row cache lock一则案例
官网解释为:This event is used to wait for a lock on a data dictionary cache specified by "cache id" (P1).
从解释可以看出这个等待时间是数据字段上面的等待,通过p1可以查询到等待的数据字典。
昨天接到用户反馈说系统异常缓慢,需要紧急优化一下,从用户给出的时间段拉取了awr报告进行分析。
top 10中94%的都是row cache lock的等待,说明问题就是这个row cache lock引起的。需要找到这个时间点的cache信息。
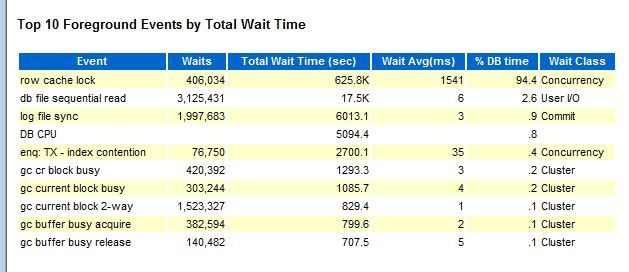
可以通过ash或者dba_hist_active_sess_history查询
SELECT event,p1,p1text
FROM v$active_session_history ash
WHERE ash.sample_time > '22-JUN-16 14.00.00.00 PM'
AND ash.sample_time < '22-JUN-16 16.00.00.00 PM'
and event='row cache lock'
因为系统一直还很缓慢所以可以通过当前的v$session 去查询
SYS@jktoa1> selectdistinct p1,p1text from v$session t where t.event='row cache lock';
P1 P1TEXT
--------------------------------------------------------------------------
13 cache id
SYS@jktoa1> selectparameter,gets,getmisses,MODIFICATIONS from v$rowcache where cache#=13;
PARAMETER GETS GETMISSES MODIFICATIONS
------------------------------------------ ---------- -------------
dc_sequences 220656516 42531729 220656171
可以看出是sequence引起的,在从这段时间的awr报告中看到对应的sql。可以看到8ctzwy7jhquhz这个sql执行时间上很多,而且还是sequnece。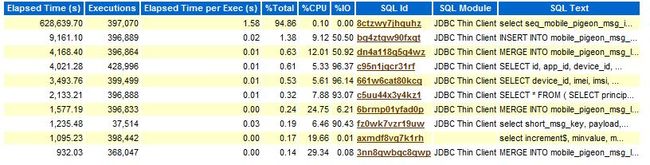
sql内容为:selectseq_mobile_pigeon_msg_id.nextval from dual
基本可以确定就是这个sequence的因为访问次数过多(每秒要请求54次),引起sequence分配时在系统的中争用。
sequence的脚本如下:
createsequence SEQ_MOBILE_PIGEON_MSG_ID
minvalue 1
maxvalue999999999999999999999999999
start with55051
increment by 1
nocache;
看到sequence的定义,可以肯定是因为sequence因为nocache加上并发调用引起的。
但是因为数据库是rac环境,如果调整为cache,如果应用对序列有顺序要求的这种,调整就会有问题。
比如cache 40,
instance 1 使用1-40
instance 2使用41-80
和开发问过应用对序列顺序要求后,确认应用对sequence的顺序没有太大依赖,所以可以调整sequence的cache。
调整后应用访问正常。
row cache lock还有很多,比如dc_users,dc_segments这些处理起来就比较麻烦,需要通过debug跟踪session找到具体出现row cache lock的原因。才能从根本上解决问题。