Spark高级操作之json复杂和嵌套数据结构的操作一
一,基本介绍
本文主要讲spark2.0版本以后存在的Sparksql的一些实用的函数,帮助解决复杂嵌套的json数据格式,比如,map和嵌套结构。Spark2.1在spark 的Structured Streaming也可以使用这些功能函数。
下面几个是本文重点要讲的方法。
A),get_json_object()
B),from_json()
C),to_json()
D),explode()
E),selectExpr()
二,准备阶段
首先,创建一个没有任何嵌套的JSon Schema
import org.apache.spark.sql.types._
import org.apache.spark.sql.functions._
val jsonSchema = new StructType().add("battery_level", LongType).add("c02_level", LongType).add("cca3",StringType).add("cn", StringType).add("device_id", LongType).add("device_type", StringType).add("signal", LongType).add("ip", StringType).add("temp", LongType).add("timestamp", TimestampType)
使用上面的schema,我在这里创建一个Dataframe,使用的是scala 的case class,同时会产生一些json格式的数据。当然,生产中这些数据也可以来自于kafka。这个case class总共有两个字段:整型(作为device id)和一个字符串(json的数据结构,代表设备的事件)
// define a case class
case class DeviceData (id: Int, device: String)
// create some sample data
val eventsDS = Seq (
(0, """{"device_id": 0, "device_type": "sensor-ipad", "ip": "68.161.225.1", "cca3": "USA", "cn": "United States", "temp": 25, "signal": 23, "battery_level": 8, "c02_level": 917, "timestamp" :1475600496 }"""),
(1, """{"device_id": 1, "device_type": "sensor-igauge", "ip": "213.161.254.1", "cca3": "NOR", "cn": "Norway", "temp": 30, "signal": 18, "battery_level": 6, "c02_level": 1413, "timestamp" :1475600498 }"""),
(2, """{"device_id": 2, "device_type": "sensor-ipad", "ip": "88.36.5.1", "cca3": "ITA", "cn": "Italy", "temp": 18, "signal": 25, "battery_level": 5, "c02_level": 1372, "timestamp" :1475600500 }"""),
(3, """{"device_id": 3, "device_type": "sensor-inest", "ip": "66.39.173.154", "cca3": "USA", "cn": "United States", "temp": 47, "signal": 12, "battery_level": 1, "c02_level": 1447, "timestamp" :1475600502 }"""),
(4, """{"device_id": 4, "device_type": "sensor-ipad", "ip": "203.82.41.9", "cca3": "PHL", "cn": "Philippines", "temp": 29, "signal": 11, "battery_level": 0, "c02_level": 983, "timestamp" :1475600504 }"""),
(5, """{"device_id": 5, "device_type": "sensor-istick", "ip": "204.116.105.67", "cca3": "USA", "cn": "United States", "temp": 50, "signal": 16, "battery_level": 8, "c02_level": 1574, "timestamp" :1475600506 }"""),
(6, """{"device_id": 6, "device_type": "sensor-ipad", "ip": "220.173.179.1", "cca3": "CHN", "cn": "China", "temp": 21, "signal": 18, "battery_level": 9, "c02_level": 1249, "timestamp" :1475600508 }"""),
(7, """{"device_id": 7, "device_type": "sensor-ipad", "ip": "118.23.68.227", "cca3": "JPN", "cn": "Japan", "temp": 27, "signal": 15, "battery_level": 0, "c02_level": 1531, "timestamp" :1475600512 }"""),
