python requests.session验证码登录应用实战,爱站关键词挖掘采集
爱站站长工具一直是不少个人站长,seo相关从业者使用的工具之一,相比站长工具数据,爱站站长工具的数据更具有参考意义,前段时间爱站一直是关站状态,是因为专利侵权?还是其他呢?应该没有什么大体上的更新,网页规则没有发生什么改变,以前写的python抓取源码还是能够使用。

爱站网成立于2009年,主办单位是亿讯网络公司,是一家专门针对中文站点提供服务的网站,主要为广大站长提供站长工具查询,目前网站访问量已超过百万,注册会员100万人次。
爱站关键词挖掘工具抓取几个关键点:
1.需登录方可查看获取全部数据
两个思路:
第一:直接粘贴登录后的 cookies 特别简单方便!
第二:使用 requests.session 保持cookies 登录状态 获取我们想要的采集数据。
self.s=requests.session() #设置一个会话
#登录网站账号
def login(self):
data = {
'refer': 'https://ci.aizhan.com/',
'username':self.username,
'password':self.password,
'code': self.code,
}
html=self.s.post(self.login_url,data=data,timeout=10).content.decode('utf-8')
time.sleep(2)
self.html=html
#登录主程序
def login_main(self):
self.get_code()
self.login()
self.verify()
if self.status==1:
print("正在重新获取验证码,请稍候重新输入验证码...")
time.sleep(2)
self.get_code()
self.login()
self.verify()
if self.status == 2:
print(">>>程序终止!")
sys.exit()
2.验证码登录的处理
我这里处理是手工打码,下载到验证码图片,然后输入验证码,登录网站。
当然你可以接入第三方打码平台;
或者使用图片识别;
或者人工智能学习!
#获取验证码信息
def get_code(self):
code_html = self.s.get(self.login_url,headers=self.headers,timeout=10).content.decode('utf-8')
time.sleep(2)
captcha=re.findall(r') ,code_html,re.S)[0]
img_code_url=f'https://www.aizhan.com/{captcha}'
print(f"验证码图片地址为:{img_code_url},正在获取图片内容...")
r=self.s.get(img_code_url,timeout=10)
time.sleep(2)
with open(f'code.png','wb') as f:
f.write(r.content)
code=input("请打开图片,输入图片验证码:")
print(">>>已获取验证码,下一步,准备尝试登录...")
self.code=code
,code_html,re.S)[0]
img_code_url=f'https://www.aizhan.com/{captcha}'
print(f"验证码图片地址为:{img_code_url},正在获取图片内容...")
r=self.s.get(img_code_url,timeout=10)
time.sleep(2)
with open(f'code.png','wb') as f:
f.write(r.content)
code=input("请打开图片,输入图片验证码:")
print(">>>已获取验证码,下一步,准备尝试登录...")
self.code=code
本渣渣就只会手动党,最渣的方式。。
3.登录成功的状态验证,以及验证码输入有误的处理
#验证登录是否成功
def verify(self):
if "退出" in self.html:
print(">>>爱站账号登录成功了!")
status=0
elif "验证码错误" in self.html:
print(">>>验证码输入有误!")
status=1
else:
print(">>>爱站账号登录失败!")
print(">>>请检查爱站账号是否有误或者是否被封禁或者网站是否无法打开!")
status=2
self.status=status
4.关键词字符转成url地址格式(关键点!!!)
还好网上有大佬分享!!
来源:https://www.biaodianfu.com/aizhan-keywords.html
http://static.aizhan.com/js/home.js
function encode_unicode_param(a) {
for (var s = "
", t = 0; t < a.length; t++) {
var e = a.charCodeAt(t).toString(16);
s += (2 == e.length) ? "
n
" + e : e
}
return s
}
function decode_unicode_param(a) {
a = a.replace(/n/g, "
00
");
for (var s = "
", t = 0; t < a.length / 4; t++) s += unescape("
%u
" + a.substr(4 * t, 4));
return s
}
来源:https://www.biaodianfu.com/aizhan-keywords.html
#关键词字符url转换
def get_keyword_url(self):
s = ""
if self.keyword:
self.keyword =self.keyword.replace('+', '')
for c in keyword:
e = hex(ord(c))[2:]
if len(e) == 2:
e = "n" + e
s += e
print(s)
return s
5.数据采集的特殊情况处理
第一:关键词无数据

第二:关键词数据存在分页情况
所以数据采集处理的时候有三种情况(暂时我就观察到这样的三种情况)
#爱站关键词挖掘
def get_keywords(self):
key=self.keyword
keyurl=self.get_keyword_url()
url=f'https://ci.aizhan.com/{keyurl}/'
html=self.s.get(url,timeout=10).content.decode('utf-8')
if "没有相关的关键词。" in html:
print(f'{key}没有相关的关键词')
print(">>>采集程序终止!")
