(四)ElasticSearch内存分配以及优化
ElasticSearch内存分配以及优化
文章目录
- ElasticSearch内存分配以及优化
-
- 1:服务器内存分配
- 2:内存解释
-
- 2.1:Elasticsearch内存分配
-
- 2.1.1:fielddata:顺排索引
- 2.1.2 Node Query Cache
- 2.1.3 Indexing Buffer
- 2.1.4 Shard Request Cache 用于缓存请求结果
- 2.2:Lucene:segment
-
- 2.2.1:lucene文件内容
- 3:内存不够解决:ram.percent 达到100%
-
- 3.1 es高负载带来的影响
- 3.2 查看节点内存负载:get _cat/nodes
-
- 3.2.1:节点负载详解
- 3.2.2:问题原因分析:lucene缓存了过多的索引数据:
- 3.3 问题解决
1:服务器内存分配

内存消耗大户:
1:Elasticsearch
2:Lucene(全文搜索)
2:内存解释
2.1:Elasticsearch内存分配
Elasticsearch默认安装后设置的堆内存是1GB,实际业务肯定不够,需要进行配置,不要超过32G
因为如果堆大小小于 32 GB,JVM 可以利用指针压缩,这可以大大降低内存的使用:每个指针 4 字节而不是 8 字节。如果大于32G 每个指针占用 8字节,并且会占用更多的内存带宽,降低了cpu性能。
每G管理分片数不超过20,即可推理总分片数。
xmx-JVM最大允许分配的堆内存,按需分配
xms-JVM初始分配的堆内存
这是我们的配置
-Xmx10g -Xms10g
2.1.1:fielddata:顺排索引
fielddata就是存储字段以及字段的类型。会消耗大量的JVM内存,几个g是正常的,因此,尽量为JVM设置大的内存,不要为不必要的字段启用fielddata存储。通过format参数控制是否启用字段的fielddata特性,字符类型的分析字段,fielddata的默认值是paged_bytes,这就意味着,默认情况下,字符类型的分析字段启用fielddata存储。一旦禁用fielddata存储,那么字符类型的分析字段将不再支持排序和聚合查询。
** Fielddata 是 延迟 加载也是第二次查询快的原因**。如果你从来没有聚合一个分析字符串,就不会加载 fielddata 到内存中,也就不会使用大量的内存。
如果没有足够的内存保存fielddata时,Elastisearch会不断地从磁盘加载数据到内存,并剔除掉旧的内存数据。剔除操作会造成严重的磁盘I/O,并且引发大量的GC,会严重影响Elastisearch的性能。

1、format属性
fielddata会消耗大量的JVM内存,因此,尽量为JVM设置大的内存,不要为不必要的字段启用fielddata存储。通过format参数控制是否启用字段的fielddata特性,字符类型的分析字段,fielddata的默认值是paged_bytes,这就意味着,默认情况下,字符类型的分析字段启用fielddata存储。一旦禁用fielddata存储,那么字符类型的分析字段将不再支持排序和聚合查询。
2、加载属性(loading)
loading属性控制fielddata加载到内存的时机,可能的值是lazy,eager和eager_global_ordinals,默认值是lazy。
lazy:fielddata只在需要时加载到内存,默认情况下,在第一次搜索时,fielddata被加载到内存中;但是,如果查询一个非常大的索引段(Segment),lazy加载方式会产生较大的时间延迟。
eager:在倒排索引的段可用之前,其数据就被加载到内存,eager加载方式能够减少查询的时间延迟,但是,有些数据可能非常冷,以至于没有请求来查询这些数据,但是冷数据依然被加载到内存中,占用紧缺的内存资源。
