Elasticsearch 压测方案之 esrally 简介
- 为什么要压测?
- 如何进行压测?
- 入门
- 简介
- 快速入门
- 相关术语
- 压测流程
- 压测结果分析
- 实战
- 问题一
- 问题二
- 问题三
- 进阶
- 自定义car
- 自定义track
- 分布式压测
- 最后一个问题
- 总结
- 参考资料
为什么要压测?
关于压测,我们先来看下百度百科上的一个定义。
压测,即压力测试,是确立系统稳定性的一种测试方法,通常在系统正常运作范围之外进行,以考察其功能极限和隐患。从定义不难看出压测的目的,是要测出一个系统的极限,提早发现隐患,早作打算。那么对于 es 来讲,我认为压测一般有以下几个目的:
1 . 验证 es 的性能,尽管网上把 es 的性能夸上天了,还是自己跑一下才放心.
2 . 针对 es 的某些配置做试验性测试,比如关闭索引的 _all 特性,是否能提高写性能,具体能提高多少。
3 . 对比 es 新版本和旧版本的性能差异。众所周知,es 的版本升级非常快,用着 2.x 的同学们还没来得及升级 5.x ,眼看 6.x 都要发布了。此时,你到底要不要升级呢?答案虽然是肯定的,但是你怎么说服你的 leader 呢?很简单:压测新版本,和旧版本做对比,用表格、图表指明新版本在写性能、读性能方面的改善等等,搞定。
4 . 对 es 集群做容量规划。俗话说“人无远虑,必有近忧”,容量规划就是“远虑”。简单讲就是你线上的 es 集群一共需要多少节点?每个节点的配置如何?这个集群的写性能极限是多少?读性能呢?如果你回答不了这些问题,那就说明你没有做过容量规划,只是两眼一抹黑,说干就干,上了再说,好在有惊无险,没有碰到性能问题。至于什么时候会遇到问题,你也说不准,感觉是个概率和人品问题……对面的老板已经黑脸了…… 对于这个问题我们在最后再来详细讨论。
如何进行压测?
现在我们知道压测的目的了,接下来该如何进行压测呢?一般有以下几个方案:
1 . 自己写代码。无需多言,想怎么写怎么写,难点在于如果确保测试代码的专业性。这里有一些开源项目,留给大家自己探索:esperf 和 elasticsearch-stress-test
2 . http压测工具。es 对外暴露了 Restful API,因此所有的针对 http 协议的压测工具都可以用来测试 es,比如 JMeter、httpload等等。
3 . elastic 官方工具 esrally。
入门
简介
