大型项目技术栈第十讲 日志与性能监控
大型项目技术栈第十讲 日志与性能监控
一、事务管理策略
什么是事务?
事务是逻辑上的一组操作,要么都执行,要么都不执行。
事务最经典也经常被拿出来说例子就是转账了。假如小明要给小红转账1000元,这个转账会涉及到两个关键操作就是:将小明的余额减少1000元,将小红的余额增加1000元。万一在这两个操作之间突然出现错误比如银行系统崩溃,导致小明余额减少而小红的余额没有增加,这样就不对了。事务就是保证这两个关键操作要么都成功,要么都要失败。
事物的四大特性(ACID)介绍一下?
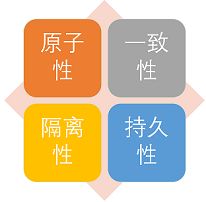
- 原子性: 事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;
- 一致性: 执行事务前后,数据保持一致,多个事务对同一个数据读取的结果是相同的;
- 隔离性: 并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的;
- 持久性: 一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
并发事务带来哪些问题?
在典型的应用程序中,多个事务并发运行,经常会操作相同的数据来完成各自的任务(多个用户对统一数据进行操作)。并发虽然是必须的,但可能会导致以下的问题:
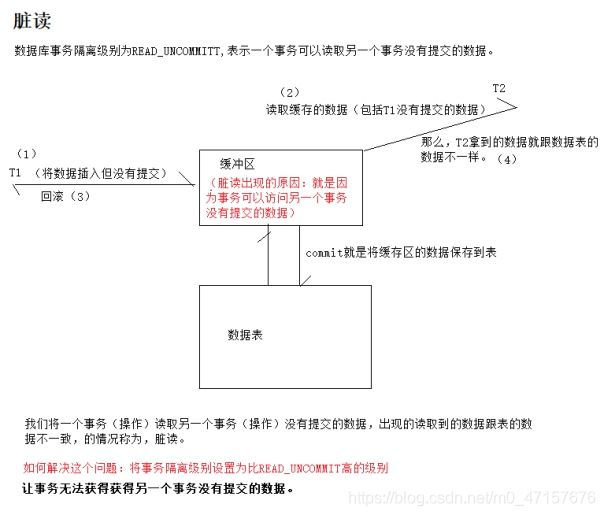
- 脏读(Dirty read): 当一个事务正在访问数据并且对数据进行了修改,而这种修改还没有提交到数据库中,这时另外一个事务也访问了这个数据,然后使用了这个数据。因为这个数据是还没有提交的数据,那么另外一个事务读到的这个数据是“脏数据”,依据“脏数据”所做的操作可能是不正确的。
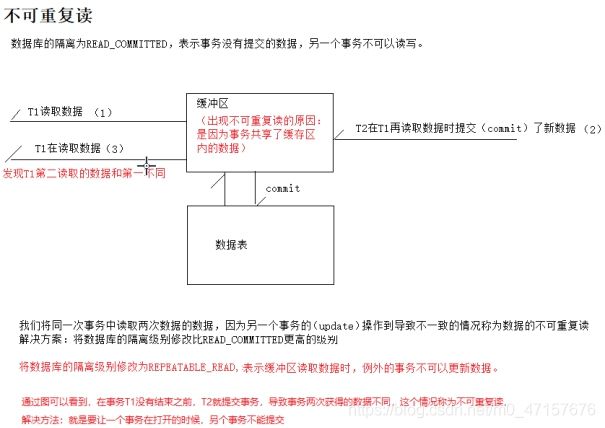
- 不可重复读(Unrepeatableread): 指在一个事务内多次读同一数据。在这个事务还没有结束时,另一个事务也访问该数据。那么,在第一个事务中的两次读数据之间,由于第二个事务的修改导致第一个事务两次读取的数据可能不太一样。这就发生了在一个事务内两次读到的数据是不一样的情况,因此称为不可重复读。
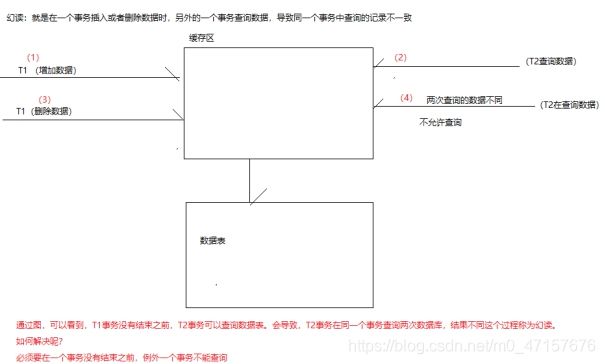
- 幻读(Phantom read): 幻读与不可重复读类似。它发生在一个事务(T1)插入了几行数据,接着另一个并发事务(T2)读取了一些数据时。T1删除了一些数据,第二个事务T2在随后的查询中,就会发现少了一些原本存在的记录,就好像发生了幻觉一样,所以称为幻读。
不可重复度和幻读区别:
不可重复读的重点是修改,幻读的重点在于新增或者删除。
例1(同样的条件, 你读取过的数据, 再次读取出来发现值不一样了 ):事务1中的A先生读取自己的工资为 1000的操作还没完成,事务2中的B先生就修改了A的工资为2000,导 致A再读自己的工资时工资变为 2000;这就是不可重复读。
例2(同样的条件, 第1次和第2次读出来的记录数不一样 ):假某工资单表中工资大于3000的有4人,事务1读取了所有工资大于3000的人,共查到4条记录,这时事务2 又插入了一条工资大于3000的记录,事务1再次读取时查到的记录就变为了5条,这样就导致了幻读。
事务隔离级别有哪些?MySQL的默认隔离级别是?
SQL 标准定义了四个隔离级别:
- READ-UNCOMMITTED(读取未提交): 最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读。
- READ-COMMITTED(读取已提交): 允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生。
- REPEATABLE-READ(可重复读): 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。
- SERIALIZABLE(可串行化): 最高的隔离级别,完全服从ACID的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。
| 隔离级别 | 脏读 | 不可重复读 | 幻影读 |
|---|---|---|---|
| READ-UNCOMMITTED | √ | √ | √ |
| READ-COMMITTED | × | √ | √ |
| REPEATABLE-READ | × | × | √ |
| SERIALIZABLE | × | × | × |
MySQL InnoDB 存储引擎的默认支持的隔离级别是 REPEATABLE-READ(可重读)。我们可以通过SELECT @@tx_isolation;命令来查看
show variables;#查看所有数据库变量
select @@tx_isolation;#检索变量tx_isolation的值 @@表示检索变量
这里需要注意的是:与 SQL 标准不同的地方在于InnoDB 存储引擎在 **REPEATABLE-READ(可重读)事务隔离级别下使用的是Next-Key Lock 锁算法,因此可以避免幻读的产生,这与其他数据库系统(如 SQL Server)是不同的。所以说InnoDB 存储引擎的默认支持的隔离级别是 REPEATABLE-READ(可重读) 已经可以完全保证事务的隔离性要求,即达到了 SQL标准的SERIALIZABLE(可串行化)**隔离级别。
模拟脏读
打开mysql客户端A,查看隔离级别

