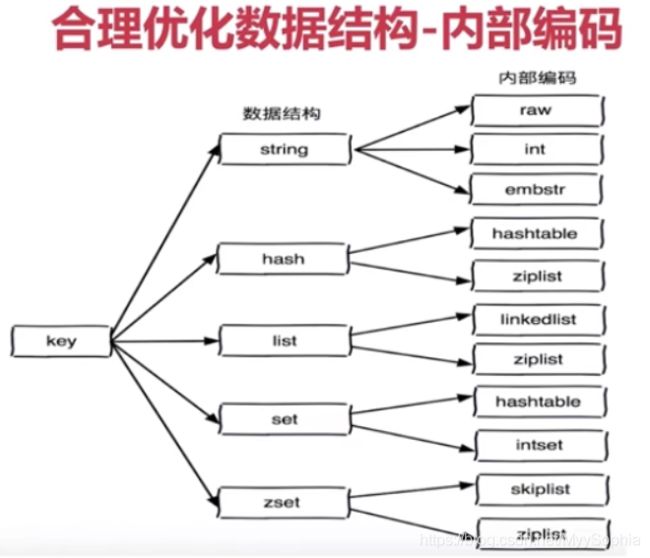
Redis内部针对不同类型存在编码的概念,所谓编码就是具体使用哪种底层数据结构来实现。编码不同将直接影响数据的内存占用和读写效率。
Redis作者想通过不同编码实现效率和空间的平衡。比如当我们的存储只有10个元素的列表,当使用双向链表数据结构时,必然需要维护大量的内部字段如每个元素需要:前置指针,后置指针,数据指针等,造成空间浪费,如果采用连续内存结构的压缩列表(ziplist),将会节省大量内存,而由于数据长度较小,存取操作时间复杂度即使为O(n2)性能也可满足需求。
编码类型转换在Redis写入数据时自动完成,这个转换过程是不可逆的,转换规则只能从小内存编码向大内存编码转换。
redis> lpush list:1 a b c d
(integer) 4 //存储4个元素
redis> object encoding list:1
"ziplist" //采用ziplist压缩列表编码
redis> config set list-max-ziplist-entries 4
OK //设置列表类型ziplist编码最大允许4个元素
redis> lpush list:1 e
(integer) 5 //写入第5个元素e
redis> object encoding list:1
"linkedlist" //编码类型转换为链表
redis> rpop list:1
"a" //弹出元素a
redis> llen list:1
(integer) 4 // 列表此时有4个元素
redis> object encoding list:1
"linkedlist" //编码类型依然为链表,未做编码回退
127.0.0.1:6380> config get hash-max-ziplist-value
1) "hash-max-ziplist-value"
2) "64"
list-max-ziplist-entries参数,这个参数用来决定列表长度在多少范围内使用ziplist编码。当然还有其它参数控制各种数据类型的编码。hash,list,set,zset内部编码配置表:
| 类型 | 编码 | 决定条件 |
|---|---|---|
| hash | ziplist | 满足所有条件: value最大空间(字节)<=hash-max-ziplist-value field个数<=hash-max-ziplist-entries |
| 同上 | hashtable | 满足任意条件: value最大空间(字节)>hash-max-ziplist-value field个数>hash-max-ziplist-entries |
| list | ziplist | ziplist 满足所有条件: value最大空间(字节)<=list-max-ziplist-value 链表长度<=list-max-ziplist-entries |
| 同上 | linkedlist | 满足任意条件 value最大空间(字节)>list-max-ziplist-value 链表长度>list-max-ziplist-entries |
| 同上 | quicklist | 3.2版本新编码: 废弃list-max-ziplist-entries和list-max-ziplist-entries配置 使用新配置: list-max-ziplist-size:表示最大压缩空间或长度,最大空间使用[-5-1]范围配置,默认-2表示8KB,正整数表示最大压缩长度 list-compress-depth:表示最大压缩深度,默认=0不压缩 |
| set | intset | 满足所有条件: 元素必须为整数 集合长度<=set-max-intset-entries |
| 同上 | hashtable | 满足任意条件 元素非整数类型 集合长度>hash-max-ziplist-entries |
| zset | ziplist | 满足所有条件: value最大空间(字节)<=zset-max-ziplist-value 有序集合长度<=zset-max-ziplist-entries |
| 同上 | skiplist | 满足任意条件: value最大空间(字节)>zset-max-ziplist-value 有序集合长度>zset-max-ziplist-entries |
zset的底层存储是skiplist或者ziplist,
1、查看类型
-
127.0.0.1:6380> type testKey -
zset
2、查看底层数据结构
-
127.0.0.1:6380> OBJECT encoding testKey -
"skiplist"
什么是skiplist呢?
其原代码放在这个目录中。