esrally 是 elastic 官方开源的一款基于 python3 实现的针对 es 的压测工具,源码地址为 https://github.com/elastic/rally,相关博客介绍在 这里。esrally主要功能如下:
- 自动创建、压测和销毁 es 集群
- 可分 es 版本管理压测数据和方案
- 完善的压测数据展示,支持不同压测之间的数据对比分析,也可以将数据存储到指定的es中进行二次分析
- 支持收集 JVM 详细信息,比如内存、GC等数据来定位性能问题
elastic 官方也是基于 esrally 进行 es 的性能测试,并将结果实时发布到 https://elasticsearch-benchmarks.elastic.co/ ,大家可以从该网站上直接查看 es 的性能。官方使用两台服务器进行压测,一台运行 esrally ,一台运行 es,服务器的配置如下:
CPU: Intel(R) Core(TM) i7-6700 CPU @ 3.40GHz
RAM: 32 GB
SSD: Crucial MX200
OS: Linux Kernel version 4.8.0-53
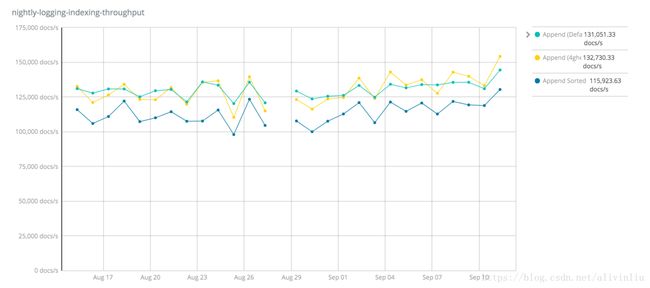
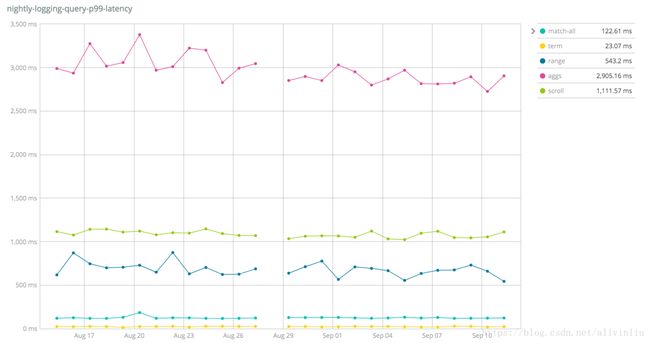
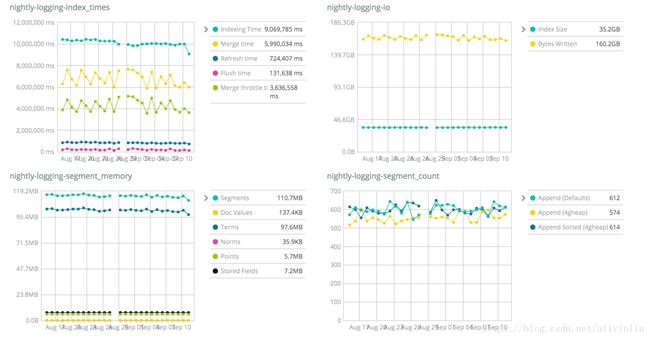
JVM: Oracle JDK 1.8.0_131-b11网站顶部的 Geonames、Geopoint、Percolator等都是针对不同的数据集做的压测,比如下面这些图展示了 logging 日志类数据的压测结果。
快速入门
esrally 的文档在这里,这里简单说下安装与运行。
esrally 对于软件环境的要求如下:
- Python 3.4+ 和 pip3
- JDK 8
- git 1.9+
安装方法为:
pip3 install esrally
Tips:
可以使用国内的pip源,比如豆瓣或者阿里的,这样安装会快很多。安装完毕后执行如下的配置命令,确认一些数据存放的路径即可。
esrally configure接下来就可以开跑了,比如下面这条命令是针对 es 5.0.0 版本进行压力测试。
esrally --distribution-version=5.0.0运行结束后,会得到如下的结果。
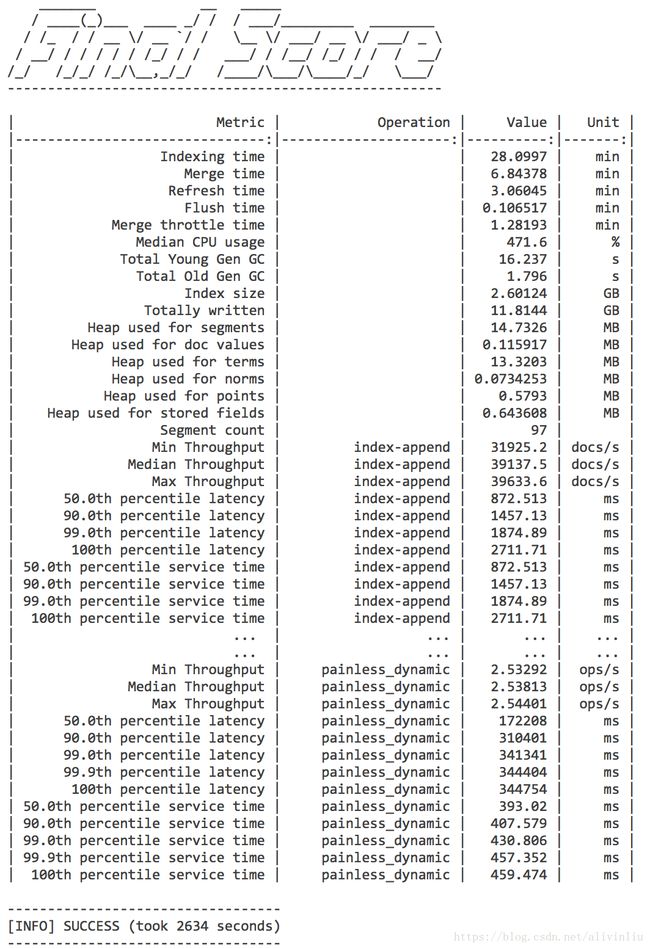
对于第一次见到压测结果的同学来说可能有些晕,这么多数据,该怎么看?!别急,一步步来!