客户端A设置事务隔离级别

客户端B设置事务隔离级别
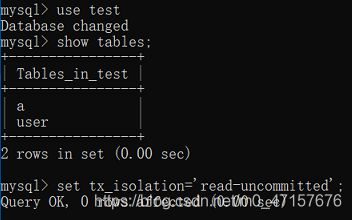
客户端A关闭事务自动提交,开启事务

客户端B关闭事务自动提交,开启事务
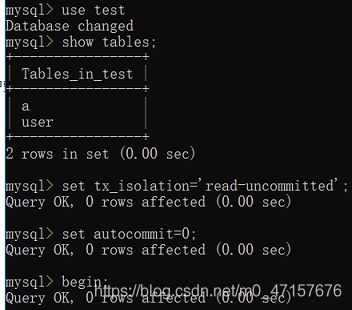
客户端A查询一条记录

客户端B修改该记录

客户端A再次查询该记录,出现脏读:

二、druid性能监控
1.Druid的监控统计功能页面效果
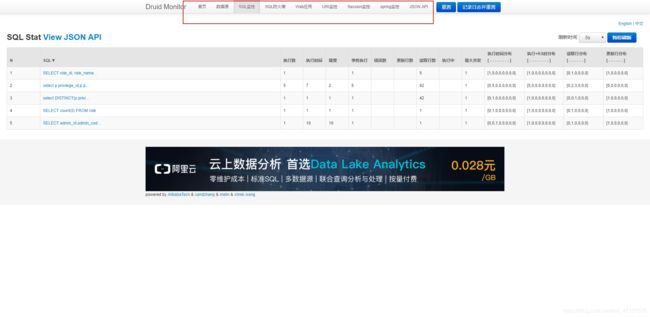
2.1.打开监控功能
Druid内置提供一个StatFilter,用于统计监控信息。
(参考文档:https://github.com/alibaba/druid/wiki/%E9%85%8D%E7%BD%AE_StatFilter)
2.1.1. 别名配置
StatFilter的别名是stat,这个别名映射配置信息保存在druid-xxx.jar!/META-INF/druid-filter.properties。
在spring中使用别名配置方式如下:
//如果Properties文件的属性名命名符合configFromPropety的参数Properties的命名规则,则自动赋值
@Bean
public DruidDataSource getDataSource(){
Properties props = new Properties();
try {
props.load(SpringMybatisConfig.class.getClassLoader().getResourceAsStream("db.properties"));
DruidDataSource dataSource = new DruidDataSource();
dataSource.configFromPropety(props);
dataSource.setFilters("stat");//配置默认监控filter
return dataSource;
} catch (IOException e) {
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
}
return null;
}
2.1.2. 组合配置
StatFilter可以和其他的Filter配置使用,比如:
//如果Properties文件的属性名命名符合configFromPropety的参数Properties的命名规则,则自动赋值
@Bean
public DruidDataSource getDataSource(){
Properties props = new Properties();
try {
props.load(SpringMybatisConfig.class.getClassLoader().getResourceAsStream("db.properties"));
DruidDataSource dataSource = new DruidDataSource();
dataSource.configFromPropety(props);
dataSource.setFilters("stat,wall,slf4j");
dataSource.setConnectionProperties("druid.stat.mergeSql=true;druid.stat.slowSqlMillis=1000");//开启慢sql监控,大于1000毫秒的为慢sql,默认是3秒
return dataSource;
} catch (IOException e) {
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
}
return null;
}
在上面的配置中,StatFilter和WallFilter、SlfFilter组合使用。
WallFilter:防止sql注入的过滤器
(参考文档:https://github.com/alibaba/druid/wiki/%E9%85%8D%E7%BD%AE-wallfilter)
Slf4jFileter:日志记录JDBC执行的SQL
(参考文档:https://github.com/alibaba/druid/wiki/配置_LogFilter)
2.2使用Druid的内置监控页面
要访问druid的内置监控页面,需要配置一个servlet(参考文档:https://github.com/alibaba/druid/wiki/配置_StatViewServlet配置)
@WebServlet(urlPatterns = "/druid/*",initParams = {
@WebInitParam(name="allow",value = ""),//ip白名单,没有配置或空,则允许所有访问
@WebInitParam(name="deny",value = ""),//ip黑名单
@WebInitParam(name = "loginUsername",value = "admin"),//用户名
@WebInitParam(name="loginPassword",value = "123456"),//密码
@WebInitParam(name="resetEnable",value="false")//禁用html页面的reset all功能
})
public class DruidStatueServlet extends StatViewServlet {
}
或者在spring配置类中:
