使用Kettle 对记录排序并取前面n条记录的方法
2.1:测试数据准备工作
-- 创建表
CREATE TABLE `tmallorder` (
`datekey` INT(11) NOT NULL,-- 日期
`storename` VARCHAR(50) CHARACTER SET utf8 COLLATE utf8_bin DEFAULT NULL, -- 店铺名称
`goodsname` VARCHAR(50) CHARACTER SET utf8 COLLATE utf8_bin DEFAULT NULL, -- 商品名称
`goodsmoney` DECIMAL(20,4) DEFAULT NULL -- 销售额
) ENGINE=INNODB DEFAULT CHARSET=utf8
-- 插入测试数据
INSERT INTO tmallorder(datekey,storename,goodsname,goodsmoney)
VALUES(20121111,'GXG旗舰店','GXG黑色呢绒大衣20121111G1',985231455.80)
INSERT INTO tmallorder(datekey,storename,goodsname,goodsmoney)
VALUES(20121111,'GXG旗舰店','GXG黑色呢绒大衣20121111G2',882373145.48)
INSERT INTO tmallorder(datekey,storename,goodsname,goodsmoney)
VALUES(20121111,'太平鸟旗舰店','太平鸟黑色呢绒大衣20121111T1',100025863.80)
INSERT INTO tmallorder(datekey,storename,goodsname,goodsmoney)
VALUES(20121111,'太平鸟旗舰店','太平鸟黑色呢绒大衣20121111T3',1126988817.48)
INSERT INTO tmallorder(datekey,storename,goodsname,goodsmoney)
VALUES(20121112,'GXG旗舰店','GXG黑色呢绒大衣20121111G1',2585231455.80)
INSERT INTO tmallorder(datekey,storename,goodsname,goodsmoney)
VALUES(20121112,'GXG旗舰店','GXG黑色呢绒大衣20121111G2',1585231455.80)
INSERT INTO tmallorder(datekey,storename,goodsname,goodsmoney)
VALUES(20121112,'太平鸟旗舰店','太平鸟黑色呢绒大衣20121111T1',300025863.80)
INSERT INTO tmallorder(datekey,storename,goodsname,goodsmoney)
VALUES(20121112,'太平鸟旗舰店','太平鸟黑色呢绒大衣20121111T2',170025863.80)
--最终的统计结果
日期 店铺 商品名称 销售额
20121111 GXG旗舰店 GXG黑色呢绒大衣20121111G1 985231455.8000
20121111 GXG旗舰店 GXG黑色呢绒大衣20121111G2 882373145.4800
20121111 太平鸟旗舰店 太平鸟黑色呢绒大衣20121111T1 100025863.8000
20121111 太平鸟旗舰店 太平鸟黑色呢绒大衣20121111T2 126988817.4800
20121111 太平鸟旗舰店 太平鸟黑色呢绒大衣20121111T3 1126988817.4800
20121112 GXG旗舰店 GXG黑色呢绒大衣20121111G1 2585231455.8000
20121112 GXG旗舰店 GXG黑色呢绒大衣20121111G2 1585231455.8000
20121112 太平鸟旗舰店 太平鸟黑色呢绒大衣20121111T1 300025863.8000
20121112 太平鸟旗舰店 太平鸟黑色呢绒大衣20121111T2 170025863.8000
2.2: 针对所有记录排序取top n,不分组取top n
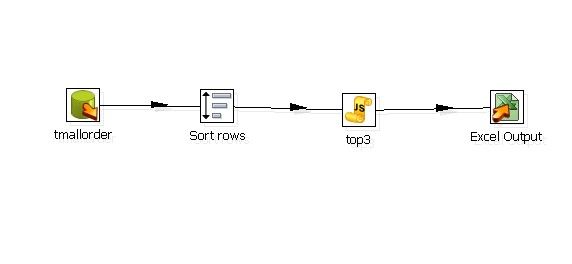
组件:sortrows+js
2.2.1:
tmallorder就是测试表数据的一个输出,sort rows 就是先针对记录做一个排序,针对业务需求选择是降序或者是升序,本例是取交易额大的所以排序指标是降序
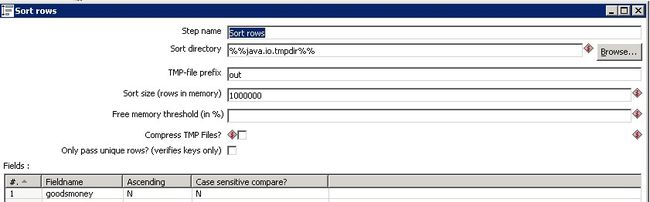
排序字段为1个 交易额 ASC 为N即为降序排序。
2.2.2:
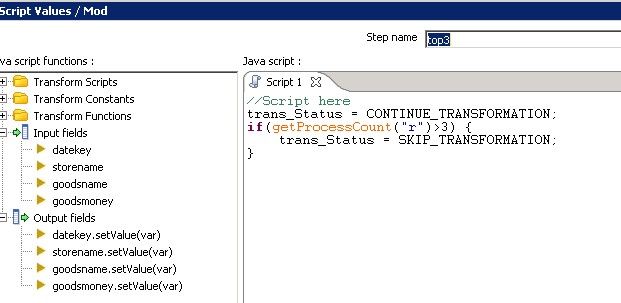
trans_Status = CONTINUE_TRANSFORMATION;
if(getProcessCount("r")>3) {
trans_Status = SKIP_TRANSFORMATION;
}
SKIP_TRANSFORMATION , ERROR_TRANSFORMATION, CONTINUE_TRANSFORMATION是TRANSFORMATION已经预先定义好的静态常量,不可更改。 作用是 过滤记录行,控制转换流程
例如:
trans_Status = CONTINUE_TRANSFORMATION
if (field.getString()==’123’) trans_Status = SKIP_TRANSFORMATION
getProcessCount("")方法在kettle是一个特殊的函数,含义和参数解释spoon官方解释:
// Returns a number with the current processed Rows.