Tips:
由于 esrally 的测试数据存储在国外 aws 上,导致下载很慢甚至会超时失败,从而导致整个压测无法进行。后面我会把这些测试数据的压缩包放到国内,大家可以下载后直接放到 esrally 的数据文件夹下面,保证压测的正常进行。另外由于数据量过大,压测的时间一般会很久,可能在1个小时左右,所以大家要有耐心哦~
如果你只是想体验下,可以加上 –test-mode 的参数,此时只会下载1000条文档进行测试。
相关术语
rally 是汽车拉力赛的意思,也就是说 esrally 是将压测比作了汽车拉力赛,因此其中的很多术语都是从汽车拉力赛中借鉴来的。
track
track 是赛道的意思,在这里是指压测用的数据和测试策略,详细文档在这里。esrally 自带的track都在 github 上,地址在这里 https://github.com/elastic/rally-tracks。在该 repository 中,有很多测试数据,比如 geonames geopoint logging nested 等,每个数据文件夹中的 README.md 中有详细的数据介绍,而 track.json 便是压测策略的定义文件。
我们来看下 loggins/track.json 文件
{% import "rally.helpers" as rally with context %}
{
"short-description": "Logging benchmark",
"description": "This benchmark indexes HTTP server log data from the 1998 world cup.",
"data-url": "http://benchmarks.elasticsearch.org.s3.amazonaws.com/corpora/logging",
"indices": [
{
"name": "logs-181998",
"types": [
{
"name": "type",
"mapping": "mappings.json",
"documents": "documents-181998.json.bz2",
"document-count": 2708746,
"compressed-bytes": 13815456,
"uncompressed-bytes": 363512754
}
]
},
{
"name": "logs-191998",
"types": [
{
"name": "type",
"mapping": "mappings.json",
"documents": "documents-191998.json.bz2",
"document-count": 9697882,
"compressed-bytes": 49439633,
"uncompressed-bytes": 1301732149
}
]
}
],
"operations": [
{{ rally.collect(parts="operations/*.json") }}
],
"challenges": [
{{ rally.collect(parts="challenges/*.json") }}
]
}该 json 文件主要包含下面几个部分:
- description 和 short-description: track 的描述文字
- data-url: 一个url地址,指明测试数据的下载根路径,与下方 indices 中的 documents 结合,可得到数据的下载地址。
- indices: 指定该track可以操作的索引,包括创建、更新、删除等操作。详细信息可以参见这里。
- operations: 指定具体的操作,比如 index 索引数据的操作、force-merge 强制合并segment的操作、search 搜索的操作等等。具体例子可以看下面的示例。详细信息可以参见这里。
- challenges: 通过组合 operations 定义一系列 task ,再组合成一个压测的流程,请参照下方的 例子。详细信息可以参见这里。
operations/default.json 中的一个定义如下:
{
"name": "index-append",
"operation-type": "index",
"bulk-size": 5000
}其中 operation-type 包含 index、force-merge、index-stats、node-stats、search等,每一个operation-type都有自己的可定义参数,比如 index 中可以通过指定 bulk-size 来决定批量写入的文档数。
challenges/default.json 中的一个定义如下:
{
"name": "append-no-conflicts",
"description": "",
"default": true,
"index-settings": {
"index.number_of_replicas": 0
},
"schedule": [
{
"operation": "index-append",
"warmup-time-period": 240,
"clients": 8
},
{
"operation": "force-merge",
"clients": 1
},
{
"operation": "index-stats",
"clients": 1,
"warmup-iterations": 100,
"iterations": 100,
"target-throughput": 50
},
{
"operation": "node-stats",
"clients": 1,
"warmup-iterations": 100,
"iterations": 100,
"target-throughput": 50
},
{
"operation": "default",
