maven之读写pdf简单实例(pdfbox与itext)与pdfbox源码解析(访问者模式)
记录学习的脚步
本文是用pdfbox读写pdf,但是因为pdfbox在写pdf的时候,对中文的支持不好,会有乱码,我尝试着修改COSString的源码,试了UTF-8、UTF-16BE几种编码 中文输出还是乱码 接着把pdfbox parent中的pom 的
所幸itext对中文的支持还不错 使用itext进行写pdf
参考
pdfbox 官网 http://pdfbox.apache.org/cookbook/documentcreation.html
itext 官网 http://itextpdf.com/learn
下面 itext 中的代码 来源于 这位哥们写的 http://www.iteye.com/topic/1006313 本来是打算自己写的 但是这哥们写的不错 还有注释 就直接用了
itext的更多详细的操作 可参考 http://rensanning.iteye.com/blog/1538689 他写的很详细
1、先看pdfbox的读写pdf的代码
产生pdf的 SavePdfDocument.java类 必要的地方都加了注释
package com.undergrowth.pdfbox;
import java.io.IOException;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.pdfbox.cos.COSString;
import org.apache.pdfbox.exceptions.COSVisitorException;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.pdmodel.PDPage;
import org.apache.pdfbox.pdmodel.edit.PDPageContentStream;
import org.apache.pdfbox.pdmodel.font.PDFont;
import org.apache.pdfbox.pdmodel.font.PDType1Font;
/**
* SavePdfDocument类用于产生pdf文档
* @author Administrator
* @date 2014-8-31
* @version 1.0.0
*/
public class SavePdfDocument {
/**
* 日志常量
*/
public static final Log logger=LogFactory.getLog(SavePdfDocument.class);
/**
* 测试产生pdf文档
* @param sayWhat 要写入到pdf文档中的内容
* @param filePath 保存pdf的路径
* @throws IOException
* @throws COSVisitorException
*
*/
public boolean helloPdf(String sayWhat,String filePath) throws IOException, COSVisitorException{
boolean f=false;
PDDocument document=getPdDocument();
PDPage page=getPdPage();
document.addPage(page);
PDFont font=getFont();
PDPageContentStream contentStream=getPdPageContentStream(document, page);
contentStream.beginText();
contentStream.setFont(font, 20);
contentStream.moveTextPositionByAmount(200, 300);
/* COSString cosString=new COSString(new String(sayWhat.getBytes(), "UTF-16BE"));
contentStream.drawString("hello world"+"\t");*/
//contentStream.drawString("hello world"+cosString.getString());
contentStream.drawString(sayWhat);
contentStream.endText();
//关闭页面内容流
contentStream.close();
document.save(filePath);
document.close();
logger.info("成功创建pdf");
f=true;
return f;
}
/**
* 获取空的pdf文档对象
* @return PDDocument
*/
public PDDocument getPdDocument(){
PDDocument document=new PDDocument();
return document;
}
/**
* 通过文件名加载文档
* @param fileName
* @return PDDocument
* @throws IOException
*/
public PDDocument getPdDocument(String fileName) throws IOException{
PDDocument document=PDDocument.load(fileName);
return document;
}
/**
* 获取空的pdf页面对象
* @return PDPage
*/
public PDPage getPdPage(){
PDPage page =new PDPage();
return page;
}
/**
* 获取海维提卡体
* @return PDFont
*/
public PDFont getFont(){
PDFont font=PDType1Font.HELVETICA_BOLD;
return font;
}
/**
* 获取页面内容流 向页面添加内容
* @param document PDDocument
* @param page PDPage
* @return PDPageContentStream
* @throws IOException
*/
public PDPageContentStream getPdPageContentStream(PDDocument document,PDPage page) throws IOException{
PDPageContentStream contentStream=new PDPageContentStream(document, page);
return contentStream;
}
}
提取pdf的 PdfTextStripperTest.java
package com.undergrowth.pdfbox;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.OutputStreamWriter;
import java.io.Writer;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.util.PDFTextStripper;
public class PdfTextStripperTest {
public static Log log=LogFactory.getLog(PdfTextStripperTest.class);
/**
* 获取文本提取
*
* @param document
* @param writer
* @throws IOException
*/
public void getTextStripper(PDDocument document, Writer writer)
throws IOException {
PDFTextStripper textStripper = new PDFTextStripper();
textStripper.writeText(document, writer);
}
/**
* 提取文本内容
* @param String fileName 加载文档的路径
* @return String
* @throws IOException
*/
public String getText(String fileName) throws IOException {
String textString = "";
SavePdfDocument pdfDocument = new SavePdfDocument();
PDDocument document = pdfDocument.getPdDocument(fileName);
//将提取出来的字节流转换为字符流进行显示
ByteArrayOutputStream out = new ByteArrayOutputStream();
OutputStreamWriter writer = new OutputStreamWriter(out);
getTextStripper(document, writer);
document.close();
out.close();
writer.close();
byte[] con = out.toByteArray();
textString = new String(con);
log.info("提取的文本内容为:"+textString);
return textString;
}
}
测试类
package com.undergrowth.pdfbox;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.UnsupportedEncodingException;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.pdfbox.exceptions.COSVisitorException;
import junit.framework.Test;
import junit.framework.TestCase;
import junit.framework.TestSuite;
/**
* Unit test for simple App.
