计系2复习(1)数据表示与格式 寄存器与寻址 简单指令
目录
- 数据表示
-
- 整型数据
-
- 无符号整型
- 有符号整型
- 浮点型数据
-
- 规格化的浮点数
- 非规格化的浮点数
- 特殊值
- 无符号整数的比较运算
- 字节顺序
- 数据格式
- 寄存器
- 寻址
- 指令
-
- 数据传送指令
- 算数逻辑指令
- 计算有效地址
- 题目
-
- 1
- 2
- 3
- 4
- 5
数据表示
这一章节主要介绍计算机如何表示各种类型的数据,及其在内存中的排布规律。计系1好像也讲过
整型数据
整型数据分为无符号整型和有符号整型,先来看比较简单的无符号整型。
无符号整型
使用二进制表示。懂的都懂
有符号整型
有符号整型使用补码编码。其中最高位表示符号位。补码和数值有如下转换关系:
- 正数的补码是其绝对值数字的二进制表示
- 负数的补码是其绝对值数字的二进制表示按位取反(包括符号位)后再+1
下面给出简单的补码与数值关系:
| 补码的二进制表示 | 对应十进制数值 |
|---|---|
| 100 | -4 |
| 101 | -3 |
| 110 | -2 |
| 111 | -1 |
| 000 | 0 |
| 001 | 1 |
| 010 | 2 |
| 011 | 3 |
浮点型数据
浮点型数据使用科学计数法,即通过`符号位–指数位–阶尾数的组合,表示不同范围。

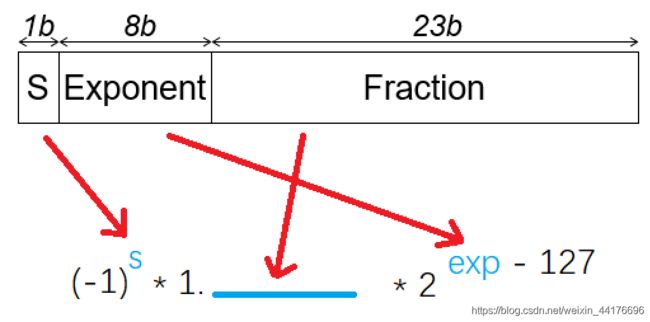
规格化的浮点数
当:exp字段不全为0或1(1<=exp<=254)时,称之为规格化的浮点数。
规格化的浮点数有如下的计算方法:
非规格化的浮点数
当:exp字段全为0时。有如下的计算方法,其中E = 1-bias = 1-127 = -126:
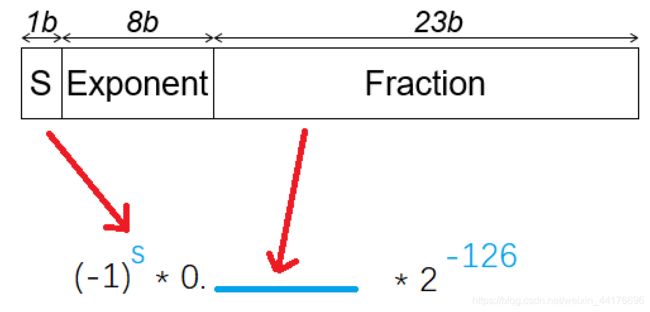
注:非规格化的浮点数提供了表示0的方法。
特殊值
当:exp字段全为1且frac字段全为0,表示无穷。
无符号整数的比较运算
在 C 语言中,如果一个运算数是有符号而另一个是无符号的话,那么C语言会隐式地将有符号数强转为无符号数。下面列出几个与直觉相反的运算结果:
| 表达式 | 强转后实际的表达式 | 结果 |
|---|---|---|
| -1 < 0U | 4294967295 < 0 | false |
| 2147483647U > -2147483647-1 | 2147483647 > 2147483648 | false |
| 2147483647 > (int) 2147483648U | 2147483647 > -1 | true |
字节顺序
字节顺序描述了一个二进制数值在内存中的排布规律,常见的字节顺序有大端法和小端法。
大端法:符合常人的理解,将最高有效字节存储在前面,即按照地址递增顺序存储字节。比如存储十六进制数0x12345678
| 地址 | 0x0100 | 0x0101 | 0x0102 | 0x0103 |
|---|---|---|---|---|
| 值 | 12 | 34 | 56 | 78 |
小端法:方便机器存取,将最低有效字节存储在前面,即按照地址递减顺序存储字节:
| 地址 | 0x0100 | 0x0101 | 0x0102 | 0x0103 |
|---|---|---|---|---|
| 值 | 78 | 56 | 34 | 12 |
数据格式
在x86中,汇编指令后面都会跟上一个后缀,比如movq,movl这种,这些后缀表示了操作数的格式。
字:在x86中,一个字被定义为2个字节。
下面给出各个数据类型的数据格式及其汇编后缀,值得注意的是,指针是四字的大小:
| 数据类型 | 称呼 | 汇编指令后缀 | 大小(字节) |
|---|---|---|---|
| char | 字节 | b | 1 |
| short | 字 | w | 2 |
| int | 双字 | l | 4 |
| double | 四字 | q | 8 |
| char* | 四字 | q | 8 |
为什么没有五字的数据格式?说明五字不行
附:

寄存器
在x86的cpu中包含16个寄存器,这些寄存器可以直接且快速的被cpu访问,下面给出所有寄存器的示意,及其常见用法(比如%rax做返回值):