"clients": 1,
"warmup-iterations": 100,
"iterations": 500,
"target-throughput": 10
},
{
"operation": "term",
"clients": 1,
"warmup-iterations": 100,
"iterations": 500,
"target-throughput": 60
},
{
"operation": "range",
"clients": 1,
"warmup-iterations": 100,
"iterations": 200,
"target-throughput": 2
},
{
"operation": "hourly_agg",
"clients": 1,
"warmup-iterations": 100,
"iterations": 100,
"target-throughput": 0.2
},
{
"operation": "scroll",
"clients": 1,
"warmup-iterations": 100,
"iterations": 200,
"target-throughput": 10
}
]
}这里定义了一个名为 append-no-conflicts 的 challenge。由于每次压测只能运行一个challenge,这里的 default 参数是指当压测未指定时默认运行的 challenge。schedule 中指定了该 challenge 中按顺序执行 index-append、force-merge、index-stats、node-stats、default、term、range、hourly_agg、scroll 等 9 个task,其中每个 task 都指定了 一个 operation,除此之外还可以设定 clients (并发客户端数)、warmup-iterations(预热的循环次数)、iterations(operation 执行的循环次数)等,详情请参见[]此处](http://esrally.readthedocs.io/en/latest/track.html#schedule)。
通过下面的命令可以查看当前 esrally 可用使用的track。
esrally list tracksesrally 的 track 数据位于 rally 目录(mac默认是 ~/.rally)中 benchmarks/tracks/ 下面。
car
car 是赛车的意思,这里是指不同配置的 es 实例。通过下面的命令可以查看 esrally 当前可用的 car。
esrally list carsName
----------
16gheap
1gheap
2gheap
4gheap
8gheap
defaults
ea
verbose_iwcars 的配置位于 rally 目录(mac默认是 ~/.rally)中 benchmarks/teams/default/cars/ 下面。具体配置可以参见 cars 的文档,除了 heap 的配置,所有的 es 配置都可以修改。
race
race 是一次比赛的意思,这里是指某一次压测。要比赛,就要有赛道和赛车,如果不指定赛车,就用 default 配置,如果不指定赛道,则默认使用 geonames track。通过下面的命令来执行一次 race。
esrally race --track=logging --challenge=append-no-conflicts --car="4gheap"上面的命令便是执行一次压测,并指定使用 logging 的track,运行该 track 中的 append-no-conflicts 的 challenge,指定的 car 为 4gheap 的 es 实例。详情可以查看 race 相关文档。
Tournament
tournament 是锦标赛的意思,是由多个 race 组成的。通过下面的命令可以查看所有的 race。
esrally list racesRecent races:
Race Timestamp Track Challenge Car User Tag
---------------- ------- ------------------- -------- ------------------------------
20160518T122341Z pmc append-no-conflicts defaults intention:reduce_alloc_1234
20160518T112057Z pmc append-no-conflicts defaults intention:baseline_github_1234
20160518T101957Z pmc append-no-conflicts defaults当有了多个 race 后,可以通过下面的命令方便地比较不同 race 之间的数据。
esrally compare --baseline=20160518T112057Z --contender=20160518T112341Z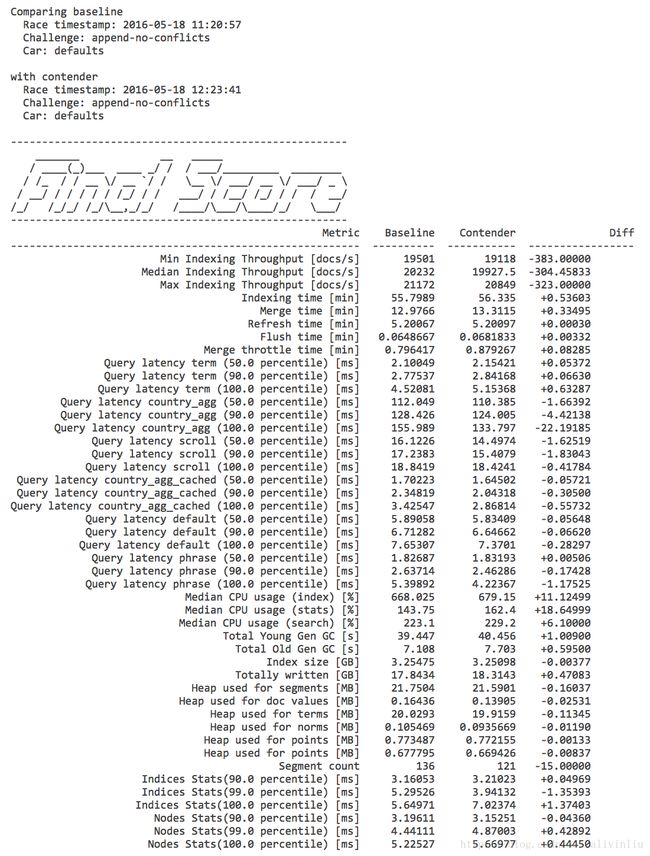
详细信息可以参见 tournament 的文档。
Pipeline
Pipeline 在这里是指压测的一个流程,通过下面的命令可以查看已有的pipeline。
esrally list pipelineName Description
----------------------- ---------------------------------------------------------------------------------------------
from-sources-complete Builds and provisions Elasticsearch, runs a benchmark and reports results.
