Eclipse搭建Hadoop开发环境二三事
前言
这是关于Hadoop的系列文章。
Hadoop基本概念指南
Eclipse搭建Hadoop开发环境二三事
IntelliJ IDEA搭建Hadoop开发环境
Hadoop文件存储系统-HDFS详解以及java编程实现
Eclipse搭建开发环境
当我们完成了基本的概念学习,我们就应该着手写代码了。毕竟时间才是真理啊!好了,今天我们就来聊聊如何搭建Hadoop的开发环境。
材料准备
毕竟如果想要烹饪出一道美食的话第一就是要选好食材,而我们想要搭建好开发环境也需要提前准备好需要的软件。需要的软件清单如下:
Eclipse
Hadoop的tar包
Eclipse的Hadoop插件
开始配置
好了废话不多说我们开始准备吧!首先是下载Hadoop的tar包下载地址如下:
Hadoop tar 包下载地址
看到tar包不要怕,他其实就和我们普通的压缩包并没有什么不一样的地方。我们需要下载它然后解压,当然然后我们在linux上部署的话,我们只需要wget就可以了。ok,把他解压到一个目录下面去。我们在此处选择的是2.6.2版本。
然后我们需要做的就是配置环境变量,因为你要跑的话,需要配置好相应的环境变量。如下图所示:
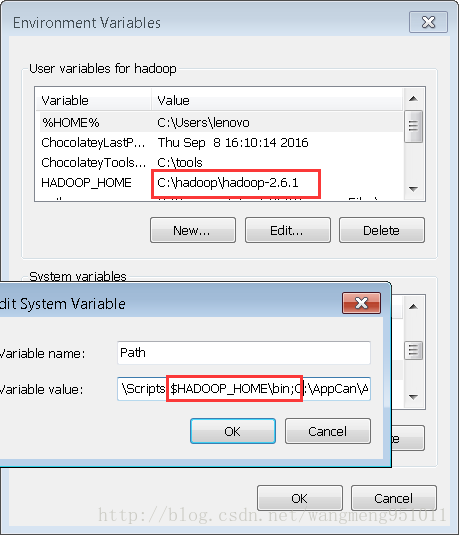
配置完环境变量之后我们接下来要做的事情是下载winutils.exe的相关文件,有人会问这个东西干嘛用的?实际上,windows缺少这样的东西,官方出的类似于插件的东西。我们可以在网上直接搜索,当然,去github上搜索也是一个不错的选择啦!果然能够搜到,啊哈,我们下载之。对了,需要下载的是hadoop.dll以及winutils.exe。ok,下载完毕,我们需要将她放在我们解压的hadoop的根目录的bin目录下,并将hadoop.dll放到我们的C:\Windows\System32目录下去。
接下来我们要做的就是安装Eclipse的插件了,啊哈,这个插件还是非常好用的。插件安装好之后我们就可以直接在我们亲爱的Eclipse的视图上看到Hadoop的标示了。当然我们现在已经可以新建Hadoop的项目了。就问你怕不怕!当然在这之前我们首先要配置下Hadoop的安装目录。配置方式如下:
windows->Preferences->Hadoop installation directory

各位大佬,到了这里我们就可以新建Hadoop的项目来试着跑一跑我们亲爱的Hadoop项目的基本例子Wordcount。新建项目的步骤我就不啰嗦了,因为,因为这个和我们新建一个java项目并没有什么区别!
好了,我们来看看建好后的项目长啥样。

我们可以看到这与我们的基本的java项目别无二致,就是依赖的jar有点多,你知道的,但是我们要知道我们最好还是要用maven将这些jar管理起来,否则真的是及其的难移植。考虑到我们是刚接触Hadoop,现在只要将例子2跑起来就是ok的,我们就不在赘述。
好了,现在我们要做的是找到Hadoop的基本例子,我已经准备好给大家了!代码如下:
package org.apache.hadoop.examples;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.*;
import org.apache.hadoop.util.GenericOptionsParser;
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
/**
* wordcount 的简单例子
*
* @author hadoop
*/
public class WordCount {
public static class Map extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, OutputCollector output, Reporter reporter)
throws IOException {
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
String s = tokenizer.nextToken();
word.set(s);
output.collect(word, one);
}
}
}
public static class Reduce extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterator values, OutputCollector output,
Reporter reporter) throws IOException {
int sum = 0;
while (values.hasNext()) {
sum += values.next().get();
}
output.collect(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws Exception {
JobConf conf = new JobConf(WordCount.class);
String[] path = new String[2];
/*path[0] = "hdfs://ip:9001/user/hadoop/input/";
path[1] = "hdfs://ip:9001/user/hadoop/output";*/
path[0] = "input/hello.txt";
path[1] = "output";
String[] otherArgs = new GenericOptionsParser(conf, path).getRemainingArgs();
conf.setJobName("worscount");
conf.setUser("hadoop");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(Map.class);
conf.setCombinerClass(Reduce.class);
conf.setReducerClass(Reduce.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(conf, new Path(otherArgs[1]));
JobClient.runJob(conf);
}
} 我们接下来要做的就是去跑一下这个例子获取结果,当然大家也都知道一般教科书上都是让我们从HDFS上获取数据的,但是我们现在并不这样做,考虑到这是入门的教程,你知道的,我们无需引入那种无关的复杂性。好了,现在run as Hadoop。但是需要注意的是output命令一定不能存在,否则就尴尬了。会报错的。最后的结果是这样子的。

好了那我们今天在本地跑Hadoop的基本例子就已经完成了,接下来我们需要做的就是如何在linux上搭建基本的环境。
总结
今天主要讲解如何在本地搭建开发环境并跑一下最基本的Hadoop的简单例子,首先让大家对于Hadoop有一个感性的认识,当然,理性的认识也会随之而来。因为我们看到了现象,总要去追溯其行为的啦!
祝大家新的一天上班愉快!