*/
public class AppTest
extends TestCase
{
/**
* Create the test case
*
* @param testName name of the test case
*/
public AppTest( String testName )
{
super( testName );
}
/**
* @return the suite of tests being tested
*/
public static Test suite()
{
return new TestSuite( AppTest.class );
}
/**
* Rigourous Test :-)
* @throws IOException
* @throws COSVisitorException
*/
public void testApp() throws COSVisitorException, IOException
{
SavePdfDocument pdfDocument=new SavePdfDocument();
String filePath="e:\\hello.pdf";
boolean f=pdfDocument.helloPdf(("hello world"), filePath);
/*
* boolean f=pdfDocument.helloPdf(new String("?我".getBytes("UTF-16BE"),"UTF-16BE"), filePath);
* System.out.println("我".getBytes("UTF-8"));
System.out.println(new String("我".getBytes("UTF-16BE"), "UTF-16BE"));
*/
assertTrue( f );
filePath="E:\\test11.pdf";
PdfTextStripperTest textStripperTest=new PdfTextStripperTest();
String stripperText = textStripperTest.getText(filePath);
assertNotSame(stripperText, "");
}
}
2、使用itext进行写pdf
PdfUtils.java
package com.undergrowth.pdfbox;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import org.apache.pdfbox.pdfparser.PDFParser;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.util.PDFTextStripper;
import com.itextpdf.text.BaseColor;
import com.itextpdf.text.Chapter;
import com.itextpdf.text.Document;
import com.itextpdf.text.DocumentException;
import com.itextpdf.text.Font;
import com.itextpdf.text.FontFactory;
import com.itextpdf.text.List;
import com.itextpdf.text.ListItem;
import com.itextpdf.text.PageSize;
import com.itextpdf.text.Paragraph;
import com.itextpdf.text.Phrase;
import com.itextpdf.text.Rectangle;
import com.itextpdf.text.Section;
import com.itextpdf.text.pdf.BaseFont;
import com.itextpdf.text.pdf.PdfWriter;
/**
* 来源: http://www.iteye.com/topic/1006313
* @author Administrator
*
*/
public class PdfUtils {
// public static final String CHARACTOR_FONT_CH_FILE = "SIMFANG.TTF"; //仿宋常规
public static final String CHARACTOR_FONT_CH_FILE = "SIMHEI.TTF"; //黑体常规
public static final Rectangle PAGE_SIZE = PageSize.A4;
public static final float MARGIN_LEFT = 50;
public static final float MARGIN_RIGHT = 50;
public static final float MARGIN_TOP = 50;
public static final float MARGIN_BOTTOM = 50;
public static final float SPACING = 20;
private Document document = null;
private FileOutputStream out=null;
/**
* 功能:创建导出数据的目标文档
* @param fileName 存储文件的临时路径
* @return
*/
public void createDocument(String fileName) {
File file = new File(fileName);
out = null;
document = new Document(PAGE_SIZE, MARGIN_LEFT, MARGIN_RIGHT, MARGIN_TOP, MARGIN_BOTTOM);
try {
out = new FileOutputStream(file);
// PdfWriter writer =
PdfWriter.getInstance(document, out);
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (DocumentException e) {
e.printStackTrace();
}
// 打开文档准备写入内容
document.open();
}
/**
* 将章节写入到指定的PDF文档中
* @param chapter
* @return
*/
public void writeChapterToDoc(Chapter chapter) {
try {
if(document != null) {
if(!document.isOpen()) document.open();
document.add(chapter);
}
} catch (DocumentException e) {
e.printStackTrace();
}
}
/**
* 功能 创建PDF文档中的章节
* @param title 章节标题
* @param chapterNum 章节序列号
* @param alignment 0表示align=left,1表示align=center
* @param numberDepth 章节是否带序号 设值=1 表示带序号 1.章节一;1.1小节一...,设值=0表示不带序号
* @param font 字体格式
* @return Chapter章节
*/