(8 ,""" {"device_id": 8, "device_type": "sensor-inest", "ip": "208.109.163.218", "cca3": "USA", "cn": "United States", "temp": 40, "signal": 16, "battery_level": 9, "c02_level": 1208, "timestamp" :1475600514 }"""),
(9,"""{"device_id": 9, "device_type": "sensor-ipad", "ip": "88.213.191.34", "cca3": "ITA", "cn": "Italy", "temp": 19, "signal": 11, "battery_level": 0, "c02_level": 1171, "timestamp" :1475600516 }"""),
(10,"""{"device_id": 10, "device_type": "sensor-igauge", "ip": "68.28.91.22", "cca3": "USA", "cn": "United States", "temp": 32, "signal": 26, "battery_level": 7, "c02_level": 886, "timestamp" :1475600518 }"""),
(11,"""{"device_id": 11, "device_type": "sensor-ipad", "ip": "59.144.114.250", "cca3": "IND", "cn": "India", "temp": 46, "signal": 25, "battery_level": 4, "c02_level": 863, "timestamp" :1475600520 }"""),
(12, """{"device_id": 12, "device_type": "sensor-igauge", "ip": "193.156.90.200", "cca3": "NOR", "cn": "Norway", "temp": 18, "signal": 26, "battery_level": 8, "c02_level": 1220, "timestamp" :1475600522 }"""),
(13, """{"device_id": 13, "device_type": "sensor-ipad", "ip": "67.185.72.1", "cca3": "USA", "cn": "United States", "temp": 34, "signal": 20, "battery_level": 8, "c02_level": 1504, "timestamp" :1475600524 }"""),
(14, """{"device_id": 14, "device_type": "sensor-inest", "ip": "68.85.85.106", "cca3": "USA", "cn": "United States", "temp": 39, "signal": 17, "battery_level": 8, "c02_level": 831, "timestamp" :1475600526 }"""),
(15, """{"device_id": 15, "device_type": "sensor-ipad", "ip": "161.188.212.254", "cca3": "USA", "cn": "United States", "temp": 27, "signal": 26, "battery_level": 5, "c02_level": 1378, "timestamp" :1475600528 }"""),
(16, """{"device_id": 16, "device_type": "sensor-igauge", "ip": "221.3.128.242", "cca3": "CHN", "cn": "China", "temp": 10, "signal": 24, "battery_level": 6, "c02_level": 1423, "timestamp" :1475600530 }"""),
(17, """{"device_id": 17, "device_type": "sensor-ipad", "ip": "64.124.180.215", "cca3": "USA", "cn": "United States", "temp": 38, "signal": 17, "battery_level": 9, "c02_level": 1304, "timestamp" :1475600532 }"""),
(18, """{"device_id": 18, "device_type": "sensor-igauge", "ip": "66.153.162.66", "cca3": "USA", "cn": "United States", "temp": 26, "signal": 10, "battery_level": 0, "c02_level": 902, "timestamp" :1475600534 }"""),
(19, """{"device_id": 19, "device_type": "sensor-ipad", "ip": "193.200.142.254", "cca3": "AUT", "cn": "Austria", "temp": 32, "signal": 27, "battery_level": 5, "c02_level": 1282, "timestamp" :1475600536 }""")).toDF("id", "device").as[DeviceData]
三,如何使用get_json_object()
该方法从spark1.6开始就有了,从一个json 字符串中根据指定的json 路径抽取一个json 对象。从上面的dataset中取出部分数据,然后抽取部分字段组装成新的json 对象。比如,我们仅仅抽取:id,devicetype,ip,CCA3 code.