from-sources-skip-build Provisions Elasticsearch (skips the build), runs a benchmark and reports results.
from-distribution Downloads an Elasticsearch distribution, provisions it, runs a benchmark and reports results.
benchmark-only Assumes an already running Elasticsearch instance, runs a benchmark and reports results- from-sources-complete 是从源代码编译 es 后再运行,可以通过 –revision 参数指明要编译的commit hash ,这样就可以针对某一个提交版本就行测试了。
- from-sources-skip-build 如果已经编译好了,使用该 pipeline,可以跳过编译的流程,节省测试时间
- from-distribution 通过 –distribution-version 指定 es 版本,esrally 会从官网直接下载该版本的可执行文件,然后进行测试。
- benchmark-only 此 pipeline 将 es 集群的管理交由用户来处理, esrally 只做压测。如果你想针对已有集群进行测试,那么要将pipeline设定为该模式。
详细信息请参见 pipeline 的文档。
压测流程
esrally 的压测流程主要分为以下三个步骤:
1 . 根据参数设定自行编译或者下载 es 可执行实例,然后根据 car 的约定,创建并启动 es 集群。如果使用 benchmark-only 的pipeline,则该步骤省略。
2 . 根据指定 track 去下载数据,然后按照指定的 challenge 进行操作
3 . 记录并输出压测结果数据
压测结果分析
压测结束后,esrally 会将结果输出到终端和结果文件(位于 esrally 目录logs 和 benchmarks/races)中,如下图所示:

在 Metric 一栏,有非常多的指标数据,详细的解释可以参见该文档。一般要关注的数据有:
- throughput 每个操作的吞吐量,比如 index、search等
- latency 每个操作的响应时长数据
- Heap used for x 记录堆栈的使用情况
先搞懂每个 metric 的含义,然后根据自己的需求去确认自己要关注的指标。
每一次压测都会以压测时的时间命名,比如 logs/rally_out_20170822T082858Z.log ,这个日志便是记录的 2017年8月22日 8:28:58开始的压测日志。而在 benchmarks/races/2017-08-22-08-28-58 中记录着最终的结果和 es 的运行日志。
另外对于 benchmark-only 模式的测试,即针对已有集群的压力测试,也可以通过安装 X-Pack Basic 版本进行监控(Monitoring),在压测的过程中就能查看相关指标。

esrally 可以在配置的时候指定将所有的 race 压测结果数据存入一个指定的 es 实例中,配置如下(在 esrally 目录中 rally.ini 文件中):
[reporting]
datastore.type = elasticsearch
datastore.host = localhost
datastore.port = 9200
datastore.secure = False
datastore.user =
datastore.password =esrally 会将数据存储在如下 3 个index中,下面 * 代指月份,即按月存储结果数据。
- rally-metrics-* 该索引分指标记录每次 race 的结果,如下图所示为某一次race的所有 metric 数据。

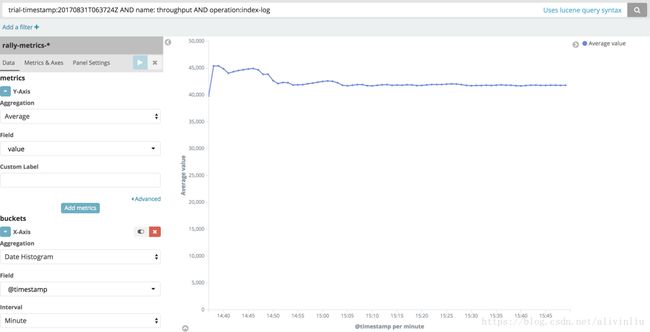
第一列时间是指某一次压测的时间,第二列时间是指标采集的时间,第三列 operation 指具体执行的操作,operation 为空的指标都是总计类的,比如indexing total time 记录的是总索引数据的时间、segments_count 是总段数等等。其他的 operation 都记录了每一个操作的数据。需要注意的是,这里记录的是 operation 的所有采样数据,不是一个最终的汇总数据。上面截图中也可以看出同一个 hour_agg 的operation 有多项名为 service_time 的指标数据,但他们的采集时间是不同的。基于这些数据,我们可以做出某一次 race 中某个指标的可视化图表,比如你想观察本次 race 中 index-log 这个 task 的 throughput 指标数据,便可以通过如下图的方式实现。
- rally-result-* 该索引分指标记录了每次 race 的最终汇总结果,比如下面这条数据。
{
"user-tag": "shardSizeTest:size6",
"distribution-major-version": 5,
"environment": "local",