public static Chapter createChapter(String title, int chapterNum, int alignment, int numberDepth, Font font) {
Paragraph chapterTitle = new Paragraph(title, font);
chapterTitle.setAlignment(alignment);
Chapter chapter = new Chapter(chapterTitle, chapterNum);
chapter.setNumberDepth(numberDepth);
return chapter;
}
/**
* 功能:创建某指定章节下的小节
* @param chapter 指定章节
* @param title 小节标题
* @param font 字体格式
* @param numberDepth 小节是否带序号 设值=1 表示带序号 1.章节一;1.1小节一...,设值=0表示不带序号
* @return section在指定章节后追加小节
*/
public static Section createSection(Chapter chapter, String title, Font font, int numberDepth) {
Section section = null;
if(chapter != null) {
Paragraph sectionTitle = new Paragraph(title, font);
sectionTitle.setSpacingBefore(SPACING);
section = chapter.addSection(sectionTitle);
section.setNumberDepth(numberDepth);
}
return section;
}
/**
* 功能:向PDF文档中添加的内容
* @param text 内容
* @param font 内容对应的字体
* @return phrase 指定字体格式的内容
*/
public static Phrase createPhrase(String text,Font font) {
Phrase phrase = new Paragraph(text,font);
return phrase;
}
/**
* 功能:创建列表
* @param numbered 设置为 true 表明想创建一个进行编号的列表
* @param lettered 设置为true表示列表采用字母进行编号,为false则用数字进行编号
* @param symbolIndent
* @return list
*/
public static List createList(boolean numbered, boolean lettered, float symbolIndent) {
List list = new List(numbered, lettered, symbolIndent);
return list;
}
/**
* 功能:创建列表中的项
* @param content 列表项中的内容
* @param font 字体格式
* @return listItem
*/
public static ListItem createListItem(String content, Font font) {
ListItem listItem = new ListItem(content, font);
return listItem;
}
/**
* 功能:创造字体格式
* @param fontname
* @param size 字体大小
* @param style 字体风格
* @param color 字体颜色
* @return Font
*/
public static Font createFont(String fontname, float size, int style, BaseColor color) {
Font font = FontFactory.getFont(fontname, size, style, color);
return font;
}
/**
* 功能: 返回支持中文的字体---仿宋
* @param size 字体大小
* @param style 字体风格
* @param color 字体 颜色
* @return 字体格式
*/
public static Font createCHineseFont(float size, int style, BaseColor color) {
BaseFont bfChinese = null;
try {
bfChinese = BaseFont.createFont(CHARACTOR_FONT_CH_FILE,BaseFont.IDENTITY_H, BaseFont.EMBEDDED);
} catch (DocumentException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return new Font(bfChinese, size, style, color);
}
/**
* 最后关闭PDF文档
*/
public void closeDocument() {
if(document != null) {
document.close();
}
}
/**
* 读PDF文件,使用了pdfbox开源项目
* @param fileName
*/
public static void readPDF(String fileName) {
File file = new File(fileName);
FileInputStream in = null;
try {
in = new FileInputStream(fileName);
// 新建一个PDF解析器对象
PDFParser parser = new PDFParser(in);
// 对PDF文件进行解析
parser.parse();
// 获取解析后得到的PDF文档对象
PDDocument pdfdocument = parser.getPDDocument();
// 新建一个PDF文本剥离器
PDFTextStripper stripper = new PDFTextStripper();
// 从PDF文档对象中剥离文本
String result = stripper.getText(pdfdocument);
System.out.println("PDF文件的文本内容如下:");
System.out.println(result);
} catch (Exception e) {
System.out.println("读取PDF文件" + file.getAbsolutePath() + "生失败!" + e);
e.printStackTrace();
} finally {
if (in != null) {
try {
in.close();
} catch (IOException e1) {
}
}
}
}
/**
* 测试pdf文件的创建
* @param args
*/
public static void main(String[] args) {
String fileName = "E:\\test11.pdf"; //这里先手动把绝对路径的文件夹给补上。
PdfUtils PdfUtils = new PdfUtils();
Font chapterFont = com.undergrowth.pdfbox.PdfUtils.createCHineseFont(20, Font.BOLD, new BaseColor(0, 0, 255));//文章标题字体
