最近在阅读 Accrual Failure Detector 论文及其网络上的分析文章,结合 Cassandra 源码,写了一点关于Accrual Failure Detector 的学习笔记,参考文章及链接附后,感觉到需要好好复习当年学过的概率论与数理统计。
概述
在分布式系统中,我们通常会在应用层做心跳检查,如果心跳消息在设定的周期中没有到达,就认为对端已经不可用了,可能crash掉了,或者网络中断了。
例如,两台server, A 和 B, A每秒钟发送一个心跳消息给 B,
- 如果B 在3秒内没有收到来自 A 的心跳,则认为 A 已经不可用了
- 如果 A 连续三次的心跳消息都没有收到响应,则认为 B 已经不可用了。
通常给每个节点设置一个 isAvaiable 属性就行了,当认为其可用则设为true, 不可用时设为 false,可是情况没那么简单,这个世界很复杂,不是非黑即白的情况。
例如有这样一个 Job servers, 由 master node 控制 worker node 来执行任务
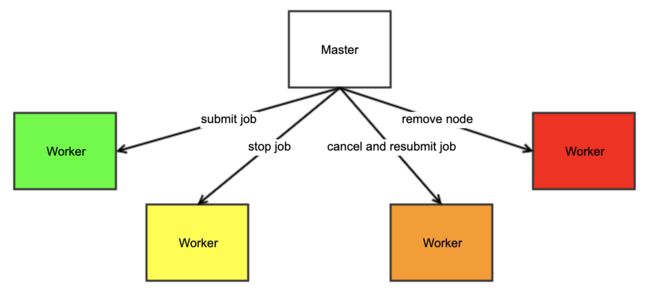
- 当网络状态是健康的,以绿色表示:提交 job 给此 worker 节点
- 当网络状态有点问题,以黄色表示:停止提交 job 给此 worker 节点
- 当网络状态有些问题,以橙色表示:取消所有此 worker 节点上的 job 并重新提交 job 给其他 worker 节点
- 当网络状态有大问题,以红色表示:将此 worker 节点从节点列表中删除。
而且网络延迟和抖动是偶发和不可预测的,非黑即白的判断常有失误。
而 Phi Accrual Failure Detector 很好地改进了这一点,它采用一个称为 Phi 的可疑程度,它可以根据当前网络的状况动态调整。
phi = -log10(1 - F(timeSinceLastHeartbeat))这里的 F 是正态分布的累积分布函数,其均值和标准差是根据历史心跳消息的到达间隔时间估算出来的。实际应用中,随机间隔的心跳时间使用指数分布可能合适。
AFD(Accrual Failure Detector) 累积故障检测器使监视和解释解耦。 这使得它们适用于更广泛的场景,并且更适合构建通用的故障检测服务。
这样做的目的是保留从其他节点接收到的心跳计算出的故障统计数据的历史记录,并试图通过考虑多个因素以及它们随着时间的累积如何进行有根据的猜测,以便得出更好的结果。 猜测特定节点是否处于运行状态。 与其要回答“节点是否断开?”问题,不如不要回答“是”或“否”,而是返回一个phi值,该值表示节点断开的可能性。
下图说明了自上一个心跳消息到达以来,Phi 如何随着时间增加而增加。
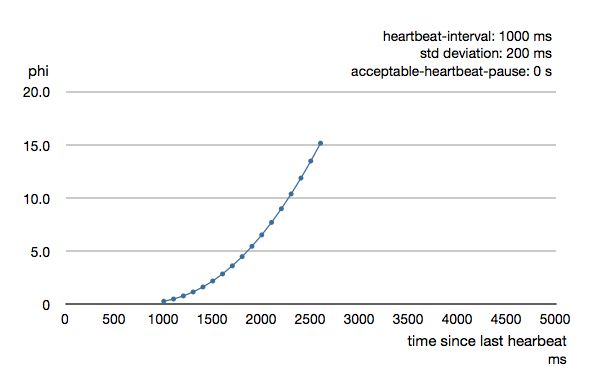
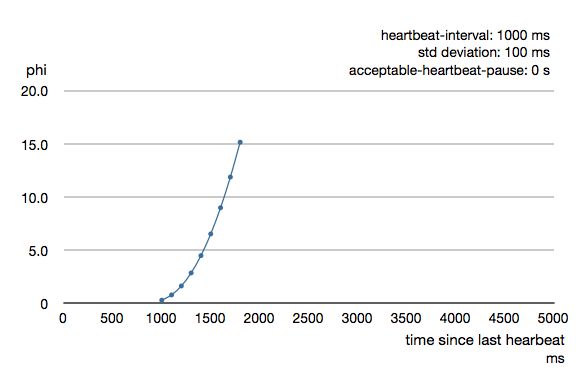
根据历史到达时间的平均值和标准偏差计算出Phi。 上一张图表是200 ms标准偏差的示例。 如果心跳以较小的偏差到达,则曲线会变得更陡峭,即可以更快地确定故障。 对于100 ms的标准偏差,曲线看起来像这样。
为了能够承受突发异常(例如,垃圾收集暂停和瞬态网络故障),故障检测器配置有余量,可以根据环境对它进行调整。 这是配置为3秒的failure-detector.acceptable-heartbeat-pause的曲线。
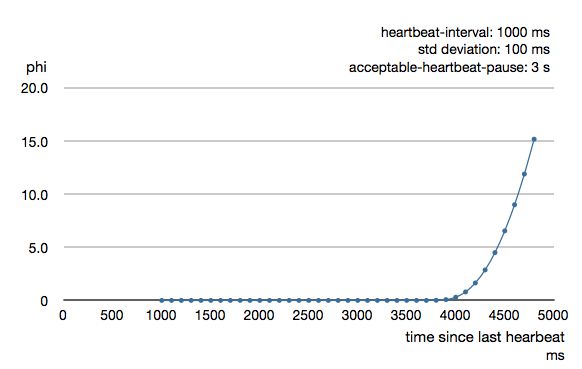
这里的 failure-detector.acceptable-heartbeat-pause 是故障检测的阈值。
较低的阈值易于产生许多误报,但可以确保在发生实际碰撞时快速检测到。
相反,较高的阈值产生较少的错误,但需要更多的时间来检测实际的崩溃。
参考论文
- The ϕ Accrual Failure Detector
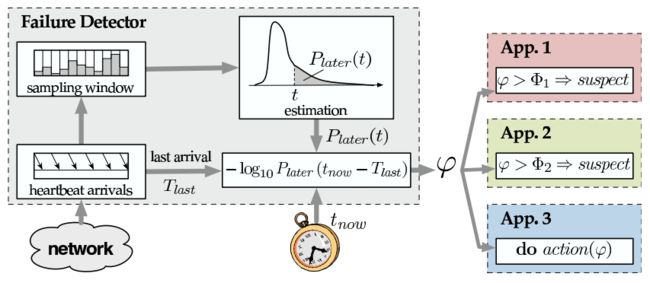
- 给定阀值 Φ1, Φ2
- 在一定时间窗口内,记录各个心跳间隔时间
- 对心跳的间隔值求指数分布(Exponential distribution)概率:
#(E是对数2.71828...,mean为此前的间隔时间平均值)
P = E ^ (-1 * (now - lastTimeStamp) / mean)其表示,自上次统计以来,心跳到达时间将超过 now - lastTimeStamp 的概率
计算 φ = - log10 P
当φ > Φ1 时,app 1 怀疑主机可能宕机了。
当φ > Φ2 时,app2 怀疑主机已经宕机了。
当然这可能会存在误判,误判的可能性如下:
Φ = 1, 1%
Φ = 2, 0.1%
Φ = 3, 0.01%
......
