Sentinel: 分布式系统的流量防卫兵--简介及使用
1. Sentinel 是什么?
随着微服务的流行,服务和服务之间的稳定性变得越来越重要。Sentinel 以流量为切入点,从流量控制、熔断降级、系统负载保护等多个维度保护服务的稳定性。
Sentinel 具有以下特征:
- 丰富的应用场景:Sentinel 承接了阿里巴巴近 10 年的双十一大促流量的核心场景,例如秒杀(即突发流量控制在系统容量可以承受的范围)、消息削峰填谷、集群流量控制、实时熔断下游不可用应用等。
完备的实时监控:Sentinel 同时提供实时的监控功能。您可以在控制台中看到接入应用的单台机器秒级数据,甚至 500 台以下规模的集群的汇总运行情况。 - 广泛的开源生态:Sentinel 提供开箱即用的与其它开源框架/库的整合模块,例如与 Spring Cloud、Dubbo、gRPC 的整合。您只需要引入相应的依赖并进行简单的配置即可快速地接入 Sentinel。
- 完善的 SPI 扩展点:Sentinel 提供简单易用、完善的 SPI 扩展接口。您可以通过实现扩展接口来快速地定制逻辑。例如定制规则管理、适配动态数据源等。
Sentinel 的主要特性:

Sentinel 的开源生态:

Sentinel 分为两个部分:
- 核心库(Java 客户端)不依赖任何框架/库,能够运行于所有 Java 运行时环境,同时对 Dubbo / Spring Cloud 等框架也有较好的支持。
- 控制台(Dashboard)基于 Spring Boot 开发,打包后可以直接运行,不需要额外的 Tomcat 等应用容器。
2. Sentinel 控制台
-
下载地址:https://github.com/alibaba/Sentinel/releases 我们使用v1.8.0
-
启动:java -jar sentinel-dashboard-1.8.0.jar &
-
登录控制台:http://localhost:8080 用户名/密码:sentinel/sentinel, 也可以用下面的命定启动指定端口
java -Dserver.port=8080 -Dcsp.sentinel.dashboard.server=localhost:8080 -Dproject.name=sentinel-dashboard -jar sentinel-dashboard-1.8.0.jar

3. 微服务引入Sentinel
- pom.xml引入依赖
<!--sentinel 核心环境 依赖-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>
- application.yml修改
server:
port: 8098
spring:
application:
name: lagou-service-autodeliver
cloud:
nacos:
discovery:
server-addr: 127.0.0.1:8848,127.0.0.1:8849,127.0.0.1:8850
sentinel:
transport:
dashboard: 127.0.0.1:8080 # sentinel dashboard/console 地址
port: 8719 # sentinel会在该端口启动http server,那么这样的话,控制台定义的一些限流等规则才能发送传递过来,
#如果8719端口被占用,那么会依次+1
management:
endpoints:
web:
exposure:
include: "*"
# 暴露健康接口的细节
endpoint:
health:
show-details: always
#针对的被调用方微服务名称,不加就是全局生效
lagou-service-resume:
ribbon:
#请求连接超时时间
ConnectTimeout: 2000
#请求处理超时时间
##########################################Feign超时时长设置
ReadTimeout: 3000
#对所有操作都进行重试
OkToRetryOnAllOperations: true
####根据如上配置,当访问到故障请求的时候,它会再尝试访问一次当前实例(次数由MaxAutoRetries配置),
####如果不行,就换一个实例进行访问,如果还不行,再换一次实例访问(更换次数由MaxAutoRetriesNextServer配置),
####如果依然不行,返回失败信息。
MaxAutoRetries: 0 #对当前选中实例重试次数,不包括第一次调用
MaxAutoRetriesNextServer: 0 #切换实例的重试次数
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RoundRobinRule #负载策略调整
logging:
level:
# Feign日志只会对日志级别为debug的做出响应
com.lagou.edu.controller.service.ResumeServiceFeignClient: debug
- 上述配置之后,启动自动投递微服务,使用 Sentinel 监控自动投递微服务 此时我们发现控制台没有任何变化,因为懒加载,我们只需要发起一次请求触发即可