"car": "external",
"plugins": [
"x-pack"
],
"track": "logging",
"active": true,
"distribution-version": "5.5.2",
"node-count": 1,
"value": {
"50_0": 19.147876358032228,
"90_0": 21.03116340637207,
"99_0": 41.644479789733886,
"100_0": 47.20634460449219
},
"operation": "term",
"challenge": "default-index",
"trial-timestamp": "20170831T063724Z",
"name": "latency"
}这个记录了 term operation 的 latency 指标数据,汇总值以 percentile(百分位数) 的形式展示。基于该数据,我们可以绘制针对某个指标的多race对比,比如下图便是对比多 race 之间 hourly_agg(按小时做聚合)、default(match_all 查询)、term(term查询)、range(range查询)的latency(延迟时间)对比。
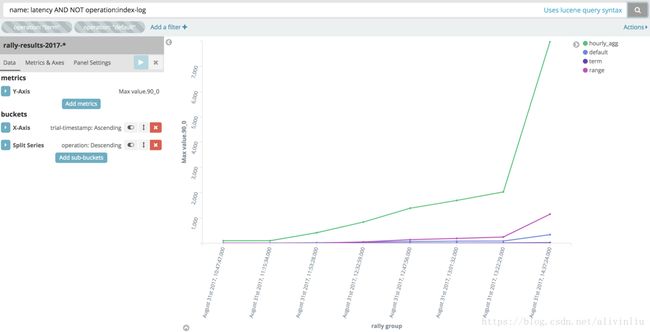
- rally-races-* 该索引记录了所有 race 的最终结果,即命令行执行的输出结果。
除了es相关指标数据外,esrally 还会同时记录测试的一些环境信息,比如操作系统、JVM等等,你可以方便的查看本次测试的软硬件环境。
实战
问题一
提问:如何对比 5.5.0 相比 2.4.6 的性能改进?
回答:
分别针对 5.5.0 和 2.4.6 做一次压测,然后比较两者两者的相关指标即可,这里我们的 track 和 challenge 如下:
- track: nyc_taxis
- challenge: append-no-conflicts
测试步骤如下:
1 . 测试 2.4.6 的性能
esrally race --distribution-version=2.4.6 --track=nyc_taxis --challenge=append-no-conflicts --user-tag="version:2.4.6"2 . 测试 5.5.0 的性能
esrally race --distribution-version=5.5.0 --track=nyc_taxis --challenge=append-no-conflicts --user-tag="version:5.5.0"3 . 对比两次 race 的结果
esrally list races
esrally compare --baseline=[2.4.6 race] --contender=[5.5.0 race]
Tips:
--user-tag 用于为 race 打标签,方便后续查找
如果只是试一下,可以加上 --test-mode ,用测试数据来跑,很快。问题二
提问:如何测试 _all 关闭后对于写性能的影响?
回答:
针对 5.5.0 版本的 es 做两次测试,第一次开启 _all,第二次关闭 _all,对比两次的结果,由于只测试写性能,所以我们只需要 index 类型的 operation执行。这里我们的 track 和 challenge 如下:
- track: nyc_taxis
- challenge: append-no-conflicts
测试步骤如下:
1 . 默认 nyc_taxis 的 mapping 设置是将 _all 关闭的,直接测试 _all 关闭时的性能。
esrally race --distribution-version=5.5.0 --track=nyc_taxis --challenge=append-no-conflicts --user-tag="enableAll:false" --include-tasks="type:index"2 . 修改 nyc_taxis 的 mapping 设置,打开 _all。mapping 文件位于 rally 主目录 benchmarks/tracks/default/nyc_taxis/mappings.json,修改 _all.enabled 为 true。
esrally race --distribution-version=5.5.0 --track=nyc_taxis --challenge=append-no-conflicts --user-tag="enableAll:true" --include-tasks="type:index"3 . 对比两次 race 的结果
esrally list races
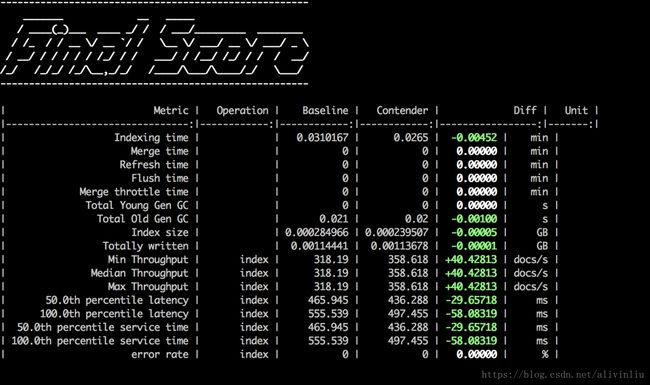
esrally compare --baseline=[enableAll race] --contender=[disableAll race]下图是我在 –test-mode 模式下运行的对比结果,也可以看出关闭 _all 可以提升写性能。
Tips:
–include-tasks 用于只运行 challenge 中的部分 task
问题三
提问:如何测试已有集群的性能?
