Mysql日志模块
Mysql日志模块
- redo log(重做日志)
- binlog(归档日志)
- 两种日志的区别
- 更新操作
- change buffer v.s. redo log
-
- 你的sql语句为什么突然变慢了
-
- 1.redo log日志写满了
- 2. 内存满了
- 3. Mysql认为系统空闲时
- 4. Mysql正常关闭
redo log(重做日志)
WAL技术(Write-Aheading Logging): 他的主要思想是先写日志再执行操作。
如果一条记录需要更新,先将更新记录写在redo log日志中,innodb引擎会在合适的时刻执行相应的更新操作。
Innodb的redo log大小是固定的,固定大小是4g,当redo log日志写满之后,会重头开始写,在重写之前,会将数据更新操作执行完毕之后,在进行重写。
Innodb可以保证数据库发生异常重启,我们可以通过redo log进行恢复,这个能力成为crash-safe。
binlog(归档日志)
Mysql分为两部分,一部分Server端,负责Mysql功能层面的东西,一部分引擎端,负责底层存储。redo log是Innodb引擎独有的日志模块,binlog是Server层自己的日志。
两种日志的区别
- binlog是所有引擎都可以使用的,而redo log是Innodb独有的。
- binlog记录的是逻辑日志,记录了语句的原始逻辑,比如“id为3的记录字段c+1”,redolog记录的是物理日志,是在某个数据页上做了什么修改。
- binlog是追加的形式,日志文件到了一定的大小会重新创建一个文件,redo log会覆盖原有的日志记录。
更新操作
mysql>update t set c=c+1 where id=2
下面我们来分析一下Innodb会执行的操作:
1. 引擎通过索引树找到对应的Id,然后看这一行数据所在的数据页是否存在内存中,如果不存在,就从磁盘中读取到内存。
2. 执行器拿到数据之后,执行更新操作
3. 执行完操作,将数据内容更新到内存,写入redo log 日志,进入prepare阶段,表示事务随时可提交
4. 执行器生成该操作的binlog日志
5. 执行commit操作
这就是两次分段提交,那么我们为什么需要分段提交呢?
假设我们不使用分段提交的方式,有下面两种情形
1.先写redo log, 在写binlog。现程序在redo log写完之后,binlog写完之前崩溃了,那么在重启之后,我们可以通过redo log来恢复更新操作,但由于binlog缺失,在进行丛库修复的时候,就不会执行此次更新的同步,这样就导致了主从不同步。
2.先写binlog,再写redo log。程序在写完binlog之后,redo log之前发生了崩溃,那么由于redo log中没有对应的操作,数据不会回复,后期如果使用binlog来修复,就会发现多了一个事务和更新操作。
为什么不可以直接写两个日志文件,在恢复时判断两个文件完整才能恢复?
因为redo log 提交完成了,那么就不能进行回滚了,会覆盖到其他事务,而 redo log 提交,binlog写入失败,不能回滚的条件下就会导致主备不一致。
change buffer v.s. redo log
change buffer 跟 redo log 在功能上看起来差不多,那么他两者之间有什么区别呢?
我们就一个例子来分析:
mysql>insert into t(id,k) values(id1,k1), (id2,k2)
现假设id1,id2不在同一个数据页上,而且id1的数据页在内存中。
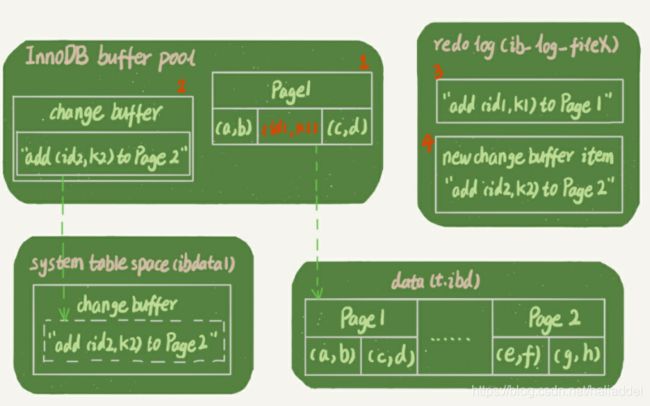
执行步骤如下:
- PAGE1在内存中,直接更新
- PAGE2不在内存中,在change buffer中记录下“我要向page2中插入一条数据(id2,k2)”
- 将上述两个操作记录在redo log中。
在后续中,如果要操作到page2的数据,那么就会从change buffer中读取更新操作执行。
你的sql语句为什么突然变慢了
redo log的内存不是无限大的,在合适的时机,mysql会将redo log中的数据写到磁盘。将内存里面的数据写入到磁盘,这个过程就是flush。
当内存里面的数据页与磁盘数据页内容不一致时,称之为“脏页”,反之,为“干净页”。
当平时很快的操作,突然变慢了,很可能就是mysql在flush。
那么在什么情况下会执行flush操作呢?
1.redo log日志写满了
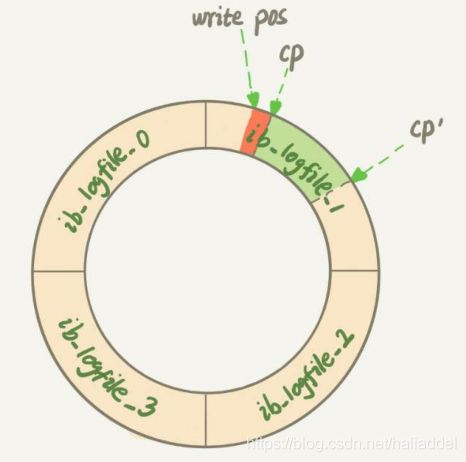
这是mysql会停止所有的更新操作,将checkpoint往前推,前推之前,需要吧这一段日志内存里面对应的数据页刷到磁盘。
2. 内存满了
当系统内存不足时,需要淘汰掉一些数据页,腾内存给新的数据页。如果淘汰掉的数据页是脏页,就需要将脏页写到磁盘。
既然redo log已经记录了对这些数据页的操作,为啥不直接淘汰呢?
这样做的主要原因是出于性能考虑,更新后内存页主要就只有两种状态:
1. 数据页在内存中,那么他的数据页就是更改过的,直接返回
2. 数据页在磁盘,flush之后保证了数据页是一致的,直接读取到内存后返回
3. Mysql认为系统空闲时
4. Mysql正常关闭
在下次重启时,由于数据页是干净的,可以直接读取到内存。