sys.exit()
req=etree.HTML(html)
pagenum=req.xpath('//div[@class="pager"]/ul/li/a/text()')[-1]
if int(pagenum)>1:
print(f'{key}关键词数据存在分页,共有{pagenum}个分页!')
for i in range(1,int(pagenum)+1):
print(f'正在采集第{i}页关键词数据..')
page_url=f'{url}{i}/'
page_html = self.s.get(page_url, timeout=10).content.decode('utf-8')
time.sleep(2)
page_req = etree.HTML(page_html)
datas=self.get_page_kewords(page_req)
self.keywords_data.extend(datas)
print(f">>>采集关键词数据完成!")
else:
print(f'{key}关键词数据没有分页,正在抓取关键词数据...')
datas=self.get_page_kewords(req)
self.keywords_data.extend(datas)
print(f">>>采集关键词数据完成!")
6.数据的保存,还是保存为excel格式文件!
#保存数据为excel
def save_datas(self):
key=self.keyword
print(f"正在保存{key}关键词数据...")
workbook = xlwt.Workbook(encoding='utf-8')
booksheet = workbook.add_sheet('Sheet 1', cell_overwrite_ok=True)
title = [['序号', '关键词', 'PC/移动指数', '收录数', '首页第1位网页链接', '首页第1位网页标题', '首页第2位网页链接', '首页第2位网页标题']]
title.extend(self.keywords_data)
for i, row in enumerate(title):
for j, col in enumerate(row):
booksheet.write(i, j, col)
workbook.save(f'{key}.xls')
print(f">>>保存关键词数据为 {key}.xls 成功!")
采集效果:
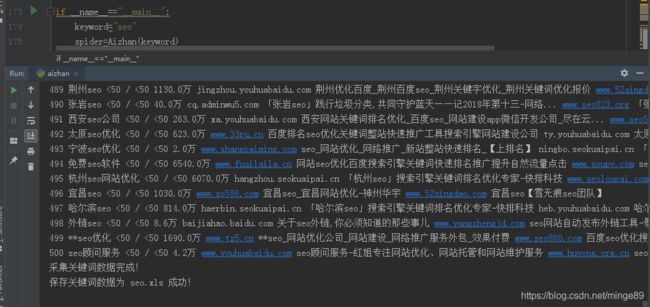


附完整源码:
#爱站关键词挖掘
#20200214 by 微信:huguo00289
# -*- coding: utf-8 -*-
import requests,time,re,sys
from fake_useragent import UserAgent
from lxml import etree
import xlwt
class Aizhan(object):
def __init__(self,keyword,username,password):
self.ua=UserAgent()
self.headers={
'UserAgent':self.ua.random}
self.s=requests.session() #设置一个会话
self.login_url = "https://www.aizhan.com/login.php"
self.code=''
self.html=''
self.status=int()
self.keywords_data=[]
self.keyword = keyword
self.username=username
self.password=password
#获取验证码信息
def get_code(self):
code_html = self.s.get(self.login_url,headers=self.headers,timeout=10).content.decode('utf-8')
time.sleep(2)
captcha=re.findall(r',code_html,re.S)[0]
img_code_url=f'https://www.aizhan.com/{captcha}'
print(f"验证码图片地址为:{img_code_url},正在获取图片内容...")
r=self.s.get(img_code_url,timeout=10)
time.sleep(2)
with open(f'code.png','wb') as f:
f.write(r.content)
code=input("请打开图片,输入图片验证码:")
print(">>>已获取验证码,下一步,准备尝试登录...")
self.code=code
#登录网站账号
def login(self):
data = {
'refer': 'https://ci.aizhan.com/',
'username':self.username,
'password':self.password,
'code': self.code,
}
html=self.s.post(self.login_url,data=data,timeout=10).content.decode('utf-8')
time.sleep(2)
self.html=html
#验证登录是否成功
def verify(self):
if "退出" in self.html:
print(">>>爱站账号登录成功了!")
status=0
elif "验证码错误" in self.html:
print(">>>验证码输入有误!")
status=1
else:
print(">>>爱站账号登录失败!")
print(">>>请检查爱站账号是否有误或者是否被封禁或者网站是否无法打开!")