由此可见,当Φ = 8时,误判率已经很小了。cassandra中默认采用Φ = 8。
参考实现
- Cassandra 中有一个 FailureDetector 类, Cassandra 节点之间通过 Gossip 协议来知晓其他节点在集群中的状态信息,其 Gossiper 类有个每秒钟的定时任务来发送和接收Gossip 消息。

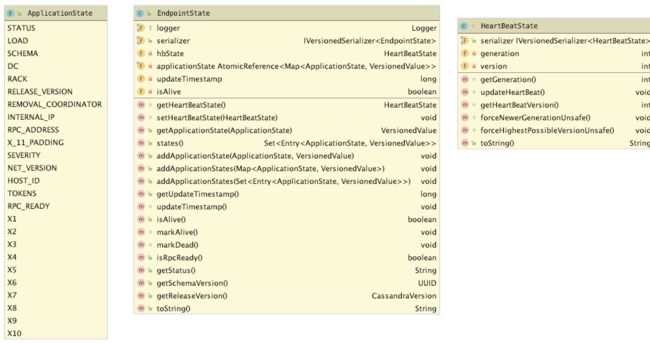
Gossiper 类维护了一个 endpointStateMap, key是节点地址,Value是节点状态

节点状态由 HeartBeatState 和 ApplicationState 组成
Gossiper 在启动的时候会通过executor.scheduleWithFixedDelay创建定时任务 GossipTask。而 GossipTask 每次运行时会调用 doGossipToLiveMember, maybeGossipToUnreachableMember,和 doStatusCheck方法。
而 doStatusCheck方法会遍历endpointStateMap中的InetAddress,对其执行FailureDetector.instance.interpret(endpoint)
org.apache.cassandra.gms.FailureDetector 的interpret方法会调用ArrivalWindow.phi计算now值的phi,然后乘以PHI_FACTOR,如果大于phiConvictThreshold则会回调IFailureDetectionEventListener的convict方法

- 心跳消息来了就汇报
用一个滑动窗口记录下 接收到的 一个节点的心跳信息的时间间隔,在cassandra中,窗口的size设置为1000;然后根据窗口中的数据来生成指数分布,从而估计下一次心跳在当前时刻应该到来的概率;
public void report(InetAddress ep)
{
long now = Clock.instance.nanoTime();
ArrivalWindow heartbeatWindow = arrivalSamples.get(ep);
if (heartbeatWindow == null)
{
// avoid adding an empty ArrivalWindow to the Map
heartbeatWindow = new ArrivalWindow(SAMPLE_SIZE);
heartbeatWindow.add(now, ep);
heartbeatWindow = arrivalSamples.putIfAbsent(ep, heartbeatWindow);
if (heartbeatWindow != null)
heartbeatWindow.add(now, ep);
}
else
{
heartbeatWindow.add(now, ep);
}
if (logger.isTraceEnabled() && heartbeatWindow != null)
logger.trace("Average for {} is {}", ep, heartbeatWindow.mean());
}- 根据心跳消息到来的时间,解释计算指定节点的 Phi 值
public void interpret(InetAddress ep)
{
ArrivalWindow hbWnd = arrivalSamples.get(ep);
if (hbWnd == null)
{
return;
}
long now = Clock.instance.nanoTime();
long diff = now - lastInterpret;
lastInterpret = now;
if (diff > MAX_LOCAL_PAUSE_IN_NANOS)
{
logger.warn("Not marking nodes down due to local pause of {} > {}", diff, MAX_LOCAL_PAUSE_IN_NANOS);
lastPause = now;
return;
}
if (Clock.instance.nanoTime() - lastPause < MAX_LOCAL_PAUSE_IN_NANOS)
{
logger.debug("Still not marking nodes down due to local pause");
return;
}
double phi = hbWnd.phi(now);
if (logger.isTraceEnabled())
logger.trace("PHI for {} : {}", ep, phi);