Font sectionFont = com.undergrowth.pdfbox.PdfUtils.createCHineseFont(16, Font.BOLD, new BaseColor(0, 0, 255));//文章小节字体
Font textFont = com.undergrowth.pdfbox.PdfUtils.createCHineseFont(10, Font.NORMAL, new BaseColor(0, 0, 0));//小节内容字体
PdfUtils.createDocument(fileName);
Chapter chapter = com.undergrowth.pdfbox.PdfUtils.createChapter("糖尿病病例1", 1, 1, 0, chapterFont);
Section section1 = com.undergrowth.pdfbox.PdfUtils.createSection(chapter, "病例联系人信息", sectionFont,0);
Phrase text1 = com.undergrowth.pdfbox.PdfUtils.createPhrase("如您手中有同类现成病例,在填写完以上基础信息后,传病例附件",textFont);
section1.add(text1);
Section section2 = com.undergrowth.pdfbox.PdfUtils.createSection(chapter, "病例个人体会", sectionFont,0);
Phrase text2 = com.undergrowth.pdfbox.PdfUtils.createPhrase("1.下载病例生成PDF文档",textFont);
// text2.setFirstLineIndent(20); //第一行空格距离
section2.add(text1);
section2.add(text2);
List list = com.undergrowth.pdfbox.PdfUtils.createList(true, false, 20);
String tmp = "还有什么能够文档。文档是 PDF 文档的所有元素的容器。 ";
ListItem listItem1 = com.undergrowth.pdfbox.PdfUtils.createListItem(tmp,textFont);
ListItem listItem2 = com.undergrowth.pdfbox.PdfUtils.createListItem("列表2",textFont);
list.add(listItem1);
list.add(listItem2);
section2.add(list);
PdfUtils.writeChapterToDoc(chapter);
PdfUtils.closeDocument();
//读取
readPDF(fileName);
}
}
上面使用了黑体字体 需要将黑体字体的ttf文件放在resources目录下 即可
上面即使使用pdfbox与itext的简单实例
附pom.xml
4.0.0
com.undergrowth
pdfbox
0.0.1-SNAPSHOT
jar
pdfbox
http://maven.apache.org
UTF-8
junit
junit
3.8.1
test
org.apache.pdfbox
pdfbox
1.8.6
com.ibm.icu
icu4j
3.8
com.itextpdf
itextpdf
5.5.1
jar
org.apache.maven.plugins
maven-javadoc-plugin
2.9.1
date
a
日期:
3、再来看看pdfbox的源码吧 说起pdfbox的源码编译 就郁闷
因为pdfbox核心库pdfbox中测试需要用到
com.levigo.jbig2
levigo-jbig2-imageio
1.6.2
test
net.java.dev.jai-imageio
jai-imageio-core-standalone
1.2-pre-dr-b04-2011-07-04
test
jbig2.googlecode
JBIG2 ImageIO-Plugin repository at googlecode.com
http://jbig2-imageio.googlecode.com/svn/maven-repository/
位于googlecode上的jar包 可 google 与我天朝的关系貌似不太友好啊 一直编译不过去 后来干脆只有将pdfbox核心库中pdfbox的测试库全删了 再把上面的依赖注释掉
哈哈 编译成功
好吧 还是来看看 pdfbox中用到的访问者模式吧 也正是由于这个模式中的访问者的操作 才将最终的document内容输出到输出流中去
访问者模式是什么啊 好吧
看看这里有两篇文章 有个大致印象吧
访问者模式 http://blog.csdn.net/hfmbook/article/details/7684175
访问者模式 http://www.2cto.com/kf/201402/278957.html
还是从头看起 先看 PDdocument的构造器
/**
* Constructor, creates a new PDF Document with no pages. You need to add
* at least one page for the document to be valid.
*/
public PDDocument()
{
document = new COSDocument();
//First we need a trailer
COSDictionary trailer = new COSDictionary();
document.setTrailer( trailer );
//Next we need the root dictionary.
COSDictionary rootDictionary = new COSDictionary();
trailer.setItem( COSName.ROOT, rootDictionary );
rootDictionary.setItem( COSName.TYPE, COSName.CATALOG );
rootDictionary.setItem( COSName.VERSION, COSName.getPDFName( "1.4" ) );
//next we need the pages tree structure
COSDictionary pages = new COSDictionary();
rootDictionary.setItem( COSName.PAGES, pages );
pages.setItem( COSName.TYPE, COSName.PAGES );
COSArray kidsArray = new COSArray();
pages.setItem( COSName.KIDS, kidsArray );
pages.setItem( COSName.COUNT, COSInteger.ZERO );
}在构建一个新的PDDocument的时候 底层使用了一个COSDocument进行替代 然后在document中有一个全局的字典记录器 trailer
大致示意图 画得太丑了 完全没有艺术细胞 哎
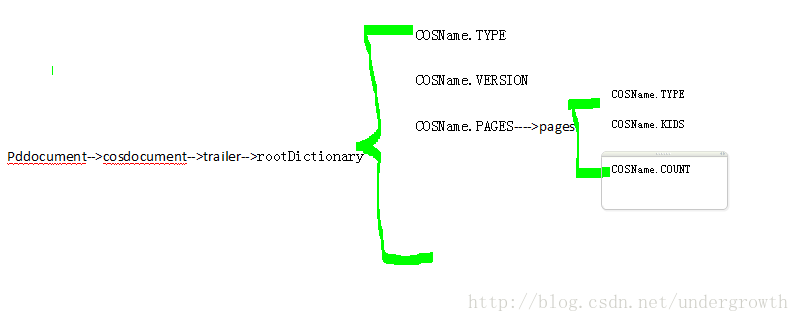
其实上面 如果有兴趣 你追踪看一下 发现 new COSDocument();
/**
* Constructor. Uses memory to store stream.
