初识MySQL
去年开学的时候决定接触下MySQL,
买了本书——MySQL从入门到精(fang)通(qi),跟着前面几章,下载安装、建库建表,然后就是增删改查,
然后这本书就看不下去了,全书都在“你执行这个语句,然后你就会看到这种结果”,这样然后那样...
可能我没选对书,说好的从入门开始呢,感觉书上内容很飘,MySQL到底是啥?
有没有人给入门的孩子介绍下MySQL的基本构成?
1. MySQL逻辑架构
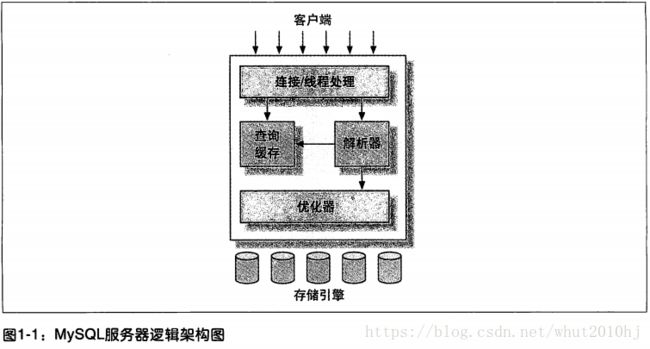
用Navicat 连接MySQL 的时候会要求提供IP、端口号、用户名和密码,此时我们用Navicat 客户端访问的就是MySQL最上层的服务了;
大多数MySQL 的核心服务功能都集中在第二层;
第三层是存储引擎,存储引擎负责数据的存储和提取,具体怎么存怎么取,都是这家伙实现的,相当NB了。存储引擎和服务层之间是通过API来回交互的,具体怎么如何交互的,就需要深入了解了(说白了就是我也还不知道)。
2. MySQL的并发控制
数据库系统概念这本书就有章节是单独讲并发和事务的,可见这个在数据库实现上还是非常关键的,同时这本书更像是数据库上的百科全书,啥都讲,看得人头大。
并发控制的目的就是要解决多个请求同时读写某一个数据表或者数据表的某一行产生冲突而导致数据不正确问题。
2.1 读写锁
一个经典且简单的做法就是加锁,一个只能一个进程可以操作。考虑到读写的不同,可以实现两种锁,共享锁(S锁)和排他锁(X锁),也叫读锁和写锁。读锁是共享的,相互之间不阻塞,写锁是排他的,一个写锁会阻塞其他的读锁和写锁(有读锁的时候可以有其他读锁,有写锁的时候不能有其他的)。
2.2 锁粒度
比如A要访问表T的x行,B要访问表T的y行(x!=y),A进表的时候把表锁了,B就进不去了,其实他两本来不冲突的,现在却阻塞了,效率就低了。我们可以只锁要访问的行,而不是整个表,这样AB就都可以进行操作了,缺点就是这样一来锁的数量就多了。
任何时候,在给定的资源上,锁定的数据量越少,则系统的并发程度就越高,只要相互之间不发生冲突即可。缺点就是加锁也要消耗资源。这两者之间可以根据特定情况寻求平衡。
根据锁粒度的不同就有表锁和行级锁。
3. 事务
我刚学数据库的时候哪知道什么事务,研究生的数据库课程提都没提这两字,可能是老师觉得讲了你也不会听吧=。=
事务就是把一块SQL语句打包起来,这一个包里的语句,要么全部执行,要么都不执行。
为啥非要这样搞,不这样搞不行吗?不搞可以,搞了数据不会出错,如果你觉得你的数据库数据错一点也没啥,那就不搞。
一个运行良好的失误处理系统,需要具备原子性、一致性、隔离性和持久性(取英文头字母也就是常说的ACID)。
原子性:曾经以为原子是最小的物质哈,就是一个事务必须是不可分割的最小单元;
一致性:数据库从一个一致性状态zhuan转换到另一个一致性状态(这样干之前一致,后也一致);
隔离性:事务之间要隔离,我干的事情在提交前你是看不到的;
持久性:一旦事务提交,则其所做的修改就会永远保存到数据库中。
3.1 隔离级别
这里可以参考一篇通俗易懂的文章:码农翻身:数据库村的旺财和小强
就是根据事务之间隔离程度的不同,分了四个级别,分别是
未提交读(read uncommited):一个事务中的修改,还没提交,其他事务也是可见的。事务读取未提交的数据,称为脏读(我改了还没提交你读了,然后我给回滚了,你读的不就不对了)。