4. Sentinel 关键概念
| 名称 | 描述 |
|---|---|
| 资源 | 它可以是 Java 应用程序中的任何内容,例如,由应用程序提供的服务,或由应用程序调用 的其它应用提供的服务,甚至可以是一段代码。我们请求的API接口就是资源 |
| 规则 | 围绕资源的实时状态设定的规则,可以包括流量控制规则、熔断降级规则以及系统保护规 则。所有规则可以动态实时调整。 |
5. Sentinel 流量规则模块
系统并发能力有限,比如系统A的QPS支持1个,如果太多请求过来,那么A就应该进行流量控制了,比 如其他请求直接拒绝

参数解析:
- 资源名:默认请求路径
- 针对来源:Sentinel可以针对调用者进行限流,填写微服务名称,默认default(不区分来源)
- 阈值类型/单机阈值
- QPS:(每秒钟请求数量)当调用该资源的QPS达到阈值时进行限流
- 线程数:当调用该资源的线程数达到阈值的时候进行限流(线程处理请求的时候,如果说业务逻辑执行 时间很⻓,流量洪峰来临时,会耗费很多线程资源,这些线程资源会堆积,最终可能造成服务不可用, 进一步上游服务不可用,最终可能服务雪崩)
- 是否集群:是否集群限流
- 流控模式:
- 直接:资源调用达到限流条件时,直接限流
- 关联:关联的资源调用达到阈值时候限流自己
- 链路:只记录指定链路上的流量
- 流控效果:
- 快速失败:直接失败,抛出异常
- Warm Up:根据冷加载因子(默认3)的值,从阈值/冷加载因子,经过预热时⻓,才达到设置的QPS阈值
- 排队等待:匀速排队,让请求匀速通过,阈值类型必须设置为QPS,否则无效
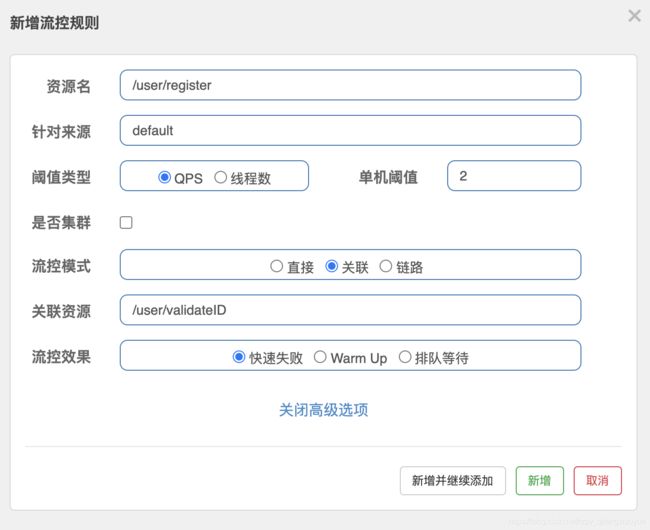
- 流控模式之关联限流
关联的资源调用达到阈值时候限流自己,比如用户注册接口,需要调用身份证校验接口(往往身份证校 验接口),如果身份证校验接口请求达到阈值,使用关联,可以对用户注册接口进行限流。
@RestController
@RequestMapping("/user")
public class UserController {
/**
* 用户注册接口
*
* @return
*/
@GetMapping("/register")
public String register() {
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy/mm/dd HH:MM:ss");
System.out.println(simpleDateFormat.format(new Date()) + " Register success!");
return "Register success!";
}
/**
* 验证注册身份证接口(需要调用公安户籍资源)
*
* @return
*/
@GetMapping("/validateID")
public String findResumeOpenState() {
System.out.println("validateID");
return "ValidateID success!";
}
}
模拟密集式请求/user/validateID验证接口,我们会发现/user/register接口也被限流了
- 流控模式之链路限流
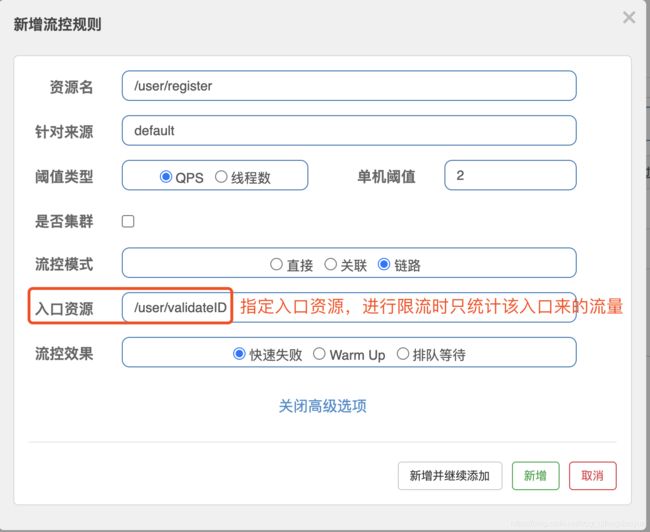
链路指的是请求链路(调用链)链路模式下会控制该资源所在的调用链路入口的流量。需要在规则中配置入口资源,即该调用链路入口 的上下文名称。
NodeSelectorSlot 中记录了资源之间的调用链路,这些资源通过调用关系,相互之间构成一棵调用树。这棵树的根节点是一个名字为 machine-root 的虚拟节点,调用链的入口都是这个虚节点的子节点。
一棵典型的调用树如下图所示:
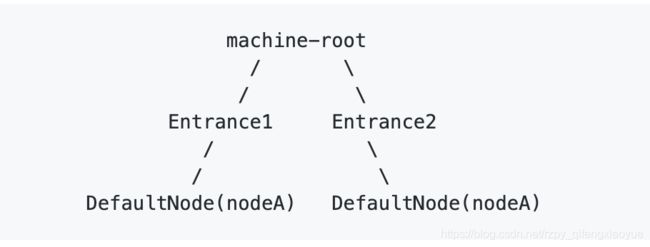
上图中来自入口 Entrance1 和 Entrance2 的请求都调用到了资源 NodeA,Sentinel 允许只根据某个入口的统计信息对资源限流。比如我们可以设置 strategy 为 RuleConstant.STRATEGY_CHAIN,同时设置 refResource 为 Entrance1 来表示只有从入口 Entrance1 的调用才会记录到 NodeA 的限流统计当中,而不关心经 Entrance2 到来的调用。
-
流控效果之快速失败