// The type is changable.
//
// Usage:
// getProcessCount(var);
// 1: String - The Pentaho/Kettle Type:
// u - Lines Update
// i - Lines Insert
// w - Lines Write
// r - Lines Read
// o - Lines Output
JS后面的操作就是输出处理后的数据了,我们可以看一下结果,如下图。
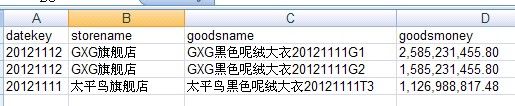
在TEST的所有结果集里面取交易额top3记录,我们看前面的表数据可以看出处理结果是正确的。
2.3: 针对所有记录排序取top n,分组取top n 即在每天都取出top N
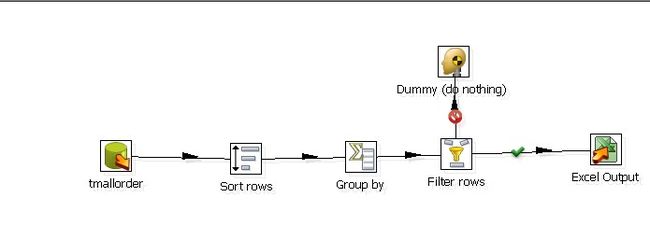
组件:sort rows+group by+Filter rows
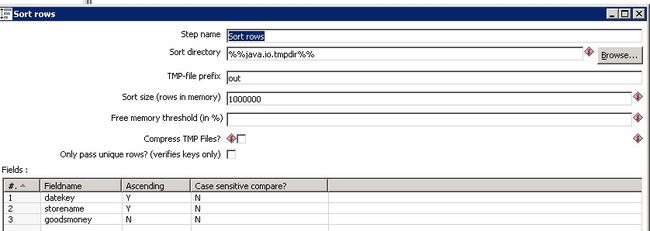
2.3.1:因为是分组排序取top n,所以在分组之前排序的时候除了top n的标准字段金额之外,就是还要加上要分组的字段,如下图:
goodsmoney就是top的标准按照金额最大取top 分组字段为datekey日期。
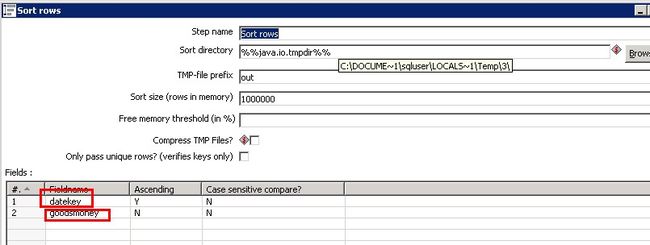
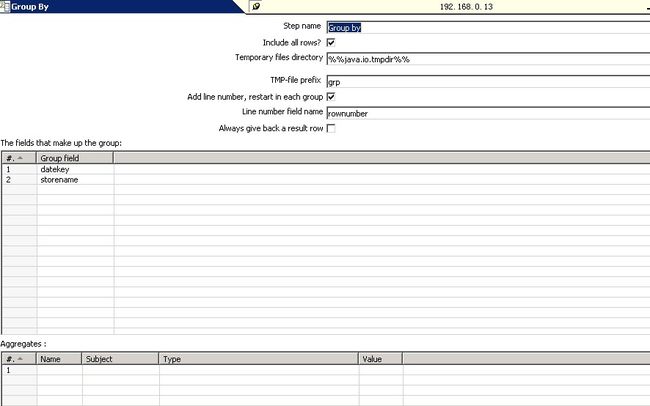
2.3.2:说到分组排序就要说分组了 这里我们就用到了我们日常经常使用的group by组件如下图,打钩的地方勾上。Add line number处给一个字段,名字自定