val eventsFromJSONDF = Seq (
(0, """{"device_id": 0, "device_type": "sensor-ipad", "ip": "68.161.225.1", "cca3": "USA", "cn": "United States", "temp": 25, "signal": 23, "battery_level": 8, "c02_level": 917, "timestamp" :1475600496 }"""),
(1, """{"device_id": 1, "device_type": "sensor-igauge", "ip": "213.161.254.1", "cca3": "NOR", "cn": "Norway", "temp": 30, "signal": 18, "battery_level": 6, "c02_level": 1413, "timestamp" :1475600498 }"""),
(2, """{"device_id": 2, "device_type": "sensor-ipad", "ip": "88.36.5.1", "cca3": "ITA", "cn": "Italy", "temp": 18, "signal": 25, "battery_level": 5, "c02_level": 1372, "timestamp" :1475600500 }"""),
(3, """{"device_id": 3, "device_type": "sensor-inest", "ip": "66.39.173.154", "cca3": "USA", "cn": "United States", "temp": 47, "signal": 12, "battery_level": 1, "c02_level": 1447, "timestamp" :1475600502 }"""),
(4, """{"device_id": 4, "device_type": "sensor-ipad", "ip": "203.82.41.9", "cca3": "PHL", "cn": "Philippines", "temp": 29, "signal": 11, "battery_level": 0, "c02_level": 983, "timestamp" :1475600504 }"""),
(5, """{"device_id": 5, "device_type": "sensor-istick", "ip": "204.116.105.67", "cca3": "USA", "cn": "United States", "temp": 50, "signal": 16, "battery_level": 8, "c02_level": 1574, "timestamp" :1475600506 }"""),
(6, """{"device_id": 6, "device_type": "sensor-ipad", "ip": "220.173.179.1", "cca3": "CHN", "cn": "China", "temp": 21, "signal": 18, "battery_level": 9, "c02_level": 1249, "timestamp" :1475600508 }"""),
(7, """{"device_id": 7, "device_type": "sensor-ipad", "ip": "118.23.68.227", "cca3": "JPN", "cn": "Japan", "temp": 27, "signal": 15, "battery_level": 0, "c02_level": 1531, "timestamp" :1475600512 }"""),
(8 ,""" {"device_id": 8, "device_type": "sensor-inest", "ip": "208.109.163.218", "cca3": "USA", "cn": "United States", "temp": 40, "signal": 16, "battery_level": 9, "c02_level": 1208, "timestamp" :1475600514 }"""),
(9,"""{"device_id": 9, "device_type": "sensor-ipad", "ip": "88.213.191.34", "cca3": "ITA", "cn": "Italy", "temp": 19, "signal": 11, "battery_level": 0, "c02_level": 1171, "timestamp" :1475600516 }""")).toDF("id", "json")
测试及输出