if (PHI_FACTOR * phi > getPhiConvictThreshold())
{
if (logger.isTraceEnabled())
logger.trace("Node {} phi {} > {}; intervals: {} mean: {}", new Object[]{ep, PHI_FACTOR * phi, getPhiConvictThreshold(), hbWnd, hbWnd.mean()});
for (IFailureDetectionEventListener listener : fdEvntListeners)
{
listener.convict(ep, phi);
}
}
else if (logger.isDebugEnabled() && (PHI_FACTOR * phi * DEBUG_PERCENTAGE / 100.0 > getPhiConvictThreshold()))
{
logger.debug("PHI for {} : {}", ep, phi);
}
else if (logger.isTraceEnabled())
{
logger.trace("PHI for {} : {}", ep, phi);
logger.trace("mean for {} : {}", ep, hbWnd.mean());
}
}如何计算 Phi 值,https://issues.apache.org/jira/browse/CASSANDRA-2597 中有详细解释:
在分布式系统的Gossip节点之间创建 Failure Detector 时,最初的Cassandra作者对原始论文中的φ应计故障检测器示例进行了修改。他们在自己的Cassandra论文中提到:“尽管原始论文表明该分布近似于高斯分布,但由于 Gossip 通道的性质及其对延迟的影响,我们发现指数分布是更好的近似分布。”关于该主题的内容已不再赘述,但可能是因为最初的Phi Accrual论文实现期望正常的心跳消息,而ArrivalWindow仅测量了接收来自 Gossip 的'Syn','Ack'和'Ack2'消息之间的间隔。给定的端点,经历典型随机抖动的常规消息传输将遵循正态分布,但是由于从端点A到端点B的 Gossip消息是以随机间隔发送的,因此它们很可能构成了泊松过程,从而使指数分布变得适当。
double phi(long tnow)
{
assert arrivalIntervals.mean() > 0 && tLast > 0; // should not be called before any samples arrive
long t = tnow - tLast;
lastReportedPhi = t / mean();
return lastReportedPhi;
}phi 方法通过t / mean()来近似计算P(x <= t), 这是一个近似公式,推导过程如下:
(P_later 表示 endpoint B 挂掉的概率,t参数表示自从上一次收到B的heartbeat信息以来的时间)
# 原始公式:
P_later(t) = 1 - F(t)
# F(t) 是指数分布的CDF(累积分布函数),也就是如下公式,其中 L 是速率参数
P_later(t) = 1 - (1 - e^(-Lt))速率参数L的最大似然估计由 1/平均值 给出,其中平均值是从实际数据中观察到的时间的算术平均值(此处是从端点B到达的最新 Gossip 消息到达的时间)。 我们希望这个速率参数会随时间变化,因此有必要存储到达间隔的滑动窗口。所以
P_later(t) = 1 - (1 - e^(-t/mean))
=> P_later(t) = e^(-t/mean)
=> phi(t) = -log10(P_later(t))
=> phi(t) = -log10(e^(-t/mean))
=> phi(t) = -log(e^(-t/mean)) / log(10)
= (t/mean) / log(10)
~> phi(t) = 0.4342945 * t/mean参考资料
- Akka Phi Accrual Failure Detector
- The Phi Accrual Failure Detector by Hayashibara et al
- Cassandra - A Decentralized Structured Storage System
- Inconsistent implementation of 'cumulative distribution function' for Exponential Distribution
- Cassandra中失效检测原理详解
- cassandra中对节点失败与否的探测方法