此处我设置的是rownunber,分组字段就是分组取top的字段比如每天,每个店铺都可以。rownumber 会作为下一步的一个新增字段。
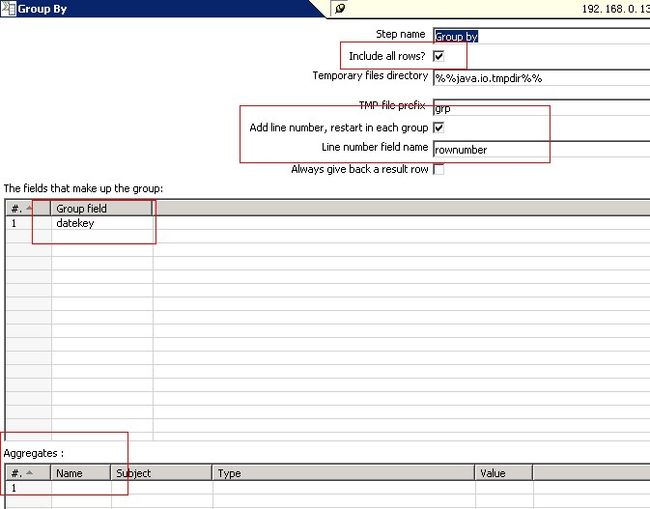
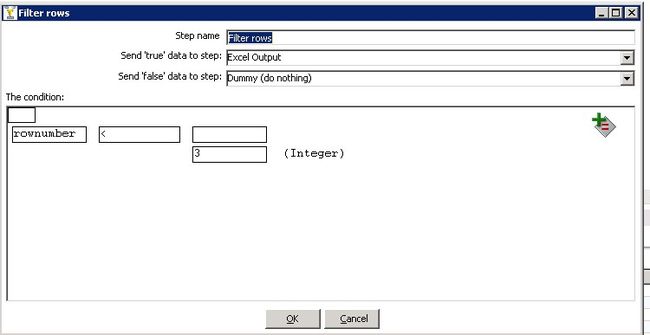
2.3.3:最后一步就是要用到过滤(Filter rows)上一步的rownumber其实就是分组排序后的每一个排名字段。我们取top3,
即为rownumber<4的所有数据
如下图:
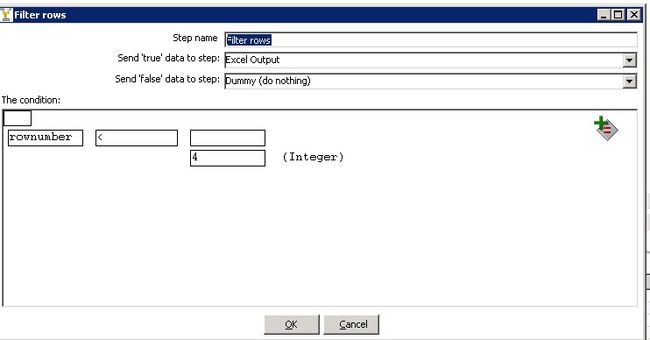
最终结果为:
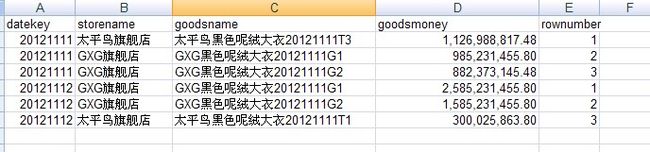
和测试表结果对比后,我们可以发现11号和12号两天的数据分别取top3是正确的。
2.4: 针对kettle分组排序取topn 的总结:
其实规则都一样,如果再往下扩展,取每天每个店铺的top2我们就可以在sort rows 和group by 中添加指标即可,过滤的操作不变,就是topn 中N的值。
取每天每个店铺的top2:具体的就不再多说了,看步骤:
step1: top指标还是交易额字段,group by 为日期 店铺
step2:group by 为日期 店铺 添加排序标示
step3:取top2 rownumber<3
step 4:预览处理结果:
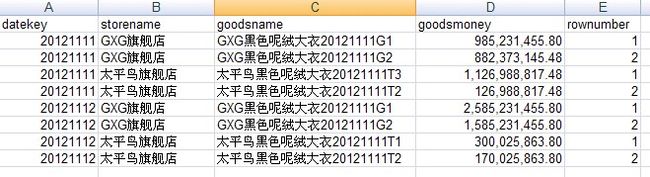
和表中数据对比后可发现,11和12号两天中,GXG和太平鸟两个店铺销售额前2的商品数据是正确的。
总结:无论是哪一种ETL ,工具其实都是有它的优点和缺点的。利用好他们的优点,想办法解决他们的缺点,会给我们的工作带来轻松和愉快,谢谢大家。