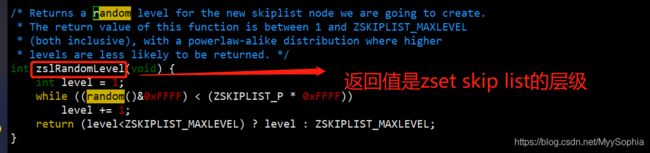
可以看到redis中当存储的value长度大约ZSKIPLIST_MAXLEVEL(521字节)
3、string类型较长时存为string,较短则存成int ,这就是简单动态字符串(simple dynamic string)SDS。
127.0.0.1:6381> set test 123456789101112
OK
127.0.0.1:6381> OBJECT ENCODING test
"int"
127.0.0.1:6381> set test 12345678910111213141516171819292122232425
OK
127.0.0.1:6381> OBJECT ENCODING test
"embstr"
127.0.0.1:6381> set test 123456789101112131415161718192921222324251111111111111111111111111111111111111111111111111111111111111111111111111111111
OK
127.0.0.1:6381> OBJECT ENCODING test
"raw" //长度大于39编码方式为 raw
事实上这背后的原理还很复杂,有兴趣可参考付磊著 redis设计与运维
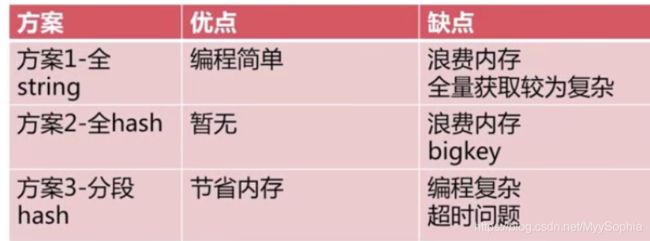
需求:picId >=userI(10亿)
方案:
1、全部string :set picId userId
2、一个hash :hset allPics picId userId
3、若干个小hash :hset picId/100 picId%100 userId
对比测试<100W>
| String | 115M |
| hset | 129M |
| 若干个hash | 26M |

1、配置(支持动态修改)
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
2、ziplist(小和长度有限对象)
- 连续内存
- 读写有指针位移
- 新增删除有内存重分配
客户端内存优化
一次内存暴增

master 超过了maxmem ,而从节点没有异常。
要考虑哪些方面?
1、先想一下redis的内存组成 , 自身+ 缓冲+ kv数据
2、主从复制问题?
3、缓冲 复制缓冲区?AOF缓冲区?(检查硬盘)?输入客户端缓冲区?输出缓冲区?
排查(大部分都是客户端缓冲区):
1、看dbsize大小是否一致
2、查看client_longest_output_list (输出客户端缓冲区list)
3、client list 查看内存使用量,查看cmd为何?

monitor 命令慎用
预防和处理
1、处理:干掉monitor进程
2、预防
禁用monitor(rename-command),适度限制缓冲区大小
cachecloud 监控(https://github.com/sohutv/cachecloud#cc7)
监控输出缓冲区大小,使用info命令查看
client_longest_output_list:0https://www.iteye.com/blog/carlosfu-2254571
其他方法

该不该使用redis

十、总结
序列化是有成本的
不要忽略键的长度
参考:
1、https://cachecloud.github.io/2017/02/16/Redis%E5%86%85%E5%AD%98%E4%BC%98%E5%8C%96/
2、redis主从复制(2)— replication buffer与replication backlog
3、复制超时
4、主从同步的参数问题 https://github.com/redis-io/redis/issues/1400
5、copy on write 技术 https://www.cnblogs.com/Java3y/p/9884583.html
6、深入理解复制 https://www.cnblogs.com/ivictor/p/9749491.html