快速失败:直接拒绝(RuleConstant.CONTROL_BEHAVIOR_DEFAULT)方式是默认的流量控制方式,当QPS超过任意规则的阈值后,新的请求就会被立即拒绝,拒绝方式为抛出FlowException。这种方式适用于对系统处理能力确切已知的情况下,比如通过压测确定了系统的准确水位时 -
流控效果之Warm up
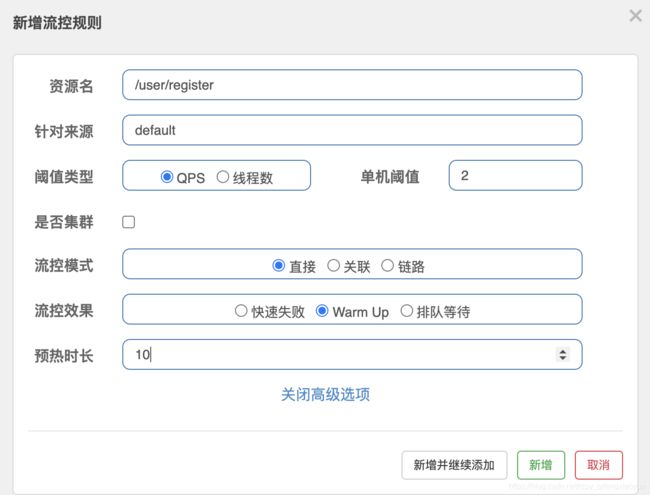
Warm Up(RuleConstant.CONTROL_BEHAVIOR_WARM_UP)方式,即预热/冷启动方式。当系统长期处于低水位的情况下,当流量突然增加时,直接把系统拉升到高水位可能瞬间把系统压垮。通过"冷启动",让通过的流量缓慢增加,在一定时间内逐渐增加到阈值上限,给冷系统一个预热的时间,避免冷系统被压垮。
Warm Up 模式默认会从设置的 QPS 阈值的 1/3 开始慢慢往上增加至 QPS 设置值。
- 流控效果之匀速排队