提交读(read commited):一个事务开始时,只能看到以提交事务所做的修改。但是吧,举个例子,A事务先读了一个数据,然后干了点别的,事务还没结束哈,这中间B事务修改了这个数据,然后提交了,A再去读刚那个数据,尼玛,变了。这就是不可重复读现象,所有有时候提交度级别也叫不可重复读(nonrepeatable read)。
可重复读(repeatable read):可重复读就是要保证同一个事务中,多次读取的同样记录的结果是一样的。这个是MySQL的默认隔离级别。但是这里有个幻读问题,比如我SELECT符合某个条件的n行出来做了修改,然后别人插入了一条符合这个条件的行记录进来,结果看起来好像是我少修改了一行,出现幻觉了。MySQL的InnoDB引擎多版本并发控制(MVCC)解决了幻读问题。
可串行化(serializable):就是事务要串行执行,不能有穿插,是最高的隔离级别了,读没一行数据的时候都会加锁。

3.2 死锁
死锁是指两个或者多个事务在同一资源上相互占用,并请求锁定对方的资源,从而导致恶性循环的现象。
举个栗子:AB两人要吃饭,只有一双筷子(假定吃饭必须要两只筷子哈),正常情况下就是一个人先吃,吃完了第二个人吃,或者一人吃一会儿。现在的情况却是一人拿了一只筷子,都要先吃,你要我的那一只,我要你的那一只,结果就是谁都吃不成,就是死锁(死磕到底了)。
死锁发生以后,只有部分或者完全回滚其中一个事务,才能打破死锁。
3.3 事务日志
使用事务日志,存储引擎在修改时,该该修改行为记录到事务日志中,把日志持久化到磁盘,而对表只修改其内存拷贝。这样内存中修改的数据可以在后台慢慢的写到磁盘里,因为日志持久化了,就算这次没写完就掉电了,重启的时候根据日志也能恢复。这样就提高了事务的效率。
3.4 MySQL中的事务
默认采用自动提交,如果不显式地开始事务,每个查询都被当做一个事务,并执行提交操作。
4. 多版本并发控制(MVCC)
上面推荐的那篇码农翻身作者的文章里也提到了这个,
MVCC在很多情况下加锁操作,实现了非阻塞的读操作,写操作也只锁定必要的行。
InnoDB的MVCC是通过在每行记录后面保存两个隐藏的列来实现的。这两个列,一个保存了行创建时的系统版本号,一个保存行删除时的系统版本号。系统版本号在每开始一个事务的时候都会自动递增。事务开始时刻的系统版本号会作为事务的版本号,用来和查询到的每行记录的版本号进行比较。
在SELECT时,InnoDB只查找这样的行:①创建版本号小于或者等于当前事务的版本号(小于:在事务开始前存在;等于:自身干的);②删除版本号要么未定义,要么大于当前事务版本号。①和②是&&的关系,满足①而且满足②。
INSERT、DELETE、UPDATE操作会修改相应的版本号。
5. MySQL存储引擎
只简单的讲下MyISAM和InnoDB,
MyISAM 是MySQL5.1及之前版本的默认引擎,不支持事务,对整张表加锁,读加共享锁,写加排他锁。
InnoDB 是现在的默认引擎,支持事务,采用MVCC来支持高并发,默认级别是可重复读,并且通过间隙锁策略防止幻读出现。
间隙锁使得InnoDB不仅仅锁定查询涉及的行,还会对索引中的间隙进行锁定,以防止幻影行的插入。
对于快照读(简单的select操作),是利用MVCC来防止幻读的,当前读(select ... lock in share mode、select ... for update、insert、update、delete)中是通过加间隙锁来避免幻读的。
InnoDB表是基于聚集索引建立的,对主键查询性能高。
参考书籍:《MySQL从入门到放弃》《数据库系统概念》《高性能MySQL》