*/
public COSDocument()
{
this(new RandomAccessBuffer(), false);
} /**
* Default constructor.
*/
public RandomAccessBuffer()
{
// starting with one chunk
bufferList = new ArrayList();
currentBuffer = new byte[BUFFER_SIZE];
bufferList.add(currentBuffer);
pointer = 0;
currentBufferPointer = 0;
size = 0;
bufferListIndex = 0;
bufferListMaxIndex = 0;
} 会发现 COSDocument 实际上是初始化一个16k的内存堆块
接着看 创建了一个PDPage的构造函数
/**
* Creates a new instance of PDPage with a size of 8.5x11.
*/
public PDPage()
{
page = new COSDictionary();
page.setItem( COSName.TYPE, COSName.PAGE );
setMediaBox( PAGE_SIZE_LETTER );
}创建了一个page 页面的矩形大小为 page拥有一个type和media_box属性
/**
* A page size of LETTER or 8.5x11.
*/
public static final PDRectangle PAGE_SIZE_LETTER =
new PDRectangle( 8.5f*DEFAULT_USER_SPACE_UNIT_DPI, 11f*DEFAULT_USER_SPACE_UNIT_DPI );page.setItem( COSName.MEDIA_BOX, mediaBoxValue.getCOSArray() );接着看 document.addPage(page); 将创建的页面添加到文档中 估计就是和上面画的那张不太好看的图挂上钩 额
/**
* This will add a page to the document. This is a convenience method, that
* will add the page to the root of the hierarchy and set the parent of the
* page to the root.
*
* @param page The page to add to the document.
*/
public void addPage( PDPage page )
{
PDPageNode rootPages = getDocumentCatalog().getPages();
rootPages.getKids().add( page );
page.setParent( rootPages );
rootPages.updateCount();
}
看看 第一个方法 getDocumentCatalog().getPages(); 这个方法就是返回rootDictionary中所包含的所有页面
/**
* This will get the root node for the pages.
*
* @return The parent page node.
*/
public PDPageNode getPages()
{
return new PDPageNode( (COSDictionary)root.getDictionaryObject( COSName.PAGES ) );
}初始化的时候 rootDictionary中的page的计数是为0的
接着 第三行 page.setParent( rootPages ); 将page指向root的page页
再看PDPageContentStream的构造器
/**
* Create a new PDPage content stream.
*
* @param document The document the page is part of.
* @param sourcePage The page to write the contents to.
* @throws IOException If there is an error writing to the page contents.
*/
public PDPageContentStream(PDDocument document, PDPage sourcePage) throws IOException
{
this(document, sourcePage, false, true);
} /**
* Create a new PDPage content stream.
*
* @param document The document the page is part of.
* @param sourcePage The page to write the contents to.
* @param appendContent Indicates whether content will be overwritten. If false all previous content is deleted.
* @param compress Tell if the content stream should compress the page contents.
* @throws IOException If there is an error writing to the page contents.
*/
public PDPageContentStream(PDDocument document, PDPage sourcePage, boolean appendContent, boolean compress)
throws IOException
{
this(document, sourcePage, appendContent, compress, false);
} /**
* Create a new PDPage content stream.
*
* @param document The document the page is part of.
* @param sourcePage The page to write the contents to.
* @param appendContent Indicates whether content will be overwritten. If false all previous content is deleted.
* @param compress Tell if the content stream should compress the page contents.
* @param resetContext Tell if the graphic context should be reseted.
* @throws IOException If there is an error writing to the page contents.