eager_global_ordinals:按照global ordinals积极把fielddata加载到内存。
2.1.2 Node Query Cache
(负责缓存filter 查询结果),每个节点有一个,被所有 shard 共享,filter query查询结果要么是 yes 要么是no,不涉及 scores 的计算。
集群中每个节点都要配置,默认为:indices.queries.cache.size:10%
2.1.3 Indexing Buffer
索引缓冲区,用于存储新索引的文档,当其被填满时,缓冲区中的文档被写入磁盘中的 segments 中。节点上所有 shard 共享。
缓冲区默认大小: indices.memory.index_buffer_size: 10%如果缓冲区大小设置了百分百则 indices.memory.min_index_buffer_size 用于这是最小值,默认为 48mb。indices.memory.max_index_buffer_size 用于最大大小,无默认值。
2.1.4 Shard Request Cache 用于缓存请求结果
2.2:Lucene:segment
lucene详解文档
segment详解
2.2.1:lucene文件内容
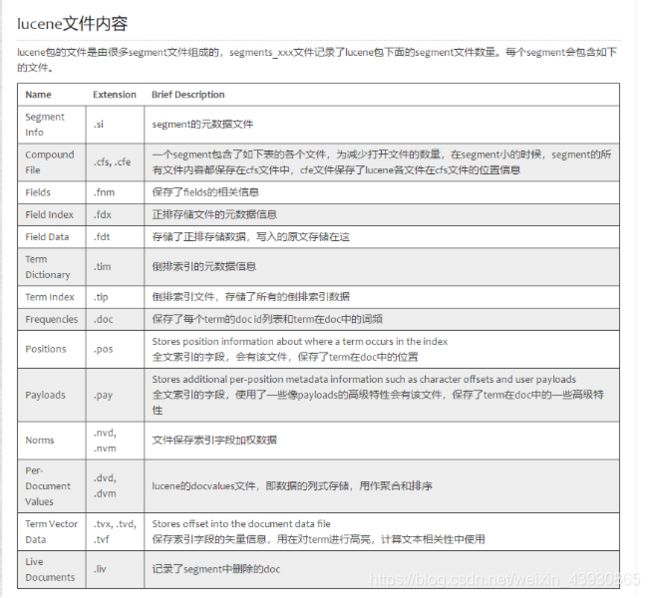
3:内存不够解决:ram.percent 达到100%
3.1 es高负载带来的影响
为什么es内存使用率到达75%会下降?
3.2 查看节点内存负载:get _cat/nodes
发现内存被消耗完毕,此时读写均异常
主节点每30秒会去检查其他节点的状态,如果任何节点的垃圾回收时间超过30秒,则会导致主节点任务该节点脱离集群。
3.2.1:节点负载详解
节点负载详解
get _cat/nodes?h=ip,cpu,hp,rp,fm,sm,qcm,sqti,rc,rm,dt,du&v
curl -s “ip:9200/_cat/nodes?h=ip,hp,rp,rc,rm,fm,sm,sc,qcm,sqti,dt,du&v”
ip:node.ip
cpu:cpu使用率
hp:堆内存使用
rp:ram.percent,总内存使用量百分比,保持在75%以下最好
rc:Used total memory,使用总内存大小
rm:ram.max:总内存大小
fm:fielsdata.sizeMemoey:字段缓存
sm:segment.memory:segment使用的内存
sc:segments.count:segment的数量
qcm:query_cache.memory_size:查询缓存的内存使用
sqti:search.query_time:查询总用时
dt:disk.total:所有磁盘空间
du:disk.used:使用的磁盘空间
3.2.2:问题原因分析:lucene缓存了过多的索引数据:
现在让我们假设您有一个集群,它有三个节点,整体内存压力要高得多。在这个例子中,三个节点中的两个节点在很长一段时间内非常有规律地最大化,一个节点始终徘徊在垃圾收集开始的75%左右。
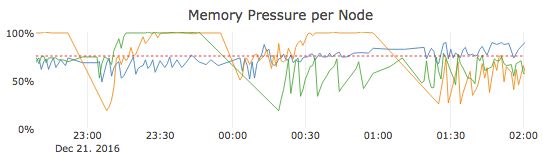
高内存压力从两个方面影响集群性能:当内存压力升至75%及以上时,可用内存会减少,但是您的集群现在还需要花费一些CPU资源来通过垃圾收集回收内存。垃圾收集进行时,这些中央处理器资源不可用于处理用户请求。因此,随着系统资源越来越受限,用户请求的响应时间会增加。如果内存压力持续上升并接近100%,则会使用更的垃圾收集形式,这反过来会极大地影响集群响应时间。
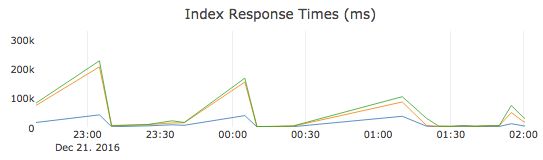 :
:
3.3 问题解决
1:减少集群负载:
先减少或停止入库数据,
分片索引的数量,减少副本数
2:集群扩容
3:分析es架构是否合理