匀速排队(RuleConstant.CONTROL_BEHAVIOR_RATE_LIMITER)方式会严格控制请求通过的间隔时间,也即是让请求以均匀的速度通过,对应的是漏桶算法。
这种方式主要用于处理间隔性突发的流量,例如消息队列。想象一下这样的场景,在某一秒有大量的请求到来,而接下来的几秒则处于空闲状态,我们希望系统能够在接下来的空闲期间逐渐处理这些请求,而不是在第一秒直接拒绝多余的请求。
例如,QPS 配置为 5,则代表请求每 200 ms 才能通过一个,多出的请求将排队等待通过。超时时间代 表最大排队时间,超出最大排队时间的请求将会直接被拒绝。
注意:匀速排队模式暂时不支持 QPS > 1000 的场景。
6. Sentinel 降级规则模块
Sentinel 提供以下几种降级熔断策略:
- 慢调用比例 (SLOW_REQUEST_RATIO):
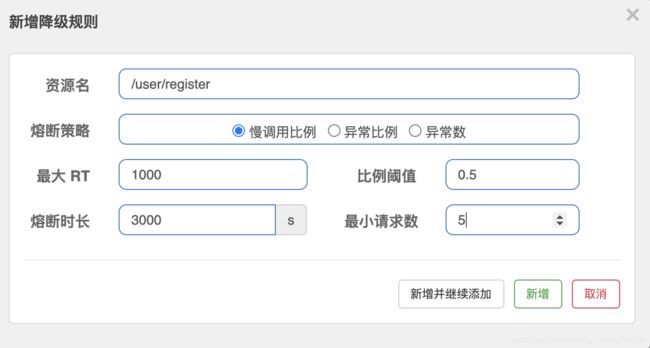
选择以慢调用比例作为阈值,需要设置允许的慢调用 RT(即最大的响应时间),请求的响应时间大于该值则统计为慢调用。当单位统计时长(statIntervalMs)内请求数目大于设置的最小请求数目,并且慢调用的比例大于阈值,则接下来的熔断时长内请求会自动被熔断。经过熔断时长后熔断器会进入探测恢复状态(HALF-OPEN 状态),若接下来的一个请求响应时间小于设置的慢调用 RT 则结束熔断,若大于设置的慢调用 RT 则会再次被熔断。
举例:当 1s 内持续进入 >=5 个请求,平均响应时间超过阈值(以 ms 为单位),那么在接下的时间窗口 (以 s 为单位)之内,对这个方法的调用都会自动地熔断(抛出 DegradeException)。注意 Sentinel 默认统计的 RT 上限是 4900 ms,超出此阈值的都会算作 4900 ms,若需要变更此上限 可以通过启动配置项 -Dcsp.sentinel.statistic.max.rt=xxx 来配置。

- 异常比例 (ERROR_RATIO):

当单位统计时长(statIntervalMs)内请求数目大于设置的最小请求数目,并且异常的比例大于阈值,则接下来的熔断时长内请求会自动被熔断。经过熔断时长后熔断器会进入探测恢复状态(HALF-OPEN 状态),若接下来的一个请求成功完成(没有错误)则结束熔断,否则会再次被熔断。异常比率的阈值范围是 [0.0, 1.0],代表 0% - 100%。

- 异常数 (ERROR_COUNT):

当单位统计时长内的异常数目超过阈值之后会自动进行熔断。经过熔断时长后熔断器会进入探测恢复状态(HALF-OPEN 状态),若接下来的一个请求成功完成(没有错误)则结束熔断,否则会再次被熔断。
当资源近 1 分钟的异常数目超过阈值之后会进行熔断。注意由于统计时间窗口是分钟级别的,若 timeWindow 小于 60s,则结束熔断状态后仍可能再进入熔断状态。
时间窗口 >= 60s

- 更多高级应用可参考官方文档
https://github.com/alibaba/Sentinel/wiki/%E4%BB%8B%E7%BB%8D