*/
public PDPageContentStream(PDDocument document, PDPage sourcePage, boolean appendContent, boolean compress,
boolean resetContext) throws IOException
{
// Get the pdstream from the source page instead of creating a new one
PDStream contents = sourcePage.getContents();
boolean hasContent = contents != null;
// If request specifies the need to append to the document
if (appendContent && hasContent)
{
// Create a pdstream to append new content
PDStream contentsToAppend = new PDStream(document);
// This will be the resulting COSStreamArray after existing and new streams are merged
COSStreamArray compoundStream = null;
// If contents is already an array, a new stream is simply appended to it
if (contents.getStream() instanceof COSStreamArray)
{
compoundStream = (COSStreamArray) contents.getStream();
compoundStream.appendStream(contentsToAppend.getStream());
}
else
{
// Creates the COSStreamArray and adds the current stream plus a new one to it
COSArray newArray = new COSArray();
newArray.add(contents.getCOSObject());
newArray.add(contentsToAppend.getCOSObject());
compoundStream = new COSStreamArray(newArray);
}
if (compress)
{
List filters = new ArrayList();
filters.add(COSName.FLATE_DECODE);
contentsToAppend.setFilters(filters);
}
if (resetContext)
{
// create a new stream to encapsulate the existing stream
PDStream saveGraphics = new PDStream(document);
output = saveGraphics.createOutputStream();
// save the initial/unmodified graphics context
saveGraphicsState();
close();
if (compress)
{
List filters = new ArrayList();
filters.add(COSName.FLATE_DECODE);
saveGraphics.setFilters(filters);
}
// insert the new stream at the beginning
compoundStream.insertCOSStream(saveGraphics);
}
// Sets the compoundStream as page contents
sourcePage.setContents(new PDStream(compoundStream));
output = contentsToAppend.createOutputStream();
if (resetContext)
{
// restore the initial/unmodified graphics context
restoreGraphicsState();
}
}
else
{
if (hasContent)
{
LOG.warn("You are overwriting an existing content, you should use the append mode");
}
contents = new PDStream(document);
if (compress)
{
List filters = new ArrayList();
filters.add(COSName.FLATE_DECODE);
contents.setFilters(filters);
}
sourcePage.setContents(contents);
output = contents.createOutputStream();
}
formatDecimal.setMaximumFractionDigits(10);
formatDecimal.setGroupingUsed(false);
// this has to be done here, as the resources will be set to null when reseting the content stream
resources = sourcePage.getResources();
if (resources == null)
{
resources = new PDResources();
sourcePage.setResources(resources);
}
} 其实这个方法这么多 对于第一次创建PDPageContentStream的话
contents = new PDStream(document);output = contents.createOutputStream();并且将输出流指向PDStream 即指向document的记录文件中
至于 contentStream.beginText();
contentStream.setFont(font, 20);
contentStream.moveTextPositionByAmount(200, 300); 这几个方法 都比较简单 就是写一些命令 移动上面所见的page的位置
看drawString
/**
* This will draw a string at the current location on the screen.
*
* @param text The text to draw.
* @throws IOException If an io exception occurs.
*/
public void drawString(String text) throws IOException
{
if (!inTextMode)
{
throw new IOException("Error: must call beginText() before drawString");
}
COSString string = new COSString(text);
ByteArrayOutputStream buffer = new ByteArrayOutputStream();
string.writePDF(buffer);
appendRawCommands(buffer.toByteArray());
appendRawCommands(SPACE);
appendRawCommands(SHOW_TEXT);
}这里有一个COSString类 我估计就是这个类导致与中文的乱码 还是看看它的构造器吧
/**
* Explicit constructor for ease of manual PDF construction.
*
* @param value
* The string value of the object.
*/
public COSString(String value)
{
try
{
boolean unicode16 = false;
char[] chars = value.toCharArray();
int length = chars.length;
for (int i = 0; i < length; i++)
{
if (chars[i] > 255)
{
unicode16 = true;
break;
}
}
if (unicode16)
{
byte[] data = value.getBytes("UTF-16BE");
out = new ByteArrayOutputStream(data.length + 2);
out.write(0xFE);
out.write(0xFF);
out.write(data);
}
else
{
byte[] data = value.getBytes("ISO-8859-1");
out = new ByteArrayOutputStream(data.length);
out.write(data);
}
}
catch (IOException ignore)
{
LOG.error(ignore,ignore);
// should never happen
}
}很明显的看到 当单个字符的编码小于255的时候 使用ISO-8859-1获取到字节码 ISO-8859-1不支持中文啊 不乱码才怪 恩 其实还有很多地方都是用的是ISO-8859-1 所以目前还不清楚 到底需要改哪些地方 才能正确输出中文 貌似对中文的支持确实不太好
好吧 接着看 其实上面就是向PDPageContentStream的output输出流中写入字节 其实就是向document的记录文件中写入字节
接着 contentStream.close(); 一定要 close() 因为
public class PDPageContentStream implements Closeable实现了Closeable接口
接下来的这部操作 就是执行输出操作的地方了 也是用到了访问者模式的地方
document.save(filePath);
/**
* Save the document to a file.
*
* @param fileName The file to save as.
*
* @throws IOException If there is an error saving the document.
* @throws COSVisitorException If an error occurs while generating the data.