回答:
使用 benchmark-only 的 pipeline 即可,这里我们的 track 和 challenge 如下:
- track: nyc_taxis
challenge: append-no-conflicts
测试步骤如下:
1 . 执行下方命令即可测试已有集群
esrally race --pipeline=benchmark-only --target-hosts=127.0.0.1:9200 --cluster-health=yellow --track=nyc_taxis --challenge=append-no-conflicts
Tips:
--cluster-health=yellow 默认 esrally 会检查集群状态,非 green 状态会直接退出。添加该参数可以避免该情况希望这三个问答可以帮助到大家快速掌握 esrally 的用法。
进阶
自定义 car
前面讲解 car 的时候,我们提到 esrally 已经自带了一些可用的 es 配置,但是如果这些还不能满足你的时候,可以通过下面两个方案解决
1 . 定制自己的car
car 的配置文件位于 esrally 目录 benchmarks/teams/default/cars,在这里新增一个自己的 car 配置文件就可以了。这里就不赘述了,感兴趣的可以查阅 car 的文档。
2 . 自己搭建集群
最简单的方式是脱离 esrally 的管理,自行搭建集群,这样想怎么配置就怎么配置了。
自定义 track
虽然 esrally 自带了很多 track,而且这些数据本身也不小,简单列在下面:
| Track | 压缩数据大小 | 解压数据大小 | 文档数 |
|---|---|---|---|
| geonames | 252 MB | 3.3 GB | 11396505 |
| geopoint | 482 MB | 2.3 GB | 60844404 |
| logging | 1.2 GB | 31 GB) | 247249096 |
| nested | 663 MB | 3.3 GB | 11203029 |
| noaa | 947 MB | 9 GB | 33659481 |
| nyc_taxis | 4.5 GB | 74 GB | 165346692 |
| percolator | 103KB | 105 MB | 2000000 |
| pmc | 5.5 GB | 22 GB | 574199 |
这些数据文件位于 esrally 目录 benchmarks/data 下面。不同的 Track 有不同的测试目的,详情可以去该 github repo 下面去查看。
当我们做定向测试的时候,还是希望针对自己的数据进行压测,此时可以自定义 track。操作也很简单,详情可以参考官方文档。这里简单列一下操作步骤。
1 . 在 上文提到的 data 目录中创建自己的数据目录。
2 . 准备压测数据文件。 esrally 使用的是一个json文件,其实是一个一个 json object。
3 . 将准备好的数据文件压缩成 bz2 格式,然后复制到步骤 1 创建的目录中去。
4 . 新增自定义的track。可以直接复制 geoname 目录,然后修改相关的配置文件,将测试数据与 track 绑定。
5 . 添加完后,通过 esrally list rack 就可以看到自定义的 track。
分布式压测
esrally 还支持分布式压测,即如果一个节点的 esrally 无法达到要求的并发数、请求数,那么可以将 esrally 分布到多台机器上去同时执行。分布式压测文档在这里,此处用到了 esrally dameon,对应命令是 esrallyd 。简单讲就是 esrally 通过 esrallyd 将多台机器组合成一个集群,然后 esrally 在执行测试任务的时候通过制定 –load-driver-hosts 便可以将测试任务分发到对应的机器上执行。这里便不赘述了,感兴趣的去看前面提到的文档。
最后一个问题
提问:一个 index 的 shard 数该如何确认?