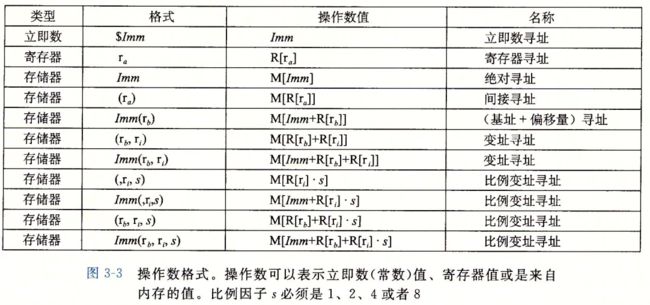
寻址
通过一定的方式获取内存或者寄存器中数值的方法,这个过程称为寻址。在x86中,有如下的寻址方法,他们对应的输出分别是:
要注意 $imm 和 imm 的区别,不带$的是访问内存,而带$的是直接取立即数。
| 汇编代码 | 输出(寻址结果) |
|---|---|
| $imm | imm |
| r | R[r] |
| imm | M[imm] |
| ( r ) | M[R[r]] |
| imm( r ) | M[imm+R[r]] |
| (r1, r2) | M[R[r1] + R[r2]] |
| imm(r1, r2) | M[imm + R[r1] + R[r2]] |
| (, r, s) | M[R[r] * s] |
| imm(, r, s) | M[imm + R[r] * s] |
| (r1, r2, s) | M[R[r1] + R[r2]*s] |
| imm(r1, r2, s) | M[imm + R[r1] + R[r2]*s] |
其中 R[x] 表示取 x寄存器 的值,而 M[x] 表示取内存地址 x 处的值。
附:
指令
这一部分介绍x86中常见的汇编指令及其细节
数据传送指令
数据传送指令是使用最频繁的指令没有之一。
使用 mov 指令可以完成数据的传送。格式为 mov 源 目。将源操作数复制到目的地址。
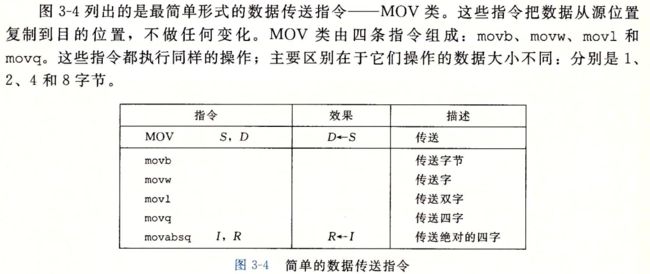
源操作数可以是一个立即数,也可以是通过寻址得到的内存空间中的数字。
而目的地址可以是寄存器,也可以是通过寻址得到的内存空间。
此外,mov指令不能直接完成内存到内存的数据搬移。
| 汇编代码 | 过程描述 | 结果 |
|---|---|---|
| movl $0x1234 %eax | 立即数->寄存器 | R[eax] = 0x1234 |
| movw %bp %sp | 寄存器->寄存器 | R[sp] = R[bp] |
| movb (%rdi, %rcx), %al | 内存->寄存器 | R[al] = M[R[rdi] + R[rcx]] |
| movb $-114, (%rsp) | 立即数->内存 | M[rsp] = -114 |
| movq %rax, -7(%rsp) | 寄存器->内存 | M[rsp + -7] = R[rax] |
除此之外,还有不对等大小的数据转移指令:

算数逻辑指令
下面列出简单的算术与逻辑指令

其中算数移位(SA_)是填上符号位,逻辑移位(SH_)是填0
计算有效地址
LEA指令是一个很神奇的指令,它不访问内存,却只计算有效地址(即寻址时,去掉最外面的M[ ])。lea的格式和mov指令完全相同。
比如
leaq 114(,%rdx, 2), %rax
这句话的意思是将 2*%rdx + 114 赋值给 %rax,而并不访问内存 M[2*%rdx + 114],所以lea指令常常被用来做一些简单的计算操作。
题目
一些习题。。
1
如果int i = 0x86231132,&i=0x400320,请问地址0x400322 地址上的那个字节存储的数值是?
区分大小端表示,其中0x400322是第三字节的数据:
大端表示:则有 86 23 11 32
小端表示:则有 32 11 23 86
2
一个float类型数的十六进制表示为0xC0A00000,则其十进制表示是什么?
写出二进制形式为:1100 0000 1010 0000 0000 0000 0000 0000,那么有:
符号位s:1
指数为exp:10000001 = 129
尾数frac:01000000000000000000000
所以数值为:
(-1)^1 * (129 - 127) * 1. 01000000000000000000000 = - 101 = -5
3
下列那一条指令是正确的:
A: movb $0xE, (%ebx)
B: movl %rax, (%rsp)
C: movq %rax, %rdx
D: movw (%rax), 4(%rsp)
A应该使用movl,因为ebx是二字长度。
B应该使用movq,因为rsp是四字长度。
D应该使用movq,原因同上。
答案:C
4
下列指令中不会改变条件码寄存器内容的是
A: CMP
B: TEST
C: ADD
D: LEA
答案:D,懂的都懂
5
1) movl (%eax, %eax, 4), %eax
2) leal (%eax, %eax, 4), %eax
上面指令中的那一条会产生如下结果: %eax = 5 * %eax?
A: 1和2都不会
B: 1
C: 2
D: 1和2都会
答案:C
movl (%eax, %eax, 4), %eax 等价于 eax = M[eax + eax*4]
leal (%eax, %eax, 4), %eax 等价于 eax = eax + eax*4