*/
public void save( String fileName ) throws IOException, COSVisitorException
{
save( new File( fileName ) );
}/**
* Save the document to a file.
*
* @param file The file to save as.
*
* @throws IOException If there is an error saving the document.
* @throws COSVisitorException If an error occurs while generating the data.
*/
public void save( File file ) throws IOException, COSVisitorException
{
save( new FileOutputStream( file ) );
} /**
* This will save the document to an output stream.
*
* @param output The stream to write to.
*
* @throws IOException If there is an error writing the document.
* @throws COSVisitorException If an error occurs while generating the data.
*/
public void save( OutputStream output ) throws IOException, COSVisitorException
{
//update the count in case any pages have been added behind the scenes.
getDocumentCatalog().getPages().updateCount();
COSWriter writer = null;
try
{
writer = new COSWriter( output );
writer.write( this );
writer.close();
}
finally
{
if( writer != null )
{
writer.close();
}
}
}writer.write( this );看看它的源码
/**
* This will write the pdf document.
*
* @param doc The document to write.
*
* @throws COSVisitorException If an error occurs while generating the data.
*/
public void write(PDDocument doc) throws COSVisitorException
{
Long idTime = doc.getDocumentId() == null ? System.currentTimeMillis() :
doc.getDocumentId();
document = doc;
if(incrementalUpdate)
{
prepareIncrement(doc);
}
// if the document says we should remove encryption, then we shouldn't encrypt
if(doc.isAllSecurityToBeRemoved())
{
this.willEncrypt = false;
// also need to get rid of the "Encrypt" in the trailer so readers
// don't try to decrypt a document which is not encrypted
COSDocument cosDoc = doc.getDocument();
COSDictionary trailer = cosDoc.getTrailer();
trailer.removeItem(COSName.ENCRYPT);
}
else
{
SecurityHandler securityHandler = document.getSecurityHandler();
if(securityHandler != null)
{
try
{
securityHandler.prepareDocumentForEncryption(document);
this.willEncrypt = true;
}
catch(IOException e)
{
throw new COSVisitorException( e );
}
catch(CryptographyException e)
{
throw new COSVisitorException( e );
}
}
else
{
this.willEncrypt = false;
}
}
COSDocument cosDoc = document.getDocument();
COSDictionary trailer = cosDoc.getTrailer();
COSArray idArray = (COSArray)trailer.getDictionaryObject( COSName.ID );
if( idArray == null || incrementalUpdate)
{
try
{
//algorithm says to use time/path/size/values in doc to generate
//the id. We don't have path or size, so do the best we can
MessageDigest md = MessageDigest.getInstance( "MD5" );
md.update( Long.toString(idTime).getBytes("ISO-8859-1") );
COSDictionary info = (COSDictionary)trailer.getDictionaryObject( COSName.INFO );
if( info != null )
{
Iterator values = info.getValues().iterator();
while( values.hasNext() )
{
md.update( values.next().toString().getBytes("ISO-8859-1") );
}
}
idArray = new COSArray();
COSString id = new COSString( md.digest() );
idArray.add( id );
idArray.add( id );
trailer.setItem( COSName.ID, idArray );
}
catch( NoSuchAlgorithmException e )
{
throw new COSVisitorException( e );
}
catch( UnsupportedEncodingException e )
{
throw new COSVisitorException( e );
}
}
cosDoc.accept(this);
} 上面那个方法 重点在 cosDoc.accept(this); 方法上 即COSDocument接受COSWriter对象的访问
那么访问者模式必有得四要素
访问者接口
访问者实现类
目标对象接口
目标对象实现类
在这里
访问者接口即是 ICOSVisitor
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.pdfbox.cos;
import org.apache.pdfbox.exceptions.COSVisitorException;
/**
* An interface for visiting a PDF document at the type (COS) level.
*
* @author Michael Traut
* @version $Revision: 1.6 $
*/
public interface ICOSVisitor
{
/**
* Notification of visit to Array object.
*
* @param obj The Object that is being visited.
* @return any Object depending on the visitor implementation, or null
* @throws COSVisitorException If there is an error while visiting this object.
*/
public Object visitFromArray( COSArray obj ) throws COSVisitorException;
/**
* Notification of visit to boolean object.
*
* @param obj The Object that is being visited.
* @return any Object depending on the visitor implementation, or null
* @throws COSVisitorException If there is an error while visiting this object.
*/
public Object visitFromBoolean( COSBoolean obj ) throws COSVisitorException;
/**
* Notification of visit to dictionary object.
*
* @param obj The Object that is being visited.
* @return any Object depending on the visitor implementation, or null
* @throws COSVisitorException If there is an error while visiting this object.
*/
public Object visitFromDictionary( COSDictionary obj ) throws COSVisitorException;
/**
* Notification of visit to document object.