回答:
其实针对这个提问,还可以再问下面两个问题。
1 . shard 设置过少是否有问题?比如一直都采用默认的 5个分片
2 . shard 设置过多是否有问题?比如直接设置为100个分片
要回到这两个问题,我们得先知道 shard 的作用。shard 是 es 实现分布式特性的基石,文档在索引进 es 时,es 会根据一个路由算法,将每一个文档分配到对应的 shard 上。每个 shard 实际对应一个 lucene index。那么每个 shard 能存储的文档数是否有上限呢?答案是有!每个shard最多存储 2^31 个文档,即 20亿。这是 lucene 设计决定的。那是不是只要我的文档数没有超过20亿,就可以只用一个或者很少的shard 呢?不尽然。因为随着 shard 体积的增大,其查询效率会下降,而且数据迁移和恢复的成本也会增高。官方建议单个 shard 大小不要超过 50GB,可以参见讨论一和讨论二.
现在回答上面的两个问题。
shard数过小不一定好,如果数据量很大,导致每个 shard 体积过大,会影响查询性能。
shard数过大也不一定好,因为 es 的每次查询是要分发给所有的 shard 来查询,然后再对结果做聚合处理,如果 shard 数过多也会影响查询性能。因此 shard 的数量需要根据自己的情况测出来。
官方文档有一节关于容量规划的章节,建议大家去看一下,链接在这里,其给出的步骤如下:
1 . 使用生产环境的硬件配置创建单节点集群
2 . 创建一个只有一个主分片无副本的索引,设置相关的mapping信息
3 . 将真实的文档导入到步骤 2 的索引中
4 . 测试实际会用到的查询语句
测试的过程中,关注相关指标数据,比如索引性能、查询性能,如果在某一个点相关性能数据超出了你的预期值,那么此时的 shard size大小便是符合你预期的单个 shard size的大小。接下来通过下面这个简单的计算公式便大致能确定一个 index 需要设定的 shard 数了。
shard数 = index 的数据总大小/单个shard size的极限值比如你测出单个 shard size 最大为 20 GB,而你预测该索引数据最大量在1年或者2年内不会超过 200GB,那么你的 shard 数就可以设置为10。
接下来要做的事情也很明确,我们要用 esrally 完成上面的压测步骤:
1 . 自行维护 es 节点的创建和运行,esrally 运行的时候采用 benchmark-only 模式.
2 . 自定义 track,这里有以下两个重点:
- 生成真实数据。如果你的数据无法生成很多,那么可以在 track 的 schedule 中设置 iterations 参数,即循环进行同一个操作,这样也可以测试大数据量的写性能。
- 定义自己的查询任务。在 track 的 operations 中是可以定义自己的查询语句的,比如下面这个
{
"name": "hourly_agg",
"operation-type": "search",
"index": "logs-*",
"type": "type",
"body": {
"size": 0,
"aggs": {
"by_hour": {
"date_histogram": {
"field": "@timestamp",
"interval": "hour" }
}
}
}
}其中的 body 便是自定义的查询语句,所以你可以通过自己的需求来设定查询语句,以贴近实际使用的情况。
3 . 还要记得设置索引的 mapping 与线上一致,比如是否启用 _all 等设置。
4 . 基于自定义的track来进行压测即可。要注意的是运行 esrally 的机器要和 es 机器分开,防止对 es 性能产生干扰。
Tips:
esrally 默认在每次压测是会删除已有的索引后再重新创建索引,如果你不想这样,可以在每个 index 的配置中设置 auto-managed 为 false,具体文档在这里。
通过这个参数,你就可以单独压测查询性能了,而不用每次都要先经过漫长的导入数据的过程。
总结
esrally 针对 es 的压测设计了一套完备的基于配置文件的测试流程,极大地简化了操作难度,并且提供了可重复验证的方式。对国内用户来讲,我认为最大的难处还是在于 esrally 自带的 track 文件太大,从 国外 aws 下载很慢。好在可以自定义 track,不必完全依赖自带的 track。
其他没啥好说的,esrally 棒棒哒,大家赶紧去试试吧,如果有问题欢迎来讨论!
参考资料
1 . esrally 官方文档
2 . Using Rally to benchmark Elasticsearch queries
3 . esrally 作者的演讲视频
4 . Benchmarking Elasticsearch for your use case with Rally
转自 : https://segmentfault.com/a/1190000011174694?_ea=2549617