/** * 注册一个StatViewServlet * * @return */ @Bean public ServletRegistrationBean druidServlet() { ServletRegistrationBean reg = new ServletRegistrationBean(); reg.setServlet(new StatViewServlet()); reg.addUrlMappings(new String[]{"/druid/*"}); //IP白名单 (没有配置或者为空,则允许所有访问) reg.addInitParameter("allow", ""); //是否能够重置数据 reg.addInitParameter("resetEnable", "false"); //设置账号密码 reg.addInitParameter("loginUsername", "admin"); reg.addInitParameter("loginPassword", "123456"); return reg; }
开启后即可以启动服务器,并且通过地址栏访问监控页面,访问规则:
ip:端口号/应用名/druid/login.html

输入上一步设置的账户密码即可登录
3.设置web监控
WebStatFilter用于采集web-jdbc关联监控的数据(参考文档:https://github.com/alibaba/druid/wiki/配置_配置WebStatFilter)
@WebFilter(filterName = "druidStatueFilter",urlPatterns = "/*",
initParams = {
@WebInitParam(name="exclusions",value = "*.js,*.jpg,*.png,*.css,/druid/*"),
@WebInitParam(name="profileEnable",value = "true")
})
public class DruidStatueFilter extends WebStatFilter {
}
或者在spring配置类中:
/**
* 注册一个:filterRegistrationBean
*
* @return
*/
@Bean
public FilterRegistrationBean filterRegistrationBean() {
FilterRegistrationBean filterRegistrationBean = new FilterRegistrationBean();
filterRegistrationBean.setFilter(new WebStatFilter());
//添加过滤规则
filterRegistrationBean.addUrlPatterns(new String[]{"/*"});
//添加需要忽略的格式信息
filterRegistrationBean.addInitParameter("exclusions", "*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*");
filterRegistrationBean.addInitParameter("profileEnable", "true");//配置profileEnable能够监控单个url调用的sql列表
filterRegistrationBean.addInitParameter("principalCookieName", "USER_COOKIE");//如果你的user信息保存在cookie中,你可以配置
//principalCookieName,使得druid知道当前的user是谁 USER_COOKIE为cookie名
filterRegistrationBean.addInitParameter("principalSessionName", "USER_SESSION");//使得druid能够知道当前的session的用户是谁
filterRegistrationBean.addInitParameter("DruidWebStatFilter", "/*");
return filterRegistrationBean;
}
4.设置spring监控
@Bean(name="druidStatInterceptor")//设置druid 的 aop切面类
public DruidStatInterceptor getDruidStatInterceptor(){
DruidStatInterceptor druidStatInterceptor = new DruidStatInterceptor();
return druidStatInterceptor;
}
@Bean//配置spring监控
public BeanNameAutoProxyCreator getAutoProxyCreator(){
BeanNameAutoProxyCreator beanNameAutoProxyCreator = new BeanNameAutoProxyCreator();
beanNameAutoProxyCreator.setProxyTargetClass(true);
beanNameAutoProxyCreator.setBeanNames(new String[]{"*Mapper","*Service"});
beanNameAutoProxyCreator.setInterceptorNames("druidStatInterceptor");
return beanNameAutoProxyCreator;
}