*
* @param obj The Object that is being visited.
* @return any Object depending on the visitor implementation, or null
* @throws COSVisitorException If there is an error while visiting this object.
*/
public Object visitFromDocument( COSDocument obj ) throws COSVisitorException;
/**
* Notification of visit to float object.
*
* @param obj The Object that is being visited.
* @return any Object depending on the visitor implementation, or null
* @throws COSVisitorException If there is an error while visiting this object.
*/
public Object visitFromFloat( COSFloat obj ) throws COSVisitorException;
/**
* Notification of visit to integer object.
*
* @param obj The Object that is being visited.
* @return any Object depending on the visitor implementation, or null
* @throws COSVisitorException If there is an error while visiting this object.
*/
public Object visitFromInt( COSInteger obj ) throws COSVisitorException;
/**
* Notification of visit to name object.
*
* @param obj The Object that is being visited.
* @return any Object depending on the visitor implementation, or null
* @throws COSVisitorException If there is an error while visiting this object.
*/
public Object visitFromName( COSName obj ) throws COSVisitorException;
/**
* Notification of visit to null object.
*
* @param obj The Object that is being visited.
* @return any Object depending on the visitor implementation, or null
* @throws COSVisitorException If there is an error while visiting this object.
*/
public Object visitFromNull( COSNull obj ) throws COSVisitorException;
/**
* Notification of visit to stream object.
*
* @param obj The Object that is being visited.
* @return any Object depending on the visitor implementation, or null
* @throws COSVisitorException If there is an error while visiting this object.
*/
public Object visitFromStream( COSStream obj ) throws COSVisitorException;
/**
* Notification of visit to string object.
*
* @param obj The Object that is being visited.
* @return any Object depending on the visitor implementation, or null
* @throws COSVisitorException If there is an error while visiting this object.
*/
public Object visitFromString( COSString obj ) throws COSVisitorException;
}
可以看到 有很多访问的操作方法
访问者实现类 又很多 这里只列举 COSWriter 的一个实现方法
/**
* The visit from document method.
*
* @param doc The object that is being visited.
*
* @throws COSVisitorException If there is an exception while visiting this object.
*
* @return null
*/
public Object visitFromDocument(COSDocument doc) throws COSVisitorException
{
try
{
if(!incrementalUpdate)
{
doWriteHeader(doc);
}
doWriteBody(doc);
// get the previous trailer
COSDictionary trailer = doc.getTrailer();
long hybridPrev = -1;
if (trailer != null)
{
hybridPrev = trailer.getLong(COSName.XREF_STM);
}
if(incrementalUpdate)
{
doWriteXRefInc(doc, hybridPrev);
}
else
{
doWriteXRef(doc);
}
// the trailer section should only be used for xref tables not for xref streams
if (!incrementalUpdate || !doc.isXRefStream() || hybridPrev != -1)
{
doWriteTrailer(doc);
}
// write endof
getStandardOutput().write(STARTXREF);
getStandardOutput().writeEOL();
getStandardOutput().write(String.valueOf(getStartxref()).getBytes("ISO-8859-1"));
getStandardOutput().writeEOL();
getStandardOutput().write(EOF);
getStandardOutput().writeEOL();
if(incrementalUpdate)
{
doWriteSignature(doc);
}
return null;
}
catch (IOException e)
{
throw new COSVisitorException(e);
}
catch (SignatureException e)
{
throw new COSVisitorException(e);
}
}目标对象接口 COSBase 有一个抽象的 可接受访问的方法
/**
* visitor pattern double dispatch method.
*
* @param visitor The object to notify when visiting this object.
* @return any object, depending on the visitor implementation, or null
* @throws COSVisitorException If an error occurs while visiting this object.
*/
public abstract Object accept(ICOSVisitor visitor) throws COSVisitorException;目标对象实现类 也很多 只列举 COSDocument 的
/**
* visitor pattern double dispatch method.
*
* @param visitor The object to notify when visiting this object.
* @return any object, depending on the visitor implementation, or null
* @throws COSVisitorException If an error occurs while visiting this object.
*/
@Override
public Object accept(ICOSVisitor visitor) throws COSVisitorException
{
return visitor.visitFromDocument( this );
}所以 在上面的write方法中 调用 cosDoc.accept(this); 的时候
实际上 调用了上面的accept方法 接着调用了 COSWriter的visitFromDocument方法 实现最终的文档内容的输出
对于访问者模式 额 感觉就是对同一类对象 不同的访问者实现类 可以做不同的事情 额 好像 哎 还是不太明白 其实 主要是没有真正的用过 只是学过 看过 还是理解不深啊 记录学习的脚步 接着努力学习 。。。