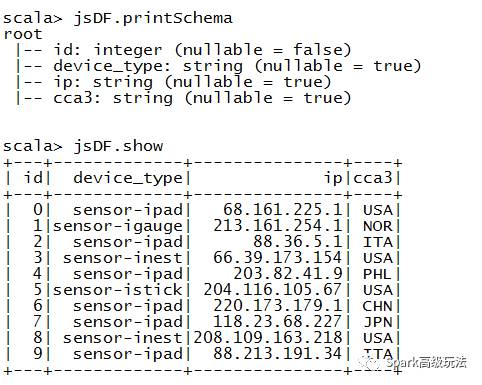
val jsDF = eventsFromJSONDF.select($"id", get_json_object($"json", "$.device_type").alias("device_type"),get_json_object($"json", "$.ip").alias("ip"),get_json_object($"json", "$.cca3").alias("cca3"))
jsDF.printSchema
jsDF.show
四,如何使用from_json()
与get_json_object不同的是该方法,使用schema去抽取单独列。在dataset的api select中使用from_json()方法,我可以从一个json 字符串中按照指定的schema格式抽取出来作为DataFrame的列。还有,我们也可以将所有在json中的属性和值当做一个devices的实体。我们不仅可以使用device.arrtibute去获取特定值,也可以使用*通配符。
下面的例子,主要实现如下功能:
A),使用上述schema从json字符串中抽取属性和值,并将它们视为devices的独立列。
B),select所有列
C),使用.,获取部分列。
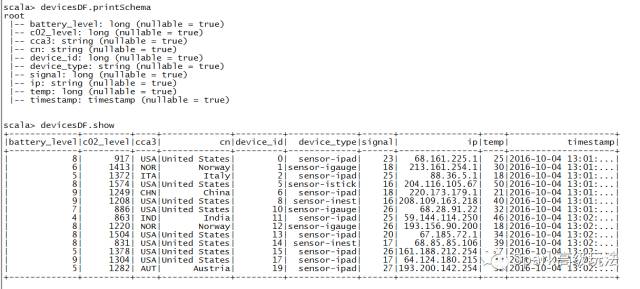
val devicesDF = eventsDS.select(from_json($"device", jsonSchema) as "devices").select($"devices.*").filter($"devices.temp" > 10 and $"devices.signal" > 15)
五,如何使用to_json()
下面使用to_json()将获取的数据转化为json格式。将结果重新写入kafka或者保存partquet文件。
val stringJsonDF = eventsDS.select(to_json(struct($"*"))).toDF("devices")
stringJsonDF.show

保存数据到kafka
stringJsonDF.write.format("kafka").option("kafka.bootstrap.servers", "localhost:9092").option("topic", "iot-devices").save()
注意依赖
groupId = org.apache.spark
artifactId = spark-sql-kafka-0-10_2.11
version = 2.1.0
六,如何使用selectExpr()
将列转化为一个JSON对象的另一种方式是使用selectExpr()功能函数。例如我们可以将device列转化为一个JSON对象。
val stringsDF = eventsDS.selectExpr("CAST(id AS INT)", "CAST(device AS STRING)")
stringsDF.show

SelectExpr()方法的另一个用法,就是使用表达式作为参数,将它们转化为指定的列。如下:
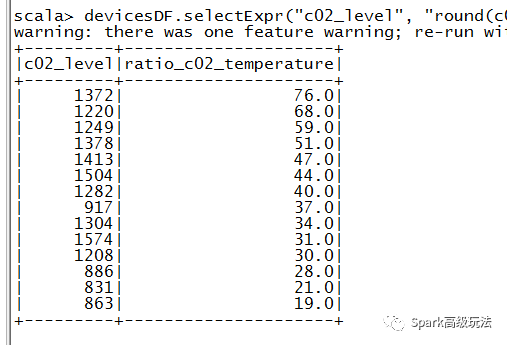
devicesDF.selectExpr("c02_level"
, "round(c02_level/temp) as ratio_c02_temperature")
.orderBy($"ratio_c02_temperature" desc).show
使用Sparksql的slq语句是很好写的
首先注册成临时表,然后写sql
devicesDF.createOrReplaceTempView("devicesDFT")
spark.sql("select c02_level,round(c02_level/temp) as ratio_c02_temperature from devicesDFT order by ratio_c02_temperature desc").show
七,验证
为了验证我们的DataFrame转化为json String是成功的我们将结果写入本地磁盘。
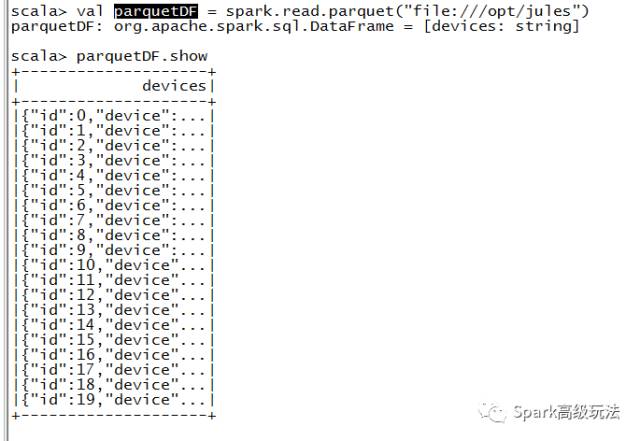
stringJsonDF.write.mode("overwrite").format("parquet").save("file:///opt/jules")
![]()
读入
val parquetDF = spark.read.parquet("file:///opt/jules")
八,总结
本文主要讲 get_json_object(), from_json(), to_json(), selectExpr(), and explode()基本介绍使用,下次文章讲解更加复杂的嵌套格式的使用,欢迎关注浪尖公众号。