status=2
self.status=status
#关键词字符url转换
def get_keyword_url(self):
"""
http://static.aizhan.com/js/home.js
function encode_unicode_param(a) {
for (var s = "", t = 0; t < a.length; t++) {
var e = a.charCodeAt(t).toString(16);
s += (2 == e.length) ? "n" + e : e
}
return s
}
function decode_unicode_param(a) {
a = a.replace(/n/g, "00");
for (var s = "", t = 0; t < a.length / 4; t++) s += unescape("%u" + a.substr(4 * t, 4));
return s
}
来源:https://www.biaodianfu.com/aizhan-keywords.html
"""
s = ""
if self.keyword:
self.keyword =self.keyword.replace('+', '')
for c in keyword:
e = hex(ord(c))[2:]
if len(e) == 2:
e = "n" + e
s += e
print(s)
return s
#爱站关键词挖掘
def get_keywords(self):
key=self.keyword
keyurl=self.get_keyword_url()
url=f'https://ci.aizhan.com/{keyurl}/'
html=self.s.get(url,timeout=10).content.decode('utf-8')
if "没有相关的关键词。" in html:
print(f'{key}没有相关的关键词')
print(">>>采集程序终止!")
sys.exit()
req=etree.HTML(html)
pagenum=req.xpath('//div[@class="pager"]/ul/li/a/text()')[-1]
if int(pagenum)>1:
print(f'{key}关键词数据存在分页,共有{pagenum}个分页!')
for i in range(1,int(pagenum)+1):
print(f'正在采集第{i}页关键词数据..')
page_url=f'{url}{i}/'
page_html = self.s.get(page_url, timeout=10).content.decode('utf-8')
time.sleep(2)
page_req = etree.HTML(page_html)
datas=self.get_page_kewords(page_req)
self.keywords_data.extend(datas)
print(f">>>采集关键词数据完成!")
else:
print(f'{key}关键词数据没有分页,正在抓取关键词数据...')
datas=self.get_page_kewords(req)
self.keywords_data.extend(datas)
print(f">>>采集关键词数据完成!")
#采集单页关键词数据
def get_page_kewords(self,req):
datas=[]
orders=req.xpath('//table[@class="table table-striped table-s2"]/tbody/tr/td[@class="order"]/text()') #序号
titles = req.xpath('//table[@class="table table-striped table-s2"]/tbody/tr/td[@class="title"]/a/@title') #关键词
centers = req.xpath('//table[@class="table table-striped table-s2"]/tbody/tr/td[@class="center"]/span/text()') #PC/移动指数
levels = req.xpath('//table[@class="table table-striped table-s2"]/tbody/tr/td[@class="level"]/text()') # 收录数
url1s = req.xpath('//table[@class="table table-striped table-s2"]/tbody/tr/td[@class="url"][1]/a/i/text()') # 首页第1位网页链接
url1_titles = req.xpath('//table[@class="table table-striped table-s2"]/tbody/tr/td[@class="url"][1]/a/p/text()') # 首页第1位网页标题
url2s = req.xpath('//table[@class="table table-striped table-s2"]/tbody/tr/td[@class="url"][2]/a/i/text()') # 首页第2位网页链接
url2_titles = req.xpath('//table[@class="table table-striped table-s2"]/tbody/tr/td[@class="url"][2]/a/p/text()') # 首页第2位网页标题
for order,title,center,level,url1,url1_title,url2,url2_title in zip(orders,titles,centers,levels,url1s,url1_titles,url2s,url2_titles):
print(order,title,center,level,url1,url1_title,url2,url2_title)
data=[order,title,center,level,url1,url1_title,url2,url2_title]
datas.append(data)
time.sleep(2)
return datas
#保存数据为excel
def save_datas(self):
key=self.keyword
print(f"正在保存{key}关键词数据...")
workbook = xlwt.Workbook(encoding='utf-8')
booksheet = workbook.add_sheet('Sheet 1', cell_overwrite_ok=True)
title = [['序号', '关键词', 'PC/移动指数', '收录数', '首页第1位网页链接', '首页第1位网页标题', '首页第2位网页链接', '首页第2位网页标题']]
title.extend(self.keywords_data)
for i, row in enumerate(title):
for j, col in enumerate(row):
booksheet.write(i, j, col)
workbook.save(f'{key}.xls')
print(f">>>保存关键词数据为 {key}.xls 成功!")
#登录主程序
def login_main(self):
self.get_code()
self.login()
self.verify()
if self.status==1:
print("正在重新获取验证码,请稍候重新输入验证码...")
time.sleep(2)
self.get_code()
self.login()
self.verify()
if self.status == 2:
print(">>>程序终止!")
sys.exit()
if __name__=="__main__":
username=input("请输入爱站站长工具账号名称:")
password = input("请输入爱站站长工具账号密码:")
keyword=input("请输入要挖掘的关键词:")
spider=Aizhan(keyword,username,password)
spider.login_main()
spider.get_keywords()
spider.save_datas()
以上仅供参考和学习,如有雷同肯定是我抄袭的!
欢迎与我交流python,微信:huguo00289